文本挖掘从小白到精通(二十一)如何使用造好的轮子快速实现各项文本挖掘任务
特别推荐|【文本挖掘系列教程】:

文本挖掘从小白到精通(一)---语料、向量空间和模型的概念
文本挖掘从小白到精通(三)---主题模型和文本数据转换
文本挖掘从小白到精通(五)---主题模型的主题数确定和可视化
文本挖掘从小白到精通(六)---word2vec的训练、使用和可视化
文本挖掘从小白到精通(七)--- Word2vec的增量学习
文本挖掘从小白到精通(八)--- 从海量文章中挖掘主要观点
文本挖掘从小白到精通(九)--- 文本相似性度量
文本挖掘从小白到精通(十)--- 不需设定聚类数的Single-pass
文本挖掘从小白到精通(十一)--- 不需设定聚类数的DBSCAN
文本挖掘从小白到精通(十二)--- 7种简单易行的文本特征提取方法
文本挖掘从小白到精通(十三)--- 文本挖掘中会涉及的若干降维方法
文本挖掘从小白到精通(十四)--- 如何将训练所得的word2vec模型用于后续任务
文本挖掘从小白到精通(十五)--- NLP小白也能轻松学会的BERT使用指南
文本挖掘从小白到精通(十六)--- 像使用scikit-learn一样玩转BERT
文本挖掘从小白到精通(十七)--- 只有少量标注文本数据怎么办?
文本挖掘从小白到精通(十八)---文本层次聚类
文本挖掘从小白到精通(十九)--- 目前有比Topic Model更先进的聚类方式么
文本挖掘从小白到精通(二十)- 如何更有效率的加载大型词嵌入模型?
【特辑】文本分类算法集锦,从小白到大牛,附代码注释和训练语料
原作【nlp-exercises 101 】是Shrivarsheni 写的,发布在 https://www.machinelearningplus.com/nlp/nlp-exercises/ 。由于其中的代码绝大部分是针对英文来操作的,不太适合中文,笔者对其中的内容进行了选取,并针对中文做了适配,改动幅度近于90%。
自然语言处理是人工智能理解人类语言的技术。NLP任务如文本分类、总结、情感分析、翻译等被广泛使用。本帖旨在为基础和高级NLP任务提供些许参考。篇幅有限,很多原理没有来得及铺陈开来,直接上的代码,如有疑问,欢迎Google或者直接下方留言。
1. 如何在nltk中下载 "stopwords(停用词)" and "punkt(标点符号)" 这两个工具包?
# Downloading packages and importing
import nltk
nltk.download('punkt')
nltk.download('stop')
nltk.download('stopwords')
[nltk_data] Downloading package punkt to
[nltk_data] C:\Users\Administrator\AppData\Roaming\nltk_data...
[nltk_data] Unzipping tokenizers\punkt.zip.
[nltk_data] Error loading stop: Package 'stop' not found in index
[nltk_data] Downloading package stopwords to
[nltk_data] C:\Users\Administrator\AppData\Roaming\nltk_data...
[nltk_data] Unzipping corpora\stopwords.zip.
2. 如何在spacy导入语言模型(language model) ?
难度等级 : L1
Q. 导入spacy库并加载'en_core_web_sm'模型以支持英语语言模型。加载'xx_ent_wiki_sm'以支持多语言。
# Import and load model
import spacy
nlp=spacy.load("en_core_web_sm")
nlp
# More models here: https://spacy.io/models
<spacy.lang.en.English at 0x24e7a5d4e10>
3. 如何对给定的文本进行词条化(tokenization)?
难度等级 : L1
Q. 对给定文本词条化后的词条(token)进行打印。
import jieba
text ='''通过对全网主流媒体及社交媒体平台进行实时数据抓取和深度处理,可以帮助政府/企业及时、全面、精准地从海量的数据中了解公众态度、掌控舆论动向、聆听用户声音、洞察行业变化。'''
text_segment = jieba.lcut(text)
print(text_segment )
['通过', '对', '全网', '主流', '媒体', '及', '社交', '媒体', '平台', '进行', '实时', '数据', '抓取', '和', '深度', '处理', ',', '可以', '帮助', '政府', '/', '企业', '及时', '、', '全面', '、', '精准', '地', '从', '海量', '的', '数据', '中', '了解', '公众', '态度', '、', '掌控', '舆论', '动向', '、', '聆听', '用户', '声音', '、', '洞察', '行业', '变化', '。']
4. 如何对给定的文档进行语句划分?
from pyltp import SentenceSplitter
docs = '''社会化聆听可以7*24小时全天侯对全网进行实时监测,采用文本挖掘技术对民众意见反馈、领导发言、政策文件进行监测分析。通过这些先进的nlp技术的处理,可以帮助政府及时的了解社会各阶层民众对社会现状和发展所持有的情绪、态度、看法、意见和行为倾向 。最终实现积极主动的响应处理措施和方案,对于互联网上一些错误的、失实的舆论做出正确的引导作用,控制舆论发展方向。'''
sentences = SentenceSplitter.split(docs)
print('\n'.join(list(sentences)))
5. 如何利用 transformers 对文本进行词条化 ?
难度等级 : L1
Q. 使用Huggingface的 transformers库直接对文本进行词条化处理,不需要分词。
# Import tokenizer from transfromers
!pip install transformers
from transformers import AutoTokenizer
text = '''对公司品牌进行负面舆情实时监测,事件演变趋势预测,预警实时触达,
帮助公司市场及品牌部门第一时间发现负面舆情,及时应对危机公关,控制舆论走向,
防止品牌受损。'''
# Initialize the tokenizer
tokenizer=AutoTokenizer.from_pretrained('bert-base-chinese')
# 使用tokenizer对文本进行编码
inputs=tokenizer.encode(text)
print(inputs)
# 使用tokenizer对文本编码进行解码
outputs = tokenizer.decode(inputs)
print(outputs)
6. 如何在对文本词条化时将停用词(stopwords)用作短语区隔符号 ?
难度等级 : L2
Q. 有时把停用词用作区隔符号,将会保留有意义的短语( meaningful phrases),这对于很多场景,如文本分类、主题建模和文本聚类都很有用。
text = '''
文本挖掘主要有哪些功能
达观数据拥有多年的自然语言处理技术经验,掌握从词语短串到篇章分析各层面的分析技术,在此基础之上提供以下文本挖掘功能:
* 涉黄涉政检测:对文本内容做涉黄涉政检测,满足相应政策要求;
* 垃圾评论过滤:在论坛发言或用户评论中,过滤文本中的垃圾广告,提升文本总体质量;
* 情感分析:对用户评论等文本内容做情感分析,指导决策与运营;
* 自动标签提取:自动提取文本重要内容生成关键性标签,在此基础之上拓展更多功能形式;
* 文本自动分类:通过对文本内容进行分析,给出文本所属的类别和置信度,支持二级分类。
正常政治言论也会被过滤掉吗?
不会,达观对涉政内容会返回一个“反动”权值,取值范围0到1。当涉政内容的反动权值接近“1”时,文本的反动倾向很高,根据客户要求可以直接过滤掉,当反动权值接近“0”时,则文本为正常政治言论的几率就非常高,客户可通过反动权值控制审核松紧程度。
黄反内容、垃圾广告形式多样怎么处理?
传统的方法更多的是通过配词典的方式来解决。但是这种方法遇到变形文本时命中率很低,造成严重的漏盘,而且需要人工不断更新词典,效率很低。
达观数据通过机器学习的方法智能识别各种变形变换的内容,同时根据最新的样本数据实时更新运算模型,自动学习更新,保证检测的效果。
实时的弹幕能够做处理吗?
可以,达观数据文本挖掘系统支持高并发大数据量实时处理,完全可以支持实时弹幕的处理,实现对弹幕文本做筛除涉黄、涉政、垃圾评论、广告内容等的检测。
标签自动提取对于非热门行业适用吗?
达观标签自动提取功能可以利用行业数据进行模型训练和调整,在接入一个非热门行业服务之前,我们会以此行业的规范文本作为训练样本做模型训练,新的模型更新之后会适应此行业的个性化需求,而且在后期应用的过程模型会不断的更新迭代保证提取的结果与行业的发展保持同步。'''
for r in ['主要有','那些','哪些','\n','或','拥有','。',',','之前','以下','对于',';',':','、','会','我们','在此','之上',
'*','各','从''而且','一个','以此','作为','之后','当','进行','?','怎么','更多','可以',
'不','通过','吗', '也','可','但是','这种','遇到','则','就','对','等','很','做','中的','的'
]:
text = text.replace(r, 'DELIM')
words = [t.strip() for t in text.split('DELIM')]
words_filtered = list(filter(lambda a: a not in [''] and len(a) >1, words))
print(words_filtered)
7. 如何移除文本中的停用词 ?
难度等级 : L1
Q. 从文本中移除类似“我们”、“,”、“想要”、“一个”这样的无意义词汇和标点。
import jieba
text = "达观数据客户意见洞察平台对公司品牌进行负面舆情实时监测,事件演变趋势预测,预警实时触达,帮助公司市场及品牌部门第一时间发现负面舆情,及时应对危机公关,控制舆论走向,防止品牌受损。"
my_stopwords = [i.strip() for i in open('stop_words_zh.txt',encoding='utf-8').readlines()]
new_tokens=[]
# Tokenization using word_tokenize()
all_tokens=jieba.lcut(text)
for token in all_tokens:
if token not in my_stopwords:
new_tokens.append(token)
" ".join(new_tokens)
8. 如何进行词干化(stemming)?
难度等级 : L2
Q. 在给定的文本中,将每个词条(token)转换为它的词根形式(root form)。
# Stemming with nltk's PorterStemmer
from nltk.stem import PorterStemmer
stemmer=PorterStemmer()
stemmed_tokens=[]
text= '''
“哇,这个新来的boy真的super handsome!”,
“这个timetable做的not very good”,
“coffee 我们需要meet一下然后看看tomorrow怎么安排”,'''
for token in nltk.word_tokenize(text):
stemmed_tokens.append(stemmer.stem(token))
" ".join(stemmed_tokens)
9. 如何从邮箱号中抽取出姓名 ?
