
【导读】最近小编推出CVPR2019图卷积网络相关论文和CVPR2019生成对抗网络相关视觉论文,反响热烈。最近,模型的可解释性是现在正火热的科研和工程问题,也在各个顶级会议上都有相关文章发表,今天小编专门整理最新十篇可解释性相关应用论文—推荐系统、知识图谱、迁移学习以及视觉推理等。
1、Recurrent Knowledge Graph Embedding for Effective Recommendation(基于循环知识图嵌入的推荐)
RecSys ’18
作者:Zhu Sun, Jie Yang, Jie Zhang, Alessandro Bozzon, Long-Kai Huang, Chi Xu
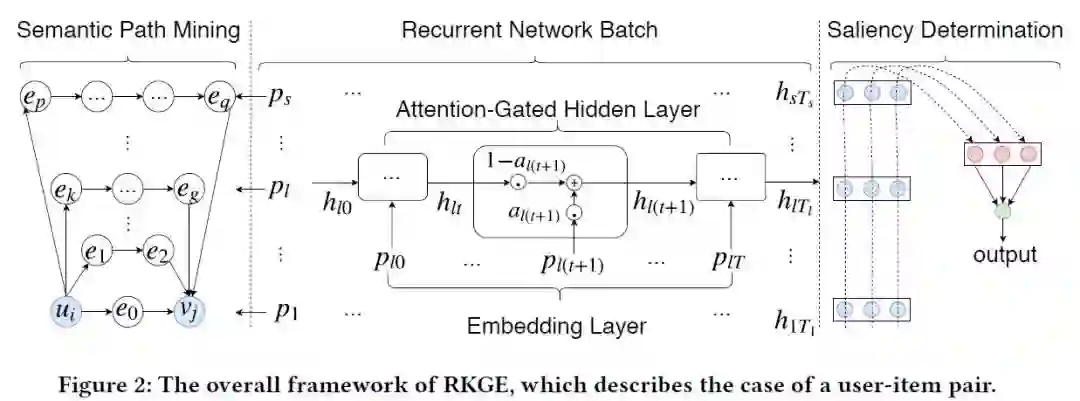
摘要:知识图(KGs)已被证明是改进推荐的有效方法。现有的方法主要依赖于KG手工设计的特性(例如,元路径meta paths),这需要领域知识(domain knowledge)。本文介绍了一种KG嵌入方法RKGE,它可以自动学习实体和实体之间的路径的语义表示,从而描述用户对商品的偏好。具体地说,RKGE采用了一种新的循环网络架构,其中包含了一批循环网络,用于对链接相同实体对的路径进行语义建模,这些路径无缝地融合到推荐中。它还使用pooling操作符来区分不同路径在描述用户对商品的偏好时的显著性。对真实数据集的广泛验证显示出RKGE相对于最先进方法的优越性。此外,我们证明了RKGE为推荐结果提供了有意义的解释。
网址:
https://yangjiera.github.io/works/recsys2018.pdf
2、Explainable Recommendation via Multi-Task Learning in Opinionated Text Data( 在观点文本数据中基于多任务学习的可解释性推荐)
SIGIR ’18
作者:Nan Wang, Hongning Wang, Yiling Jia, Yue Yin
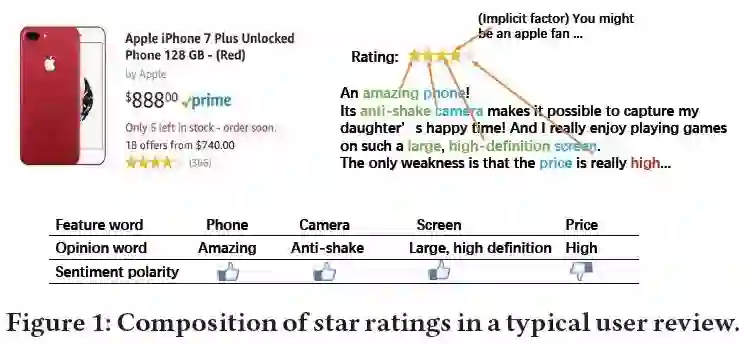
