ECCV 2018 | 微软亚洲研究院与北京大学共同提出用于物体检测的可学习区域特征提取模块
机器之心发布
作者:Jiayuan Gu、Han Hu、Liwei Wang、Yichen Wei、Jifeng Dai
尽管现代的物体检测系统中的多数步骤是可学习的,但对于区域特征的提取,以 RoI Pooling 为例,仍保留不少手工设计的痕迹。近日,来自微软亚洲研究院和北京大学的研究者们提出了统一现有区域特征提取方法的视角,并据此设计了一种新的可端到端学习的区域特征提取方法。新的方法在 COCO 检测任务上的表现普遍超过 RoI Pooling 及其变种,并且启发研究者们进一步探索完全可学习的物体检测系统。该论文已被 ECCV2018 接收。
论文:Learning Region Features for Object Detection

论文地址:https://arxiv.org/abs/1803.07066
1. 简介
深度学习时代的一大特点是,许多人工设计的特征、算法组件和设计选择都被数据驱动和可学习的对应物所取代。物体检测的演变就是一个很好的例子。最近,先进的基于区域的物体检测方法 [4, 5, 10–12, 14, 19, 27] 由五个步骤组成,分别是图像特征生成、候选区域 (proposal) 生成、区域特征提取、区域识别和重复检测去除。大多数的步骤,包括图像特征提取 [10]、候选区域生成 [6, 27, 30] 和重复检测去除 [15, 16],在近年来都变得可学习。区域特征提取很大程度上依旧是人工设计的。目前的常用方法,RoI pooling [10] 和它的变种 [12, 14],将候选区域规则地划分为若干统计区 (bin),通过启发式规则 (平均、最大或是双线性插值 [5, 12] 等) 对统计区中的图像特征进行计算,并将各个统计区中的特征连接在一起作为候选区域的特征。这个过程符合直观也很有成效,但更多地像一种经验法则。没有清晰直观的证据表明这就是最优的。
研究者们在本文中研究了完全可学习的区域特征提取,用于提升物体检测的整体性能和加深对这一步骤的理解。主要的两个贡献如下:首先,他们提出了区域特征提取的一般化视角。统计区(或者更宽泛地说,子区域)的特征被表达为全图上不同位置图像特征的加权和。大多数之前的方法被证明是上述表达通过指定权重的特例。基于一般化的视角,第二个贡献是一个根据关注区域 (RoI) 和图像特征来表达权重的可学习模块。用以加权的权重受两方面因素影响:关注区域与图像位置的几何关系,和图像特征本身。受到 [16, 32] 启发,研究者们用注意力模型 (attention model) 建模第一个因素。同时,受到 [5] 启发,他们在输入的图像特征上简单地加上一个卷积层 (convolution layer) 来挖掘第二个因素。所提出的方法去除了之前 RoI pooling 中大部分启发式的设计,向完全可学习的物体检测迈进一步。另外,由于朴素的实现计算代价大,研究者们同时提出了一种略微影响精度但高效的稀疏采样的实现方式。对于所习得的权重的定性和定量的分析表明了从数据而非人工地学习空间分布相关的权重是可行而且有效的。
