训练GAN,你应该知道的二三事
机器之心专栏
作者:追一科技 AI Lab 研究员 Miracle
写在前面的话
笔者接触 GAN 也有一段时间了,从一开始的小白,到现在被 GANs 虐了千百遍但依然深爱着 GANs 的小白,被 GANs 的对抗思维所折服,被 GANs 能够生成万物的能力所惊叹。我觉得 GANs 在某种程度上有点类似于中国太极,『太极生两仪,两仪生四象』,太极阐明了宇宙从无极而太极,以至万物化生的过程,太极也是讲究阴阳调和。(哈哈,这么说来 GANs 其实在中国古代就已经有了发展雏形了。)
众所周知,GANs 的训练尤其困难,笔者自从跳入了 GANs 这个领域(坑),就一直在跟如何训练 GANs 做「对抗训练」,受启发于 ganhacks,并结合自己的经验记录总结了一些常用的训练 GANs 的方法,以备后用。
(⚠️本篇不是 GANs 的入门扫盲篇,初学者慎入。)
什么是 GANs?
GANs(Generative Adversarial Networks)可以说是一种强大的「万能」数据分布拟合器,主要由一个生成器(generator)和判别器(discriminator)组成。生成器主要从一个低维度的数据分布中不断拟合真实的高维数据分布,而判别器主要是为了区分数据是来源于真实数据还是生成器生成的数据,他们之间相互对抗,不断学习,最终达到Nash均衡,即任何一方的改进都不会导致总体的收益增加,这个时候判别器再也无法区分是生成器生成的数据还是真实数据。
GANs 最初由 Ian Goodfellow [1] 于 2014 年提出,目前已经在图像、语音、文字等方面得到广泛研究和应用,特别是在图像生成方面,可谓是遍地开花,例如图像风格迁移(style transfer)、图像修复(image inpainting)、超分辨率(super resolution)等。
GANs 出了什么问题?
GANs 通常被定义为一个 minimax 的过程:
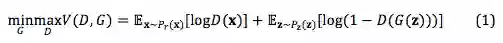
其中 P_r 是真实数据分布,P_z 是随机噪声分布。乍一看这个目标函数,感觉有点相互矛盾,其实这就是 GANs 的精髓所在—— 对抗训练。
在原始的 GANs 中,判别器要不断的提高判别是非的能力,即尽可能的将真实样本分类为正例,将生成样本分类为负例,所以判别器需要优化如下损失函数:
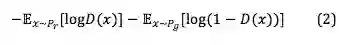
作为对抗训练,生成器需要不断将生成数据分布拉到真实数据分布,Ian Goodfellow 首先提出了如下式的生成器损失函数:

由于在训练初期阶段,生成器的能力比较弱,判别器这时候也比较弱,但仍然可以足够精准的区分生成样本和真实样本,这样 D(x) 就非常接近1,导致 log(1-D(x)) 达到饱和,后续网络就很难再调整过来。为了解决训练初期阶段饱和问题,作者提出了另外一个损失函数,即:
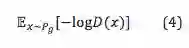
以上面这个两个生成器目标函数为例,简单地分析一下GAN模型存在的几个问题:
Ian Goodfellow 论文里面已经给出,固定 G 的参数,我们得到最优的 D^*:
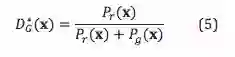
也就是说,只有当 P_r=P_g 时候,不管是真实样本和生成样本,判别器给出的概率都是 0.5,这个时候就无法区分样本到底是来自于真实样本还是来自于生成样本,这是最理想的情况。
1. 对于第一种目标函数
在最优判别器下 D^* 下,我们给损失函数加上一个与 G 无关的项,(3) 式变成:
注意,该式子其实就是判别器的损失函数的相反数。
把最优判别器 D^* 带入,可以得到:

到这里,我们就可以看清楚我们到底在优化什么东西了,在最优判别器的情况下,其实我们在优化两个分布的 JS 散度。当然在训练过程中,判别器一开始不是最优的,但是随着训练的进行,我们优化的目标也逐渐接近JS散度,而问题恰恰就出现在这个 JS 散度上面。一个直观的解释就是只要两个分布之间的没有重叠或者重叠部分可以忽略不计,那么大概率上我们优化的目标就变成了一个常数 -2log2,这种情况通过判别器传递给生成器的梯度就是零,也就是说,生成器不可能从判别器那里学到任何有用的东西,这也就导致了无法继续学习。
Arjovsky [2] 以其精湛的数学技巧提供一个更严谨的一个数学推导(手动截图原论文了)。

