【泡泡图灵智库】自动驾驶中的基于立体视觉的3D语义物体和相机运动追踪(ECCV)
泡泡图灵智库,带你精读机器人顶级会议文章
标题:Stereo Vision-based Semantic 3D Object and Ego-motion Tracking for Autonomous Driving
作者:Peilaing Li, Tong Qin, Shaojie Shen (HKUST )
来源:ECCV 2018
编译:张珊珊
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

大家好,今天为大家带来的文章是——Stereo Vision-based Semantic 3D Object and Ego-motion Tracking for Autonomous Driving,该文章发表于ECCV 2018。
我们提出一种基于双目视觉的在动态自动驾驶场景下追踪相机和3D语义物体的方法。代替使用端到端的方法直接生成物体的3D检测框,我们利用易于标记的2D检测结果和离散的观测点分类,并通过一个轻量级的语义推断方法得到物体粗略的3D测量。基于在动态环境中鲁棒的物体感知辅助相机位姿跟踪,结合我们新提出的动态物体集束调整(BA)方法将时序的稀疏特征关联和语义3D测量模型融合到一个统一的优化框架中,我们获得了具有实例精度和时间一致性的3D物体姿态、速度和锚定动态点云估计。我们提出的方法的性能在不同的场景中得到证明。相机运动估计和目标定位的性能都与最先进的解决方案进行了比较。
主要贡献
1.提出一种基于2D检测结果和观测点分类的轻量级的3D检测框推断方法,提供物体投影轮廓和遮挡掩模用于提取物体特征,同时作为语义测量模型参与后续的优化。
2.提出一种新的动态物体集束调整(BA)方法紧耦合语义和特征测量,用于实现具有实例精度和时间一致性的物体连续追踪。
算法流程
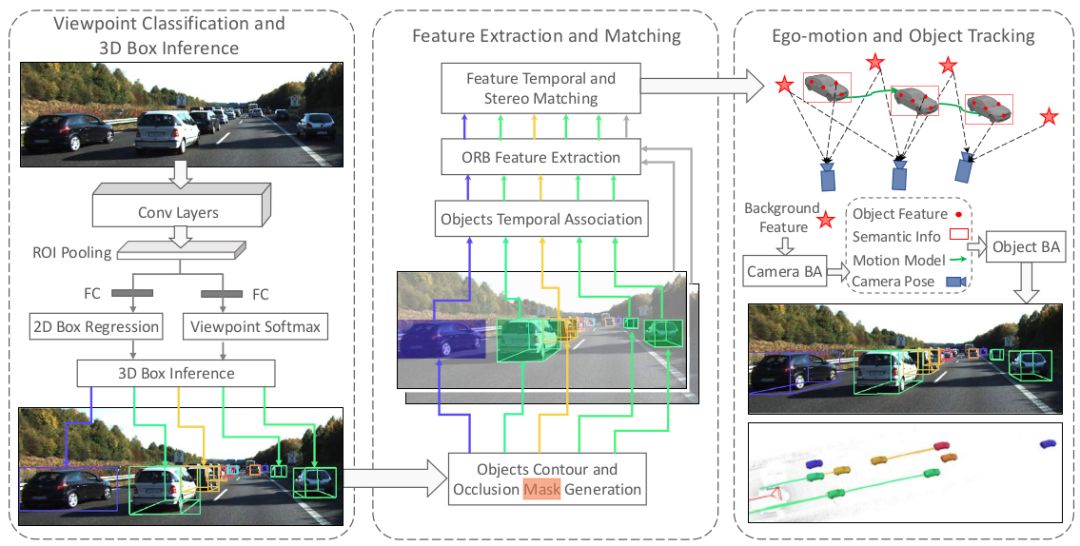
图1 本文系统的完整流程图
本文提出的语义追踪系统有三个主要的模块,如图1所示。第一个模块执行2D物体检测和观测点分类,并利用2D检测框的边与3D检测框上的点之间的约束粗略的推断物体的位姿。第二个模块是特征提取和匹配,将所有推断出来的3D检测框投影到2D图像上得到物体轮廓和遮挡掩模,以此引导的特征匹配被用于在立体图像和时序图像上获取鲁棒的特征关联。在第三个模块中,所有的语义测量和特征测量被紧耦合到一个优化方法中,用于相机和物体位姿的求解。
1.观测点分类和3D检测框的推断
