多轮对话之对话管理:Dialog Management
作者丨徐阿衡
学校丨卡耐基梅隆大学硕士
研究方向丨QA系统
本文经授权转载自知乎专栏「徐阿衡-自然语言处理」。
开始涉猎多轮对话,这一篇想写一写对话管理(Dialog Management),感觉是个很庞大的工程,涉及的知识又多又杂,在这里只好挑重点做一个引导性的介绍,后续会逐个以单篇形式展开。
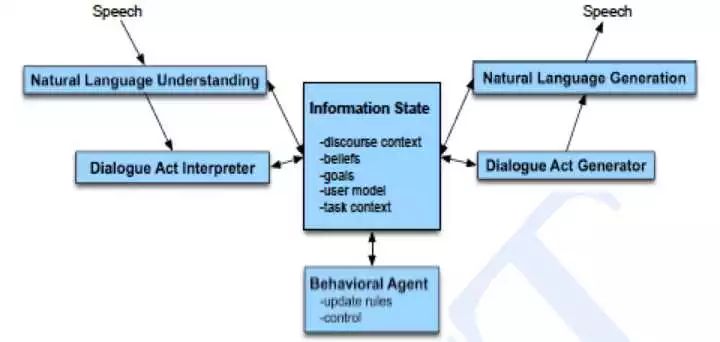
放一张多轮语音对话流程图,理解下 DM 在整个对话流程中处于什么地位。
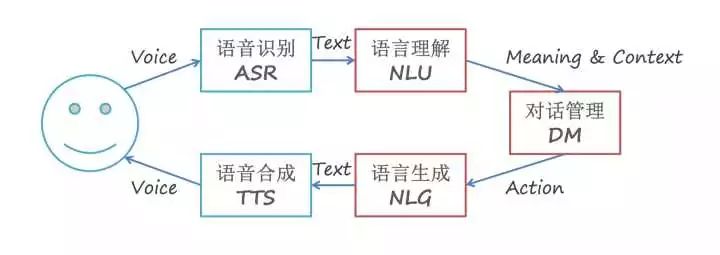
简单描述一下这个流程图常见的一种信息流动方式,首先是语音识别 ASR,产生语音识别结果也就是用户话语;语义解析模块 NLU 将
映射成用户对话行为
;对话管理模块 DM 选择需要执行的系统行为
。
如果这个系统行为需要和用户交互,那么语言生成模块 NLG 会被触发,生成自然语言或者说是系统话语;最后,生成的语言由语音合成模块 TTS 朗读给用户听。
这一篇第一部分介绍下对话管理及重要的几个小知识点,第二部分介绍对话管理的一些方法,主要有三大类:
Structure-based Approaches
Key phrase reactive
Tree and FSM
…
Principle-based Approaches
Frame
Information-State
Plan
…
Statistical Approaches
这一类其实和上面两类有交叉…不过重点想提的是:
Reinforcement Learning
方法不等于模型,这里只介绍一些重要概念,不会涉及模型细节。
Dialog Management
对话管理(Dialog Management, DM)控制着人机对话的过程,DM 根据对话历史信息,决定此刻对用户的反应。最常见的应用还是任务驱动的多轮对话,用户带着明确的目的如订餐、订票等,用户需求比较复杂,有很多限制条件,可能需要分多轮进行陈述。
一方面,用户在对话过程中可以不断修改或完善自己的需求,另一方面,当用户的陈述的需求不够具体或明确的时候,机器也可以通过询问、澄清或确认来帮助用户找到满意的结果。
总的来说,对话管理的任务大致有下面一些:
1. 对话状态维护(dialog state tracking, DST)
t+1 时刻的对话状态,依赖于之前时刻 t 的状态
,和之前时刻 t 的系统行为
,以及当前时刻 t+1 对应的用户行为
。可以写成
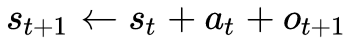
2. 生成系统决策(dialog policy)
根据 DST 中的对话状态(DS),产生系统行为(dialog act),决定下一步做什么 dialog act 可以表示观测到的用户输入(用户输入 -> DA,就是 NLU 的过程),以及系统的反馈行为(DA -> 系统反馈,就是 NLG 的过程)。
3. 作为接口与后端/任务模型进行交互
4. 提供语义表达的期望值(expectations for interpretation)
interpretation:用户输入的 internal representation,包括 speech recognition 和 parsing/semantic representation 的结果。
本质上,任务驱动的对话管理实际就是一个决策过程,系统在对话过程中不断根据当前状态决定下一步应该采取的最优动作(如:提供结果,询问特定限制条件,澄清或确认需求等),从而最有效的辅助用户完成信息或服务获取的任务。

如图,DM 的输入就是用户输入的语义表达(或者说是用户行为,是 NLU 的输出)和当前对话状态,输出就是下一步的系统行为和更新的对话状态。这是一个循环往复不断流转直至完成任务的过程。
