
题目
知识图谱的生成式对抗零样本关系学习:Generative Adversarial Zero-Shot Relational Learning for Knowledge Graphs
简介
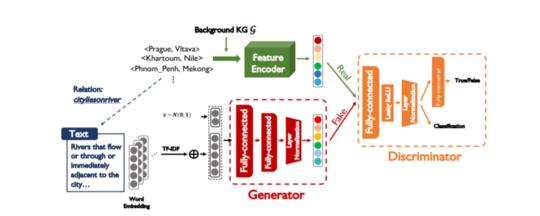
大规模知识图谱(KGs)在当前的信息系统中显得越来越重要。为了扩大知识图的覆盖范围,以往的知识图完成研究需要为新增加的关系收集足够的训练实例。本文考虑一种新的形式,即零样本学习,以摆脱这种繁琐的处理,对于新增加的关系,我们试图从文本描述中学习它们的语义特征,从而在不见实例的情况下识别出看不见的关系。为此,我们利用生成性对抗网络(GANs)来建立文本与知识边缘图域之间的联系:生成器学习仅用有噪声的文本描述生成合理的关系嵌入。在这种背景下,零样本学习自然转化为传统的监督分类任务。从经验上讲,我们的方法是模型不可知的,可以应用于任何版本的KG嵌入,并在NELL和Wikidataset上产生性能改进。
作者 Pengda Qin,Xin Wang,Wenhu Chen,Chunyun Zhang,Weiran Xu1William Yang Wang
成为VIP会员查看完整内容
相关内容

知识图谱(Knowledge Graph),在图书情报界称为知识域可视化或知识领域映射地图,是显示知识发展进程与结构关系的一系列各种不同的图形,用可视化技术描述知识资源及其载体,挖掘、分析、构建、绘制和显示知识及它们之间的相互联系。
知识图谱是通过将应用数学、图形学、信息可视化技术、信息科学等学科的理论与方法与计量学引文分析、共现分析等方法结合,并利用可视化的图谱形象地展示学科的核心结构、发展历史、前沿领域以及整体知识架构达到多学科融合目的的现代理论。它能为学科研究提供切实的、有价值的参考。
专知会员服务
66+阅读 · 2020年4月17日



相关VIP内容
专知会员服务
66+阅读 · 2020年4月17日
相关资讯