摘要:通过解释自动生成的推荐,可以让用户更明智、更准确地决定使用哪些结果,从而提高他们的满意度。在这项工作中,我们开发了一个可解释推荐的多任务学习解决方案。通过联合张量因子分解,将推荐用户偏好建模和解释用户意见内容建模这两项学习任务结合起来。因此,该算法不仅预测了用户对一组商品的偏好,即推荐,而且预测用户如何在特征级别上喜欢某一特定商品,即观点文本解释。通过对Amazon和Yelp两个大型评论数据集的大量实验,与现有的几种推荐算法相比,验证了我们的解决方案在推荐和解释任务方面的有效性。我们广泛的实验研究清楚地证明了我们的算法生成的可解释建议有着不错的实用价值。
网址:
https://arxiv.org/abs/1806.03568
代码链接:
https://github.com/MyTHWN/MTER
3、TEM:Tree-enhanced Embedding Model for Explainable Recommendation(基于Tree增强嵌入方法的可解释性推荐)
WWW ’18
作者:Xiang Wang, Xiangnan He, Fuli Feng, Liqiang Nie, Tat-Seng Chua
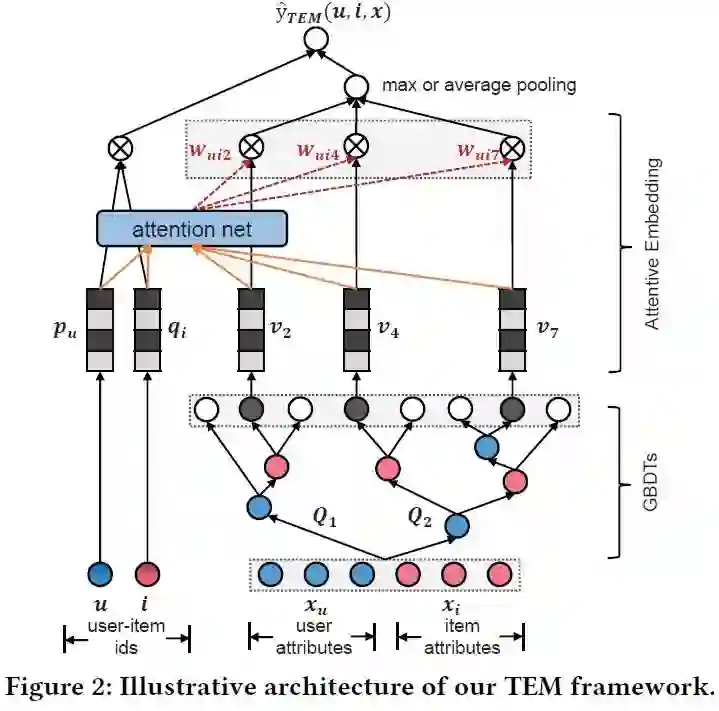
摘要:虽然协同过滤是个性化推荐的主导技术,但它只对用户-商品交互进行建模,不能为推荐提供具体的理由。与此同时,与用户-商品交互相关的丰富的侧面信息(例如,用户统计数据和商品属性)提供了有价值的证据,可以说明为什么该推荐适合于用户,但在提供解释方面还没有得到充分的探索。在技术方面,基于嵌入的方法,如广度&深度和神经因子分解机,提供了最先进的推荐性能。然而,它们的工作原理就像一个黑匣子,无法明确地呈现出预测背后的原因。另一方面,决策树等基于树的方法通过从数据中推断决策规则来进行预测。虽然可以解释,但它们不能推广到不可见的特性交互,因此在协作过滤应用程序中会失败。在这项工作中,我们提出了一种新的解决方案,称为树增强嵌入方法,它结合了基于嵌入和基于树的模型的优点。我们首先使用一个基于树的模型从丰富的侧面信息来学习明确的决策规则(又称交叉特征)。接下来,我们设计了一个嵌入模型,该模型可以包含显式交叉特征,并推广到用户ID和商品ID上不可见的交叉特征。嵌入方法的核心是一个易于解释的注意力网络,使得推荐过程完全透明和可解释。我们对旅游景点和餐厅推荐的两个数据集进行了实验,证明了我们的解决方案的优越性能和可解释性。
网址:
https://dl.acm.org/citation.cfm?id=3178876.3186066
代码链接:
https://github.com/xiangwang1223/TEM
4、Explainable Reasoning over Knowledge Graphs for Recommendation(基于知识图谱可解释推理的推荐)
AAAI ’19
作者:Xiang Wang, Dingxian Wang, Canran Xu, Xiangnan He, Yixin Cao, Tat-Seng Chua
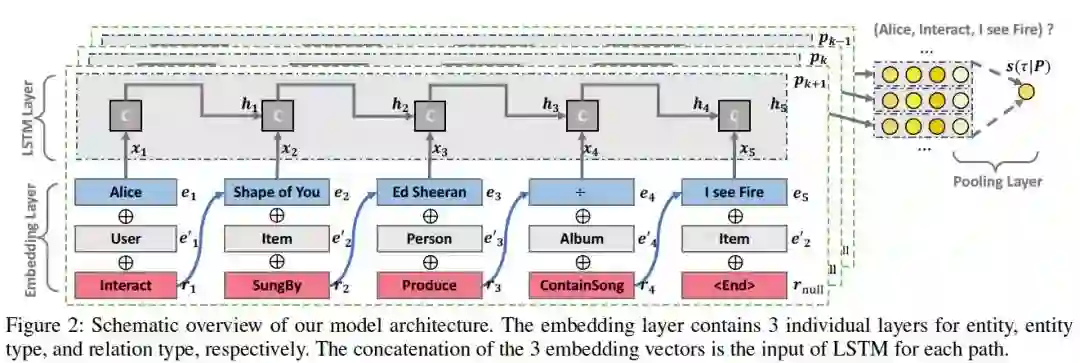
摘要:近年来,将知识图谱与推荐系统相结合引起越来越多的关注。通过研究知识图谱中的相互关系,可以发现用户与商品之间的连接路径,这为用户与商品之间的交互提供了丰富且互补的信息。这种连通性不仅揭示了实体和关系的语义,而且有助于理解用户的兴趣。然而,现有的工作尚未充分探索用来推断用户偏好的这种连接性,特别是在建模路径内部的顺序依赖关系和整体语义方面。本文提出了一种新的知识感知路径递归网络(Knowledgeaware Path Recurrent Network,KPRN)模型,利用知识图进行推荐。KPRN可以通过组合实体和关系的语义来生成路径表示。通过利用路径中的顺序依赖关系,我们允许对路径进行有效的推理,从而推断用户-商品交互的基本原理。此外,我们设计了一个新的加权pooling操作来区分连接用户和商品的不同路径的优势,使我们的模型具有一定的可解释性。我们对电影和音乐的两个数据集进行了大量的实验,证明了,与最好的方法相比,CKE(Collaborative Knowledge Base Embedding)和神经因子分解(Neural Factorization Machine),都有了显著的改进。
网址:
https://arxiv.org/abs/1811.04540
代码链接:
5、Explainable Recommendation Through Attentive Multi-View Learning(基于注意力机制多视角学习的可解释推荐)
AAAI ’19
作者:Jingyue Gao, Xiting Wang, Yasha Wang, Xing Xie