2. 区域特征提取的一般化视角
图像特征生成这一步骤会输出空间大小为 H×W (由于神经网络 [27] 的下采样, 通常是原图的 16×缩放) 和通道数为 C_f 的特征图 x。候选区域生成这一步骤会输出一定数量的关注区域 (RoI), 每个 RoI 用四个坐标的边界框 b 表示。通常,区域特征提取的步骤会从图像特征 x 和关注区域 b 生成区域特征 y(b),如
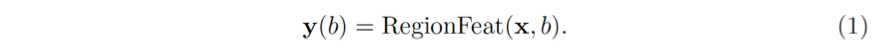
一般地,y(b) 的维度为 K×C_f。通道数保持和图像特征 x 一样为 C_f,而 K 表示区域中空间子区域 (spatial part) 的个数。上述概念可以被泛化。一个子区域 (part) 未必有规则的形状。子区域的特征 y_k (b) 无需从图像特征 x 上固定的空间位置得来。甚至,子区域的并集未必是关注区域本身。在一般化的表达式中,子区域的特征被视为图像特征 x 在采样区域 Ω_b (support region) 上的加权和,如
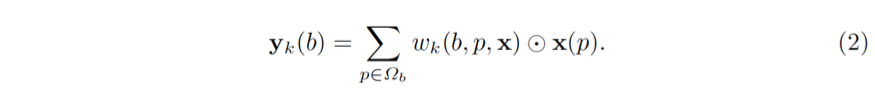
其中,Ω_b 是采样区域,它可以是 RoI 本身,也可以包含更多语境 (context) 信息,甚至是全图。p 枚举了 Ω_b 内的所有空间位置。w_k (b,p,x) 是对应于位置 p 处的图像特征 x(p) 的加权权重。⊙ 表示逐元素乘法 (element-wise multiplication)。这里的权重假定是归一化的,即 ∑_(p∈Ω_b) w_k (b,p,x)=1。
研究者证明各种关注区域池化方法 [5, 10, 12, 14] 都是上述观点的特例。在这些方法中,采样区域Ω_b 和权重 w_k (⋅) 的具体形式各异,并且大多是人为定义的。
(1) Regular RoI Pooling
普通的区域池化 (Regular RoI Pooling) [10] 的采样区域 Ω_b 是 RoI 本身。它被规则地划分为网格 (比如 7×7)。每个子区域的特征 y_k (b) 是所有图像特征 x(p) 的最大或平均值,其中 p 位于第 k 个统计区内部。
以 averaging pooling 为例,公式 (2) 中的权重是
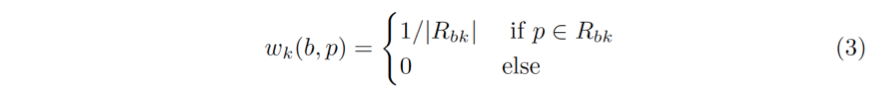
其中,R_bk 是第 k 个统计区内部所有位置的集合。
Regular RoI Pooling 存在一个缺陷:由于神经网络的空间下采样,它无法区分非常近的若干关注区域。
(2) Aligned RoI Pooling