其中,语义输入就是流转的动力,DM 的限制条件(即通过每个节点需要补充的信息/付出的代价)就是阻力,输入携带的语义信息越多,动力就越强;完成任务需要的信息越多,阻力就越强。
一个例子:

实际上,DM 可能有更广泛的职责,比如融合更多的信息(业务+上下文),进行第三方服务的请求和结果处理等等。
Initiative
对话引擎根据对话按对话由谁主导可以分为三种类型:
系统主导:系统询问用户信息,用户回答,最终达到目标。
用户主导:用户主动提出问题或者诉求,系统回答问题或者满足用户的诉求。
混合:用户和系统在不同时刻交替主导对话过程,最终达到目标。
有两种类型,一是用户/系统转移任何时候都可以主导权,这种比较困难,二是根据 prompt type 来实现主导权的移交。
Prompts 又分为 open prompt(如 ‘How may I help you‘ 这种,用户可以回复任何内容 )和 directive prompt(如 ‘Say yes to accept call, or no’ 这种,系统限制了用户的回复选择)。
Basic Concepts
Ground and Repair
对话是对话双方共同的行为,双方必须不断地建立共同基础(common ground, Stalnaker, 1978),也就是双方都认可的事物的集合。共同基础可以通过听话人依靠(ground)或者确认(acknowledge)说话人的话段来实现。
确认行为(acknowledgement)由弱到强的 5 种方法(Clark and Schaefer 1989)有:持续关注(continued attention),相关邻接贡献(relevant next contribution),确认(acknowledgement),表明(demonstration),展示(display)。
听话人可能会提供正向反馈(如确认等行为),也可能提供负向反馈(如拒绝理解/要求重复/要求 rephrase 等),甚至是要求反馈(request feedback)。
如果听话人也可以对说话人的语段存在疑惑,会发出一个修复请求(request for repair),如:

还有的概念如 speech acts,discourse 这类,之前陆陆续续都介绍过一些了。
Challenges
人的复杂性(complex)、随机性(random)和非理性化(illogical)的特点导致对话管理在应用场景下面临着各种各样的问题,包括但不仅限于:
模型描述能力与模型复杂度的权衡
用户对话偏离业务设计的路径
如系统问用户导航目的地的时候,用户反问了一句某地天气情况。
多轮对话的容错性
如 3 轮对话的场景,用户已经完成 2 轮,第 3 轮由于 ASR 或者 NLU 错误,导致前功尽弃,这样用户体验就非常差。
多场景的切换和恢复
绝大多数业务并不是单一场景,场景的切换与恢复即能作为亮点,也能作为容错手段之一。
降低交互变更难度,适应业务迅速变化
跨场景信息继承
Structure-based Approaches
Key Pharse Reactive Approaches
本质上就是关键词匹配,通常是通过捕捉用户最后一句话的关键词/关键短语来进行回应,比较知名的两个应用是 ELIZA 和 AIML。
AIML (人工智能标记语言),XML 格式,支持 ELIZA 的规则,并且更加灵活,能支持一定的上下文实现简单的多轮对话(利用 that),支持变量,支持按 topic 组织规则等。
<category>
<pattern>DO YOU KNOW WHO * IS</pattern>
<template><srai>WHO IS <star/></srai></template>
</category>
<category>
<pattern>MOTHER</pattern>
<template> Tell me more about your family. </template>
