多方对话研究简述
作者:哈工大SCIR 张开颜
1 介绍
人机对话技术是人工智能领域的一个重要研究方向,从手机智能助手,到闲聊陪护型聊天机器人,再到各种面向场景的任务型对话系统平台和智能家居,人机对话系统渐渐融入人类社会的日常运行中,促进了将来人机共融社会的发展。然而,目前的人机对话系统大多是在人机双方参与的假设下进行设计,而更具挑战的人机多方混合对话(即多方对话,Multi-Party Conversation)的任务(Traum 2003[1])(Uthus and Aha 2013[2])在研究和应用上鲜有涉及。
本文将从人机对话角度出发,对近几年多方对话的主要数据集和研究任务进行梳理分类,并介绍几个主要任务的已有方法,最后本文也将简述其他与多方对话相关的研究任务。
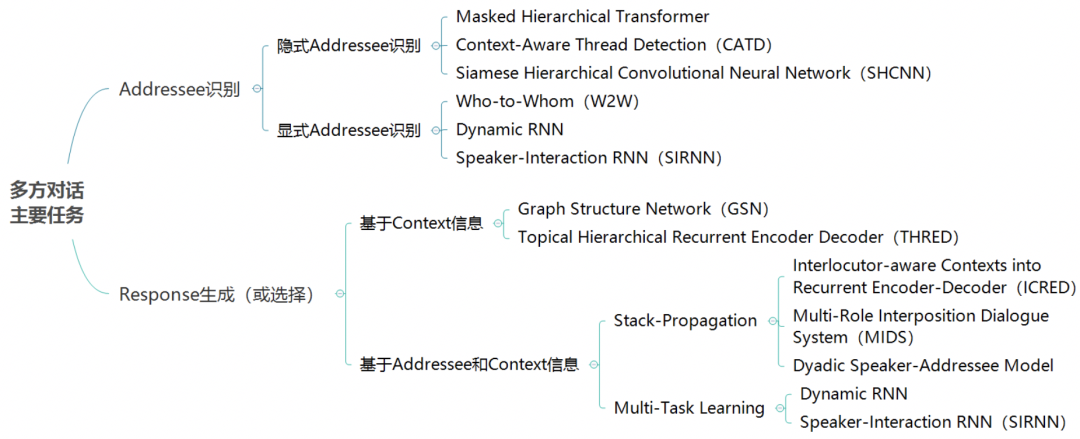
在多方对话场景中,我们可以将整个对话过程抽象为一个三元组集合[(Spk,Utter,Adr)] ,表示为参与者 Spk 对参与者 Adr 说 Utter 这句话(其中 Adr 可以为空,即说话对象不是显式存在的)。基于此,为了使机器人具有参与多方对话的能力,我们可以从 Addressee 和 Utterance 两个方面对多方对话近期的研究任务进行分类,如图1所示:
-
Addressee 方面(说话对象),主要考虑 Addressee 的识别问题。根据数据中是否存在明确的 Addressee 标签,可以将相关任务分为 隐式Addressee识别和 显式Addressee识别。前者主要体现为 Utterances 之间 Reply-to 关系结构识别任务,后者体现为 Addressee 标签预测任务。 -
Utterance 方面(回复,Response),主要考虑 Response 的生成或选择问题。我们同样可以根据数据中是否存在明确的 Addressee 标签,将相关任务分为直接 基于Context 进行回复生成(或选择)和 基于Addressee和Context综合信息进行回复生成(或选择)。在后一种情况中,我们可以进一步根据Addressee 信息的利用方式,将相关任务分为 Stack-Propagation学习( Qin et al. 2019 [3])和 多任务学习(Multi-Task Learning)。
2 主要数据集
该部分主要对多方对话相关任务中应用较为广泛的数据集进行简要介绍,根据数据集来源,我们可以简单划分为三种类型的数据:
-
Internet Relay Chat Logs(IRC),主要以 Ubuntu IRC Logs应用最为广泛,相关论文中也有用了 Linux IRC Logs( Kummerfeld et al. 2019 [4])。 -
Forums and Social Media,包括来自Reddit 和 Twitter 的论坛或社交媒体数据,其中 Reddit Dataset应用最为广泛。 -
Television Series Transcripts,包括 Friends 和 The Big Bang Theory 等电视连续剧角色对话数据,相关任务中使用 Friends较多。
本文将主要介绍 Ubuntu IRC Logs、Reddit Dataset 和 Friends 三个数据集,包括数据格式、数据获取以及在多方对话相关论文中数据使用等情况。
2.1 Ubuntu IRC Logs
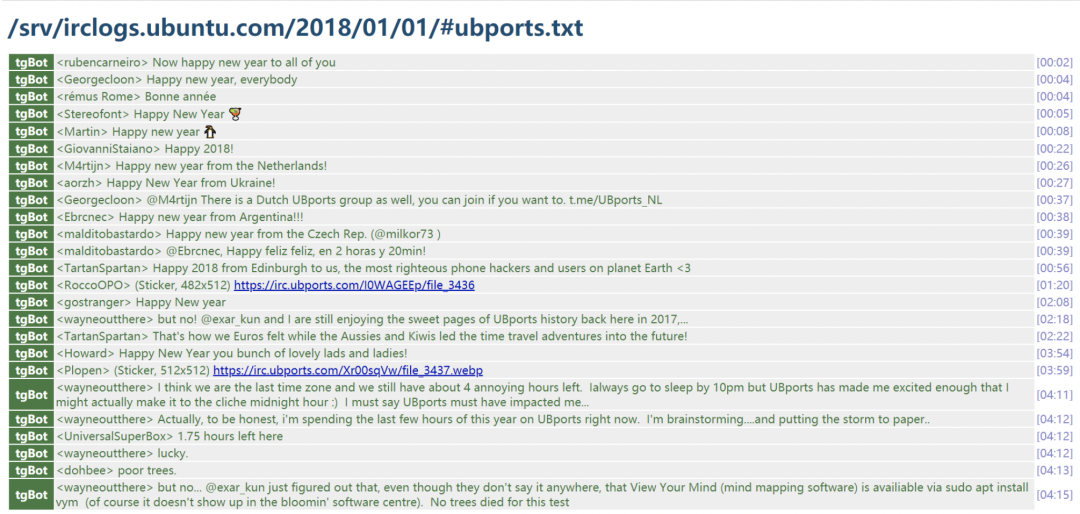
Ubuntu IRC Logs 是从 Ubuntu 在线聊天室(即Ubuntu IRC)获取的日志数据集。在 Ubuntu IRC 的每个聊天室中,会有许多用户会讨论各种各样的主题,这些主题大多是与Ubuntu有关的技术问题。Ubuntu IRC Logs 数据格式如图2所示,其中每一行中包含用户ID、用户回复话语(部分包含说话对象,用“@”表示)、回复时间等信息。