难度等级 : L2
Q. 利用正则从邮箱地址中抽取出姓名。
# Using regular expression to extract usernames
import re
text = '我的邮箱号是Scottish_folds_meow@gmail.com。'
usernames= re.findall('([^\u4E00-\u9FA5]\w.*)@', text,re.M|re.I)
print(usernames)
['Scottish_folds_meow']
10. 如何在排除停用词的情况下找出文中最常见的词汇?
难度等级 : L2
Q. 在启用停用词的情况下,抽取给定文本段落中的TOP10高频词汇。
import jieba
text = '''
文本挖掘主要有哪些功能
达观数据拥有多年的自然语言处理技术经验,掌握从词语短串到篇章分析个层面的分析技术,在此基础之上提供以下文本挖掘功能:
* 涉黄涉政检测:对文本内容做涉黄涉政检测,满足相应政策要求;
* 垃圾评论过滤:在论坛发言或用户评论中,过滤文本中的垃圾广告,提升文本总体质量;
* 情感分析:对用户评论等文本内容做情感分析,指导决策与运营;
* 自动标签提取:自动提取文本重要内容生成关键性标签,在此基础之上拓展更多功能形式;
* 文本自动分类:通过对文本内容进行分析,给出文本所属的类别和置信度,支持二级分类。
正常政治言论也会被过滤掉吗?
不会,达观对涉政内容会返回一个“反动”权值,取值范围0到1。当涉政内容的反动权值接近“1”时,文本的反动倾向很高,根据客户要求可以直接过滤掉,当反动权值接近“0”时,则文本为正常政治言论的几率就非常高,客户可通过反动权值控制审核松紧程度。
黄反内容、垃圾广告形式多样怎么处理?
传统的方法更多的是通过配词典的方式来解决。但是这种方法遇到变形文本时命中率很低,造成严重的漏盘,而且需要人工不断更新词典,效率很低。
达观数据通过机器学习的方法智能识别各种变形变换的内容,同时根据最新的样本数据实时更新运算模型,自动学习更新,保证检测的效果。
实时的弹幕能够做处理吗?
可以,达观数据文本挖掘系统支持高并发大数据量实时处理,完全可以支持实时弹幕的处理,实现对弹幕文本做筛除涉黄、涉政、垃圾评论、广告内容等的检测。
标签自动提取对于非热门行业适用吗?
达观标签自动提取功能可以利用行业数据进行模型训练和调整,在接入一个非热门行业服务之前,我们会以此行业的规范文本作为训练样本做模型训练,新的模型更新之后会适应此行业的个性化需求,而且在后期应用的过程模型会不断的更新迭代保证提取的结果与行业的发展保持同步。'''
my_stopwords = [i.strip() for i in open('stop_words_zh.txt',encoding='utf-8').readlines()]
new_tokens=[]
# Tokenization using word_tokenize()
all_tokens=jieba.lcut(text.strip(' ').replace('\n',''))
for token in all_tokens:
if len(token) >1: #仅关注词长大于1的词汇
if token not in my_stopwords:
new_tokens.append(token)
freq_dict={}
# Calculating frequency count
for word in new_tokens:
if word not in freq_dict:
freq_dict[word]=1
else:
freq_dict[word]+=1
sorted(freq_dict.items(),key = lambda x:x[1],reverse=True)[:20] #按照键进行降序排列,仅展示TOP20高频词汇
[('文本', 16),
('内容', 9),
('自动', 6),
('行业', 6),
('达观', 5),
('数据', 5),
('分析', 5),
('提取', 5),
('反动', 5),
('模型', 5),
('检测', 4),
('垃圾', 4),
('评论', 4),
('过滤', 4),
('标签', 4),
('权值', 4),
('更新', 4),
('挖掘', 3),
('功能', 3),
('涉政', 3)]
11. 如何对给定文本进行拼写纠错 ?¶
难度等级 : L2
Q. 通过训练具体领域的语言模型来纠正该领域文本中的拼写错误。
import re, collections
def words(text):
return re.findall('[\u4e00-\u9fa5_a-zA-Z]+', text.lower())
def train(features):
model = collections.defaultdict(lambda: 1)
for f in features:
model[f] += 1
return model
NWORDS = train(words(open('car_reviews.txt',encoding='utf-8').read()))
hanzi = open('hanzi.txt',encoding='utf-8').read()
def edits1(word):
splits = [(word[:i], word[i:]) for i in range(len(word) + 1)]
deletes = [a + b[1:] for a, b in splits if b]
transposes = [a + b[1] + b[0] + b[2:] for a, b in splits if len(b)>1]
replaces = [a + c + b[1:] for a, b in splits for c in hanzi if b]
inserts = [a + c + b for a, b in splits for c in hanzi]
return set(deletes + transposes + replaces + inserts)
def known_edits2(word):
return set(e2 for e1 in edits1(word) for e2 in edits1(e1) if e2 in NWORDS)
def known(words):
return set(w for w in words if w in NWORDS)
def correct(word):
candidates = known([word]) or known(edits1(word)) or known_edits2(word) or [word]
return max(candidates, key=NWORDS.get)
correct("后箱备")
'后备箱'
correct("油蚝量")12. 如何度量若干文本之间的余弦相似度(cosine similarity)?
难度等级 : L3
Q. 用sklearn中的文本特征抽取器CountVectorizer和TfidfVectorizer来实现文本相似度计算。
# Using Vectorizer of sklearn to get vector representation
import jieba
import pandas as pd
from sklearn.metrics.pairwise import cosine_similarity
from sklearn.feature_extraction.text import CountVectorizer,TfidfVectorizer
text1 = '涉黄涉政检测:对文本内容做涉黄涉政检测,满足相应政策要求'
text2 = '垃圾评论过滤:在论坛发言或用户评论中,过滤文本中的垃圾广告,提升文本总体质量'
text3 = '情感分析:对用户评论等文本内容做情感分析,指导决策与运营'
text4 = '自动标签提取:自动提取文本重要内容生成关键性标签,在此基础之上拓展更多功能形式'
text5 = '文本自动分类:通过对文本内容进行分析,给出文本所属的类别和置信度,支持二级分类。'
documents=[text1,text2,text3,text4,text5]
vectorizer = CountVectorizer(
stop_words= my_stopwords,
tokenizer =lambda x : ' '.join(jieba.lcut(x)))
matrix=vectorizer.fit_transform(documents)
# Obtaining the document-word matrix
doc_term_matrix=matrix.todense()
doc_term_matrix
# Computing cosine similarity
df = pd.DataFrame(doc_term_matrix)
print(cosine_similarity(df,df))
vectorizer = TfidfVectorizer(
stop_words= my_stopwords,
tokenizer =lambda x : ' '.join(jieba.lcut(x)))
matrix=vectorizer.fit_transform(documents)
# Obtaining the document-word matrix
doc_term_matrix=matrix.todense()
doc_term_matrix
# Computing cosine similarity
df = pd.DataFrame(doc_term_matrix)
print(cosine_similarity(df,df))
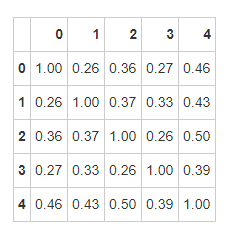
[[1. 0.60569101 0.62043724 0.59192176 0.62451717]
[0.60569101 1. 0.75529928 0.71314498 0.75758034]
[0.62043724 0.75529928 1. 0.69155057 0.78177146]
[0.59192176 0.71314498 0.69155057 1. 0.73255858]
[0.62451717 0.75758034 0.78177146 0.73255858 1. ]]
13. 如何计算文本间的soft cosine similarity("软性"余弦值) ?
难度等级 : L4
Q. 利用gensim中的计算文档间的"软性"余弦值。
import gensim
import jieba
from gensim.models import KeyedVectors
from gensim.similarities import termsim
from gensim import corpora
import numpy as np
import pandas as pd
from warnings import filterwarnings
filterwarnings('ignore')
print(gensim.__version__)
3.8.0
text1 = '涉黄涉政检测:对文本内容做涉黄涉政检测,满足相应政策要求'
text2 = '垃圾评论过滤:在论坛发言或用户评论中,过滤文本中的垃圾广告,提升文本总体质量'
text3 = '情感分析:对用户评论等文本内容做情感分析,指导决策与运营'
text4 = '自动标签提取:自动提取文本重要内容生成关键性标签,在此基础之上拓展更多功能形式'
text5 = '文本自动分类:通过对文本内容进行分析,给出文本所属的类别和置信度,支持二级分类。'
documents=[text1,text2,text3,text4,text5]
model = KeyedVectors.load_word2vec_format(r'E:\bpemb模型文件\zh\zh.wiki.bpe.vs200000.d300.w2v.bin', binary=True)
def simple_preprocess(text):
return jieba.lcut(text)
# Prepare a dictionary and a corpus.
dictionary = corpora.Dictionary([simple_preprocess(doc) for doc in documents])
# Prepare the similarity matrix
similarity_matrix = model.similarity_matrix(dictionary, tfidf=None, threshold=0.0, exponent=2.0, nonzero_limit=100)