对齐的区域池化 (Aligned RoI Pooling) [12] 通过对每个 R_bk 中的采样点进行双线性插值,弥补了普通的区域池化中的量化缺陷。简单地说,假定每个统计区只采样一个点,比如统计区的中心 (u_bk,v_bk)。设位置 p=(u_p,v_p),公式 (2) 中的权重可以表示为
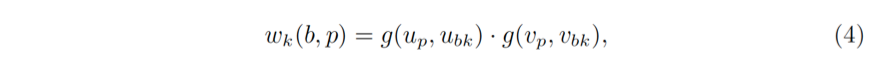
其中,g(a,b)=max(0,1-|a-b|) 表示一个维度上线性插值的权重。注意公式 (4) 中的权重只有在采样点 (u_bk,v_bk) 周围最近的四个坐标才非零。
(3) Deformable RoI pooling
可形变的区域池化 (Deformable RoI pooling) [5] 通过对每一个统计区学习一个偏移 (δu_bk,δv_bk),并作用于统计区中心,泛化了对齐的区域池化。公式 (4) 中的权重可以扩展为
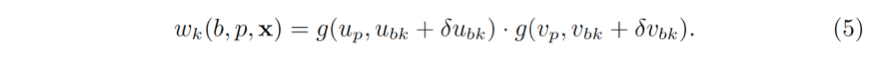
偏移是通过一个作用于图像特征 x 的可学习的子模块产生的。特别地,这个子模块从对齐的区域池化提取的特征出发,通过额外的全连接层 (fully connected layer) 回归偏移。
权重和偏移是依赖于图像特征而且可以端到端学习的,物体的形变被更好地根据图像内容进行建模。另外,由于位移原则上可以任意大,所以采样区域 Ω_b 不再局限于关注区域内部,而是能够覆盖全图。
3. 数据驱动的区域特征学习
普通的和对齐的区域池化是完全由人工设计的。可变形的区域池化引入了可学习的模块,但它的形式仍然限制在规则的网格。在本文中,研究者试图用最少的人工设计学习公式 (2) 中的权重 w_k (b,p,x)。
直观地,研究者考虑两个会影响权重的因素。首先,位置 p 和 关注区域框 b 的几何关系是至关重要的。例如,在关注区域框 b 中的位置应该比离得较远的位置贡献更大。第二,图像特征 x 应该适应性地被使用。这一点是受到可变形关注区域池化 [5] 的启发。
所以,权重被建模成与两项的和的幂指数相关
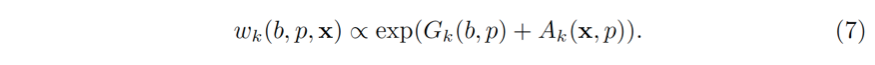
公式 (4.1) 中的第一项 G_k (b,p) 刻画了几何关系
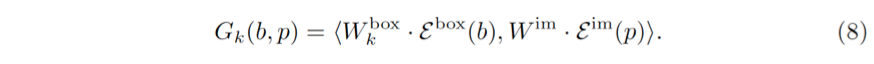
计算几何关系一共分为三个步骤。第一,类似 [16, 32],目标框与图像位置被映射到高维空间。这种映射是通过用不同波长的正余弦函数作用与标量 z 而得
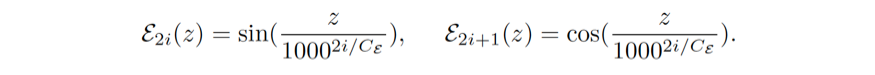
第二,映射向量 E^im (p) 和 E^box (b) 是分别通过可学习的权值矩阵 W^im 和 W_k^box 线性变换而得。最后,两个变换后的向量的内积被作为几何关系的权重。