(Ouchi and Tsuboi 2016[5])对 Ubuntu IRC Logs 进行处理使其适用于多方对话中的Addressee and Response Selection(ARS)任务。主要处理操作包括:(1)提取日志中 User ID、Addressee ID以及 Utterance;(2)对于存在Addressee的对话,在相关主题文档的上下文中随机抽样得到反例;(3)根据对话历史长度设置,对对话历史进行切分获得训练样本。最终构造示例如图3所示,训练集包含6606个对话日志文档,每个文档中平均包含26个说话人,210万个utterances,按对话历史长度为10分割得到66.5万个训练样本。该数据集在Addressee识别的相关研究中应用较多(R. Zhang et al. 2018[6])(Le et al. 2019[7])。
2.2 Reddit Dataset
Reddit Dataset 主要由 Reddit 论坛中帖子和对应的回复组成。其原始数据格式如图4所示,其中包含发帖用户的各种详细信息。

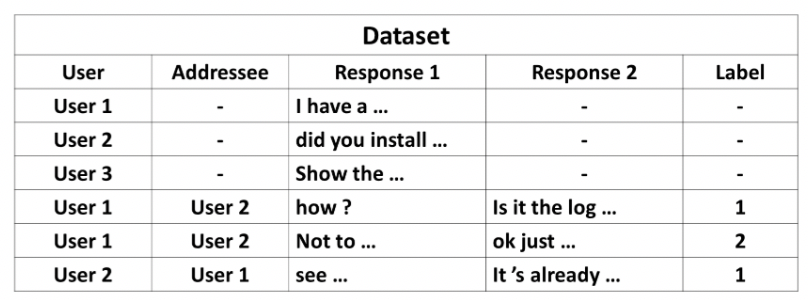
(Jiang et al. 2018[8])对上述 Reddit Dataset 进行处理使其可以用于conversation disentanglement任务。在该任务中,将同一个帖子下的回复看做一个 Thread,论文中将相同 sub-reddit(即 reddit 的主题)下的所有回复组合为一个综合数据集,来判断某个回复所属 Thread ID。其中构造的数据格式如图5所示,数据中包括 gadgets、iPhone、politics 共三个 sub-reddit,总共包含 4500 个对话(session),12万个 utterance,3.5万个说话人。(Tan, Wang, and Wang 2019[9])在此基础上扩大了数据集规模,并进行了类似任务(Thread Detection)的研究。

2.3 Friends Dataset
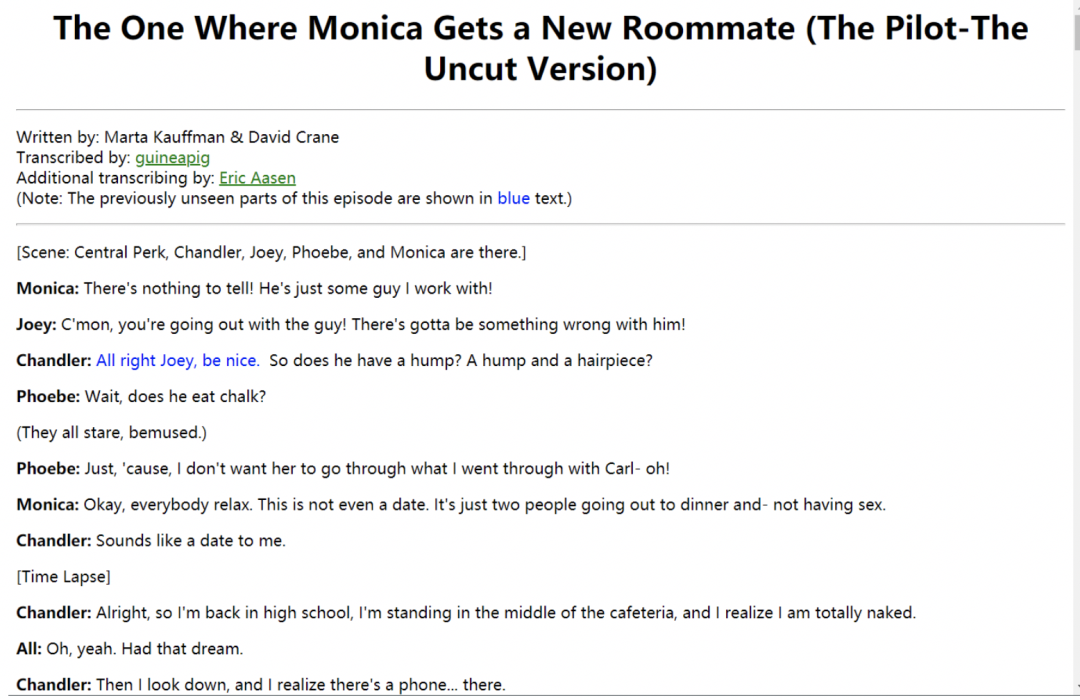
FriendsDataset 来自于老友记对话,老友记是一部情景喜剧,剧情主要围绕六个角色展开。Friends Dataset 主要为各角色之间的对话,如图6所示。
(Yang et al. 2019[10])提取了老友记中六个主要角色(Monica, Joey, Chandler, Phoebe, Rachel, and Ross)的对话进行多方对话的回复生成任务。论文中为了方便使用RNN对各个角色进行建模,将所有角色的对话按顺序进行了排列,如图7所示(其中

3 主要任务及方法
3.1 Addressee 识别
根据数据集中是否存在 Addressee 标签,我们将 Addressee 识别分为隐式识别和显式识别两种任务。在隐式 Addressee 识别中,主要对 Utterance 进行建模,各种任务大多可以抽象为 Reply-to 关系结构识别问题。在显式 Addressee 识别中,主要通过对 Utterance 和 Speaker 进行建模,从而进行 Addressee 的预测。
3.1.1 隐式Addressee识别
该部分将介绍隐式 Addressee 识别的相关研究,主要介绍近期的两个任务及方法,这两种任务的数据中都没有 Addressee 标签,仅对 Utterance 进行建模,从而求解 Utterance 之间的 Reply-to 关系。
两个任务的主要区别在于 reply-to 的目标个数不同:
-
第一个任务只需要从对话历史中找出一个 utterance 作为输入消息的 reply-to 目标; -
第二个任务可以看做从对话历史中找出一组 utterance 作为 reply-to 目标。
首先介绍第一个任务,其可以描述为:给定对话历史及其回复关系(即对话图),要求在对话历史中找出当前话语(target utterance)的父话语(parent utterance)。
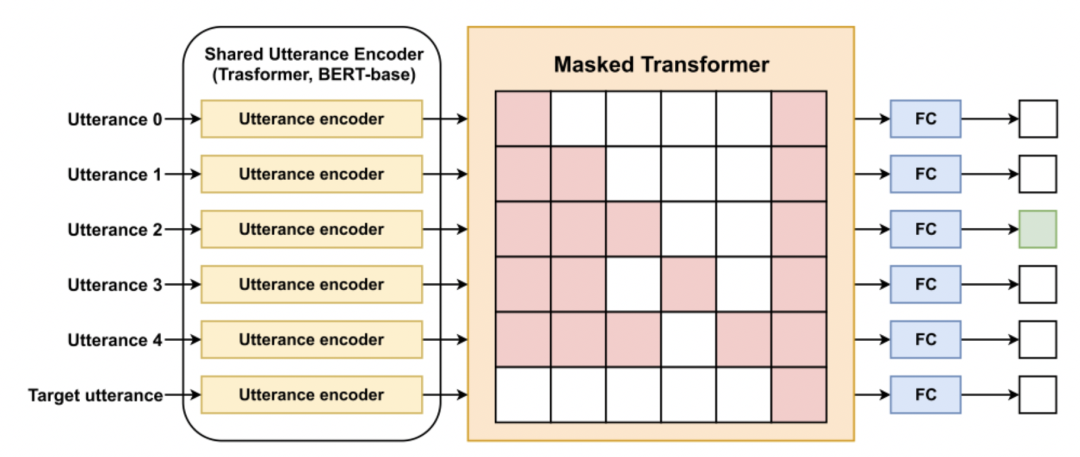
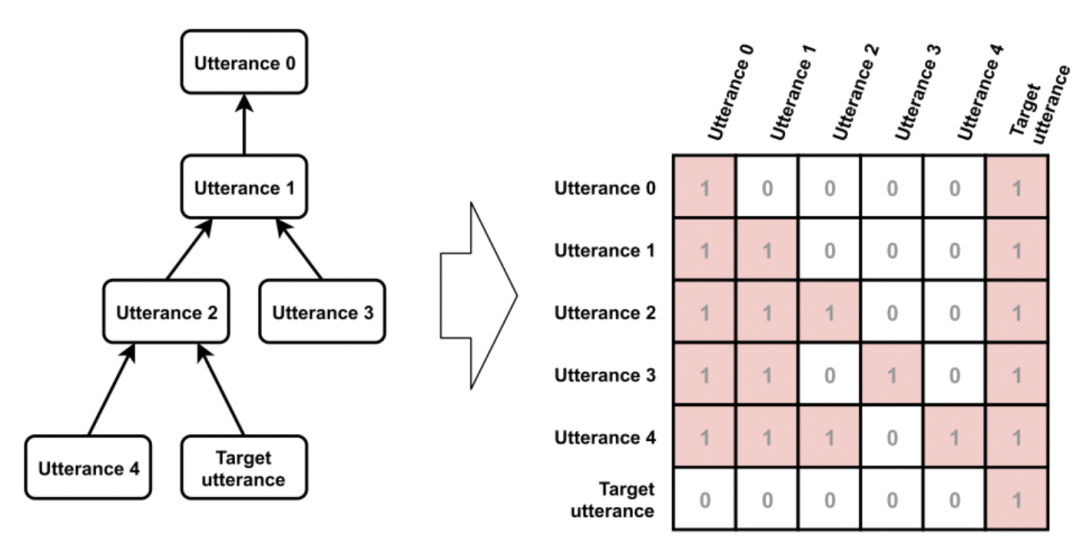