# Convert the sentences into bag-of-words vectors.
sent_1 = dictionary.doc2bow(simple_preprocess(text1))
sent_2 = dictionary.doc2bow(simple_preprocess(text2))
sent_3 = dictionary.doc2bow(simple_preprocess(text3))
sent_4 = dictionary.doc2bow(simple_preprocess(text4))
sent_5 = dictionary.doc2bow(simple_preprocess(text5))
sentences = [sent_1, sent_2, sent_3, sent_4, sent_5]
# Compute soft cosine similarity
print(softcossim(sent_1, sent_2, similarity_matrix))
0.2575362240810525
#一口气算出所有文档之间的"软性"余弦值
def create_soft_cossim_matrix(sentences):
len_array = np.arange(len(sentences))
xx, yy = np.meshgrid(len_array, len_array)
cossim_mat = pd.DataFrame([[round(softcossim(sentences[i],sentences[j], similarity_matrix) ,2) for i, j in zip(x,y)] for y, x in zip(xx, yy)])
return cossim_mat
create_soft_cossim_matrix(sentences)
14.如何不通过词典找到某个词的相关词?¶
难度等级:L3
Q.利用词嵌入的手段找到某个词汇的相关词(近义词、反义词或者同语境词汇)。
from pymagnitude import *
vectors = Magnitude(r'E:\2020.09.04 基于wiki的词嵌入wikipedia2vec-master\百度百科.magnitude')
vectors.most_similar('自然语言')
15.如何度量两个词汇之间的相似度
Q.利用词汇之间的词向量的余弦值来度量词汇相似度。
from sklearn.metrics.pairwise import cosine_similarity
from pymagnitude import *
vectors = Magnitude(r'E:\2020.09.04 基于wiki的词嵌入wikipedia2vec-master\百度百科.magnitude')
def sklearn_cosine(x, y):
return cosine_similarity(x, y)
word1 = '倚马千言'
word2 = '才思敏捷'
word3 = '倚门倚闾'
word4 = '倚马七纸'
vector1 = vectors.query(word1).reshape(1,-1)
vector2 = vectors.query(word2).reshape(1,-1)
vector3 = vectors.query(word3).reshape(1,-1)
vector4 = vectors.query(word4).reshape(1,-1)
print("'倚马千言'和'才思敏捷'之间的余弦相似度:",sklearn_cosine(vector1 ,vector2)[0][0])
print("'倚马千言'和'倚门倚闾'之间的余弦相似度:",sklearn_cosine(vector1 ,vector3)[0][0])
print("'倚门倚闾'和'才思敏捷'之间的余弦相似度:",sklearn_cosine(vector3 ,vector2)[0][0])
print("'倚门千言'和'倚马七纸'之间的余弦相似度:",sklearn_cosine(vector1 ,vector4)[0][0])
print("'才思敏捷'和'倚马七纸'之间的余弦相似度:",sklearn_cosine(vector4 ,vector2)[0][0])
print("'倚门倚闾'和'倚马七纸'之间的余弦相似度:",sklearn_cosine(vector3 ,vector4)[0][0])
'倚马千言'和'才思敏捷'之间的余弦相似度: 0.6707871
'倚马千言'和'倚门倚闾'之间的余弦相似度: 0.40876597
'倚门倚闾'和'才思敏捷'之间的余弦相似度: 0.34079546
'倚门千言'和'倚马七纸'之间的余弦相似度: 0.8365689950912402
'才思敏捷'和'倚马七纸'之间的余弦相似度: 0.6443239906284672
'倚门倚闾'和'倚马七纸'之间的余弦相似度: 0.5506272158696582
16.如何度量两句话之间的相似度?
难度等级:L3
Q.通过度量两个文档向量之间的余弦夹角值来度量其语义相似度。
text1 = '文本挖掘实录:用文本挖掘剖析54万首诗歌'
text2 = '数据挖掘实操|用文本挖掘剖析近5万首《全唐诗》'
text3 = '以虎嗅网4W+文章的文本挖掘为例,展现数据分析的一整套流程'
text4 = '干货| 如何利用Social Listening从在线垂直社区提炼有价值的信息?'
# 使用 sklearn中的CountVectorizer来获取文档的向量化表示
import jieba
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
documents=[text1,text2,text3,text4]
my_stopwords = [i.strip() for i in open('stop_words_zh.txt',encoding='utf-8').readlines()]
vectorizer = TfidfVectorizer(
stop_words= my_stopwords,
tokenizer =lambda x : ' '.join(jieba.lcut(x)))
matrix=vectorizer.fit_transform(documents)
# 获取文档-词频矩阵
doc_term_matrix=matrix.todense()
doc_term_matrix
# 计算余弦相似值
df=pd.DataFrame(doc_term_matrix)
print(cosine_similarity(df,df))
###两两相似度结果:
# '文本挖掘实录:用文本挖掘剖析54万首诗歌','数据挖掘实操|用文本挖掘剖析近5万首《全唐诗》' 0.90711536
# '文本挖掘实录:用文本挖掘剖析54万首诗歌','以虎嗅网4W+文章的文本挖掘为例,展现数据分析的一整套流程' 0.80459625
# '数据挖掘实操|用文本挖掘剖析近5万首《全唐诗》','以虎嗅网4W+文章的文本挖掘为例,展现数据分析的一整套流程' 0.80541531
# '以虎嗅网4W+文章的文本挖掘为例,展现数据分析的一整套流程','干货| 如何利用Social Listening从在线垂直社区提炼有价值的信息?'0.72434468
# '文本挖掘实录:用文本挖掘剖析54万首诗歌','干货| 如何利用Social Listening从在线垂直社区提炼有价值的信息?' 0.70148463
[[1. 0.90711536 0.80459625 0.70148463]
[0.90711536 1. 0.80541531 0.73332658]
[0.80459625 0.80541531 1. 0.72434468]
[0.70148463 0.73332658 0.72434468 1. ]]
17. 如何计算给定的两段文本间的WMD距离(Word mover distance)?
难度等级: L3
Q. 通过词嵌入模型计算两段文本间的WMD(word mover distance)值 。
#通过gensim载入训练好的Word2Vec模型
import jieba
import itertools #用来进行两两语句对组合,且不重复
from gensim.models import KeyedVectors
model = KeyedVectors.load_word2vec_format(r'E:\bpemb模型文件\zh\zh.wiki.bpe.vs200000.d300.w2v.bin', binary=True)
sent1 = '印媒:印度借边境局势紧张之际 在拉达克测试新武器'
sent2 = "印度方向传来震耳枪响,一名士兵倒在血泊!军官承认已无能为力"
sent3 = '印度女演员宣称“为国家呐喊”,制片人怼“带几个人去打中国”'
sent4 = '印度边境附近军营传出枪响 一士兵举枪自尽倒在血泊中'
sent5 = '印度提高边境桥梁承重级别 能向拉达克调动更多T90'
sent6 ='四面楚歌!解放军在中印边境架大喇叭播放印度歌曲。'
origin_sents = [sent1,sent2,sent3,sent4,sent5,sent4]
sents = [jieba.lcut(i) for i in origin_sents]
# 计算上述6个文档间两两文档的 WMD距离(word mover distance),数值越大,表明两个语句间的语义相似度越低
for i,j in zip(itertools.combinations(sents, 2),itertools.combinations(origin_sents, 2)):
print('"{}"和"{}"之间的WMD距离为:'.format(j[0],j[1]),model.wmdistance(*i))
18.如何使用LSA模型抽取文本中的主题词?
难度等级 : L3
Q. 通过sklearn中的TruncatedSVD进行LSA(潜在语义分析,Latent Semantic Analysis)操作,从大段文本/大量文档中抽取主题关键词(topic keywords) 。
import jieba
from pyltp import SentenceSplitter
docs = '''9月9日,就在日本安倍政权接近尾声、新首相呼之欲出之际,印度国防秘书库马尔与日本驻印度大使铃木哲签署了《相互提供物资与劳务协定》,旨在通过印军和日本自卫队的后勤保障合作,加强双方协同能力和防务关系。根据协定,日本海上自卫队舰艇可以使用印度安达曼-尼科巴群岛的军事基地,印度海军则可以使用日本设在非洲之角国家吉布提的后勤保障基地。
9月9日,印度国防秘书库马尔与日本驻印度大使铃木哲签署了《相互提供物资与劳务协定》。
印度向来视印度洋为自家“后院”,伸入大洋的印度半岛有利于拓展其在印度洋的海上存在。连通苏伊士运河-红海-曼德海峡与马六甲海峡的北印度洋海域,又是海上航运繁忙的国际水道,贸易和战略价值十分重要,而印度恰好卡在这条航线的要冲地带。
在北印度洋,印度本土位于中间位置,并在东部安达曼-尼科巴群岛上设有司令部和军事基地,扼守马六甲海峡的西端。而在西部方向上,印度此前并没有什么抓手。印日后勤保障协议达成后,印度海军就可以利用吉布提的日本自卫队后勤基地,实现在曼德海峡-亚丁湾这一关键水域的常态化存在。
对日本来说,上述东西向航线中的任何一个节点,都事关海上贸易和能源安全,而这两项有都是关乎日本经济和国家安全的核心利益。能够利用印度安达曼-尼科巴群岛的基地,除了确保马六甲海峡航运安全,还可以利用其战略位置监视亚太地区其他大国西进印度洋的海上活动,进而充分发挥日本海上自卫队的实力,加强日本在美国印太战略中的关键作用。
《相互提供物资与劳务协定》是印日相互借力,以兑现自身远洋战略诉求的一次利益交换。类似的交换,印度在今年6月也有过一次,合作方是澳大利亚。6月初,印度总理莫迪与澳大利亚总理莫里森举行视频会晤,将双边关系提升为全面战略伙伴关系,发表了涉及印太地区海上合作愿景的联合声明,签署了包括《后勤相互保障协定》在内的7项协议。该协议允许双方舰机在对方港口和基地补充燃料、进行维修。
印澳、印日先后签署的后勤保障协议,被视为印太地区一个更广泛战略的组成部分,即以美国印太战略为总纲,以美日澳三角同盟关系为基础,通过美日澳印四角关系来构成印太战略的四大支点。
如果没有印度参与,印太战略就会存在明显短板,是个“瘸腿”战略,因而特朗普政府近年来不断加强美印军事合作,试图将美日澳同盟拓展为美日澳印准军事联盟,而这正合印度心意。
早在2016年8月,历经12年对话谈判,印度与美国签署《物流交换备忘录协定》。据此,印度可用美国设在吉布提、印度洋中部迪戈加西亚群岛、西太平洋关岛和菲律宾苏比克湾的基地,进行军事人员和装备的补给、维修和休整;美军舰机在必要时可使用印度的机场或港口。
2018年9月初,印美外长和防长“2+2会谈”期间,双方签署《通信兼容与安全协议》,为美国向印度出口加密通信安全设备铺平道路,包括在出口印度的武器装备上安装美军通信系统。近日有报道称,印度已批准与美国签署《共享地理空间国防情报协议》。另外,再加上印美之间的《基本交流与合作协议》,四大军事合作协议使得印美两国形成了事实上的准军事联盟关系。
特朗普政府的印太战略,其实是奥巴马时期“亚太再平衡”战略的扩展升级版,即突破亚太区域范畴,西进印度洋。这与印度近些年来推行的“东进战略”擦出火花,印度也一直想增加在亚太地区的存在感,尤其是通过插手地区热点敏感事务来提升自身影响力,以此彰显所谓大国地位。
印美这种战略上的一拍即合,促使双方得以迅速推进军事合作,连带着印日、印澳军事关系也显著提升,美日澳印还定期举行的“马拉巴尔”海上联合军演,这四国也已近乎形成准军事联盟。在这组关系中,印度舰艇和军机的活动范围得到扩展,还能从美国等国买到更先进的武器装备,进一步充实被称为“大杂烩”的印军装备。
2017年11月,时任新加坡国防部长黄永宏(后排左)访问印度,与时任印度国防部长西塔拉曼一起见证了两国《海上安全合作协议》的签署。
为了对付歼-20,印度斥巨资从法国引进一批“阵风”战机,但仍然无法与歼-20对抗。“阵风”是一款多用途双发中型战斗机,航程、机动性本就不如歼-20,多达14个武器挂载点更说明完全不具备隐身能力,在与歼-20对阵时很有可能还没发现对方就被击落。放眼全球,能支持印度空军与歼-20对抗的只有F-35,印度为何不采购呢?