(1) 2D检测和观测点分类
首先,利用Faster R-CNN进行2D图像的目标检测,由于实时性的需求,仅在双目的左图上进行检测。如图1所示,本文在传统的网络结构基础上在最后一个全卷积层添加子分类,不仅可以回归2D检测结果,还可以标记出物体的水平和垂直观测点。
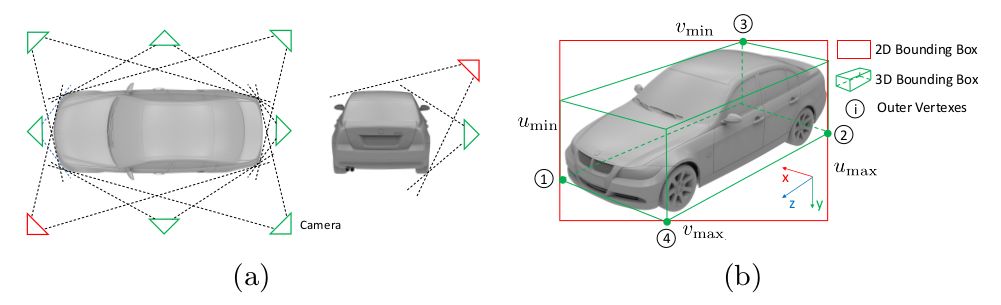
图2 物体的观测点分类
如图2(a)所示,我们将连续的物体观测角度分为8个水平和2个垂直观测方向,总共可以生成16种观测点的组合方式。图2(b)中的物体观测点即为(a)中红色三角形标注的两个观测方向组合。
(2) 3D检测框推断
为了推断3D检测框,我们做了一种假设:3D检测框在图像上的的投影会紧密贴合2D检测框,如图2(b)所示。我们现在得到了归一化平面上的2D检测框 [umin, vmin, umax, vmax]和观测点,接下来推断3D检测框。物体的3D检测框由下面三个值统一表示:中心点位置 p = [px, py, pz]^T,物体相对于相机的水平方向 θ,物体的先验尺寸 d = [dx, dy, dz]^T。其中,前两个变量 p, θ 用于表示物体的4自由度位姿。为了推断物体的3D检测框或者说物体的位姿,我们可以在图2(b)中得到4个约束关系,即3D检测框的四个点被投影到2D检测框边界上:
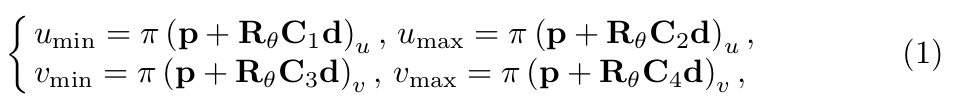
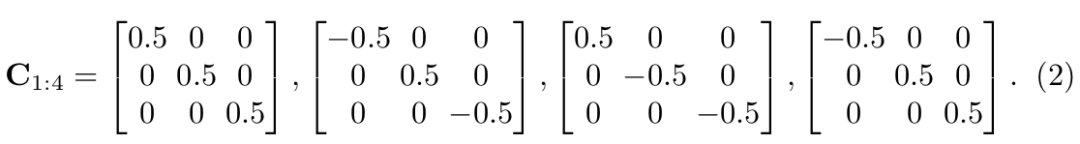
π是从相机坐标系到归一化平面的投影矩阵,Rθ表示从物体坐标系转化到相机坐标系,由θ参数化。公式(2)中,C1:4表示对角选择矩阵描述3D检测框中心点和与2D检测框边界相交的4个点①②③④之间的位置关系。当全卷积层输出了观测点,我们也就得到了对应的C1:4。例如上面给出的C1:4即为图2(b)中观测点下对应的选择矩阵。公式(1)中,第一个解释为以中心点为起点,向xyz三个方向的正方向各增加对应维度先验尺寸的一半得到点①,第二个解释为以中心点为起点,向x, z的反方向增加先验尺寸dx, dz的一半,向y的正方向增加先验尺寸dy的一半得到点②,这其中包含着由Rθ决定的从物体坐标系向相机坐标系的转换,再将点①②从相机坐标系转化到归一化平面正好和2D检测框边界相交,其余两个同理。这样,我们就得到了公式(1),用这四个等式就可以求解物体的4自由度位姿,同时也得到了3D检测框。
2.特征提取和匹配
