基于可视化配置的日志结构化转换实现

作者介绍
王东,宜信技术研发中心高级架构师,负责流式计算和大数据业务产品解决方案。曾任职于Naver china(韩国最大搜索引擎公司)中国研发中心资深工程师,多年从事CUBRID-cluster分布式数据库开发和CUBRID数据库引擎开发。开源项目DBus负责人,开源项目CUBRID-cluster发起人。

随着互联网、IT、大数据等技术的爆发式发展,企业系统产生的大量爆发数据。对于保存在数据库中的业务数据,可以通过DBus数据总线+Wormhole流式处理平台的日志方式实时地无侵入同步和落地到任意sink端,提供下游系统分析使用;对于业务系统产生的日志数据,这些包含了业务高低峰、用户轨迹、系统异常/错误信息、调用链等诸多信息,也蕴含着无价的宝藏。一些公司通过埋点等方式和手段,往日志数据里输出他们想要监控和跟踪的信息,以便提供客观的数据支撑,做出更高效、更准确的决策。
DBus-https://github.com/bridata/dbus
Wormhole-https://github.com/edp963/wormhole
在这种背景下,各种各样的日志收集、结构化、分析工具如雨后春笋般出现,业界目前已有不少发展得比较成熟的方案,例如:Logstash、Filebeat、Flume、Fluentd、Chukwa. scribe、Splunk等,更有整合了日志采集、转换分析和展示的ELK集成方案。这些方案各有所长。在结构化日志这个方面,大多采用配置正则表达的方式:用于提取日志中模式比较固定、通用的部分,例如日志时间、日志类型、行号等。对于真正的和业务比较相关的信息,我们权且称之为message部分,原因主要是这部分千变万化,很难有一个特定、通用的模式来一劳永逸地描述及囊括所有情形。然而,这部分内容对于企业来说,比前面相对固定的部分更有价值。
本文就是介绍一种通过简单、可视化、所见即所得即席验证的方式,为用户提供高效、灵活地采集和加工利用数据日志的工具。
目前业界常见的日志分析代表为ELK:
通过Logstash实时收集和转换数据,保存到Eleaticsearch中,通过Kibana进行展示。
或者通过Filebeat 作为前端抓取数据,Logstash进行数据转换,保存到Eleaticsearch中,通过Kibana进行展示。