根据JSF初始计划,F-35战机只能出售给参与研发的国家,按照财务支援、转移科技数量和分包合约确定获得战机的顺序。实现量产后,美国宣布扩大F-35出售范围,不仅项目参与国可以购买,一些未参与的友好国家也可获得购买资格,如印度、乌克兰。最新消息称,印度正在考虑引进F-35的利弊。
印度是俄罗斯军火的忠实客户,空军建设也以俄制战机为主,2016年才与法国达成引进“阵风”战机协议,从未装备或使用过美制战机。从性价比看,印度引进“阵风”非常不划算,单架战机价格达到2.4亿美元,几乎是F-35量产后的三倍,这笔资金完全可以引进大约100架F-35。另外,“阵风”还无法与歼-20对抗,战斗力仅相当于歼-16,因此引进F-35是个非常不错的选择。
不过,美国就出口F-35提出了一个非常苛刻的条件。由于印度未参与研发计划,需要在购机基础上增加一笔专利费,单机价格可能达到1.5亿美元,加上配套的武器、配件和地勤系统,以及训练飞行员的费用、运转费用,价格和采购“阵风”战机差不多。这是印度正在考虑的原因之一.
原因之二是,引进F-35后,印度空军维护机型种类将达到8种,覆盖俄制、法制、美制和国产四国机型,还需要额外建立一条维护体系和人员培养系统,会给后勤保障系统增加更大的压力。
原因之三是,印度正在进行AMCA战机研制计划。这是一款单座双发第五代隐形战斗机,用于取代现役的“幻影”2000和米格-29战机,前期已投入30亿美元研发费用,目前已经制造出模型,预计在2030年左右试飞。外形上,AMCA战机完全借鉴F-35,作战定位是填补LCA战机与苏-30MKI之间的空白,与F-35也非常接近。引进F-35意味着,印度必须在二者之间放弃一个,毫无疑问AMCA战机会被放弃。但是,印度对AMCA战机寄予厚望,在它身上投注了太多心血,突然间要放弃肯定是无法接受的。
不过,印度的准军事联盟朋友圈不止于美日澳,近年来印度还与法国、韩国、新加坡等国签署了类似的后勤保障协议。比如,印新2017年11月签署了《海上安全合作协议》,相互提供海军设施和后勤支持,这样一来印度就可以利用位于马六甲海峡东端的新加坡樟宜海军基地进行补给休整,从而实现从西端到东端对马六甲海峡的全监控,并可借此插手南海。
此外,印度与俄罗斯周年的《后勤互助协议》预计近期有望签署,这样一来印度就有可能利用俄方在北极地区的设施。印度与英国、越南的类似协议也在讨论中。但印度也有顾忌,这些军事合作既不能破坏自身外交自主和独立性,也不愿因此打破自己发起并奉行数十年的不结盟政策,同时还要在美俄等大国之间找平衡。'''
#从大段落中划分出若干语句
sentences = list(SentenceSplitter.split(docs))
#载入停用词
my_stopwords = [i.strip() for i in open('stop_words_zh.txt',encoding='utf-8').readlines()]
#分词和去停用词处理
sentence_pro = [' '.join([w.strip() for w in jieba.lcut(s) if w not in my_stopwords]) for s in sentences if len(s) >1]
# 从sklearn中导入Tf-idf文本特征抽取器
from sklearn.feature_extraction.text import TfidfVectorizer
# 定义Tf-idf文本特征抽取器
vectorizer = TfidfVectorizer(stop_words=my_stopwords, max_features= 1000, max_df = 0.4, smooth_idf=True)
# 通过.fit_transform()方法将tokens转化为文档-词汇矩阵
matrix= vectorizer.fit_transform(sentence_pro)
# 使用截断式SVD对文档-词汇矩阵进行分解,减小噪音
from sklearn.decomposition import TruncatedSVD
SVD_model = TruncatedSVD(n_components=5, algorithm='randomized', n_iter=1000, random_state=2020)
SVD_model.fit(matrix)
# 获取词组(即terms,字、词或者复合词)
terms = vectorizer.get_feature_names()
# 对每个topic中的主题词进行轮询
for i, comp in enumerate(SVD_model.components_):
terms_comp = zip(terms, comp)
# 找到每个主题中最为重要的10主题关键词
sorted_terms = sorted(terms_comp, key= lambda x:x[1], reverse=True)[:10]
print("Topic "+str(i)+": ")
#打印各个topic下的主题关键词
for t in sorted_terms:
print(t[0],end=' ')
print(' ')
Topic 0:
日本 战略 相互 签署 协定 协议 海上 提供 合作 印太
Topic 1:
日本 相互 劳务 物资 协定 提供 大使 库马尔 秘书 铃木
Topic 2:
印度洋 群岛 安达曼 尼科巴 使用 基地 马六甲海峡 海上 日本 军事基地
Topic 3:
战略 印太 亚太 政府 特朗普 印度洋 澳印 美日 西进 日本
Topic 4:
类似 交换 一次 今年 合作方 澳大利亚 英国 讨论 越南 战略
19.如何利用LDA抽取文本中的主题关键词?
# 载入 gensim, nltk
import gensim
from gensim import models, corpora
import nltk
from pprint import pprint
from nltk.corpus import stopwords
from gensim.models.ldamodel import LdaModel #针对文档-词频矩阵进行LDA主题建模
# 直接使用上面case的文本数据
all_tokens=[]
for text in sentence_pro:
tokens=[]
raw=nltk.wordpunct_tokenize(text)
for token in raw:
if token not in my_stopwords:
tokens.append(token)
all_tokens.append(tokens)
# 创建一个字典(dictionary)和 矩阵(matrix)
dictionary = corpora.Dictionary(all_tokens)
doc_term_matrix = [dictionary.doc2bow(doc) for doc in all_tokens]
model = LdaModel(doc_term_matrix, num_topics=5, id2word = dictionary,passes=40)
pprint(model.print_topics(num_topics=6,num_words=8))
[(0,
'0.042*"印度" + 0.040*"海上" + 0.035*"马六甲海峡" + 0.029*"利用" + 0.027*"安全" + '
'0.020*"东端" + 0.020*"月" + 0.018*"印度洋"'),
(1,
'0.039*"军事" + 0.033*"合作" + 0.033*"印美" + 0.024*"联盟" + 0.024*"准军事" + '
'0.024*"关系" + 0.024*"形成" + 0.024*"海上"'),
(2,
'0.054*"印度" + 0.030*"9" + 0.028*"签署" + 0.019*"日本" + 0.019*"合作" + 0.018*"协定" '
'+ 0.018*"相互" + 0.016*"协议"'),
(3,
'0.053*"战略" + 0.037*"印太" + 0.032*"关系" + 0.021*"-" + 0.020*"美国" + 0.018*"印度" '
'+ 0.018*"印日" + 0.016*"协议"'),
(4,
'0.065*"印度" + 0.029*"战略" + 0.019*"存在" + 0.016*"基地" + 0.016*"吉布提" + '
'0.015*"后勤保障" + 0.014*"群岛" + 0.014*"-"')]
20. 如何利用NMF抽取主题关键词?
难度等级: L3
Q.通过sklearn中的NMF方法进行NMF(Non-negative Matrix Factorization method,即非负矩阵分解)主题建模,从大段文本/大量文档中抽取主题关键词(topic keywords) 。
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.decomposition import NMF
# 定义Tf-idf文本特征抽取器
vectorizer = TfidfVectorizer(stop_words=my_stopwords, max_features= 1000, max_df = 0.4, smooth_idf=True)
# 通过.fit_transform()方法将tokens转化为文档-词汇矩阵
nmf_matrix= vectorizer.fit_transform(sentence_pro)
nmf_model = NMF(n_components=5)
nmf_model.fit(nmf_matrix)
# 定一个打印主题关键词的方法
def print_topics_nmf(model, vectorizer, top_n=5):
for idx, topic in enumerate(model.components_):
print("Topic %d:" % (idx+1))
print([(vectorizer.get_feature_names()[i], topic[i])
for i in topic.argsort()[:-top_n - 1:-1]])
print_topics_nmf(nmf_model,vectorizer)
21.如何方便快捷的对一句话进行情感正负面分析?