摘要:由于信息的爆炸式增长,推荐系统在我们的日常生活中发挥着越来越重要的作用。当我们评估一个推荐模型时,准确性和可解释性是两个核心方面,并且已经成为机器学习的基本权衡指标之一。在本文中,我们提出通过开发一个结合了基于深度学习的模型和现有可解释方法的优点的可解释的深度模型,来减轻准确性和可解释性之间的权衡。其基本思想是基于可解释的深度层次结构(如Microsoft概念图)构建初始网络,通过优化层次结构中的关键变量(如节点重要性和相关性)来提高模型精度。为了保证准确的评分预测,我们提出了一个周到的多视图学习框架。该框架通过在不同的特征层之间进行协同正则化,并专注地结合预测,使我们能够处理稀疏和噪声数据。为了从层次结构中挖掘可读的解释,我们将个性化解释生成问题定义为一个约束树节点选择问题,并提出了一种动态规划算法来解决该问题。实验结果表明,该模型在准确性和可解释性方面均优于现有的最好的方法。
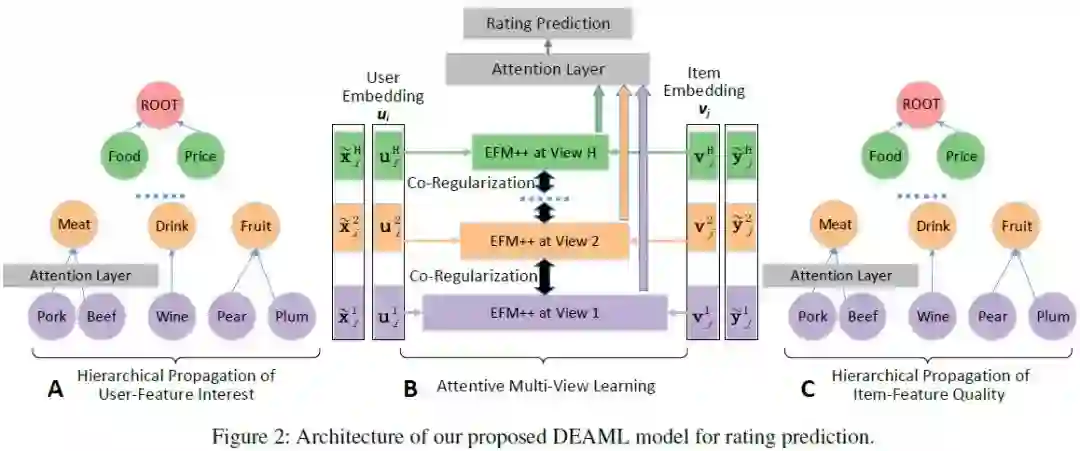
网址:
6、ExFaKT- A Framework for Explaining Facts over Knowledge Graphs and Text(ExFaKT:一个基于知识图谱和文本来解释事实的框架)
WSDM ’19
作者:Mohamed H. Gad-Elrab, Daria Stepanova, Jacopo Urbani, Gerhard Weikum
摘要:事实检验是准确填充、更新和整理知识图谱的关键。手工验证候选事实非常耗时。先前关于自动完成这一任务的工作侧重于使用非人类可解释的数值分数来估计真实性。另一些则提取文本中对候选事实的显式提及作为候选事实的证据,这很难直接发现。在我们的工作中,我们引入了ExFaKT,这是一个专注于为候选事实生成人类可理解的解释的框架。ExFaKT使用以Horn子句形式编码的背景知识将相关事实重写为一组其他更容易找到的事实。我们框架的最终输出是文本和知识图谱中候选事实的一组语义跟踪。实验表明,我们的重写在保持较高精确度的同时,显著提高了事实发现的召回率。此外,我们还表明,这些解释有效地帮助人类执行事实检查,并且在用于自动事实检查时也可以执行得很好。
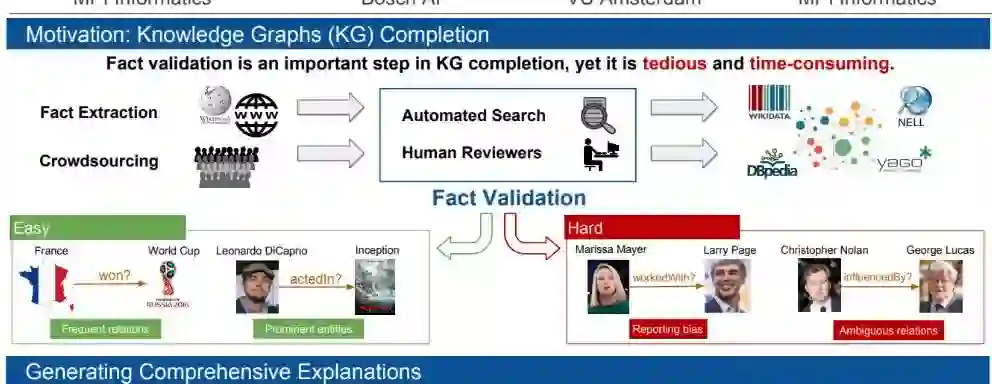