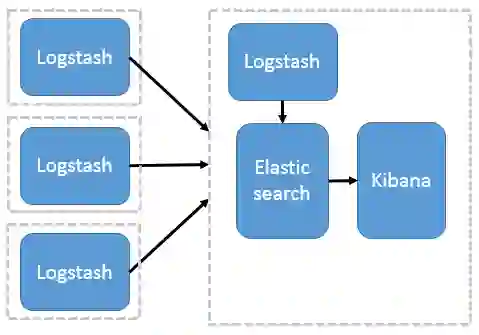
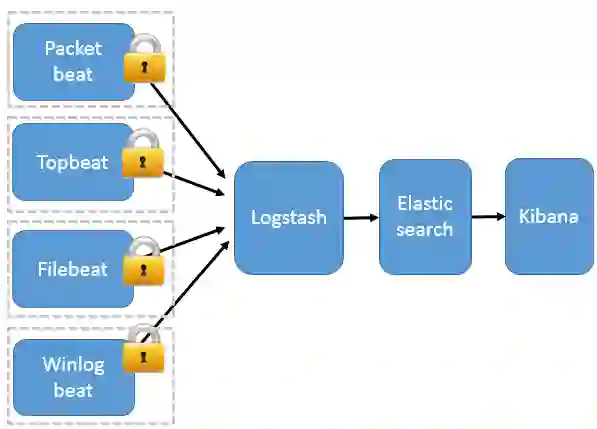
@以上图片来自参考[1]
例如:对于下面所示的类log4j的日志:
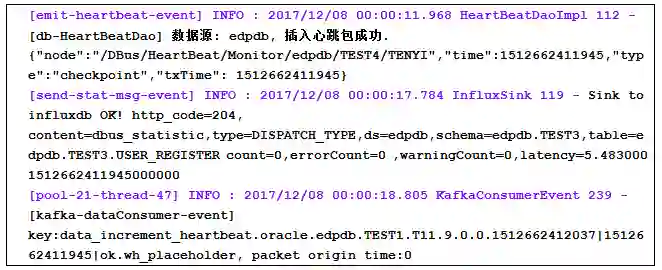
通常,我们配置log4j 配置如下:

pattern的前面相对固定,大多包含日志类型、时间、行号等,虽然不同但其实是基本稳定的;后面的%m,我们称之为message部分,一般来说是程序员在开发过程中输出的日志,各有各的模式。
以ELK为代表的流行日志处理方案几乎完美地整合了日志抓取、搜索和展示几个方面的需求,是目前业界最流行的日志处理解决方案。然而,如前所述,它主要是针对日志时间、日志类型、行号等类log4j的固定模式的提取。对于最后变化的message部分的处理,通常未深入解剖、探索,而是直接扔到类似ES的工具,交给ES去进行检索。这种情况下,用户需要从日志中提取数据,只能去ES即席查询。这种日志使用方式,显然远远无法满足用户对日志中重要数据价值“最大化榨取”的强烈需求。
Logstash提供其强大的配置功能,对这部分数据的进行支持。但由于这部分数据千变万化的特性,Logstash最终通过让用户配置正则表达式的方式来实现。正则表达式具有通用、紧凑、高效等特点,但不是很“亲民”、易懂。需要用户对正则表达式有良好的理解和掌握,才能写出正确的正则表达式(写出正确正则表达式之前,可能是无数次的测试、调整、尝试);另一方面,团队其他人员维护、变更时需要能准确读懂原作者撰写的表达式,在需要修改时,能准确无误地修改。这些都比较难。
我们关注于%m部分,即日志中的message部分,如果用户想将上述数据转换为如下的结构化数据信息:
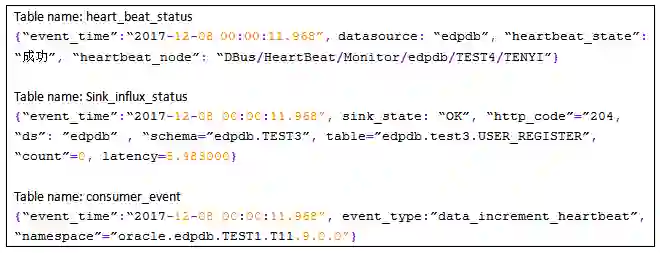
我们称这样的日志为“数据日志”。这部分日志更多是业务自身独有的一些数据,不管是程序Debug使用的日志记录,还是一些用户数据的记录,抑或是系统性埋点产生的日志。总之,他们和业务系统更相关,更个性化,也更加千差万别。
对于这部分数据日志的处理,关键的问题是:
例如:某用户id,在timestamp1的时间点,购买某商品id。一个用户可能打印很多行为日志,我们如何将这些用户的行为数据日志提取出来并以用户需要、易用的方式整合到一起,提供给后续分析使用。
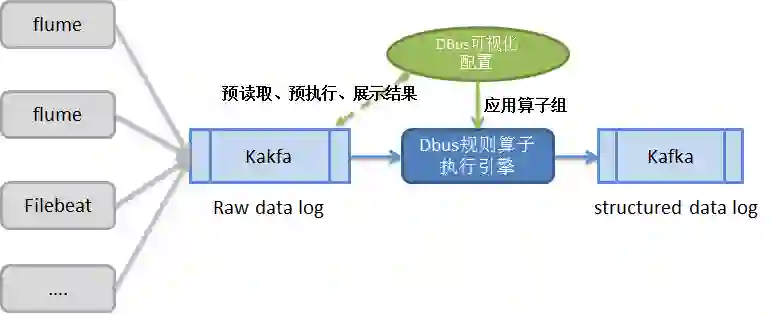
DBUS设计的数据日志同步方案如下:
日志抓取端采用业界流行的组件(例如Logstash、Flume、Filebeat等)。一方面便于用户和业界统一标准,方便用户的整合;另一方面也避免无谓的重造轮子。抓取数据称为原始数据日志(raw data log)放进Kafka中,等待处理。
提供可视化界面,配置规则来结构化日志。用户可配置日志来源和目标。同一个日志来源可以输出到多个目标。每一条“日志源-目标”线,中间数据经过的规则处理用户根据自己的需求来自由定义。最终输出的数据是结构化的,即:有schema约束,可以理解为类似数据库中的表。
所谓规则,在DBUS中,即“规则算子”。DBUS设计了丰富易用的过滤、拆分、合并、替换等算子供用户使用。用户对数据的处理可分多个步骤进行,每个步骤的数据处理结果可即时查看、验证;可重复使用不同算子,直到转换、裁剪得到自己需要的数据。
将配置好的规则算子组运用到执行引擎中,对目标日志数据进行预处理,形成结构化数据,输出到Kafka,供下游数据使用方使用。
系统流程图如下所示:
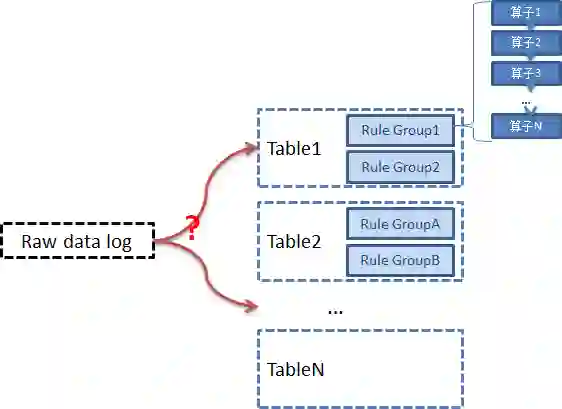
根据配置,我们支持同一条原始日志,能提取为一个表数据,或者可以提取为多个表数据。
每个表是结构化的,满足相同的schema。
每个表是一个规则 算子组的合集,可以配置1个到多个规则算子组
每个规则算子组,由一组规则算子组合而成
拿到一条原始数据日志, 它最终应该属于哪张表呢?
每条日志需要与规则算子组进行匹配:
符合条件的进入规则算子组的,最终被规则组转换为结构化的表数据。
不符合的尝试下一个规则算子组。
都不符合的,进入unknown_table表。
规则算子是对数据进行过滤、加工、转换的基本单元。常见的规则算子如下:
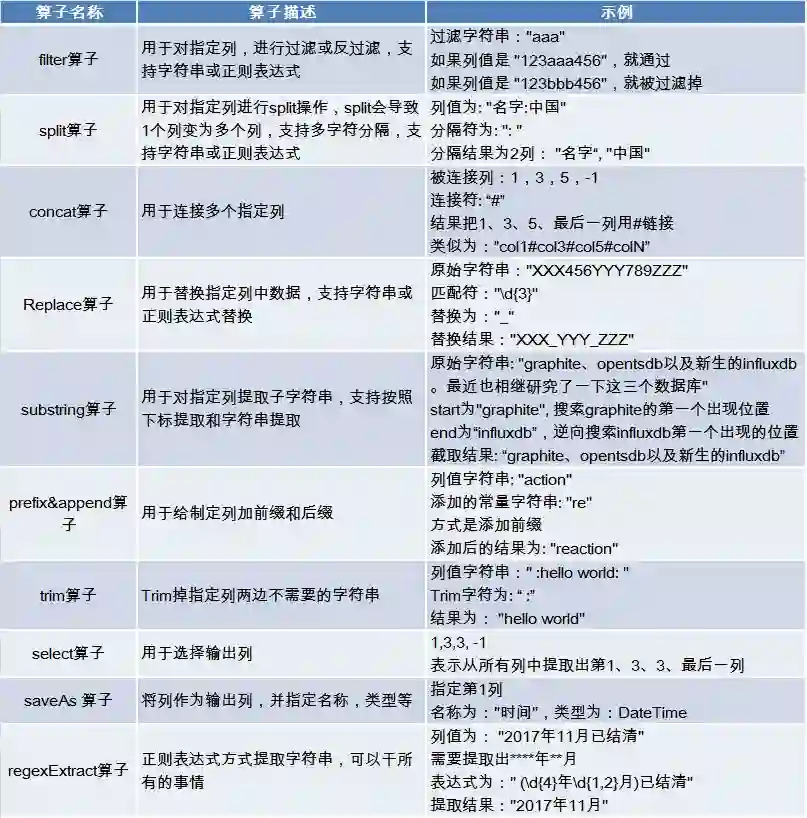
我们试图使得算子尽量满足正交性或易用性(虽然正则表达式很强大,但我们仍然开发一些简单算子例如trim算子来完成简单功能,以满足易用性),算子的开发也可以随意扩充,比如可以开发提取JSON节点值或XML节点值的算子。算子的开发也很容易,只要遵循基本接口原则,就可以开发任意自定义算子。