首先,在2D检测框内和背景分别提取特征点,由于只有左图被检测,所以需要将左图推断出来的3D检测框投影到右图得到物体的轮廓。这里的特征匹配包含两部分:用于双目的立体匹配计算视差和深度值,用于时序匹配的数据关联。
立体匹配通过极线搜索进行,由于物体的粗略位姿已知,物体上的特征点深度范围是已知的,所以我们可以在进行极线搜索的时候将搜索区域限制到一个很小的范围内,提高立体匹配的鲁棒性。
时序匹配通过对连续帧的2D检测框的相似性进行判断,首先通过帧间转换矩阵将上一帧的检测框转到下一帧坐标系并和下一帧原有的2D检测框进行相似性判断,相似性分数通过中心点距离和形状的相似性共同决定,以此进行帧间的数据关联。
3.相机和物体的运动追踪
在一个通常的自动驾驶场景中,我们的目标有三个:
(1) 连续估计相机的运动
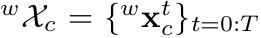
(2) 连续追踪3D物体的位置
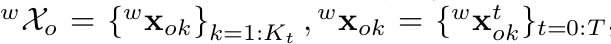
(3) 恢复动态稀疏特征点的3D位置
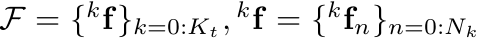
在这里,k表示物体序号,k=0表示背景;n表示第k个物体上的特征点序号;t表示时间或者帧的序号。部分符号可视化如图3所示。
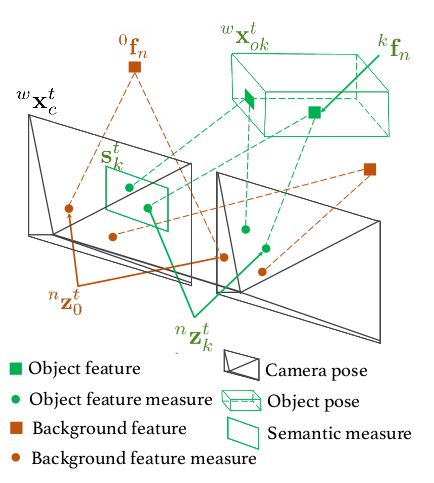
图3 符号可视化
我们首先针对目标(1),利用背景特征点的重投影误差来构建优化的最小二乘。由于没有先验信息可以利用,我们直接计算目标函数的最大似然,并假设观测模型服从高斯分布,将最大似然问题转化为马氏距离的BA问题。在这里,我们要求解的是相机的位姿和背景特征点的位置。
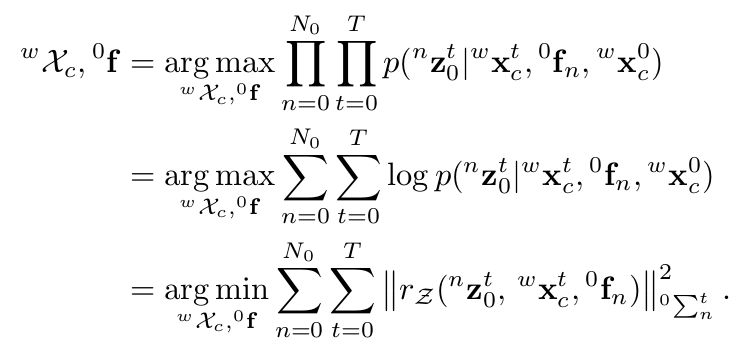
针对目标(2)和目标(3),我们需要求解出物体的位姿和物体上特征点的位置。在这里,我们假设物体为刚体,即物体上的特征点相对于物体坐标系是固定不动的,因此,如果我们有了对物体上特征点的连续观测,那么物体的时序状态也是与之相关的。
我们有了对物体的先验尺寸,因此建立一个最大后验估计问题并转化为似然和先验之积。
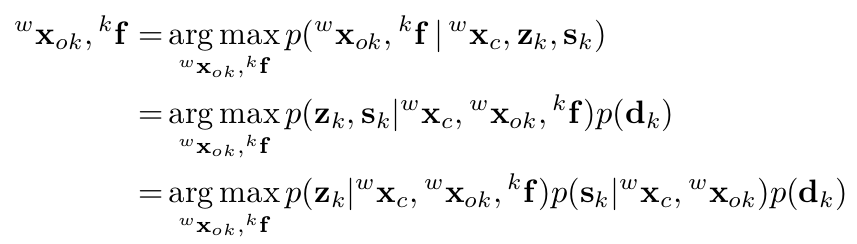
接下来,我们将似然函数分解出三部分,并将最大后验问题转化为基于马氏距离的最小二乘问题,如公式(10)所示。公式中包含四部分误差项,下面分别介绍:
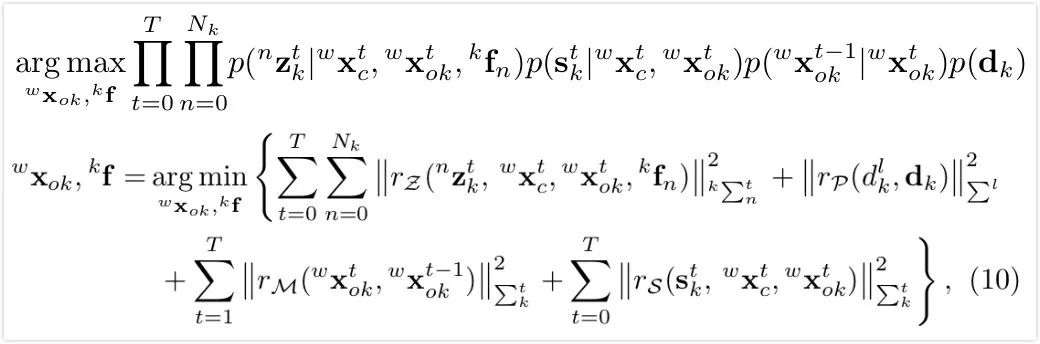