</category>
<category>
<pattern>YES</pattern>
<that>DO YOU LIKE MOVIES</that>
<template>What is your favorite movie?</template>
</category>
附上自己改写的 aiml 地址[1],在原有基础上增添了一些功能:
支持 python3
支持中文
支持 * 扩展
Trees and FSM-based Approaches
Trees and FSM-based approach 通常把对话建模为通过树或者有限状态机(图结构)的路径。相比于 simple reactive approach,这种方法融合了更多的上下文,能用一组有限的信息交换模板来完成对话的建模。
这种方法适用于:
系统主导
需要从用户收集特定信息
用户对每个问题的回答在有限集合中
这里主要讲 FSM,把对话看做是在有限状态内跳转的过程,每个状态都有对应的动作和回复,如果能从开始节点顺利的流转到终止节点,任务就完成了。
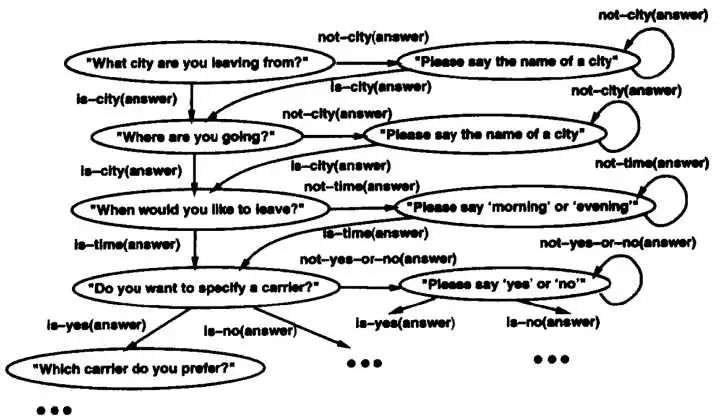
FSM 的状态对应系统问用户的问题,弧线对应将采取的行为,依赖于用户回答。
FSM-based DM 的特点是:
人为定义对话流程
完全由系统主导,系统问,用户答
答非所问的情况直接忽略
建模简单,能清晰明了的把交互匹配到模型
难以扩展,很容易变得复杂
适用于简单任务,对简单信息获取很友好,难以处理复杂的问题
缺少灵活性,表达能力有限,输入受限,对话结构/流转路径受限
对特定领域要设计 task-specific FSM,简单的任务 FSM 可以比较轻松的搞定,但稍复杂的问题就困难了,毕竟要考虑对话中的各种可能组合,编写和维护都要细节导向,非常耗时。
一旦要扩展 FSM,哪怕只是去 handle 一个新的 observation,都要考虑很多问题。实际中,通常会加入其它机制(如变量等)来扩展 FSM 的表达能力。
Principle-based Approaches
Frame-based Approaches
Frame-based approach 通过允许多条路径更灵活的获得信息的方法扩展了基于 FSM 的方法,它将对话建模成一个填槽的过程,槽就是多轮对话过程中将初步用户意图转化为明确用户指令所需要补全的信息。
一个槽与任务处理中所需要获取的一种信息相对应。槽直接没有顺序,缺什么槽就向用户询问对应的信息。

Frame-based DM 包含下面一些要素:
Frame:是槽位的集合,定义了需要由用户提供什么信息。
对话状态:记录了哪些槽位已经被填充 行为选择:下一步该做什么,填充什么槽位,还是进行何种操作。
行为选择:可以按槽位填充/槽位加权填充,或者是利用本体选择。
基于框架/模板的系统本质上是一个生成系统,不同类型的输入激发不同的生成规则,每个生成能够灵活的填入相应的模板。常常用于用户可能采取的行为相对有限、只希望用户在这些行为中进行少许转换的场合。
Frame-based DM 特点:
用户回答可以包含任何一个片段/全部的槽信息
系统来决定下一个行为
支持混合主导型系统
相对灵活的输入,支持多种输入/多种顺序
适用于相对复杂的信息获取
难以应对更复杂的情境
缺少层次
槽的更多信息可以参考这篇文章[2]。
Agenda + Frame (CMU Communicator)
Agenda + Frame (CMU Communicator) 对 frame model 进行了改进,有了层次结构,能应对更复杂的信息获取,支持话题切换、回退、退出。主要要素如下:
Product:树的结构,能够反映为完成这个任务需要的所有信息的顺序。相比于普通的 Tree and FSM approach,这里产品树(product tree)的创新在于它是动态的,可以在 session 中对树进行一系列操作比如加一个子树或者挪动子树 。