难度等级 : L0
Q. 使用SnowNLP对一句话进行情感正负面倾向分析。
from snownlp import SnowNLP
sentence = '印度卢比获选“最差货币”!千亿投资撤离,经济恐倒退20年!'
s = SnowNLP(sentence)
print('【{}】的情感倾向为 *{}* '.format(sentence,['正面' if s.sentiments>0.5 else '负面'][0]))
【印度卢比获选“最差货币”!千亿投资撤离,经济恐倒退20年!】的情感倾向为 *负面*
22.如何使用Doc2Vec来获取语句表示?
难度等级: L2
Q.使用gensim中的Doc2Vec训练模型,来获取优于word2vec的语句表示。
import jieba
from pyltp import SentenceSplitter
docs = '''9月9日,就在日本安倍政权接近尾声、新首相呼之欲出之际,印度国防秘书库马尔与日本驻印度大使铃木哲签署了《相互提供物资与劳务协定》,旨在通过印军和日本自卫队的后勤保障合作,加强双方协同能力和防务关系。根据协定,日本海上自卫队舰艇可以使用印度安达曼-尼科巴群岛的军事基地,印度海军则可以使用日本设在非洲之角国家吉布提的后勤保障基地。
9月9日,印度国防秘书库马尔与日本驻印度大使铃木哲签署了《相互提供物资与劳务协定》。
印度向来视印度洋为自家“后院”,伸入大洋的印度半岛有利于拓展其在印度洋的海上存在。连通苏伊士运河-红海-曼德海峡与马六甲海峡的北印度洋海域,又是海上航运繁忙的国际水道,贸易和战略价值十分重要,而印度恰好卡在这条航线的要冲地带。
在北印度洋,印度本土位于中间位置,并在东部安达曼-尼科巴群岛上设有司令部和军事基地,扼守马六甲海峡的西端。而在西部方向上,印度此前并没有什么抓手。印日后勤保障协议达成后,印度海军就可以利用吉布提的日本自卫队后勤基地,实现在曼德海峡-亚丁湾这一关键水域的常态化存在。
对日本来说,上述东西向航线中的任何一个节点,都事关海上贸易和能源安全,而这两项有都是关乎日本经济和国家安全的核心利益。能够利用印度安达曼-尼科巴群岛的基地,除了确保马六甲海峡航运安全,还可以利用其战略位置监视亚太地区其他大国西进印度洋的海上活动,进而充分发挥日本海上自卫队的实力,加强日本在美国印太战略中的关键作用。
《相互提供物资与劳务协定》是印日相互借力,以兑现自身远洋战略诉求的一次利益交换。类似的交换,印度在今年6月也有过一次,合作方是澳大利亚。6月初,印度总理莫迪与澳大利亚总理莫里森举行视频会晤,将双边关系提升为全面战略伙伴关系,发表了涉及印太地区海上合作愿景的联合声明,签署了包括《后勤相互保障协定》在内的7项协议。该协议允许双方舰机在对方港口和基地补充燃料、进行维修。
印澳、印日先后签署的后勤保障协议,被视为印太地区一个更广泛战略的组成部分,即以美国印太战略为总纲,以美日澳三角同盟关系为基础,通过美日澳印四角关系来构成印太战略的四大支点。
如果没有印度参与,印太战略就会存在明显短板,是个“瘸腿”战略,因而特朗普政府近年来不断加强美印军事合作,试图将美日澳同盟拓展为美日澳印准军事联盟,而这正合印度心意。
早在2016年8月,历经12年对话谈判,印度与美国签署《物流交换备忘录协定》。据此,印度可用美国设在吉布提、印度洋中部迪戈加西亚群岛、西太平洋关岛和菲律宾苏比克湾的基地,进行军事人员和装备的补给、维修和休整;美军舰机在必要时可使用印度的机场或港口。
2018年9月初,印美外长和防长“2+2会谈”期间,双方签署《通信兼容与安全协议》,为美国向印度出口加密通信安全设备铺平道路,包括在出口印度的武器装备上安装美军通信系统。近日有报道称,印度已批准与美国签署《共享地理空间国防情报协议》。另外,再加上印美之间的《基本交流与合作协议》,四大军事合作协议使得印美两国形成了事实上的准军事联盟关系。
特朗普政府的印太战略,其实是奥巴马时期“亚太再平衡”战略的扩展升级版,即突破亚太区域范畴,西进印度洋。这与印度近些年来推行的“东进战略”擦出火花,印度也一直想增加在亚太地区的存在感,尤其是通过插手地区热点敏感事务来提升自身影响力,以此彰显所谓大国地位。
印美这种战略上的一拍即合,促使双方得以迅速推进军事合作,连带着印日、印澳军事关系也显著提升,美日澳印还定期举行的“马拉巴尔”海上联合军演,这四国也已近乎形成准军事联盟。在这组关系中,印度舰艇和军机的活动范围得到扩展,还能从美国等国买到更先进的武器装备,进一步充实被称为“大杂烩”的印军装备。
2017年11月,时任新加坡国防部长黄永宏(后排左)访问印度,与时任印度国防部长西塔拉曼一起见证了两国《海上安全合作协议》的签署。
为了对付歼-20,印度斥巨资从法国引进一批“阵风”战机,但仍然无法与歼-20对抗。“阵风”是一款多用途双发中型战斗机,航程、机动性本就不如歼-20,多达14个武器挂载点更说明完全不具备隐身能力,在与歼-20对阵时很有可能还没发现对方就被击落。放眼全球,能支持印度空军与歼-20对抗的只有F-35,印度为何不采购呢?
根据JSF初始计划,F-35战机只能出售给参与研发的国家,按照财务支援、转移科技数量和分包合约确定获得战机的顺序。实现量产后,美国宣布扩大F-35出售范围,不仅项目参与国可以购买,一些未参与的友好国家也可获得购买资格,如印度、乌克兰。最新消息称,印度正在考虑引进F-35的利弊。
印度是俄罗斯军火的忠实客户,空军建设也以俄制战机为主,2016年才与法国达成引进“阵风”战机协议,从未装备或使用过美制战机。从性价比看,印度引进“阵风”非常不划算,单架战机价格达到2.4亿美元,几乎是F-35量产后的三倍,这笔资金完全可以引进大约100架F-35。另外,“阵风”还无法与歼-20对抗,战斗力仅相当于歼-16,因此引进F-35是个非常不错的选择。
不过,美国就出口F-35提出了一个非常苛刻的条件。由于印度未参与研发计划,需要在购机基础上增加一笔专利费,单机价格可能达到1.5亿美元,加上配套的武器、配件和地勤系统,以及训练飞行员的费用、运转费用,价格和采购“阵风”战机差不多。这是印度正在考虑的原因之一.
原因之二是,引进F-35后,印度空军维护机型种类将达到8种,覆盖俄制、法制、美制和国产四国机型,还需要额外建立一条维护体系和人员培养系统,会给后勤保障系统增加更大的压力。
原因之三是,印度正在进行AMCA战机研制计划。这是一款单座双发第五代隐形战斗机,用于取代现役的“幻影”2000和米格-29战机,前期已投入30亿美元研发费用,目前已经制造出模型,预计在2030年左右试飞。外形上,AMCA战机完全借鉴F-35,作战定位是填补LCA战机与苏-30MKI之间的空白,与F-35也非常接近。引进F-35意味着,印度必须在二者之间放弃一个,毫无疑问AMCA战机会被放弃。但是,印度对AMCA战机寄予厚望,在它身上投注了太多心血,突然间要放弃肯定是无法接受的。
不过,印度的准军事联盟朋友圈不止于美日澳,近年来印度还与法国、韩国、新加坡等国签署了类似的后勤保障协议。比如,印新2017年11月签署了《海上安全合作协议》,相互提供海军设施和后勤支持,这样一来印度就可以利用位于马六甲海峡东端的新加坡樟宜海军基地进行补给休整,从而实现从西端到东端对马六甲海峡的全监控,并可借此插手南海。
此外,印度与俄罗斯周年的《后勤互助协议》预计近期有望签署,这样一来印度就有可能利用俄方在北极地区的设施。印度与英国、越南的类似协议也在讨论中。但印度也有顾忌,这些军事合作既不能破坏自身外交自主和独立性,也不愿因此打破自己发起并奉行数十年的不结盟政策,同时还要在美俄等大国之间找平衡。'''
#从大段落中划分出若干语句
sentences = list(SentenceSplitter.split(docs))
#载入停用词
my_stopwords = [i.strip() for i in open('stop_words_zh.txt',encoding='utf-8').readlines()]
#分词和去停用词处理
sentence_pro = [' '.join([w.strip() for w in jieba.lcut(s) if w not in my_stopwords]) for s in sentences if len(s) >1]
# 载入模型
from gensim.models import Doc2Vec
# 按Doc2vec适配的数据格式进行训练,需要定义一个处理方法
def tagged_document(list_of_list_of_words):
for i, list_of_words in enumerate(list_of_list_of_words):
yield gensim.models.doc2vec.TaggedDocument(list_of_words, [i])
my_data = list(tagged_document(sentence_pro))
model=Doc2Vec(my_data)
sentence_representation = model.infer_vector(jieba.lcut('美日澳印还定期举行的“马拉巴尔”海上联合军演,这四国也已近乎形成准军事联盟'))
sentence_representation
array([-5.55146951e-03, -4.09128377e-04, 9.98128671e-03, -1.61631079e-03,
-1.09040793e-02, -2.49802368e-03, -4.91932034e-03, -5.54430950e-03,
1.29141295e-02, -9.19324253e-03, 4.41139610e-03, -6.34658104e-03,
...,
7.91305490e-03, -6.71930658e-03, 6.49949070e-05, -1.00128038e-03],
dtype=float32)
23.如何抽取某段文本的TF-IDF矩阵 ?