(Zhu et al. 2019[11])提出了使用Masked Hierarchical Transformer(MHT)来解决该任务。如图 8a 所示,MHT 主要包括 Utterance encoder、Masked Transformer 和 Output Layer 三个部分。Utterance encoder直接使用 Bert 预训练模型参数初始化,对utterance进行单词级别编码。Masked Transformer使用 Mask 机制来有效地利用对话的结构特点,对 utterance 进行句子级别的编码。Mask 矩阵构造示例如图 8b 所示,Mask 机制的设计主要遵循以下四点:
-
所有历史 utterance 都能够 attend 到 target utterance; -
每个 utterance 能够 attend 其自身; -
每个非 target utterance 能够 attend 其对话图中的祖先节点; -
剩下的 utterance 不做处理。
最后,将编码后的 utterances 经过全连接层和 softmax 分类器,获得其作为的 parent utterance 的概率。
接下来介绍第二个任务,其可以描述为:给定历史对话以及对话的thread标签,判断当前输入消息所属的 thread标签,如图9所示。

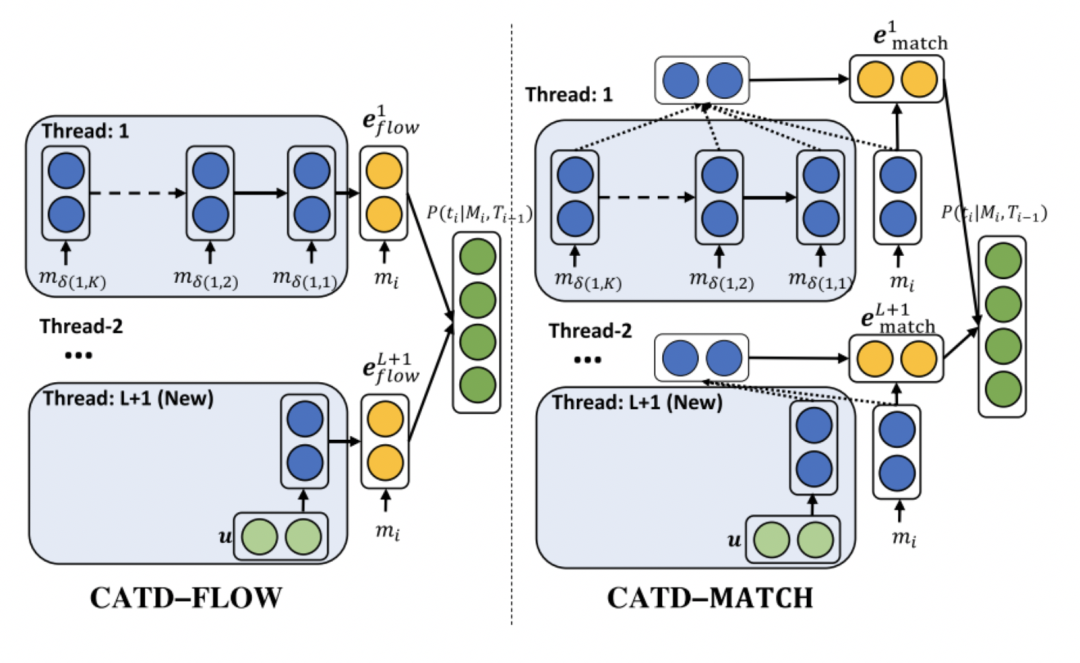
(Tan, Wang, and Wang 2019[9]) 提出了Context- Aware Thread Detection (CATD) 来解决该任务(论文中将该任务称为Thread Detection)。CATD主要分为CATD-FLOW和CATD-MATCH两个模型,分布捕捉thread历史上下文信息和thread上下文和输入消息的一致性信息(即相似性)。论文中使用Universal Sentence Encoder(USE)获得每个消息的句子表示,然后使用RNN编码每个thread最近的K个消息作为该thread的向量表示。具体来说:
-
CATD-FLOW,如图10左侧所示。使用单向LSTM编码每个thread的历史消息,最终输出作为该thread的向量表示;然后拼接每个thread向量表示和输入消息向量表示,记为 ;最后通过全连接层和softmax分类器获得输入消息属于每个thread标签的概率。
-
CATD-MATCH,如图10右侧所示。该部分thread向量表示和CATD-FLOW中的方式相同。该部分对thread和输入消息使用同一个单向 LSTM编码,从而获得更多语义层面的相似性;然后使用注意力机制,计算输入消息和thread上文消息之间相似性,进而得到thread的最终向量表示 ,如公式(1)所示:
其中 为输入消息的向量表示,将其与 进行点乘,得到匹配向量 ;最后通过全连接层和softmax分类器获得输入消息属于每个 thread 的概率。
-
CATD-COMBINE,使用权重参数,将上述 和 组合,作为最终thread表示,如公式(2)所示:
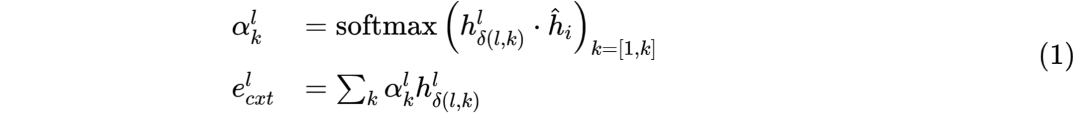 其中
其中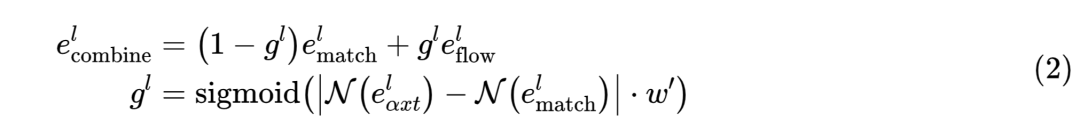
相关研究也将该任务称作Conversation Disentanglement(Shen et al. 2006[12])(Gmbh and Wezemael 2005[13])(Kummerfeld et al. 2019[4])。其中,(Kummerfeld et al. 2019[4]) 给出了一个用于 Conversation Disentanglement 的高质量大规模语料库。
总的来说,上述两种任务都可以看做隐式 Addressee 识别,更广泛的来说,都属于对话结构分析(Conversation Structure Modeling)(A. X. Zhang, Culbertson, and Paritosh 2017[14]),对于多方对话的建模有一定的借鉴意义。
3.1.2 显式Addressee识别
该部分将介绍显式Addressee识别任务,根据前提条件,可以分为两种情况:
-