下面以提取heart_beat_status表为例子进行配置说明,整个数据日志结构化过程如下:
使用Logstash 读取log4j文件作为数据输入源,输出到Kafka中(这里具体配置就不说了,可参考Logstash配置)
这里抓取端不限制,你可以使用Flume、Filebeat,甚至你自己写的端,只要输出到Kafka中就可以。
首先配置一个输出表的规则组, 查看heartbeat_log_new这个topic中,我们直接实时的可视化操作配置。

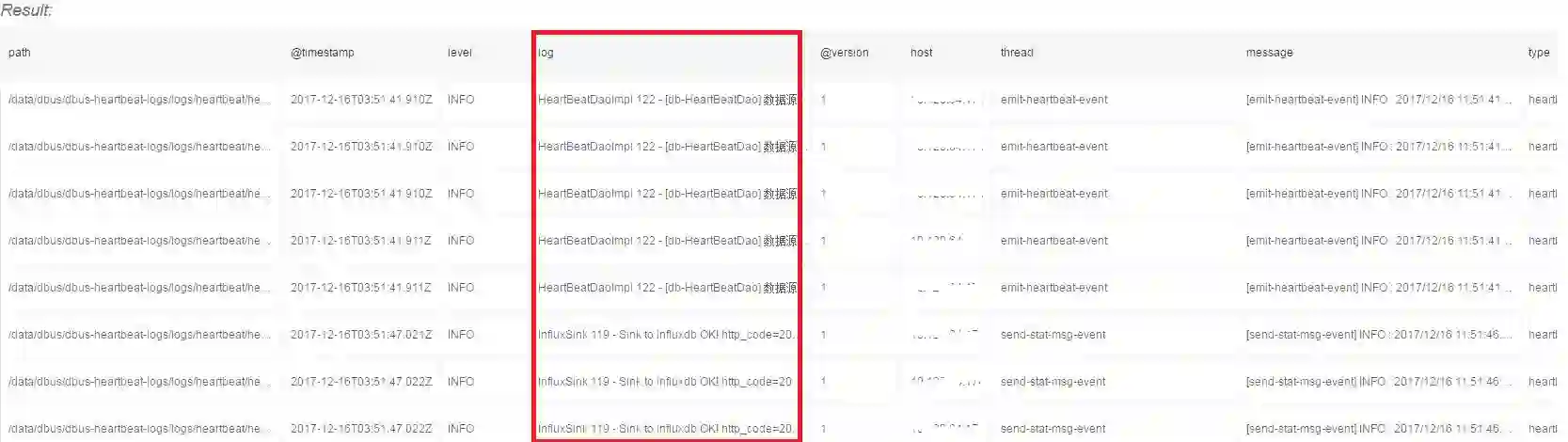
1、读取原始数据日志
可以看到由Logstash 预先提取已经包含了log4j的基本信息,例如path、@timestamp、level等。但是数据日志的详细信息在字段log中。由于不同的数据日志输出是不一样的,因此可以看到log列数据是同的。
(需要指出的是:使用logstash预先提取其它列是可选的,其实对于Flume这样直接抓取到的就是raw data log,这对我们后面的提取没有影响)
2、提取感兴趣列
例如我们提取timestamp、log 原始信息等,可以添加一个toindex算子,提取感兴趣的字段,如下:
这里需要指出,我们考虑使用数组下标方式,是有原因的:
并不是所有列天生就有列名(例如flume抽取的原始数据,或者split算子处理后的数据列);
下表方式对可以使用数组方式指定列(类似python方式, 例如:1:3 表示1,2,3列);
因此后续操作全部基于数组下标方式访问。
特别说明一下:如下?号所在的地方,鼠标移上去就会显示一个在线帮助,告诉你这个算子怎么使用,每个算子怎么用不需要记。

执行一下,就可以看到被提取后的字段情况:
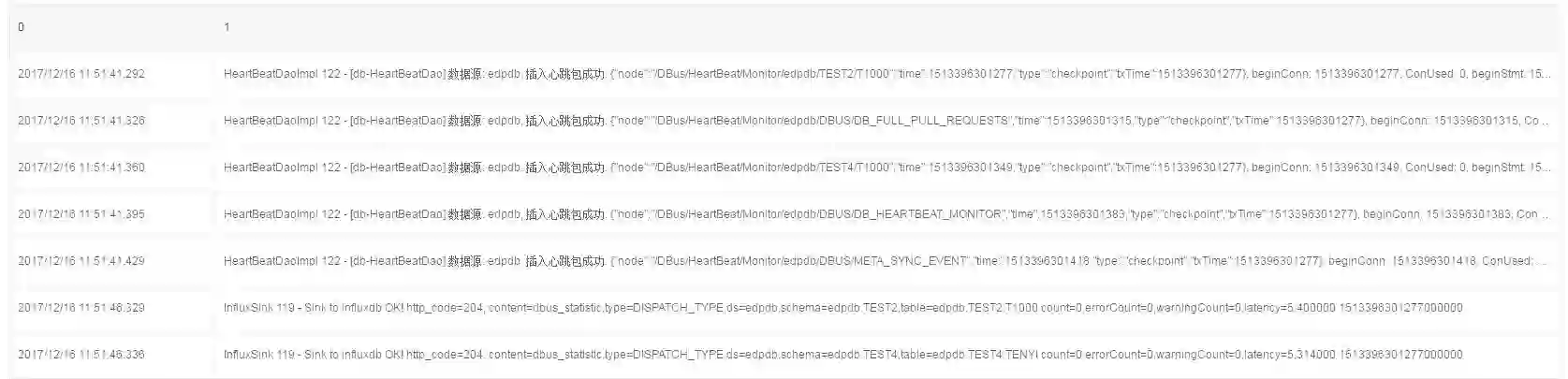
3、过滤不相关数据
在这个例子中,我们只对插入心跳包的数据感兴趣。因此添加一个filter算子,对第2列进行过滤”插入心跳包”:

执行后,不符合条件的日志行就被过滤了。

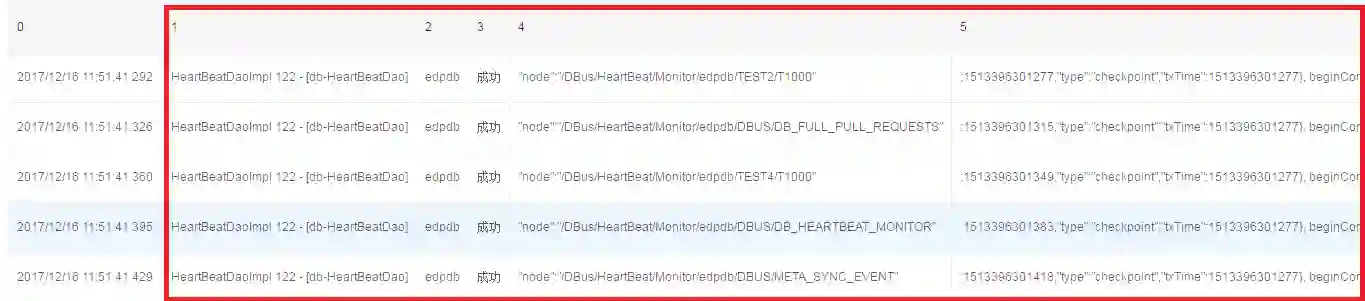
4、以切分方式进行提取
添加一个split算子,我们对“数据源”,“插入心跳包”,还有后面的“node”进行切分。