网址:
https://dl.acm.org/citation.cfm?id=3290996
代码链接:
https://www.dropbox.com/sh/wpyyiyy5lusph40/AAC72xbQoGhCu4Qpa-mwUvDua?dl=0
7、Interaction Embeddings for Prediction and Explanation in Knowledge Graphs(知识图谱中的预测和解释的交互嵌入学习)
WSDM ’19
作者:Wen Zhang, Bibek Paudel, Wei Zhang, Abraham Bernstein, Huajun Chen
摘要:知识图嵌入旨在学习实体和关系的分布式表示,并在许多应用中被证明是有效的。交叉交互(Crossover interactions)——实体和关系之间的双向影响——有助于在预测新的三元组时选择相关信息,但之前从未正式讨论过。在本文中,我们提出了一种新的知识图嵌入算法CrossE,它可以显式地模拟交叉交互。它不仅像以前的大多数方法一样,为每个实体和关系学习一个通用嵌入,而且还为这两个实体和关系生成多个三重特定嵌入,称为交互嵌入。我们评估了典型链接预测任务的嵌入,发现CrossE在复杂和更具挑战性的数据集上实现了最先进的结果。此外,我们从一个新的角度来评估嵌入——为预测的三元组提供解释,这对实际应用非常重要。在本工作中,对三元组的解释被认为是头尾实体之间可靠的闭合路径。与其他baseline相比,我们通过实验证明,CrossE更有能力生成可靠的解释来支持其预测,这得益于交互嵌入。
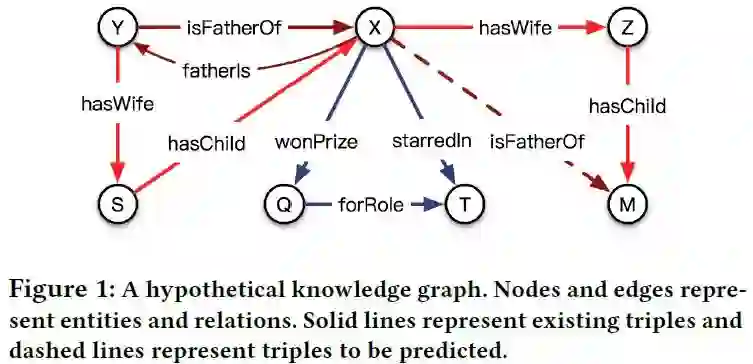
网址:
https://arxiv.org/abs/1903.04750
8、SimGNN- A Neural Network Approach to Fast Graph Similarity Computation(SimGNN:一种快速计算图相似度的神经网络方法)
WSDM ’19
作者:Yunsheng Bai, Hao Ding, Song Bian, Ting Chen, Yizhou Sun, Wei Wang