当前说话人(Speaker)和回复(Response)均已知,求解 Addressee。该情况可以用于为多方对话的数据构建,如显式Addressee缺失补全问题。 -
当前说话人(Speaker)已知,但回复(Response)未知,求解 Addressee。该情况需要进行多任务学习,是多方对话机器人需要具备的基本功能。
下面将主要介绍第一种情况的已有研究方法,第二种情况的已有方法将在3.2节进行详细介绍。
在第一种情况中,(Le et al. 2019[7])提出了 Who-to-Whom(W2W)模型来解决对话历史中 Addressee 的缺失补全问题。该论文研究发现,在 IRC 数据中,66%的对话缺少显式的 addressee 标签,W2W 主要针对该情况对缺少的 addressee进行补全。W2W模型主要包括以下三个部分:
-
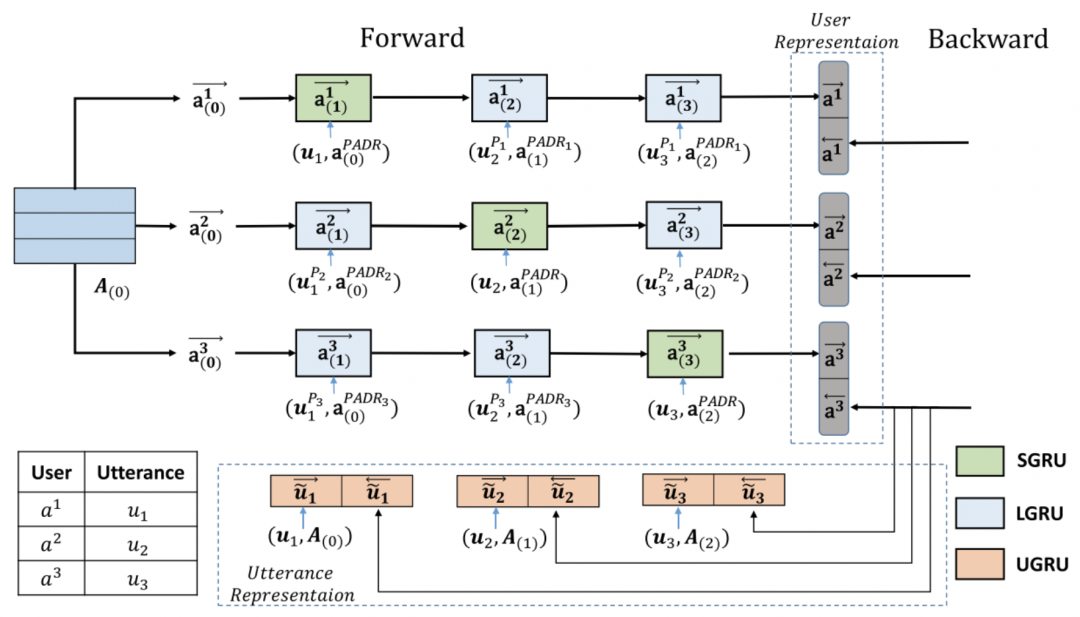
Initialization,对话语(utterance)和说话人(user 或 speaker)状态进行编码。Utterance Initialization Encoder 使用 Hierarchical RNN 进行句子编码,即首先使用 BiGRU 对 utterance 进行单词级别编码,然后使用 BiGRU 进行句子级别编码来捕捉上下文信息。Position-Based User Initialization 将对话历史中 speakers 按照首次出现倒序进行排列获得 speaker 向量矩阵 ,并使用零向量初始化。
-
Interactive Representation Learning,进行 utterance 和 user 的交互表示学习,不仅使用 utterance embedding 来更新 user 状态,而且将 user 状态融合进 utterance embedding 中。如图11所示,具体来说:
2.1 对于 user 状态(即 ),每一轮对话时,分别使用 SGRU 和 LGRU 更新 speaker 和 listener。考虑到 addressee 缺失的问题,论文中通过 Person Attention Mechanism(PAM)来计算伪 addressee 向量表示,从而进行 user 状态更新。PAM 可以使用以下公式(3)描述,其中 表示第 i 轮时,第 j 个 listener 向量(即 )和当前 speaker 向量(即 )的匹配得分,将所有listener 向量加权求和得到伪 addressee 向量表示(即 )。同时在更新第 j 个 listener 时会使用得分 对 speaker 和 utterance 进行惩罚。
2.2 对于utterance embedding,第t轮时使用 UGRU 更新 ,如公式(4)描述:
-
Matching,addressee 识别模块,对于每一轮的 addressee 计算如公式(5)所示,将当前 speaker 向量和 utterance 向量通过非线性融合得到 query,将 query 与每个 listener 做 bilinear 变换后使用 softmax,得到每个 listener 作为 addressee 的概率。
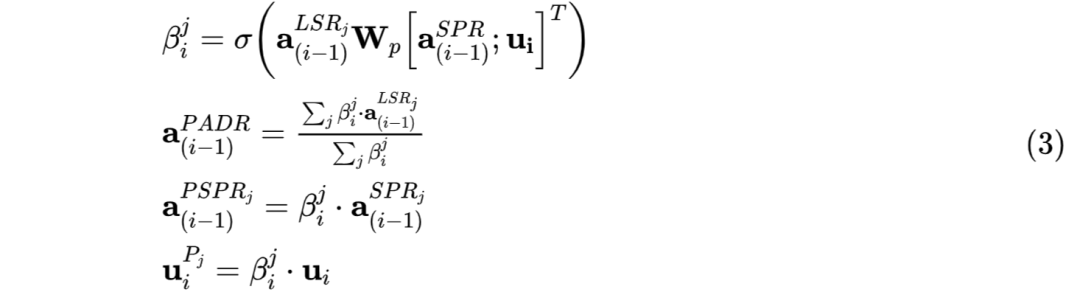 2.2 对于utterance embedding,第t轮时使用 UGRU 更新
2.2 对于utterance embedding,第t轮时使用 UGRU 更新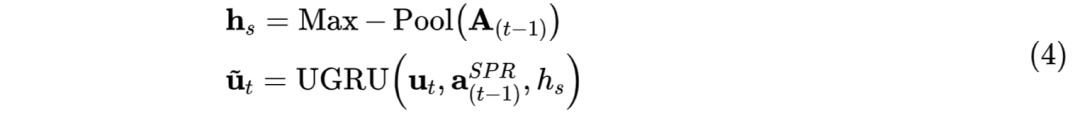
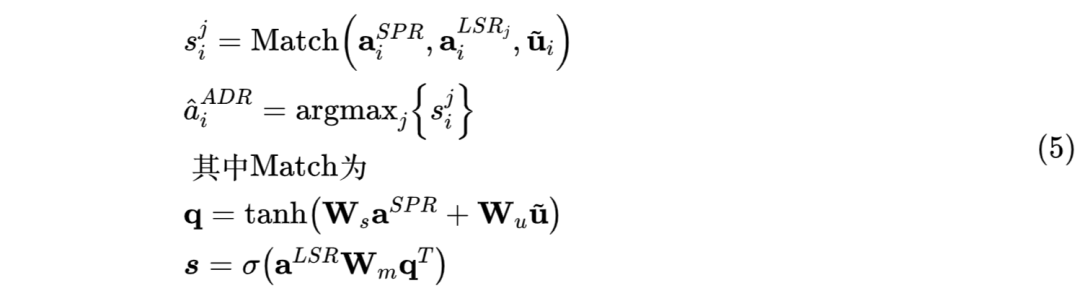
在第二种情况中,(Ouchi and Tsuboi 2016[5])和(R. Zhang et al. 2018[6])对 Addressee 选择和 Response 选择进行联合建模,使用多任务学习机制。论文中同样维护 speaker 向量矩阵,但只使用 utterance 来更新 speaker 的状态。(详情见3.2节)
3.2 Response生成(或选择)
该部分将介绍多方对话的回复生成(或选择)任务,即根据对话历史来进行回复生成(或选择)。根据对话历史信息的利用程度,我们可以将其分为以下两种情况:
-
基于Context信息,该情况仅使用对话历史信息(utterances)进行回复生成(或选择);
-
基于Addressee和Context信息,该情况可以根据Addressee信息的利用方式进一步分类:
2.1 当不需要进行 addressee 的显式标签预测时,即仅使用 addressee 信息增强 response generation/selection 可以视为 Stack-propagation 学习;
2.2 反之,可以视为 addressee selection 和 response generation/selection 的多任务学习(Multi-Task Learning)。
3.2.1 基于 Context 信息
该部分将介绍直接基于 Context 信息(对话历史,utterances)进行回复生成(或选择)的相关研究,并将详细介绍一种使用图结构建模对话进行回复生成的模型。
(Dziri et al. 2019[15]) 在HRED模型(Serban et al. 2016[16])基础上加入了主题信息,提出了THRED(Topical Hierarchical Recurrent Encoder Decoder),在Reddit数据集上进行回复生成实验,取得了较好的结果。但是,THRED 没有考虑多方对话的结构信息,仍然使用序列结构进行建模。
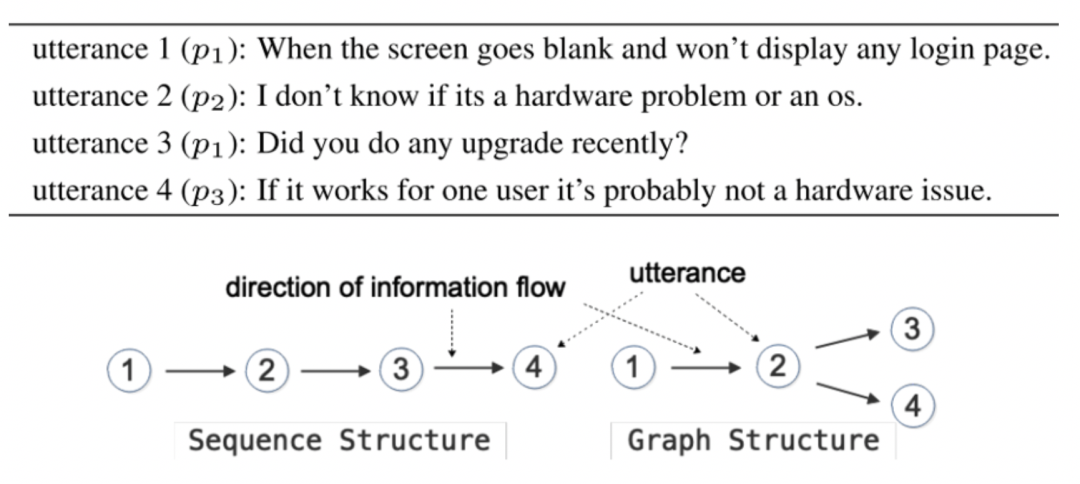
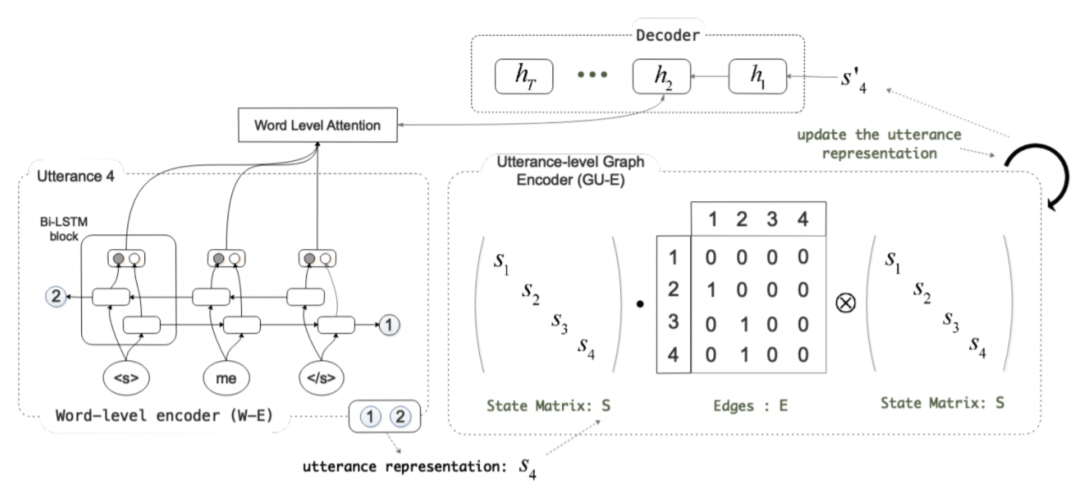
(Hu et al. n.d.[17])提出了Graph Structured Network(GSN)模型,首次尝试使用图建模多方对话历史,进行回复生成研究。如图12所示,Utterance 3 和 4 都是对 Utterance 2 的回复,可以表示为图结构。传统的 HRED 以及上述的 THRED 只能对序列结构进行建模,无法正确处理 Utterance3 和 4 的关系。而 GSN 针对图结构进行建模,能够有效的利用对话结构信息,其主要包括以下三个部分,如图13所示:
-
word-level encoder(W-E),使用 BiLSTM 对 utterance 进行单词级别编码,然后将两个方向的最后隐层状态拼接作为 utterance 的表示。
-
utterance-level graph-structured encoder(UG-E),UG-E 主要包括 utterance 信息的全图双向流动和 speaker 信息流动(在相同 speaker 的 utterance 之间建立边)。图更新算子主要使用门控机制(GRU),如公式(6)所示,其中 表示第i个节点在第l轮时的向量表示, 表示节点 i 的邻居节点集合。
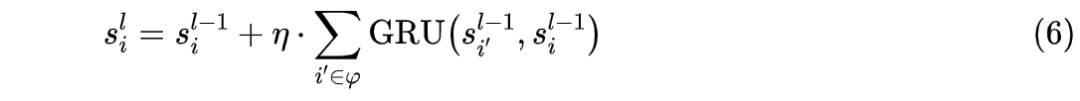
-
decoder,使用GRU进行回复生成,当对utterance i 进行回复生成时,使用utterance i经过 UG-E 编码之后的向量表示进行 GRU 隐层状态初始化。同时在生成过程中,使用注意力机制,将前一个生成词与 utterance i 的单词级别向量表示进行信息交互,如公式(7)所示:
其中
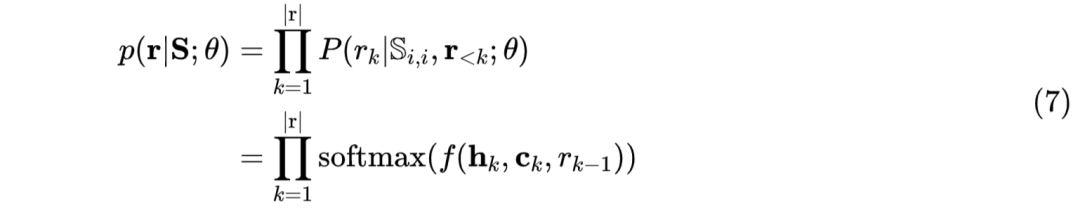 其中
其中
3.2.2 基于 Addressee 和 Context 信息
3.2.2.1 Stack-Propagation
该部分将介绍通过Stack-Propagation机制使用addressee信息进行回复生成(或选择)的相关研究方法。
当通过 Stack-Propagation 机制使用 addressee 信息进行回复生成(或选择)时,addressee 信息来源可以是根据对话历史预测的,也可能是已知。其共同点在于 addressee 标签预测不会参与模型最终 loss 计算,仅用于模型隐层使用。