Process:
Agenda:相当于任务的计划(plan),类似栈的结构(generalization of stack),是话题的有序列表(ordered list of topics),也是 handler 的有序列表(list of handlers),handler 有优先级。
Handler:产品树上的每个节点对应一个 handler,一个 handler 封装了一个 information item。
从 product tree 从左到右、深度优先遍历生成 agenda 的顺序。当用户输入时,系统按照 agenda 中的顺序调用每个 handler,每个 handler 尝试解释并回应用户输入。
handler 捕获到信息就把信息标记为 consumed,这保证了一个 information item 只能被一个 handler 消费。
input pass 完成后,如果用户输入不会直接导致特定的 handler 生成问题,那么系统将会进入 output pass,每个 handler 都有机会产生自己的 prompt(例如,departure date handler 可以要求用户出发日期)。
可以从 handler 返回代码中确定下一步,选择继续 current pass,还是退出 input pass 切换到 output pass,还是退出 current pass 并等待来自用户输入等。
handler 也可以通过返回码声明自己为当前焦点(focus),这样这个 handler 就被提升到 agenda 的顶端。
为了保留特定主题的上下文,这里使用 sub-tree promotion 的方法,handler 首先被提升到兄弟节点中最左边的节点,父节点同样以此方式提升。
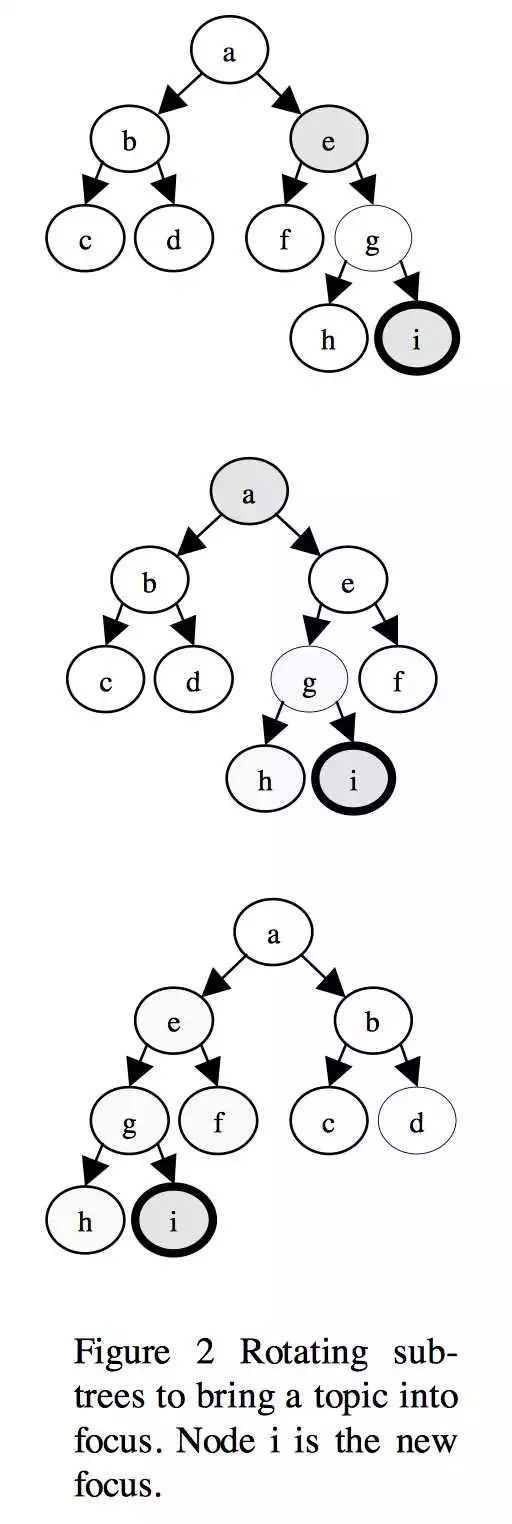
系统还能处理产品树中节点之间的依赖关系。典型的依赖关系在父节点和子节点之间。通常父节点的值取决于其子节点。每个节点都维护一个依赖节点的列表,并且会通知依赖节点值的变化,然后依赖节点可以声明自己是无效的并成为当前对话的候选主题。
给一个例子,能够回应用户的显式/隐式话题转移(A1-A3, U11),也能够动态添加子树到现有的 agenda(A8-A10)。

具体可参考论文:AN AGENDA-BASED DIALOG MANAGEMENT ARCHITECTURE FOR SPOKEN LANGUAGE SYSTEMS [3]。
Information-State Approaches
Information State Theories 提出的背景是:
很难去评估各种 DM 系统
理论和实践模型存在很大的 gap
理论型模型有:logic-based, BDI, plan-based, attention/intention,实践中模型大多数是 finite-state 或者 frame-based。即使从理论模型出发,也有很多种实现方法。
因此,Information State Models 作为对话建模的形式化理论,为工程化实现提供了理论指导,也为改进当前对话系统提供了大的方向。
Information-state theory 的关键是识别对话中流转信息的 relevant aspects,以及这些成分是怎么被更新的,更新过程又是怎么被控制的。
idea 其实比较简单,不过执行很复杂罢了。理论架构如下:
介绍下简单的一些要素:
Statics
Informational components:包括上下文、内部驱动因子(internal motivating factors),e.g., QUD, common ground, beliefs, intentions, dialogue history, user models, etc.