在 Theorm2.4 成立的情况下:
抛开上面这些文绉绉的数学表述,其实上面讲的核心内容就是当两个分布的支撑集是没有交集的或者说是支撑集是低维的流形空间,随着训练的进行,判别器不断接近最优判别器,会导致生成器的梯度处处都是为0。
2. 对于第二种目标函数
同样在最优判别器下,优化 (4) 式等价优化如下

仔细盯着上面式子几秒钟,不难发现我们优化的目标是相互悖论的,因为 KL 散度和 JS 散度的符号相反,优化 KL 是把两个分布拉近,但是优化 -JS 是把两个分布推远,这「一推一拉」就会导致梯度更新非常不稳定。此外,我们知道 KL 不是对称的,对于生成器无法生成真实样本的情况,KL 对 loss 的贡献非常大,而对于生成器生成的样本多样性不足的时候,KL 对 loss 的贡献非常小。
而 JS 是对称的,不会改变 KL 的这种不公平的行为。这就解释了我们经常在训练阶段经常看见两种情况,一个是训练 loss 抖动非常大,训练不稳定;另外一个是即使达到了稳定训练,生成器也大概率上只生成一些安全保险的样本,这样就会导致模型缺乏多样性。
此外,在有监督的机器学习里面,经常会出现一些过拟合的情况,然而 GANs 也不例外。当生成器训练得越来越好时候,生成的数据越接近于有限样本集合里面的数据。特别是当训练集里面包含有错误数据时候,判别器会过拟合到这些错误的数据,对于那些未见的数据,判别器就不能很好的指导生成器去生成可信的数据。这样就会导致 GANs 的泛化能力比较差。
综上所述,原始的 GANs 在训练稳定性、模式多样性以及模型泛化性能方面存在着或多或少的问题,后续学术上的工作大多也是基于此进行改进(填坑)。
训练 GAN 的常用策略
上一节都是基于一些简单的数学或者经验的分析,但是根本原因目前没有一个很好的理论来解释;尽管理论上的缺陷,我们仍然可以从一些经验中发现一些实用的 tricks,让你的 GANs 不再难训。这里列举的一些 tricks 可能跟 ganhacks 里面的有些重复,更多的是补充,但是为了完整起见,部分也添加在这里。
1. model choice
如果你不知道选择什么样的模型,那就选择 DCGAN[3] 或者 ResNet[4] 作为 base model。
2. input layer
假如你的输入是一张图片,将图片数值归一化到 [-1, 1];假如你的输入是一个随机噪声的向量,最好是从 N(0, 1) 的正态分布里面采样,不要从 U(0,1) 的均匀分布里采样。
3. output layer
使用输出通道为 3 的卷积作为最后一层,可以采用 1x1 或者 3x3 的 filters,有的论文也使用 9x9 的 filters。(注:ganhacks 推荐使用 tanh)
4. transposed convolution layer
在做 decode 的时候,尽量使用 upsample+conv2d 组合代替 transposed_conv2d,可以减少 checkerboard 的产生 [5];
在做超分辨率等任务上,可以采用 pixelshuffle [6]。在 tensorflow 里,可以用 tf.depth_to_sapce 来实现 pixelshuffle 操作。
5. convolution layer
由于笔者经常做图像修复方向相关的工作,推荐使用 gated-conv2d [7]。
6. normalization
虽然在 resnet 里的标配是 BN,在分类任务上表现很好,但是图像生成方面,推荐使用其他 normlization 方法,例如 parameterized 方法有 instance normalization [8]、layer normalization [9] 等,non-parameterized 方法推荐使用 pixel normalization [10]。假如你有选择困难症,那就选择大杂烩的 normalization 方法——switchable normalization [11]。
7. discriminator
想要生成更高清的图像,推荐 multi-stage discriminator [10]。简单的做法就是对于输入图片,把它下采样(maxpooling)到不同 scale 的大小,输入三个不同参数但结构相同的 discriminator。
8. minibatch discriminator
由于判别器是单独处理每张图片,没有一个机制能告诉 discriminator 每张图片之间要尽可能的不相似,这样就会导致判别器会将所有图片都 push 到一个看起来真实的点,缺乏多样性。minibatch discriminator [22] 就是这样这个机制,显式地告诉 discriminator 每张图片应该要不相似。在 tensorflow 中,一种实现 minibatch discriminator 方式如下:
上面是通过一个可学习的网络来显示度量每个样本之间的相似度,PGGAN 里提出了一个更廉价的不需要学习的版本,即通过统计每个样本特征每个像素点的标准差,然后取他们的平均,把这个平均值复制到与当前 feature map 一样空间大小单通道,作为一个额外的 feature maps 拼接到原来的 feature maps 里,一个简单的 tensorflow 实现如下:

9. GAN loss
除了第二节提到的原始 GANs 中提出的两种 loss,还可以选择 wgan loss [12]、hinge loss、lsgan loss [13]等。wgan loss 使用 Wasserstein 距离(推土机距离)来度量两个分布之间的差异,lsgan 采用类似最小二乘法的思路设计损失函数,最后演变成用皮尔森卡方散度代替了原始 GAN 中的 JS 散度,hinge loss 是迁移了 SVM 里面的思想,在 SAGAN [14] 和 BigGAN [15] 等都是采用该损失函数。

ps: 我自己经常使用没有 relu 的 hinge loss 版本。
10. other loss
perceptual loss [17]
style loss [18]
total variation loss [17]
l1 reconstruction loss
通常情况下,GAN loss 配合上面几种 loss,效果会更好。
11. gradient penalty
Gradient penalty 首次在 wgan-gp 里面提出来的,记为 1-gp,目的是为了让 discriminator 满足 1-lipchitchz 连续,后续 Mescheder, Lars M. et al [19] 又提出了只针对正样本或者负样本进行梯度惩罚,记为 0-gp-sample。Thanh-Tung, Hoang et al [20] 提出了 0-gp,具有更好的训练稳定性。三者的对比如下:

12. Spectral normalization [21]
谱归一化是另外一个让判别器满足 1-lipchitchz 连续的利器,建议在判别器和生成器里同时使用。
ps: 在个人实践中,它比梯度惩罚更有效。
13. one-size label smoothing [22]
平滑正样本的 label,例如 label 1 变成 0.9-1.1 之间的随机数,保持负样本 label 仍然为 0。个人经验表明这个 trick 能够有效缓解训练不稳定的现象,但是不能根本解决问题,假如模型不够好的话,随着训练的进行,后期 loss 会飞。
14. add supervised labels
add labels
conditional batch normalization
15. instance noise (decay over time)
在原始 GAN 中,我们其实在优化两个分布的 JS 散度,前面的推理表明在两个分布的支撑集没有交集或者支撑集是低维的流形空间,他们之间的 JS 散度大概率上是 0;而加入 instance noise 就是强行让两个分布的支撑集之间产生交集,这样 JS 散度就不会为 0。新的 JS 散度变为:
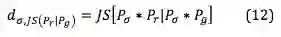
16. TTUR [23]
在优化 G 的时候,我们默认是假定我们的 D 的判别能力是比当前的 G 的生成能力要好的,这样 D 才能指导 G 朝更好的方向学习。通常的做法是先更新 D 的参数一次或者多次,然后再更新 G 的参数,TTUR 提出了一个更简单的更新策略,即分别为 D 和 G 设置不同的学习率,让 D 收敛速度更快。
17. training strategy
PGGAN [10]
PGGAN 是一个渐进式的训练技巧,因为要生成高清(eg, 1024x1024)的图片,直接从一个随机噪声生成这么高维度的数据是比较难的;既然没法一蹴而就,那就循序渐进,首先从简单的低纬度的开始生成,例如 4x4,然后 16x16,直至我们所需要的图片大小。在 PGGAN 里,首次实现了高清图片的生成,并且可以做到以假乱真,可见其威力。此外,由于我们大部分的操作都是在比较低的维度上进行的,训练速度也不比其他模型逊色多少。
coarse-to-refine
coarse-to-refine 可以说是 PGGAN 的一个特例,它的做法就是先用一个简单的模型,加上一个 l1 loss,训练一个模糊的效果,然后再把这个模糊的照片送到后面的 refine 模型里,辅助对抗 loss 等其他 loss,训练一个更加清晰的效果。这个在图片生成里面广泛应用。
18. Exponential Moving Average [24]
EMA主要是对历史的参数进行一个指数平滑,可以有效减少训练的抖动。强烈推荐!!!
总结
训练 GAN 是一个精(折)细(磨)的活,一不小心你的 GAN 可能就是一部惊悚大片。笔者结合自己的经验以及看过的一些文献资料,列出了常用的 tricks,在此抛砖引玉,由于笔者能力和视野有限,有些不正确之处或者没补全的 tricks,还望斧正。
最后,祝大家炼丹愉快,不服就 GAN。: )