(Yang et al. 2019[10])提出了MIDS(Multi-role Interposition Dialogue System)框架,在 Friends 数据集上进行说话对象选择和回复生成研究。MIDS 使用和 SI-RNN(R. Zhang et al. 2018[6])中相同的多角色建模机制,由于Friends数据集中角色个数是固定的,因此MIDS对于每个说话人使用一个单独GRU进行说话人向量更新,使用 Dual Encoder(Lowe et al. 2015[18])进行 addressee 概率预测。在回复生成时,融入 addressee 预测信息,使用注意力机制进行生成。
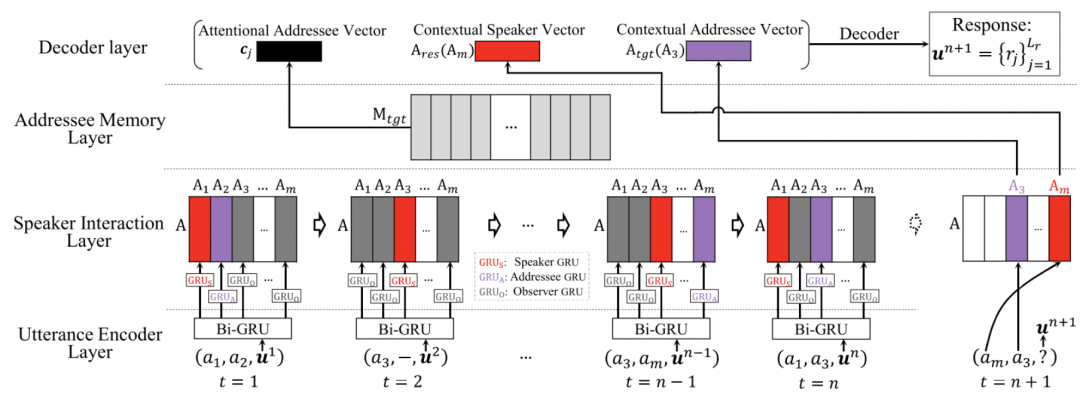
(Liu et al. 2019[19])提出了ICRED(Interlocutor-aware Contexts into Recurrent Encoder-Decoder frameworks)模型,在 Ubuntu IRC Logs 数据集上进行多方对话回复生成研究,该任务中已知 addressee,可以直接将 addressee 相关信息融入到回复生成中。ICRED 使用三种角色GRU对说话人向量进行更新,然后使用说话人向量和 Addressee 信息进行回复生成。如图14所示,ICRED 主要包括以下四个部分:
-
Utterance Encoder Layer,使用双向 GRU 进行单词级别的 utterance 编码,将两个方向的最后隐层向量拼接作为 utterance 的最终表示。
-
Speaker Interaction Layer,维护一个说话人(speaker)向量矩阵,在每一轮对话时,基于参与者的角色(speaker,addressee,observer),分别使用三种 GRU 更新其 speaker 向量。
-
Addressee Memory Layer,考虑到 speaker 通常会对 addressee 说过的话进行回复,该部分直接将 addressee 在对话历史中的最后一个回复的向量表示 融入回复生成中。
-
Decoder Layer,该部分使用 GRU 进行回复生成,其中使用了注意力机制,并融入当前 speaker 和 addressee 向量,如公式(8)所示,其中 表示第j个生成词, 和 分别表示 speaker 和 addressee 向量。
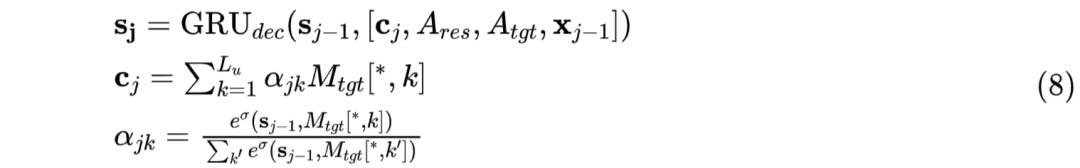
除此以外,(Li et al. 2016[20])中提出dyadic speaker-addressee 模型,在回复中加入了speaker和addressee信息进行回复生成任务,也可以归为此类,此处将不再赘述。
3.2.2.2 Multi-Task Learning
该部分主要介绍addressee和response联合选择任务(Addressee and Response Selection,ARS)的相关模型方法。
(Ouchi and Tsuboi 2016[5])首次提出了ARS任务,其可以这样形式化描述为:
在多方对话场景中,给定当前说话人 和对话历史 :
其表示在时刻 时, 对 说了话语 ,其中 是在进行 ARS 任务进行的总对话轮数。将 中的所有说话人集合记为 ,ARS 任务则需要从 中选择合适的说话人作为当前的说话对象;同时,需要从候选回复 中选择合适的回复。
(Ouchi and Tsuboi 2016[5])中提出了基于 Dual Encoder 的 Dynamic RNN 模型。Dynamic RNN 维护一个说话人向量矩阵,使用对应说话人的所有话语更新该向量,更新时使用单向 GRU ,如图15左所示。对得到的说话人向量矩阵进行最大池化操作,作为 Context 向量,记作
。预测时,将当前说话人向量
和
拼接,然后分别与每个说话人向量
和候选回复向量表示
经过双线性变换操作得到最终隐层向量,最后经过 softmax 分类获得作为说话对象和正确回复的概率,如公式(9)所示:
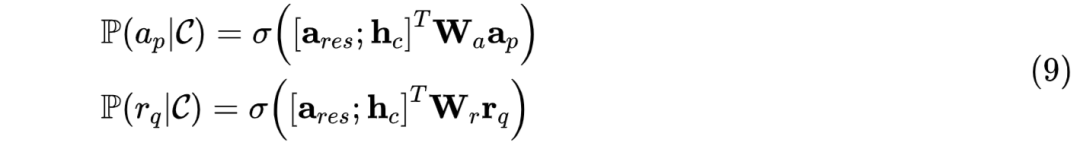
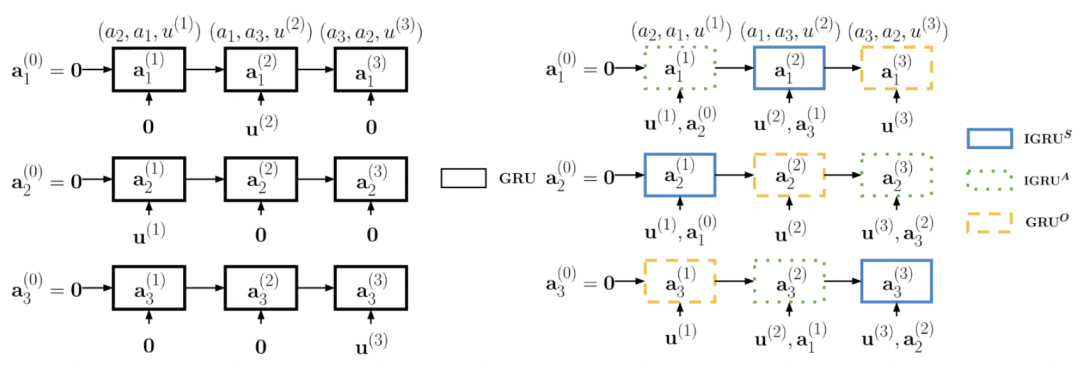