难度等级 : L3
Q. 使用sklearn或者gensim抽取文本的TF-IDF (Term Frequency -Inverse Document Frequency,即词频-逆向文件频率) 矩阵。
import jiebafrom pyltp import SentenceSplitterdocs = '''9月9日,就在日本安倍政权接近尾声、新首相呼之欲出之际,印度国防秘书库马尔与日本驻印度大使铃木哲签署了《相互提供物资与劳务协定》,旨在通过印军和日本自卫队的后勤保障合作,加强双方协同能力和防务关系。根据协定,日本海上自卫队舰艇可以使用印度安达曼-尼科巴群岛的军事基地,印度海军则可以使用日本设在非洲之角国家吉布提的后勤保障基地。9月9日,印度国防秘书库马尔与日本驻印度大使铃木哲签署了《相互提供物资与劳务协定》。印度向来视印度洋为自家“后院”,伸入大洋的印度半岛有利于拓展其在印度洋的海上存在。连通苏伊士运河-红海-曼德海峡与马六甲海峡的北印度洋海域,又是海上航运繁忙的国际水道,贸易和战略价值十分重要,而印度恰好卡在这条航线的要冲地带。在北印度洋,印度本土位于中间位置,并在东部安达曼-尼科巴群岛上设有司令部和军事基地,扼守马六甲海峡的西端。而在西部方向上,印度此前并没有什么抓手。印日后勤保障协议达成后,印度海军就可以利用吉布提的日本自卫队后勤基地,实现在曼德海峡-亚丁湾这一关键水域的常态化存在。对日本来说,上述东西向航线中的任何一个节点,都事关海上贸易和能源安全,而这两项有都是关乎日本经济和国家安全的核心利益。能够利用印度安达曼-尼科巴群岛的基地,除了确保马六甲海峡航运安全,还可以利用其战略位置监视亚太地区其他大国西进印度洋的海上活动,进而充分发挥日本海上自卫队的实力,加强日本在美国印太战略中的关键作用。《相互提供物资与劳务协定》是印日相互借力,以兑现自身远洋战略诉求的一次利益交换。类似的交换,印度在今年6月也有过一次,合作方是澳大利亚。6月初,印度总理莫迪与澳大利亚总理莫里森举行视频会晤,将双边关系提升为全面战略伙伴关系,发表了涉及印太地区海上合作愿景的联合声明,签署了包括《后勤相互保障协定》在内的7项协议。该协议允许双方舰机在对方港口和基地补充燃料、进行维修。印澳、印日先后签署的后勤保障协议,被视为印太地区一个更广泛战略的组成部分,即以美国印太战略为总纲,以美日澳三角同盟关系为基础,通过美日澳印四角关系来构成印太战略的四大支点。如果没有印度参与,印太战略就会存在明显短板,是个“瘸腿”战略,因而特朗普政府近年来不断加强美印军事合作,试图将美日澳同盟拓展为美日澳印准军事联盟,而这正合印度心意。早在2016年8月,历经12年对话谈判,印度与美国签署《物流交换备忘录协定》。据此,印度可用美国设在吉布提、印度洋中部迪戈加西亚群岛、西太平洋关岛和菲律宾苏比克湾的基地,进行军事人员和装备的补给、维修和休整;美军舰机在必要时可使用印度的机场或港口。2018年9月初,印美外长和防长“2+2会谈”期间,双方签署《通信兼容与安全协议》,为美国向印度出口加密通信安全设备铺平道路,包括在出口印度的武器装备上安装美军通信系统。近日有报道称,印度已批准与美国签署《共享地理空间国防情报协议》。另外,再加上印美之间的《基本交流与合作协议》,四大军事合作协议使得印美两国形成了事实上的准军事联盟关系。特朗普政府的印太战略,其实是奥巴马时期“亚太再平衡”战略的扩展升级版,即突破亚太区域范畴,西进印度洋。这与印度近些年来推行的“东进战略”擦出火花,印度也一直想增加在亚太地区的存在感,尤其是通过插手地区热点敏感事务来提升自身影响力,以此彰显所谓大国地位。印美这种战略上的一拍即合,促使双方得以迅速推进军事合作,连带着印日、印澳军事关系也显著提升,美日澳印还定期举行的“马拉巴尔”海上联合军演,这四国也已近乎形成准军事联盟。在这组关系中,印度舰艇和军机的活动范围得到扩展,还能从美国等国买到更先进的武器装备,进一步充实被称为“大杂烩”的印军装备。2017年11月,时任新加坡国防部长黄永宏(后排左)访问印度,与时任印度国防部长西塔拉曼一起见证了两国《海上安全合作协议》的签署。为了对付歼-20,印度斥巨资从法国引进一批“阵风”战机,但仍然无法与歼-20对抗。“阵风”是一款多用途双发中型战斗机,航程、机动性本就不如歼-20,多达14个武器挂载点更说明完全不具备隐身能力,在与歼-20对阵时很有可能还没发现对方就被击落。放眼全球,能支持印度空军与歼-20对抗的只有F-35,印度为何不采购呢?根据JSF初始计划,F-35战机只能出售给参与研发的国家,按照财务支援、转移科技数量和分包合约确定获得战机的顺序。实现量产后,美国宣布扩大F-35出售范围,不仅项目参与国可以购买,一些未参与的友好国家也可获得购买资格,如印度、乌克兰。最新消息称,印度正在考虑引进F-35的利弊。印度是俄罗斯军火的忠实客户,空军建设也以俄制战机为主,2016年才与法国达成引进“阵风”战机协议,从未装备或使用过美制战机。从性价比看,印度引进“阵风”非常不划算,单架战机价格达到2.4亿美元,几乎是F-35量产后的三倍,这笔资金完全可以引进大约100架F-35。另外,“阵风”还无法与歼-20对抗,战斗力仅相当于歼-16,因此引进F-35是个非常不错的选择。不过,美国就出口F-35提出了一个非常苛刻的条件。由于印度未参与研发计划,需要在购机基础上增加一笔专利费,单机价格可能达到1.5亿美元,加上配套的武器、配件和地勤系统,以及训练飞行员的费用、运转费用,价格和采购“阵风”战机差不多。这是印度正在考虑的原因之一.原因之二是,引进F-35后,印度空军维护机型种类将达到8种,覆盖俄制、法制、美制和国产四国机型,还需要额外建立一条维护体系和人员培养系统,会给后勤保障系统增加更大的压力。原因之三是,印度正在进行AMCA战机研制计划。这是一款单座双发第五代隐形战斗机,用于取代现役的“幻影”2000和米格-29战机,前期已投入30亿美元研发费用,目前已经制造出模型,预计在2030年左右试飞。外形上,AMCA战机完全借鉴F-35,作战定位是填补LCA战机与苏-30MKI之间的空白,与F-35也非常接近。引进F-35意味着,印度必须在二者之间放弃一个,毫无疑问AMCA战机会被放弃。但是,印度对AMCA战机寄予厚望,在它身上投注了太多心血,突然间要放弃肯定是无法接受的。不过,印度的准军事联盟朋友圈不止于美日澳,近年来印度还与法国、韩国、新加坡等国签署了类似的后勤保障协议。比如,印新2017年11月签署了《海上安全合作协议》,相互提供海军设施和后勤支持,这样一来印度就可以利用位于马六甲海峡东端的新加坡樟宜海军基地进行补给休整,从而实现从西端到东端对马六甲海峡的全监控,并可借此插手南海。此外,印度与俄罗斯周年的《后勤互助协议》预计近期有望签署,这样一来印度就有可能利用俄方在北极地区的设施。印度与英国、越南的类似协议也在讨论中。但印度也有顾忌,这些军事合作既不能破坏自身外交自主和独立性,也不愿因此打破自己发起并奉行数十年的不结盟政策,同时还要在美俄等大国之间找平衡。'''#从大段落中划分出若干语句sentences = list(SentenceSplitter.split(docs))#载入停用词my_stopwords = [i.strip() for i in open('stop_words_zh.txt',encoding='utf-8').readlines()]#分词和去停用词处理doc_tokenized = [[w.strip() for w in jieba.lcut(s) if w not in my_stopwords] for s in sentences if len(s) >1]import numpy as npfrom gensim import corporafrom gensim.utils import simple_preprocessdictionary = corpora.Dictionary()# Creating the Bag of Words from the docsBoW_corpus = [dictionary.doc2bow(doc, allow_update=True) for doc in doc_tokenized]tfidf = models.TfidfModel(BoW_corpus)#获取其中一个语句的TF-IDF句向量表示tfidf[BoW_corpus[4]]
[(8, 0.0170149740424658),
(37, 0.11546380233219157),
(45, 0.09690055545816822),
(54, 0.1198127494227414),
(62, 0.22106225197145943),
(63, 0.18189359767938695),
(64, 0.22106225197145943),
(65, 0.22106225197145943),
(66, 0.22106225197145943),
(67, 0.22106225197145943),
(68, 0.22106225197145943),
(69, 0.10355628909524209),
(70, 0.18189359767938695),
(71, 0.22106225197145943),
(72, 0.22106225197145943),
(73, 0.18189359767938695),
(74, 0.22106225197145943),
(75, 0.22106225197145943),
(76, 0.18189359767938695),
(77, 0.18189359767938695),
(78, 0.22106225197145943),
(79, 0.22106225197145943),
(80, 0.18189359767938695),
(81, 0.22106225197145943),
(82, 0.22106225197145943),
(83, 0.22106225197145943),
(84, 0.14272494338731456)]
方法2- 使用sklearn中TfidfVectorizer:
from sklearn.feature_extraction.text import TfidfVectorizer# Fit the vectorizer to our text documentsvectorizer = TfidfVectorizer()matrix = vectorizer.fit_transform(sentence_pro)print(matrix)
(0, 97) 0.14076663372332268
(0, 493) 0.19982631806229104
(0, 401) 0.18071125647638306
(0, 130) 0.19982631806229104
(0, 154) 0.15662912693506145
(0, 124) 0.16714890444630287
: :
(49, 164) 0.15522035939646828
(49, 140) 0.07346311658441326
24.如何使用gensim中的Phraser来抽取bigrams(双词组合) ?
