
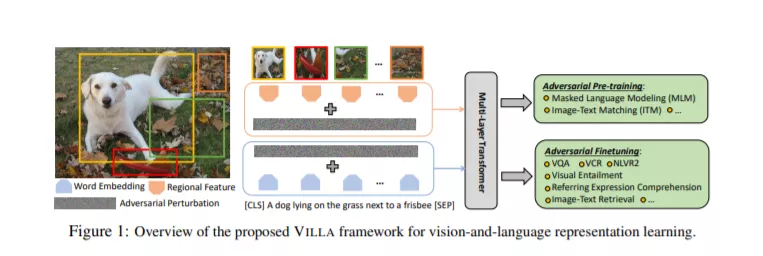
我们提出了VILLA,这是已知的第一个针对视觉和语言(V+L)表征学习的大规模对抗训练。VILLA由两个训练阶段组成: (一)任务不可知的对抗性预训练; 其次(二)针对具体任务进行对抗性微调。为了避免在图像像素和文本标记上增加对抗性扰动,我们建议在每个模态的嵌入空间中进行对抗性训练。为了实现大规模训练,我们采用了“free”对抗式训练策略,并与基于KL发散的正则化相结合,提高了嵌入空间的高不变性。我们将VILLA应用到目前表现最好的V+L模型中,并在广泛的任务中达到了新的水平,包括视觉问题回答、视觉常识推理、图像-文本检索、参考表达理解、视觉隐含和NLVR2。
https://www.zhuanzhi.ai/paper/9ac766aec437a266e108f8dd71d3ab25
成为VIP会员查看完整内容
相关内容
Arxiv
12+阅读 · 2020年8月11日
Arxiv
7+阅读 · 2020年6月11日
Arxiv
9+阅读 · 2018年1月27日
相关主题
相关VIP内容
相关资讯
相关论文
Arxiv
12+阅读 · 2020年8月11日
Arxiv
7+阅读 · 2020年6月11日
Arxiv
9+阅读 · 2018年1月27日