(R. Zhang et al. 2018[6])基于 Dynamic RNN 提出了 SI-RNN 模型(Speaker-Interaction RNN)。SI-RNN 使用角色敏感的 speaker 向量更新方式,即每一轮对话时,不同角色(sender,addressee,observer)使用不同的 GRU 单元进行更新,多轮对话更新过程如图15右所示,更新操作可使用公式(10)描述:
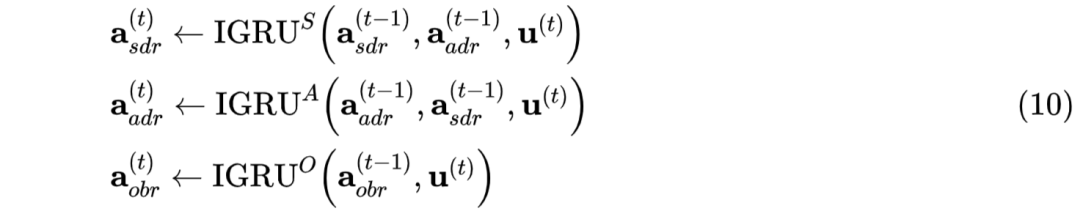
同时,SI-RNN 中还使用联合概率建模 addressee 和 response 的选择。训练时,分别以 gold addressee 和 gold response 作为前提,从而进行 response 选择和 addressee 选择,如公式(11)所示。预测时,使用联合最大概率进行选择,如公式(12)所示。
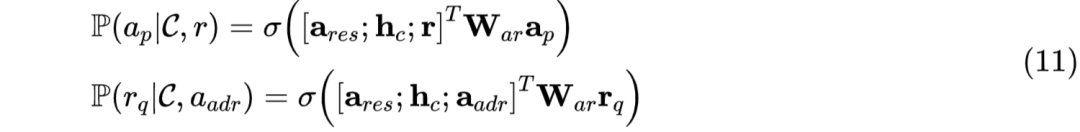
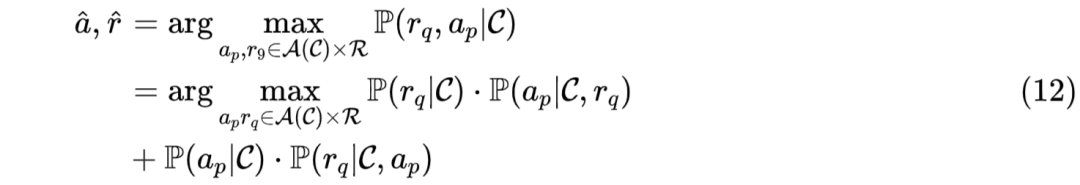
4 其他相关任务
-
Turn Taking
Turn Taking是构建多机器人系统的一种重要问题,主要任务是预测多方对话中下一个最有可能进行互动的参与者,即说话人预测(speaker,区别于 addressee 预测)。(M. G. de Bayser et al. 2019[21])使用机器学习算法(MLE 和 SVM)来进行 Turn Taking 研究。(G. De Bayser, Guerra, and Cavalin 2020[22])提出了一个集成 MLE、CNN 和 FSA 的系统在 MultiWOZ 数据集上进行 Turn Taking 研究。 -
Discourse Parsing
Discourse Parsing(多方对话语篇解析)主要分析对话历史中utterances的关系,例如Comment、Acknowledgement、Question-answer pair等类型。前文隐式addressee识别中reply-to可以看做一种关系类型。
简介参考《赛尔笔记 | 多人对话语篇解析简介》 -
Speaker Modeling
在前文关于Addressee信息利用部分,实际上已经使用了说话人建模的相关技术。在相关论文中,也有从其他角度进行建模的方法,如(Meng, Mou, and Jin 2018[23])提出使用 speaker classification 任务来作为 speaker modeling 的替代方案,即通过预测每个 utterance 所属 speaker 来实现。 -
Entity Linking
Entity Linking主要是对多方对话历史进行分析,解决对话中人称和角色的链接问题(Chen and Choi 2016[24])。(Aina et al. 2019[25])也将该问题称为角色识别问题(Character Identification),SemEval 2018曾将其作为一个子任务进行评测(Choi and Chen 2018[26])。 -
Emotion Recognition
加入情感分析的对话系统一般能产生更合适的回复(Zhou et al. 2018[27])(Rashkin et al. 2018[28])。目前多方对话中的情感识别数据集大多是多模态数据(Poria et al. 2019[29]),单独从 NLP 领域使用文本的研究较少。 -
Entrainment
Entrainment 是说话者在对话过程中开始表现出彼此相似的一种倾向(Levitan et al. 2015[30])。(Zahra Rahimi 2020[30])使用图结构进行 Entrainment 表示研究,并在下游任务(如团队影响力分析)上取得较好的效果。
5 总结
总的来说,目前多方对话研究内容比较广泛,但在人机对话领域,相关研究还不是很多。本文主要从人机对话领域,对近几年多方对话的相关任务做了梳理分类和简述,希望能为之后的研究工作提供些许参考。
参考资料
Traum, David. Issues in Multiparty Dialogues.Pdf. 2003.