摘要:图相似度搜索是基于图的最重要的应用之一,例如查找与已知化合物最相似的化合物。图的相似度/距离计算,如图的编辑距离(GED)和最大公共子图(MCS),是图的相似度搜索和许多其他应用的核心操作,但在实践中计算成本很高。受最近神经网络方法在一些图应用(如节点或图分类)中的成功的启发,我们提出了一种新的基于神经网络的方法来解决这个经典但具有挑战性的图问题,目的是在保持良好性能的同时减轻计算负担。这个被称为SimGNN的方法结合了两种策略。首先,我们设计了一个可学习的嵌入函数,它将每个图映射到一个嵌入向量,该向量提供了一个图的全局摘要。提出了一种新的注意机制,针对特定的相似度度量强调重要节点。其次,设计了一种节点对比较法,用细粒度节点信息来补充图级嵌入。我们的模型对不可见图有较好的泛化效果,并且在最坏的情况下,对两个图中的节点数运行二次方的时间。以GED计算为例,在三个实际图形数据集上的实验结果表明了该方法的有效性和效率性。具体来说,我们的模型与一系列baseline相比,包括一些基于GED计算的近似算法和许多现有的基于图神经网络的模型,实现了更小的错误率和更大的时间缩短。我们的工作表明,SimGNN为图相似度计算和图相似度搜索提供了一个新的研究方向。
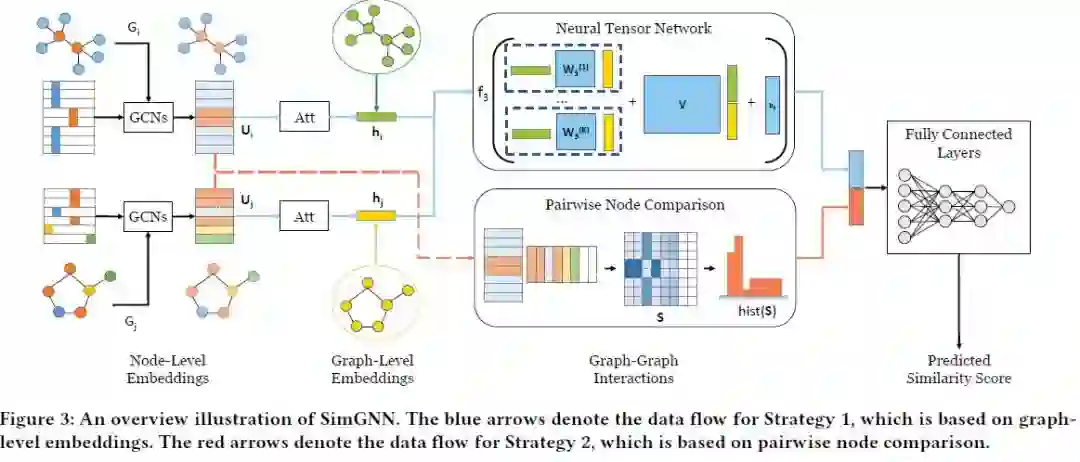
网址:
https://dl.acm.org/citation.cfm?id=3290967
代码链接:
https://github.com/benedekrozemberczki/SimGNN
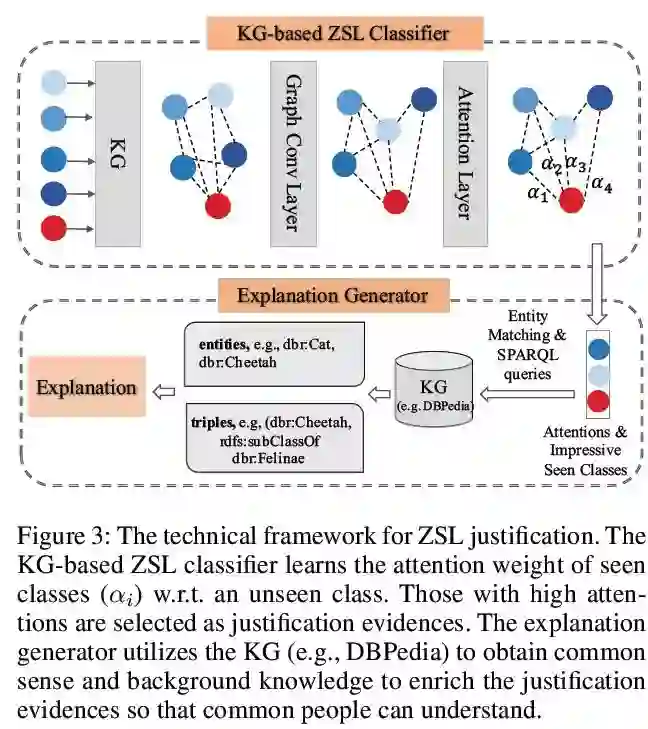
9、Human-centric Transfer Learning Explanation via Knowledge Graph(通过知识图谱以人为中心的迁移学习可解释)
AAAI-19 Workshop on Network Interpretability for Deep Learning
作者:Gao Yuxia Geng, Jiaoyan Chen, Ernesto Jim´enez-Ruiz, Huajun Chen