难度等级: L3
Q. 基于统计方法从大段文本中抽取常用词组(至少两个词汇复合而成)表达。
import jiebafrom pyltp import SentenceSplitterdocs = '''9月9日,就在日本安倍政权接近尾声、新首相呼之欲出之际,印度国防秘书库马尔与日本驻印度大使铃木哲签署了《相互提供物资与劳务协定》,旨在通过印军和日本自卫队的后勤保障合作,加强双方协同能力和防务关系。根据协定,日本海上自卫队舰艇可以使用印度安达曼-尼科巴群岛的军事基地,印度海军则可以使用日本设在非洲之角国家吉布提的后勤保障基地。9月9日,印度国防秘书库马尔与日本驻印度大使铃木哲签署了《相互提供物资与劳务协定》。印度向来视印度洋为自家“后院”,伸入大洋的印度半岛有利于拓展其在印度洋的海上存在。连通苏伊士运河-红海-曼德海峡与马六甲海峡的北印度洋海域,又是海上航运繁忙的国际水道,贸易和战略价值十分重要,而印度恰好卡在这条航线的要冲地带。在北印度洋,印度本土位于中间位置,并在东部安达曼-尼科巴群岛上设有司令部和军事基地,扼守马六甲海峡的西端。而在西部方向上,印度此前并没有什么抓手。印日后勤保障协议达成后,印度海军就可以利用吉布提的日本自卫队后勤基地,实现在曼德海峡-亚丁湾这一关键水域的常态化存在。对日本来说,上述东西向航线中的任何一个节点,都事关海上贸易和能源安全,而这两项有都是关乎日本经济和国家安全的核心利益。能够利用印度安达曼-尼科巴群岛的基地,除了确保马六甲海峡航运安全,还可以利用其战略位置监视亚太地区其他大国西进印度洋的海上活动,进而充分发挥日本海上自卫队的实力,加强日本在美国印太战略中的关键作用。《相互提供物资与劳务协定》是印日相互借力,以兑现自身远洋战略诉求的一次利益交换。类似的交换,印度在今年6月也有过一次,合作方是澳大利亚。6月初,印度总理莫迪与澳大利亚总理莫里森举行视频会晤,将双边关系提升为全面战略伙伴关系,发表了涉及印太地区海上合作愿景的联合声明,签署了包括《后勤相互保障协定》在内的7项协议。该协议允许双方舰机在对方港口和基地补充燃料、进行维修。印澳、印日先后签署的后勤保障协议,被视为印太地区一个更广泛战略的组成部分,即以美国印太战略为总纲,以美日澳三角同盟关系为基础,通过美日澳印四角关系来构成印太战略的四大支点。如果没有印度参与,印太战略就会存在明显短板,是个“瘸腿”战略,因而特朗普政府近年来不断加强美印军事合作,试图将美日澳同盟拓展为美日澳印准军事联盟,而这正合印度心意。早在2016年8月,历经12年对话谈判,印度与美国签署《物流交换备忘录协定》。据此,印度可用美国设在吉布提、印度洋中部迪戈加西亚群岛、西太平洋关岛和菲律宾苏比克湾的基地,进行军事人员和装备的补给、维修和休整;美军舰机在必要时可使用印度的机场或港口。2018年9月初,印美外长和防长“2+2会谈”期间,双方签署《通信兼容与安全协议》,为美国向印度出口加密通信安全设备铺平道路,包括在出口印度的武器装备上安装美军通信系统。近日有报道称,印度已批准与美国签署《共享地理空间国防情报协议》。另外,再加上印美之间的《基本交流与合作协议》,四大军事合作协议使得印美两国形成了事实上的准军事联盟关系。特朗普政府的印太战略,其实是奥巴马时期“亚太再平衡”战略的扩展升级版,即突破亚太区域范畴,西进印度洋。这与印度近些年来推行的“东进战略”擦出火花,印度也一直想增加在亚太地区的存在感,尤其是通过插手地区热点敏感事务来提升自身影响力,以此彰显所谓大国地位。印美这种战略上的一拍即合,促使双方得以迅速推进军事合作,连带着印日、印澳军事关系也显著提升,美日澳印还定期举行的“马拉巴尔”海上联合军演,这四国也已近乎形成准军事联盟。在这组关系中,印度舰艇和军机的活动范围得到扩展,还能从美国等国买到更先进的武器装备,进一步充实被称为“大杂烩”的印军装备。2017年11月,时任新加坡国防部长黄永宏(后排左)访问印度,与时任印度国防部长西塔拉曼一起见证了两国《海上安全合作协议》的签署。为了对付歼-20,印度斥巨资从法国引进一批“阵风”战机,但仍然无法与歼-20对抗。“阵风”是一款多用途双发中型战斗机,航程、机动性本就不如歼-20,多达14个武器挂载点更说明完全不具备隐身能力,在与歼-20对阵时很有可能还没发现对方就被击落。放眼全球,能支持印度空军与歼-20对抗的只有F-35,印度为何不采购呢?根据JSF初始计划,F-35战机只能出售给参与研发的国家,按照财务支援、转移科技数量和分包合约确定获得战机的顺序。实现量产后,美国宣布扩大F-35出售范围,不仅项目参与国可以购买,一些未参与的友好国家也可获得购买资格,如印度、乌克兰。最新消息称,印度正在考虑引进F-35的利弊。印度是俄罗斯军火的忠实客户,空军建设也以俄制战机为主,2016年才与法国达成引进“阵风”战机协议,从未装备或使用过美制战机。从性价比看,印度引进“阵风”非常不划算,单架战机价格达到2.4亿美元,几乎是F-35量产后的三倍,这笔资金完全可以引进大约100架F-35。另外,“阵风”还无法与歼-20对抗,战斗力仅相当于歼-16,因此引进F-35是个非常不错的选择。不过,美国就出口F-35提出了一个非常苛刻的条件。由于印度未参与研发计划,需要在购机基础上增加一笔专利费,单机价格可能达到1.5亿美元,加上配套的武器、配件和地勤系统,以及训练飞行员的费用、运转费用,价格和采购“阵风”战机差不多。这是印度正在考虑的原因之一.原因之二是,引进F-35后,印度空军维护机型种类将达到8种,覆盖俄制、法制、美制和国产四国机型,还需要额外建立一条维护体系和人员培养系统,会给后勤保障系统增加更大的压力。原因之三是,印度正在进行AMCA战机研制计划。这是一款单座双发第五代隐形战斗机,用于取代现役的“幻影”2000和米格-29战机,前期已投入30亿美元研发费用,目前已经制造出模型,预计在2030年左右试飞。外形上,AMCA战机完全借鉴F-35,作战定位是填补LCA战机与苏-30MKI之间的空白,与F-35也非常接近。引进F-35意味着,印度必须在二者之间放弃一个,毫无疑问AMCA战机会被放弃。但是,印度对AMCA战机寄予厚望,在它身上投注了太多心血,突然间要放弃肯定是无法接受的。不过,印度的准军事联盟朋友圈不止于美日澳,近年来印度还与法国、韩国、新加坡等国签署了类似的后勤保障协议。比如,印新2017年11月签署了《海上安全合作协议》,相互提供海军设施和后勤支持,这样一来印度就可以利用位于马六甲海峡东端的新加坡樟宜海军基地进行补给休整,从而实现从西端到东端对马六甲海峡的全监控,并可借此插手南海。此外,印度与俄罗斯周年的《后勤互助协议》预计近期有望签署,这样一来印度就有可能利用俄方在北极地区的设施。印度与英国、越南的类似协议也在讨论中。但印度也有顾忌,这些军事合作既不能破坏自身外交自主和独立性,也不愿因此打破自己发起并奉行数十年的不结盟政策,同时还要在美俄等大国之间找平衡。'''#从大段落中划分出若干语句sentences = list(SentenceSplitter.split(docs))#载入停用词my_stopwords = [i.strip() for i in open('stop_words_zh.txt',encoding='utf-8').readlines()]#分词和去停用词处理sentence_stream = [[w.strip() for w in jieba.lcut(s) if w not in my_stopwords] for s in sentences if len(s) >1]
# 从gensim中导入Phraser
from gensim.models import Phrases
from gensim.models.phrases import Phraser
# 创建一个bigram phraser
bigram = Phrases(sentence_stream, min_count=1, threshold=8, delimiter=b'_')
bigram_phraser = Phraser(bigram)
for sent in sentence_stream:
tokens_ = bigram_phraser[sent]
print([i.strip() for i in tokens_ if i.find('_')>0]) #看看经由bigram phraser产生了哪些新的词组
['9_月', '9_日', '印度_国防', '秘书_库马尔', '日本_驻', '印度_大使', '铃木_哲', '签署_相互', '提供_物资', '劳务_协定']
['日本_海上', '印度_安达曼', '-_尼科巴', '印度_海军']
['9_月', '9_日', '印度_国防', '秘书_库马尔', '日本_驻', '印度_大使', '铃木_哲', '签署_相互', '提供_物资', '劳务_协定']
['印度洋_海上']
['曼德_海峡', '北_印度洋']
...
['AMCA_战机', 'F_-', 'F_-', '35_非常']
['引进_F', '-_35', 'AMCA_战机']
['AMCA_战机']
['准军事_联盟', '后勤保障_协议']
['2017_年', '11_月', '海上_安全', '合作_协议', '相互_提供', '这样一来_印度']
['印度_俄罗斯', '这样一来_印度']
['军事_合作']
25.如实使用nltk中的ngrams来创建bigrams、trigrams?