公式 (8) 本质上是一个注意力模型 [16, 32],注意力模型是建模远距离的或者性质各异的元素间依赖关系的利器,比如不同语言中的单词 [32],位置/大小/比例不同的关注区域 [16] 等。在研究者关注的问题上,注意力模型自然地建立起 4 维的矩形框坐标和 2 维的图像位置之间的关系。大量的实验表明关注区域和图像位置间的几何关系能够被注意力模型很好地建模。
公式 (7) 中的第二项 A_k (x,p) 适应性地使用图像特征。它在图像特征上作用一层卷积,
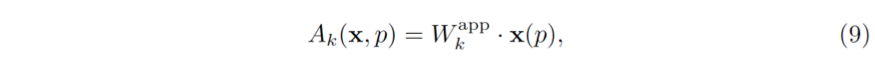
其中 W_k^app 代表可学习的卷积核的权值。
整个区域特征提取模块的结构如图 1 所示。在训练中,图像特征 x 和模块参数 (W_k^box, W^im, 和 W_k^app) 都是同时更新的。
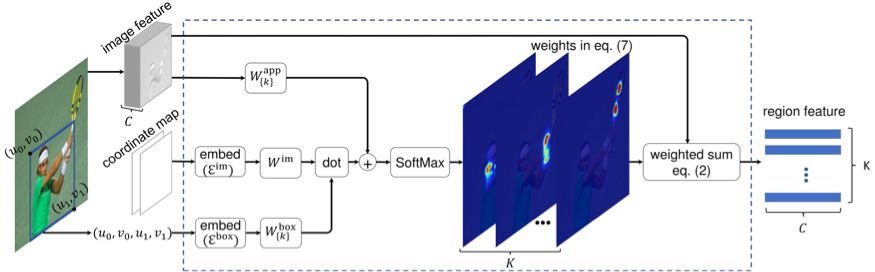
图 1 所提出的区域特征提取模块中关于公式 (2) 和 公式 (7) 的图示
4. 复杂度分析和高效实现
一种朴素的实现方式需要遍历 Ω_b 中所有位置。一种高效的实现方式可以对 Ω_b 中的位置稀疏采样。直观上,关注区域内的采样点应该更密,而其外应该较稀疏。因此,Ω_b 被划分为两个集合 Ω_b=Ω_b^In∪Ω_b^Out,分别包含了关注区域内外的位置。Ω_b^Out 代表了关注区域的语境(上下文)信息。它可以是空集也可以覆盖全图。通过指定在 Ω_b^In 和 Ω_b^Out 中的最大采样数 (通常,两者都设为 196),复杂度可以被控制。给定关注区域 b,Ω_b^In 中的位置分别以 stride_x^b 和 stride_y^b 的步长,沿 x 和 y 两个方向采样。实验表明稀疏采样的准确度与朴素的密集采样相差无几。
5. 实验
所有的实验都在 COCO 检测数据集上进行 [21]。研究者遵循 COCO 2017 的数据集划分:训练集的 115k 张图像用于训练; 验证集中的 5k 张图片进行验证; 并在测试集的 20k 张图像上进行测试。
研究者使用最先进的 R-CNN [27] 和 FPN [19] 物体探测器。ResNet-50 和 ResNet-101 [13] 被用作图像特征提取器的骨干 (backbone)。默认情况下,使用基于 ResNet-50 的 Faster R-CNN 进行对比实验。交并比 (IoU) 阈值为 0.5 的标准非极大值抑制 (NMS) 被用于去除重复检测。
(1) 采样区域的影响
研究者观察到两点。首先,研究者的方法胜过了其他两种池化方法。其次,研究者的方法的效果在使用更大的采样区域时稳步提高,表明了利用语境信息是有帮助的。然而,与使用 1× 关注区域相比,使用较大的采样区域 (例如 2× 关注区域) 分别给普通和对齐的区域池化带来了较小的提升而没有提升。
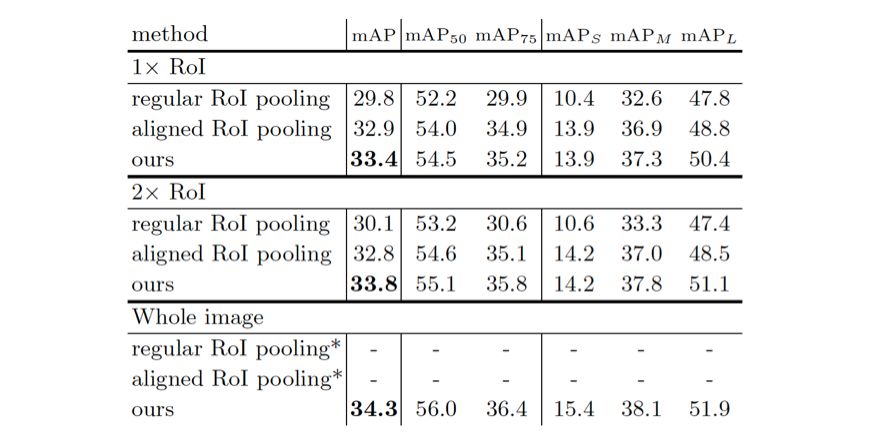
表 2 不同采样区域的三种区域特征提取方法比较。在 COCO 验证集上报告准确性 mAP。* 目前尚不清楚如何利用整个图像进行普通和对齐的目标区域池化方法,因此相应的准确数字被省略。