Formal representations:informational components 的表示,e.g., lists, records, DRSs,…
Dynamics
dialog moves:会触发更新 information state 的行为的集合,e.g., speech acts;
update rules:更新 information state 的规则集合,e.g., selection rules;
update strategy:更新规则的选择策略,选择在给定时刻选用哪一条 update rules。
意义在于可以遵循这一套理论体系来构建/分析/评价/改进对话系统。基于 information-state 的系统有:
TrindiKit Systems
– GoDiS (Larsson et al)
– information state: Questions Under Discussion
– MIDAS
– DRS information state, first-order reasoning (Bos &Gabsdil, 2000)
– EDIS
– PTT Information State, (Matheson et al 2000)
– SRI Autoroute –Conversational Game Theory (Lewin 2000)
Successor Toolkits
– Dipper (Edinburgh)
– Midiki (MITRE)
Other IS approaches
– Soar (USC virtual humans)
– AT&T MATCH system
Plan-based Approaches
一般指大名鼎鼎的 BDI (Belief, Desire, Intention) 模型。起源于三篇经典论文:
Cohen and Perrault 1979
Perrault and Allen 1980
Allen and Perrault 1980
基本假设是,一个试图发现信息的行为人,能够利用标准的 plan 找到让听话人告诉说话人该信息的 plan。这就是 Cohen and Perrault 1979 提到的 AI Plan model。
Perrault and Allen 1980 和 Allen and Perrault 1980 将 BDI 应用于理解,特别是间接言语语效的理解,本质上是对 Searle 1975 的 speech acts 给出了可计算的形式体系。
官方描述(Allen and Perrault 1980):
A has a goal to acquire certain information. This causes him to create a plan that involves asking B a question. B will hopefully possess the sought information. A then executes the plan, and thereby asks B the question. B will now receive the question and attempt to infer A’s plan. In the plan there might be goals that A cannot achieve without assistance. B can accept some of these obstacles as his own goals and create a plan to achieve them. B will then execute his plan and thereby respond to A’s question.