[2]Uthus, David C., and David W. Aha. Multiparticipant Chat Analysis: A Survey. Artificial Intelligence 199–200: 106–21. 2013. http://dx.doi.org/10.1016/j.artint.2013.02.004.
[3]Qin, Libo et al. A Stack-Propagation Framework with Token-Level Intent Detection for Spoken Language Understanding. 2019.
[4]Kummerfeld, Jonathan K. et al. A Large-Scale Corpus for Conversation Disentanglement. 2019.
[5]Ouchi, Hiroki, and Yuta Tsuboi. Addressee and Response Selection for Multi-Party Conversation. 2016.
[6]Zhang, Rui, Honglak Lee, Lazaros Polymenakos, and Dragomir Radev. Addressee and Response Selection in Multi-Party Conversations with Speaker Interaction RNNs. AAAI. 2018.
[7]Le, Ran et al. Who Is Speaking to Whom? Learning to Identify Utterance Addressee in Multi-Party Conversations. EMNLP. 2019.
[8]Jiang, Jyun Yu, Francine Chen, Yan Ying Chen, and Wei Wang. Learning to Disentangle Interleaved Conversational Threads with a Siamese Hierarchical Network and Similarity Ranking. NAACL HLT. 2018.
[9]Tan, Ming, Dakuo Wang, and Haoyu Wang. Context-Aware Conversation Thread Detection in Multi-Party Chat. 2019.
[10]Yang, Qichuan et al. End-to-End Personalized Humorous Response Generation in Untrimmed Multi-Role Dialogue System. IEEE Access. 2019.
[11]Zhu, Henghui et al. Who Did They Respond to? Conversation Structure Modeling Using Masked Hierarchical Transformer. AAAI. 2019. http://arxiv.org/abs/1911.10666
[12]Shen, Dou, Qiang Yang, Jian Tao Sun, and Zheng Chen. Thread Detaction in Dynamic Text Message Streams. SIGIR. 2016.
[13]Gmbh, Copernicus, and J E Van Wezemael. Contributions to Economical. Social Geography Discussions. 2005. http://www.aclweb.org/anthology/P08-1095
[14]Zhang, Amy X., Bryan Culbertson, and Praveen Paritosh. Characterizing Online Discussion Using Coarse Discourse Sequences. ICWSM. 2017.
[15]Dziri, Nouha, Ehsan Kamalloo, Kory Mathewson, and Osmar Zaiane. Augmenting Neural Response Generation with Context-Aware Topical Attention. 2019.
[16]Serban, Iulian V. et al. Building End-To-End Dialogue Systems Using Generative Hierarchical Neural Network Models. AAAI. 2016.
[17]Hu, Wenpeng et al. GSN : A Graph-Structured Network for Multi-Party Dialogues.
[18]Lowe, Ryan, Nissan Pow, Iulian V. Serban, and Joelle Pineau. The Ubuntu Dialogue Corpus: A Large Dataset for Research in Unstructured Multi-Turn Dialogue Systems. SIGDIAL. 2015.
[19]Liu, Cao et al. Incorporating Interlocutor-Aware Context into Response Generation on Multi-Party Chatbots. 2019. http://arxiv.org/abs/1910.13106
[20]Li, Jiwei et al. A Persona-Based Neural Conversation Model. ACL. 2016.
[21]de Bayser, Maira Gatti, Paulo Cavalin, Claudio Pinhanez, and Bianca Zadrozny. Learning Multi-Party Turn-Taking Models from Dialogue Logs. 2019. http://arxiv.org/abs/1907.02090
[22]Bayser, Gatti De, Melina Alberio Guerra, and Paulo Cavalin. A Hybrid Solution to Learn Turn-Taking in Multi-Party Service-Based Chat Groups. 2020.
[23]Meng, Zhao, Lili Mou, and Zhi Jin. Towards Neural Speaker Modeling in Multi-Party Conversation: The Task, Dataset, and Models. AAAI. 2018.
[24]Chen, Yu-Hsin, and Jinho D. Choi. Character Identification on Multiparty Conversation: Identifying Mentions of Characters in TV Shows. 2016.
[25]Aina, Laura et al. What Do Entity-Centric Models Learn? Insights from Entity Linking in Multi-Party Dialogue. 2019.
[26]Choi, Jinho D., and Henry Y. Chen. SemEval 2018 Task 4: Character Identification on Multiparty Dialogues. 2018.
[27]Zhou, Hao et al. Emotional Chatting Machine: Emotional Conversation Generation with Internal and External Memory. AAAI. 2018.
[28]Rashkin, Hannah, Eric Michael Smith, Margaret Li, and Y-Lan Boureau. I Know the Feeling: Learning to Converse with Empathy. 2018. http://arxiv.org/abs/1811.00207
[29]Poria, Soujanya et al. MELD: A Multimodal Multi-Party Dataset for Emotion Recognition in Conversations. 2019.
[30]Zahra Rahimi, Diane Litman. Entrainment2Vec : Embedding Entrainment for Multi-Party Dialogues. AAAI. 2020.
本期编辑:顾宇轩
『哈工大SCIR』公众号