(2) 稀疏采样的影响
由于稀疏采样实现,计算开销可以显著降低。默认情况下,对 Ω_b^In 和 Ω_b^Out 指定最多 196 个采样位置。实际中,面积较大的关注区域对于Ω_b^Out 将具有较少的采样位置,而面积较小的关注区域对于 Ω_b^In 将具有比最大采样数更少的采样位置。对于 Ω_b^In 和 Ω_b^Out,实际的平均采样位置数分别在 114 和 86 左右,如表 3 所示。相应的计算开销是 4.16G FLOPS,粗略地等于两个全连接层的检测头的计算量 (大约 3.9G FLOP)。
对于之后的实验,研究者的稀疏采样实现对于 Ω_b^In 和 Ω_b^Out 都最多选取 196 个位置。
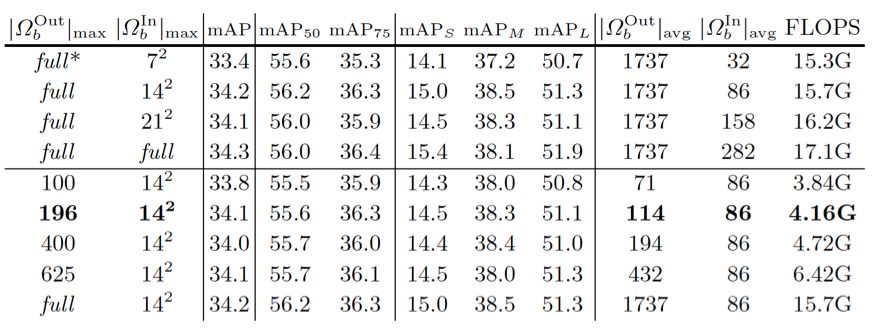
表 3 不同采样位置数下的检测准确度和计算量。均采样个数 |Ω_b^Out |_avg 和 |Ω_b^In |_avg 是在 COCO 的验证集上以 ResNet-50 RPN 生成的 300 个候选区域为样本计算而得的。
(3) 几何关系和图像特征使用方法的影响
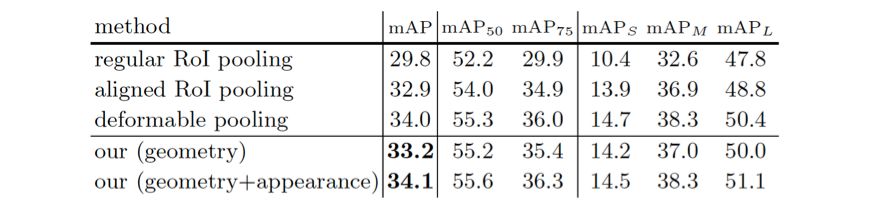
公式 (7) 中几何关系和图像特征使用对于所提出的区域特征提取模块的影响。在 COCO 的验证集上汇报结果。
(4) 不同检测网络的比较
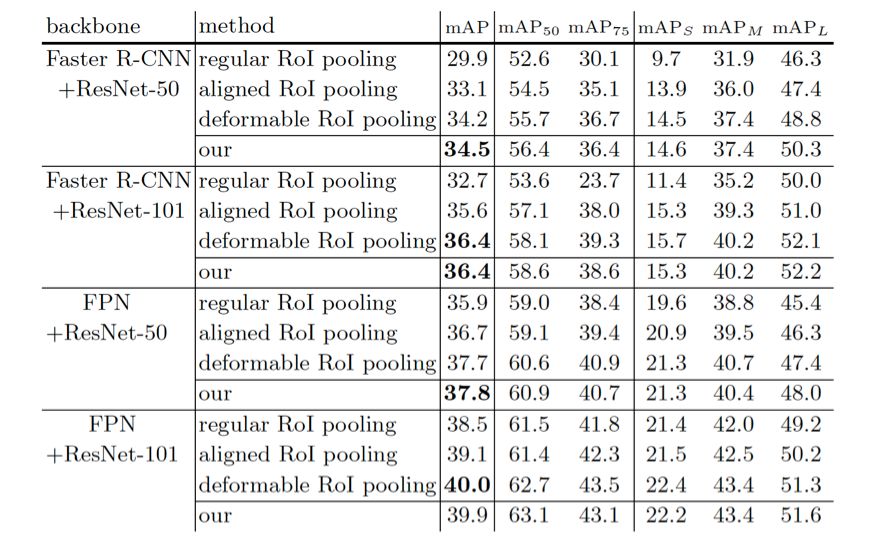
表 5 不同检测网络上不同方法的比较。在 COCO 的测试集上汇报结果。
6. 讨论
公式 (7) 中学习而得的权重 w_k (*) 被可视化在图 2(a) 中。支持区域 Ω 是全图。训练伊始,权重 w_k (*) 很大程度上是随机的。在训练之后,不同部分的权重被习得以关注关注区域上的不同位置,并主要集中在前景物体上。
为了理解公式 (7) 中几何关系与图像特征使用的作用,图 2 (b) 可视化了分别忽略其中一项后所得的权重。几何关系对应的权重似乎主要集中在关注区域,而图像特征部分对应的权重则集中在所有的物体实例上. 关于可视化,所有权重均由所有图像位置上的最大值归一化,并用原始图像进行半色调处理。
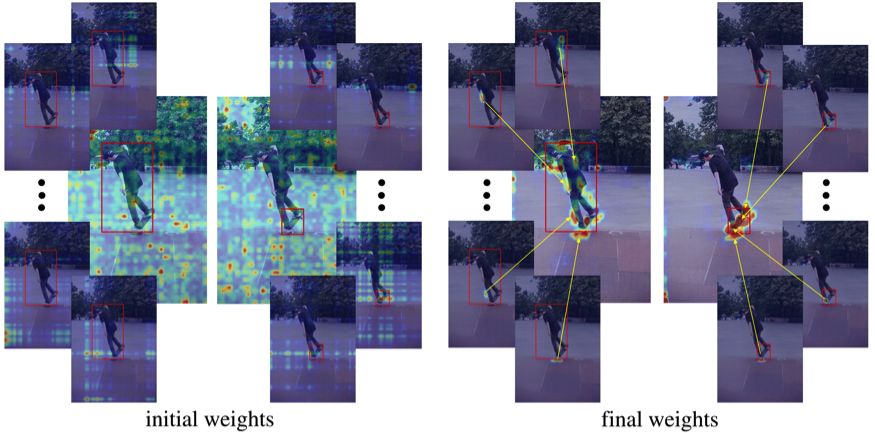
图 2 (a) 给定两个 RoI (红色框),初始 (左) 和最终 (右) 公式 (7) 中的权重 w_k (*)。中心的图片展示了所有 K=49 个子区域对应的权重图的最大值。其周围 4 个小的图片显示了 4 个子区域分别对应的权重图。

图 2 (b) 示例:几何关系对应的权重 (第一行),图像特征对应的权重 ({第二行) 和两者结合的权重 (第三行)。
本文为机器之心发布,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com