参考文献
[1]. Goodfellow, Ian, et al. "Generative adversarial nets." Advances in neural information processing systems. 2014.
[2]. Arjovsky, Martín and Léon Bottou. “Towards Principled Methods for Training Generative Adversarial Networks.” CoRR abs/1701.04862 (2017): n. pag.
[3]. Radford, Alec et al. “Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks.” CoRR abs/1511.06434 (2016): n. pag.
[4]. He, Kaiming et al. “Deep Residual Learning for Image Recognition.” 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2016): 770-778.
[5]. https://distill.pub/2016/deconv-checkerboard/
[6]. Shi, Wenzhe et al. “Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network.” 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2016): 1874-1883.
[7]. Yu, Jiahui et al. “Free-Form Image Inpainting with Gated Convolution.” CoRRabs/1806.03589 (2018): n. pag.
[8]. Ulyanov, Dmitry et al. “Instance Normalization: The Missing Ingredient for Fast Stylization.” CoRR abs/1607.08022 (2016): n. pag.
[9]. Ba, Jimmy et al. “Layer Normalization.” CoRR abs/1607.06450 (2016): n. pag.
[10]. Karras, Tero et al. “Progressive Growing of GANs for Improved Quality, Stability, and Variation.” CoRR abs/1710.10196 (2018): n. pag.
[11]. Luo, Ping et al. “Differentiable Learning-to-Normalize via Switchable Normalization.” CoRRabs/1806.10779 (2018): n. pag.
[12]. Arjovsky, Martín et al. “Wasserstein GAN.” CoRR abs/1701.07875 (2017): n. pag.
[13]. Mao, Xudong, et al. "Least squares generative adversarial networks." Proceedings of the IEEE International Conference on Computer Vision. 2017.
[14]. Zhang, Han, et al. "Self-attention generative adversarial networks." arXiv preprint arXiv:1805.08318 (2018).
[15]. Brock, Andrew, Jeff Donahue, and Karen Simonyan. "Large scale gan training for high fidelity natural image synthesis." arXiv preprint arXiv:1809.11096 (2018).
[16]. Gulrajani, Ishaan et al. “Improved Training of Wasserstein GANs.” NIPS (2017).
[17]. Johnson, Justin et al. “Perceptual Losses for Real-Time Style Transfer and Super-Resolution.” ECCV (2016).
[18]. Liu, Guilin et al. “Image Inpainting for Irregular Holes Using Partial Convolutions.” ECCV(2018).
[19]. Mescheder, Lars M. et al. “Which Training Methods for GANs do actually Converge?” ICML(2018).
[20]. Thanh-Tung, Hoang et al. “Improving Generalization and Stability of Generative Adversarial Networks.” CoRR abs/1902.03984 (2018): n. pag.
[21]. Yoshida, Yuichi and Takeru Miyato. “Spectral Norm Regularization for Improving the Generalizability of Deep Learning.” CoRR abs/1705.10941 (2017): n. pag.
[22]. Salimans, Tim et al. “Improved Techniques for Training GANs.” NIPS (2016).
[23]. Heusel, Martin et al. “GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium.” NIPS (2017).
[24]. Yazici, Yasin et al. “The Unusual Effectiveness of Averaging in GAN Training.” CoRRabs/1806.04498 (2018): n. pag.
本文为机器之心专栏,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com