可以看到切分后,原来的第1列变新的1,2,3,4,5列了。
特别需要说明的是:提取的方式非常多,Split只是一种常见方式。我们可以substring提取,replace掉不需要的数据等,我们还也可以配置正则表示式提取。我们不积极推荐用正则表示的原因是正则表达式很容易写错,并不是最简单可视化的选择。
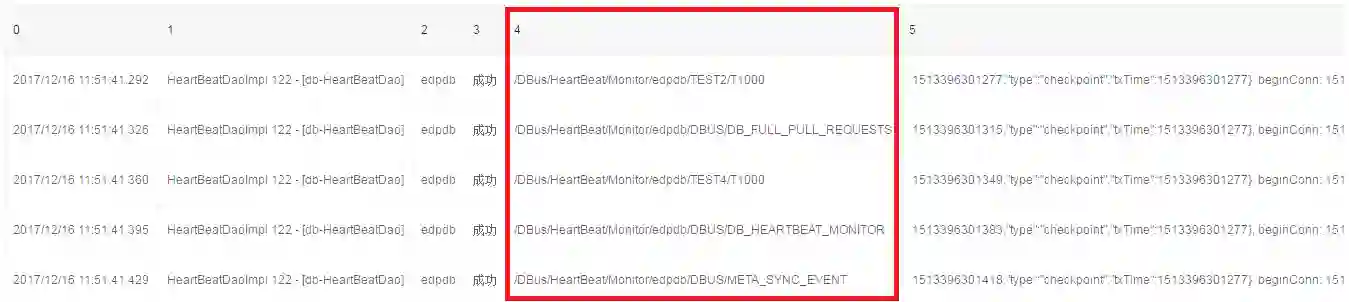
5、以trim方式出来数据
我们想提取4列的值,使用trim算子进行过滤掉不需要的数据。

执行后,这样新的5列就拿到干净的值。
6、选择输出列
最后我们把感兴趣的列输出,使用saveAs算子进行输出, 指定列名和类型。

执行后,这就是处理好的最终输出数据样本。

保存上一步配置好的规则组,运用到DBus执行算子引擎,就可以生成相应的结构化数据了。目前根据项目实际,DBus输出的数据是UMS格式。UMS是DBus开源项目(https://github.com/bridata/dbus)定义并使用的,通用的数据交换格式,是标准的JSON。其中同时包含了schema和数据信息。更多UMS介绍请参考DBus开源项目主页的介绍。
输出结果的数据格式和结构,不想使用UMS的,可经过简单的开发,实现定制化。
以下是测试案例,输出的结构化UMS数据的例子:
{
"payload": [
{
"tuple": [
"127046516736228867",
"2017-12-17 13:57:30.000",
"i",
"320171788",
"2017/12/17 13:57:30.877",
"edpdb",
"成功",
"/DBus/HeartBeat/Monitor/edpdb/TEST1/T1000"
]
},
{
"tuple": [
"127046516736228869",
"2017-12-17 13:57:30.000",
"i",
"320171790",
"2017/12/17 13:57:30.946",
"edpdb",
"成功",
"/DBus/HeartBeat/Monitor/edpdb/TEST4/ONEYI"
]
},
{
"tuple": [
"127046520930532871",
"2017-12-17 13:57:31.000",