第一项为物体上特征点的重投影误差。仔细比较发现它与计算相机位姿时的最小二乘公式形式 (背景点的重投影误差) 十分相似。区别在于这里将静态特征和相机位姿扩展为动态特征和物体位姿。如下面公式所示,该误差项分为两部分,分别是左右两图上的重投影误差,两部分形式相似。左图上的重投影误差定义为:将第k个物体上的第n个特征点通过估计的物体位姿从物体坐标系转换到世界坐标系,再投影到相机坐标系,再通过π函数转换到归一化平面,计算投影的点坐标和观测值之差作为重投影误差。
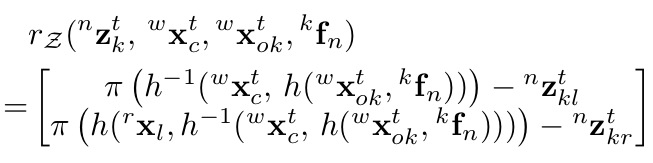
第二项为物体的尺寸先验。第三项为运动模型误差,通过该运动模型能够从t-1时刻车的状态推断k时刻车的状态,还能连续追踪车的速度和方向。该项误差定义为通过运动模型预测的t时刻状态减去估计的t时刻状态。
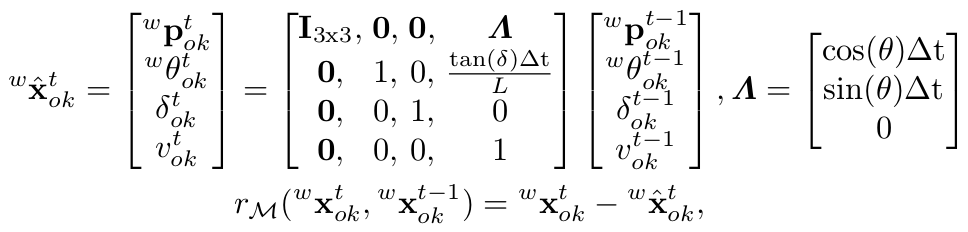
第四项为物体的语义观测误差。我们在前面通过公式(1)的四个等式关系求得一个粗略的物体位姿,现在则要将前面的等式关系构建为一个关于待优化的物体位姿的最小二乘误差项,原理和前面相同。
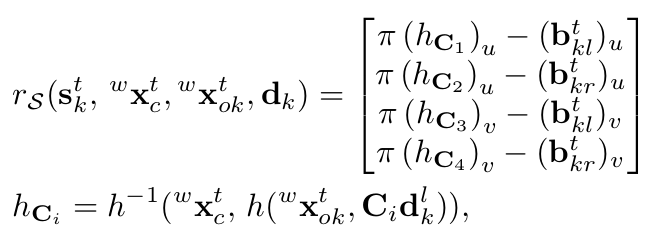
最小化所有误差后,我们得到最大后验估计的物体位姿。但是,由于物体尺寸的差异,位姿会有一定的偏差,因此需要将3D 检测框和恢复的物体稀疏点云进行对齐。
主要结果
1、相机位姿估计
由于仅利用背景点进行相机位姿的估计,所以在动态环境中本文的相机定位精度要普遍高于ORBSLAM2-stereo算法。
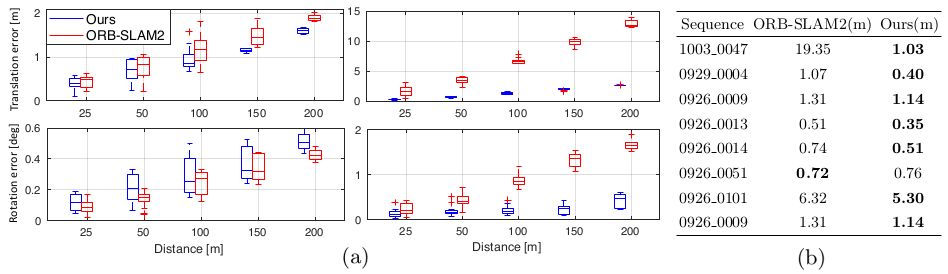
图4 本文和ORBSLAM2-stereo的定位精度比较
2、物体定位估计
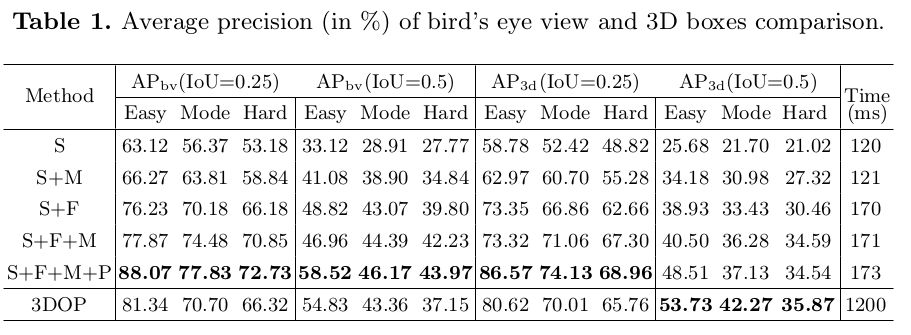
本文在KITTI tracking 数据集上对车辆的定位性能进行评估,根据遮挡等级和2D检测框的高度,将所有的检测物体分为三类:easy, moderate, hard。本文和3DOP算法的俯视框和3D检测框的平均定位精度如下表所示。S,M,F,P分别表示:语义测量,运动模型,特征观测和点云对齐。
从表中可以看出,语义观测明显改善easy(near)物体的精度由于大的特征提取区域;运动模型帮助改善hard(far)的精度,因为它平滑了小物体的检测噪声。

Abstract
We propose a stereo vision-based approach for tracking the camera ego-motion and 3D semantic objects in dynamic autonomous driving scenarios. Instead of directly regressing the 3D bounding box using end-to-end approaches, we propose to use the easy-to-labeled 2D detection and discrete viewpoint classification together with a light-weight semantic inference method to obtain rough 3D object measurements. Based on the object-aware-aided camera pose tracking which is robust in dynamic environments, in combination with our novel dynamic object bundle adjustment (BA) approach to fuse temporal sparse feature correspondences and the semantic 3D measurement model, we obtain 3D object pose, velocity and anchored dynamic point cloud estimation with instance accuracy and temporal consistency. The performance of our proposed method is demonstrated in diverse scenarios. Both the ego-motion estimation and object localization are compared with the state-of-of-the-art solutions.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号。
点击阅读原文,即可获取本文下载链接。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/bbs/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com