摘要:迁移学习(Transfer Learning)是利用从一个问题(源域)中学习到的知识来解决另一个不同但相关的问题(目标域),已经引起了广泛的研究关注。然而,目前的迁移学习方法大多是无法解释的,尤其是对没有机器学习专业知识的人来说。在这篇摘要中,我们简要介绍了两种基于知识图谱(KG)的人类可理解迁移学习解释框架。第一个解释了卷积神经网络(CNN)学习特征通过预训练和微调从一个域到另一个域的可移植性,第二个证明了零样本学习(zero-shot learning ,ZSL)中多个源域模型预测的目标域模型的合理性。这两种方法都利用了KG及其推理能力,为迁移过程提供了丰富的、人类可以理解的解释。
网址:
https://arxiv.org/abs/1901.08547
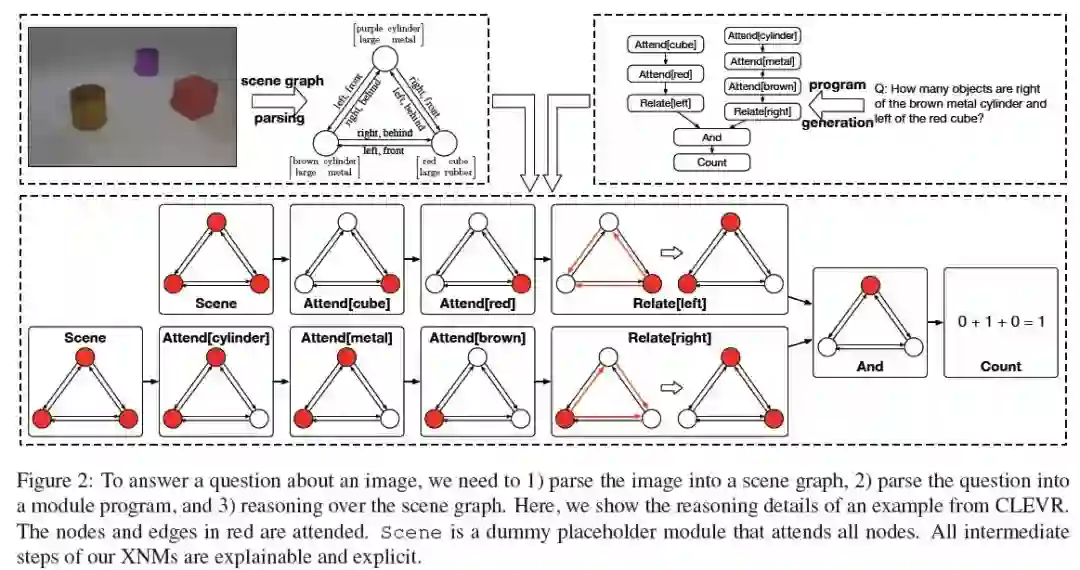
10、Explainable and Explicit Visual Reasoning over Scene Graphs(对场景图进行的可解释和显式的视觉推理)
CVPR-19
作者:Jiaxin Shi, Hanwang Zhang, Juanzi Li
摘要:我们的目标是将复杂视觉推理任务中使用的流行黑盒神经架构拆分为可解释的,明确的神经模块(XNMs), 它能够超越现有的神经模块网络,使用场景图—对象作为节点,成对关系作为边—用于结构化知识的可解释和明确推理。XNMs让我们更加关注教机器如何“思考”,无论它们“看起来”是什么。正如我们将在本文中展示的那样,通过使用场景图作为一个归纳偏差,1)我们可以用简洁灵活的方式设计XNMs,即, XNMs仅由4种元类型组成,大大减少了10 ~ 100倍的参数数量,2)我们可以根据图的注意力程度显式地跟踪推理流程。XNMs是如此的通用,以至于它们支持具有不同质量的各种场景图实现。例如,当图形被完美地检测到时,XNMs在CLEVR和CLEVR CoGenT上的准确率都达到了100%,为视觉推理建立了一个经验性能上限; 当从真实世界的图像中噪声检测出这些图时,XNMs仍然很健壮,在VQAv2.0上达到了67.5%的有竞争力的精度,超越了流行的没有图结构的(bag-of-objects)注意力模型。
网址:
https://arxiv.org/abs/1812.01855
代码链接:
https://github.com/shijx12/XNM-Net
链接:https://pan.baidu.com/s/1ETMl1B0LvIND0kj4NqrUuQ 提取码:9e9x