难度等级: L3
Q. 利用nktk中华的ngrams方法从大段文本中抽取bigrams 和trigrams(三个词汇复合而成的词汇) 。
# 创建 bigrams and trigrams
from nltk import ngrams
bigram=list(ngrams(sentence_stream[1],2))
trigram=list(ngrams(sentence_stream[1],3))
print(" Bigrams are:\n",bigram)
print("---"*40)
print(" Trigrams are:\n", trigram)
26.如何利用bert抽取语句表示进行语句相似度比较¶
难度等级:L6
Q.使用BERT模型抽取文本中各个token的嵌入表示,取其中隐藏层的特征,将其平均,得到句向量。
import numpy as np
import torch
from transformers import BertModel, BertTokenizer
from scipy.spatial.distance import cosine
def get_word_indeces(tokenizer, text, word):
'''
确定 "text "中与 "word "相对应的标记的index或indeces。`word`可以由多个字词复合而成,如 "数据分析(数据+分析)"。
确定indeces是很棘手的,因为一个词汇可能会被分解成多个token。
我用一种比较迂回的方法解决了这个问题--我用一定数量的`[MASK]`的token代替`word`,然后在词条化(tokenization)结果中找到这些token。
'''
# 将'word'词条化--它可以被分解成多个词条(token)或子词(subword)
word_tokens = tokenizer.tokenize(word)
# 创建一个"[MASK]"词条序列来代替 "word"
masks_str = ' '.join(['[MASK]']*len(word_tokens))
#将"word"替换为 mask词条
text_masked = text.replace(word, masks_str)
# `encode`环节同时执行如下功能:
# 1. 将文本词条化
# 2. 将词条映射到其对应的id
# 3. 增加特殊的token,主要是 [CLS] 和 [SEP]
input_ids = tokenizer.encode(text_masked)
# 使用numpy的`where`函数来查找[MASK]词条的所有indeces
mask_token_indeces = np.where(np.array(input_ids) == tokenizer.mask_token_id)[0]
return mask_token_indeces
def get_embedding(b_model, b_tokenizer, text, word=''):
'''
使用指定的model和tokenizer对喂进来的文本和词进行句嵌入或者词汇语境嵌入输出。
'''
# 如果提供了一个词,找出与之对应的token
if not word == '':
word_indeces = get_word_indeces(b_tokenizer, text, word)
# 对文本进行编码,添加(必要的!)特殊token,并转换为PyTorch tensors
encoded_dict = b_tokenizer.encode_plus(
text, # 待encode的文本
add_special_tokens = True, # 增加特殊token ,加在句首和句尾添加'[CLS]' 和 '[SEP]'
return_tensors = 'pt', # 返回的数据格式为pytorch tensors
)
input_ids = encoded_dict['input_ids']
b_model.eval()
# 通过模型运行经编码后的文本以获得hidden states
bert_outputs = b_model(input_ids)
# 通过BERT运行经编码后的文本,集合所有12层产生的所有隐藏状态
with torch.no_grad():
outputs = b_model(input_ids)
# 根据之前`from_pretrained`调用中的配置方式,评估模型将返回不同数量的对象。
# 在这种情况下,因为我们设置了`output_hidden_states = True`,
# 第三项将是所有层的隐藏状态。更多细节请参见文档。
# https://huggingface.co/transformers/model_doc/bert.html#bertmodel
hidden_states = outputs[2]
# `hidden_states`的shape是 [13 x 1 x <文本长度> x 768]
# 选择第二层到最后一层的嵌入,`token_vecs` 是一个形如[<文本长度> x 768]的tensor
token_vecs = hidden_states[-2][0]
# 计算所有token向量的平均值
sentence_embedding = torch.mean(token_vecs, dim=0)
# 将上述token平均嵌入向量转化为numpy array
sentence_embedding = sentence_embedding.detach().numpy()
# 如果提供了`word`,计算其token的嵌入。
if not word == '':
# 假如是词长大于等于2的词汇,取`word`T中token嵌入的平均值
word_embedding = torch.mean(token_vecs[word_indeces], dim=0)
# 转化为numpy array
word_embedding = word_embedding.detach().numpy()
return (sentence_embedding, word_embedding)
else:
return sentence_embedding
bert_model = BertModel.from_pretrained(r"E:\2020.09.07 pytorch_pretrained_models\bert-sim-chinese",
output_hidden_states=True)
bert_tokenizer = BertTokenizer.from_pretrained(r"E:\2020.09.07 pytorch_pretrained_models\bert-sim-chinese")
text_query = "如何针对用户群体进行数据分析"
text_A = "基于25W+知乎数据,我挖掘出这些人群特征和内容偏好"
text_B = "揭开微博转发传播的规律:以“人民日报”发布的G20文艺晚会微博为例"
text_C ='''不懂数理和编程,如何运用免费的大数据工具获得行业洞察?'''
# 使用BERT获取各语句的向量表示
emb_query = get_embedding(bert_model, bert_tokenizer, text_query)
emb_A = get_embedding(bert_model, bert_tokenizer, text_A)
emb_B = get_embedding(bert_model, bert_tokenizer, text_B)
emb_C = get_embedding(bert_model, bert_tokenizer, text_C)
# 计算query和各语句的相似余弦值(cosine similarity)
sim_query_A = 1 - cosine(emb_query, emb_A)
sim_query_B = 1 - cosine(emb_query, emb_B)
sim_query_C = 1 - cosine(emb_query, emb_C)
print('')
print('BERT Similarity:')
print(' sim(query, A): {:.4}'.format(sim_query_A))
print(' sim(query, B): {:.4}'.format(sim_query_B))
print(' sim(query, C): {:.4}'.format(sim_query_C))
BERT Similarity:
sim(query, A): 0.9736
sim(query, B): 0.7728
sim(query, C): 0.922
27.如何对古代汉语进行分词?
难度等级:L3
Q.使用jiayan(甲言)对古代汉语(包括诗歌、文言文)进行分词,其中涉及利用无监督、无词典的N元语法和隐马尔可夫模型进行古汉语自动分词。
同时,利用词库构建功能产生的文言词典,基于有向无环词图、句子最大概率路径和动态规划算法进行分词。
from jiayan import load_lm
from jiayan import CharHMMTokenizer
text = '''万物生芸芸,与我本同气。氤氲随所感,形体偶然异。丘岳孰为高,尘粒孰为细。忘物亦忘我,优游何所觊。'''
lm = load_lm(r'D:\jiayan_models\jiayan.klm')
tokenizer = CharHMMTokenizer(lm)
print(list(tokenizer.tokenize(text)))
28.如何对古代汉语进行自动化词库构建?
难度等级:L5
Q.jiayan中利用无监督的双字典树、点互信息以及左右邻接熵进行古代汉语词库自动化构建。
from jiayan import PMIEntropyLexiconConstructor
constructor = PMIEntropyLexiconConstructor()
lexicon = constructor.construct_lexicon(r'C:\Users\Administrator\Desktop\【精华】诗歌文本挖掘项目集\data\poems_clean.txt')
constructor.save(lexicon, '诗歌词库自动构建.csv') #输出词库
Trie building time: 2.5439980030059814
Computation time: 2.946000099182129
Word filtering: 0.33702635765075684
29.如何自动生成诗歌?
难度等级:L2
Q.如何使用transformers中的pipeline(基于GPT2)生成诗歌。
from transformers import GPT2LMHeadModel, BertTokenizerFast,pipeline
model = GPT2LMHeadModel.from_pretrained('gaochangkuan/model_dir', pad_token_id=tokenizer.eos_token_id)
tokenizer = BertTokenizerFast.from_pretrained( "gaochangkuan/model_dir") #自动下载vocab.txt
nlp =pipeline('text-generation', model = model,tokenizer =tokenizer ) #自动下载模型
nlp('阳光明媚') #七言律诗,64个字(含标点),超过该字数则无效
30.如何基于关键词的布尔逻辑组合(与、或、非)来精确检索信息?
难度等级:L4
Q.利用eldar进行关键词组合来检索查询信息。
from eldar import build_query
# build list
documents = [
"打造人工智能产业高地 泉山区牵手矿大开启校地合作新篇章",
"全国人工智能版图:广东一枝独秀,山东胜过浙江",
"科普:人工智能和大数据是如何联系在一起的?",
"联动六城 共享科技盛宴!2020科大讯飞人工智能云展会重磅亮相",
"大数据,为人工智能提供了深度学习的数据,促进人工智能快速发展",
'人工智能学习如何实现从0到1?刘鹏教授主编的《人工智能》是好帮手!',
'政协委员刘伟:人工智能“新基建”的主导权必须掌握在中国人手里',
'ai的“新基建”的高科技主导权必须掌握在中国人手里',
'全国人大代表刘庆峰:让大数据和AI一起为师生减负',
'华米科技AI创新大会公布!借力AI,华米将在健康领域继续发力',
'AI to Decode Future!华米科技将召开,AI创新大会解构未来',
'有ai加持,浙江绍兴的智慧城市建设会更加顺畅~'
]
keywords ='("大数据"|"数据"|"科技") + ( "AI"|"人工智能") ' #关键词组合逻辑
filter_word = '("浙江")' #排除词逻辑
eldar = build_query(keywords.replace('|',' OR ').replace('+',' AND ') + 'NOT ' + filter_word.replace('|',' OR '))
documents = [i.lower() for i in documents]
eldar.filter(documents)
['科普:人工智能和大数据是如何联系在一起的?',
'大数据,为人工智能提供了深度学习的数据,促进人工智能快速发展',
'ai的“新基建”的高科技主导权必须掌握在中国人手里',
'全国人大代表刘庆峰:让大数据和ai一起为师生减负',
'华米科技ai创新大会公布!借力ai,华米将在健康领域继续发力',
'ai to decode future!华米科技将召开,ai创新大会解构未来']
催更请留言、评论
To be continued~
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