"i",
"320171792",
"2017/12/17 13:57:31.026",
"edpdb",
"成功",
"/DBus/HeartBeat/Monitor/edpdb/TEST3/USER_REGISTER"
]
}
],
"protocol": {
"type": "data_increment_data",
"version": "1.3"
},
"schema": {
"batchId": 0,
"fields": [
{
"encoded": false,
"name": "ums_id_",
"nullable": false,
"type": "long"
},
{
"encoded": false,
"name": "ums_ts_",
"nullable": false,
"type": "datetime"
},
{
"encoded": false,
"name": "ums_op_",
"nullable": false,
"type": "string"
},
{
"encoded": false,
"name": "ums_uid_",
"nullable": false,
"type": "string"
},
{
"encoded": false,
"name": "event_time",
"nullable": false,
"type": "datetime"
},
{
"encoded": false,
"name": "datasource",
"nullable": false,
"type": "string"
},
{
"encoded": false,
"name": "heartbeat_state",
"nullable": false,
"type": "string"
},
{
"encoded": false,
"name": "heartbeat_node",
"nullable": false,
"type": "string"
}
],
"namespace": "heartbeat_log.heartbeat_log_schema.heartbeat_table.3.host1.0"
}
}
为了便于掌握数据抽取及规则匹配等情况,我们提供了日志数据提取的可视化实时监控界面,如下图所示,可随时了解:
实时数据条数
错误条数情况(错误条数是指:执行算子时出现错误的情况,帮助发现算子与数据是否匹配,用于修改算子)
数据延时情况
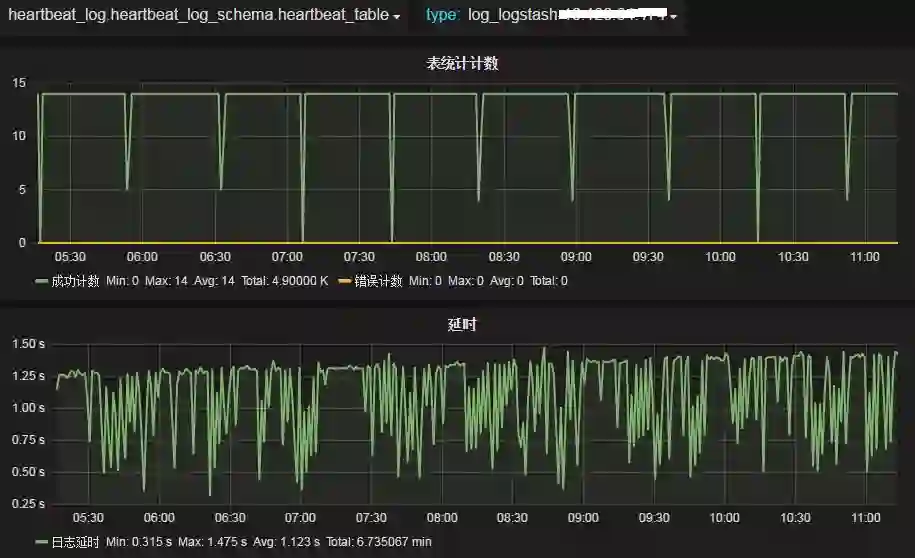
监控中还有一张表叫做__unkown_table__ 表明所有没有被匹配上的数据条数。例如:logstash抓取的日志中有5种不同模式的数据,我们只捕获了其中3种模式,其它没有被匹配上的数据,全部在_unkown_table_计数中。
DBus日志同步方案总结如下:
1、集成整合现有日志抓取工具(Flume、filebeat、logstash等),方便用户接入及整合;
2、DBUS提供了丰富的算子及可视化配置界面,供用户结构化数据日志使用。
通过可视化的,自由地使用各种规则算子对日志进行处理,生成结构化的数据日志;
每个算子配置过程都可以看到原始数据和加工后的数据;
算子可以随意增减,处理顺序可以随意调换,每个步骤的算子相互叠加使用;
用户也可以扩展开发自己需要的算子;
提供源到目标一对多的配置,让用户想怎么玩就怎么玩,从而可从任意多个角度挖掘数据价值;
监控让用户更直观地了解到数据结构化实时转换的情况,一切尽在掌控;
3、将原始数据日志转换为结构化数据,输出到kafka中提供给下游数据使用费进行使用。
最终使得日志业务数据结构化的过程,变得简单、可视化、配置集中化, 使得大家都能轻松地玩转日志数据。
本文提到的日志结构化方案计划于2018年1月发布到开源项目DBus 0.4版本中,项目地址https://github.com/bridata/dbus,敬请期待!
[1] ELK+Filebeat 集中式日志解决方案详解
https://www.ibm.com/developerworks/cn/opensource/os-cn-elk-filebeat/index.html?ca=drs-&utm_source=tuicool&utm_medium=referral
近期热文:
一篇含金量hin高的Nginx反向代理与负载均衡指南
方案虽好,成本先行:数据库Sharding+Proxy实践解析
一切皆API的大环境下,如何打造API Everything?
换个角度看Aurora:缘何“万能”?对比TiDB有何不同?