重要的概念都提到了,goals, actions, plan construction, plan inference。
理解上有点绕,简单来说就是 agent 会捕捉对 internal state (beliefs) 有益的信息,然后这个 state 与 agent 当前目标(goals/desires)相结合,再然后计划(plan/intention)就会被选择并执行。
对于 communicative agents 而言,plan 的行为就是单个的 speech acts。speech acts 可以是复合(composite)或原子(atomic)的,从而允许 agent 按照计划步骤传达复杂或简单的 conceptual utterance。
这里简单提一下重要的概念。
信念(Belief):基于谓词 KNOW,如果 A 相信 P 为真,那么用 B(A, P) 来表示。
期望(Desire):基于谓词 WANT,如果 S 希望 P 为真(S 想要实现 P),那么用 WANT(S, P) 来表示,P 可以是一些行为的状态或者实现,W(S, ACT(H)) 表示 S 想让 H 来做 ACT。
Belief 和 WANT 的逻辑都是基于公理。最简单的是基于 action schema。每个 action 都有下面的参数集:
前提(precondition):为成功实施该行为必须为真的条件。
效果(effect):成功实施该行为后变为真的条件。
体(body):为实施该行为必须达到的部分有序的目标集(partially ordered goal states)。
计划推理(Plan Recognition/Inference, PI):根据 B 实施的行为,A 试图去推理 B 的计划的过程。
PI.AE Action-Effect Rule(行为-效果规则)
PI.PA Precondition-Action Rule(前提-行为规则)
PI.BA Body-Action Rule(体-行为规则)
PI.KB Know-Desire Rule(知道-期望规则)
E1.1 Extended Inference Rule(扩展推理规则)
计划构建(Plan construction):
找到从当前状态(current state)达到目标状态(goal state)需要的行为序列(sequence of actions)。
Backward chaining,大抵是说,试图找到一个行为,如果这个行为实施了能够实现这个目标,且它的前提在初始状态已经得到满足,那么计划就完成了,但如果未得到满足,那么会把前提当做新的目标,试图满足前提,直到所有前提都得到满足。
Backward chaining 详细可参考 NLP 笔记 - Meaning Representation Languages [4]。
还有个重要的概念是 speech acts,在 NLP 笔记 - Discourse Analysis [5]中提到过,之后会细讲。更多可见 Plan-based models of dialogue [6]。
值得一提的是,基于 logic 和基于 plan 的方法虽然有更强大更完备的功能,但实际场景中并不常用,大概是因为大部分的系统都是相对简单的单个领域,任务小且具体,并不需要复杂的推理。
Statistical Approaches
RL-Based Approaches
前面提到的很多方法还是需要人工来定规则的(hand-crafted approaches),然而人很难预测所有可能的场景,这种方法也并不能重用,换个任务就需要从头再来。而一般的基于统计的方法又需要大量的数据。再者,对话系统的评估也需要花费很大的代价。
这种情况下,强化学习的优势就凸显出来了。RL-Based DM 能够对系统理解用户输入的不确定性进行建模,让算法来自己学习最好的行为序列。
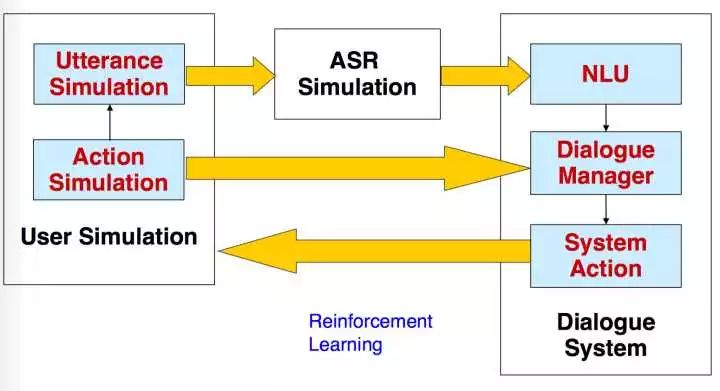
首先利用 simulated user 模拟真实用户产生各种各样的行为(捕捉了真实用户行为的丰富性),然后由系统和 simulated user 进行交互,根据 reward function 奖励好的行为,惩罚坏的行为,优化行为序列。
由于 simulated user 只用在少量的人机互动语料中训练,并没有大量数据的需求,不过 user simulation 也是个很难的任务就是了。
对话仿真的整体框架如下图:
相关链接
1. aiml 地址
https://github.com/Shuang0420/aiml
2. 填槽与多轮对话
http://t.cn/RQfkTPP
3. CMU Communicator 论文
http://www.cs.cmu.edu/~xw/asru99-agenda.pdf
4. NLP 笔记 - Meaning Representation Languages
http://t.cn/RQfFMAo
5. NLP 笔记 - Discourse Analysis
http://t.cn/RQfFacE
6. Plan-based models of dialogue
http://t.cn/RQfFC1b
我是彩蛋
解锁新功能:热门职位推荐!
PaperWeekly小程序升级啦
今日arXiv√猜你喜欢√热门职位√
找全职找实习都不是问题
解锁方式
1. 识别下方二维码打开小程序
2. 用PaperWeekly社区账号进行登陆
3. 登陆后即可解锁所有功能
职位发布
请添加小助手微信(pwbot01)进行咨询
长按识别二维码,使用小程序
*点击阅读原文即可注册

关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。



