ECCV 2020 | AFM:通过分组和自注意力抑制Mislabeled 数据
点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达

本文作者:JustTry
https://zhuanlan.zhihu.com/p/266301920
本文已由原作者授权,不得擅自二次转载
论文:Suppressing Mislabeled Data via Grouping and Self-Attention

https://www.ecva.net/papers/eccv_2020/papers_ECCV/papers/123610766.pdf
引言
近年来,深度神经网络(DNN)在图像识别任务中取得了巨大的成功,尤其是在大量标注正确的数据集(clean datasets)上。但是总是使用人工标注数据集是极其费时费力的,而且也存在标注错误的可能。目前有很多数据集是通过关键字下载网上的图片而得到的,但是这样的数据集存在很多标注错误(噪声标签)的图片。当从噪声标签(数据集中含有错误标签)中学习时,DNN的性能将大大降低。为了抑制标签错误的数据对图像识别任务的影响,本文提出了一个简单而有效的即插即用的训练模块—— Attentive Feature Mixup(AFM),它可以使更多的注意力集中在clean samples上,对noisy samples施加较小的权重,进而抑制mislabeled数据的影响。
AFM模块的优势
(i) 它不需要任何assumptions,也不需要额外的clean数据集
(ii) 该模块可以使得noisy数据集的比例得到降低
(iii) 它引入注意力机制降低mislabeled数据的权重,进而抑制mislabeled数据对模型的影响
(iv) AFM模块含有mixup模块,能够减少过拟合
模型
Attentive Feature Mixup(AFM) = Group-to-Attend (GA) + mixup
Group-to-Attend (GA):由group操作和attend操作组成
Group:将小批量的样本分组,得到一个个子样本
Attend:对所有分组的样本施加attention操作,对clean样本分配较大权重,noisy样本分配较小权重
mixup:2017年由MIT和FAIR提出,它是指利用数据和标签的随机线性插值提高神经网络的健壮性。通过mixup可以生成新的样本和新的标签。具体可参考:jianshu.com/p/980adca72
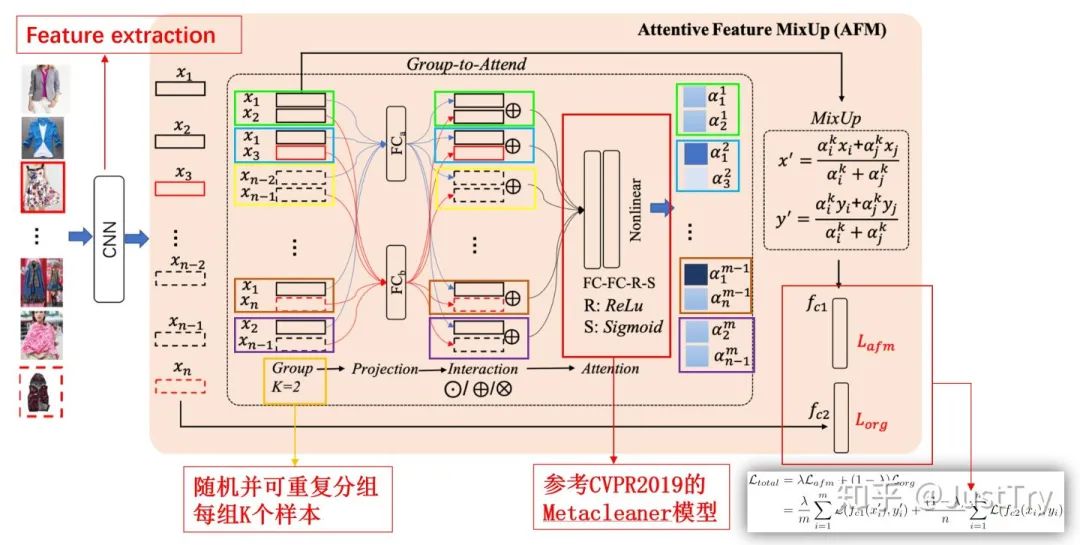
模型的具体算法如下:
1、将一个minibatch的样本经过CNN网络提取特征得到x1,...,xn
2、将n个特征随机并可重复地分成大量的组,每组含有K个特征,共m个组
3、将K个特征分别进入K个不同的全连接层(FC)(即Projection操作),得到每组新的特征
4、将每组的特征进行Interaction操作——拼接、点乘或相加
5、将Interaction操作得到的特征经过Attention模块处理,得到每组的K个权重值 注:Attention部分参照的CVPR2019的Metacleaner模型,该论文比较了三种划分权重的方法,最终得出FC-FC-R-S结构效果最好 当然,两层FC是为了实现非线性,在Sigmoid之前加上ReLu是为了保证权重值α在[0.5, 1]之间
6、MixUp:将所得的权重值(αi, αj)按比例施加到初始样本(xi, xj)上,得到新的样本x',同时,对样本空间y(one-hot变量)施加权重得到新的标签y'
7、将mixup操作得到的新的样本输入到插值分类器fc1中,得到Lafm损失函数;将初始噪声样本x1,...,xn经过常规分类器fc2,得到Lorg损失函数;对Lafm和Lorg损失函数进行线性加权,得到整个模型的最终的损失函数Ltotal进行训练————即本文采用的多任务训练模型(原样本和新样本)
值得注意的是,AFM模块仅运用在训练模型中,对对数据集进行分类的时候,去掉AFM模块。
上述算法体现了AFM模块的优势(iii)和优势(iv),但是对于上文提出的 优势(ii)使得noisy数据集的比例得到降低 如何体现呢?
以本文K=2为例,作者认为:两个clean的样本 --->(生成得到) 新的样本时,其label为clean的;
类内:一clean样本 + 一个noisy样本,经过Attention模块抑制noisy样本的权重,其label为clean;
类间:一clean样本 + 一个noisy样本,对神经网络训练没太大影响;
类内:一noisy样本 + 一个noisy样本,生成的新样本为noisy样本;
但是对于一个Ntotal的样本,其噪声标签的样本数为Nnoisy,那么每个样本是噪声样本的概率是Nnoisy / Ntotal;
然而对于生成的一个新样本,为噪声样本的前提是K(=2)个样本均为noisy样本,那么其概率经过排列组合之后,其概率明显减小了:
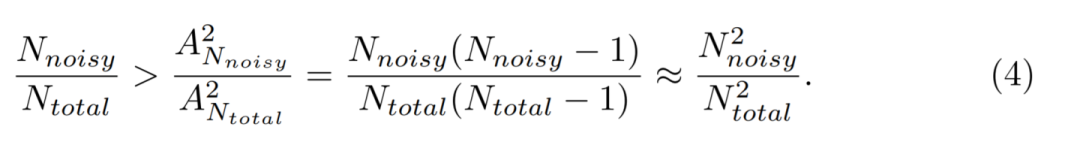
基于此,优势(ii)得到证明。
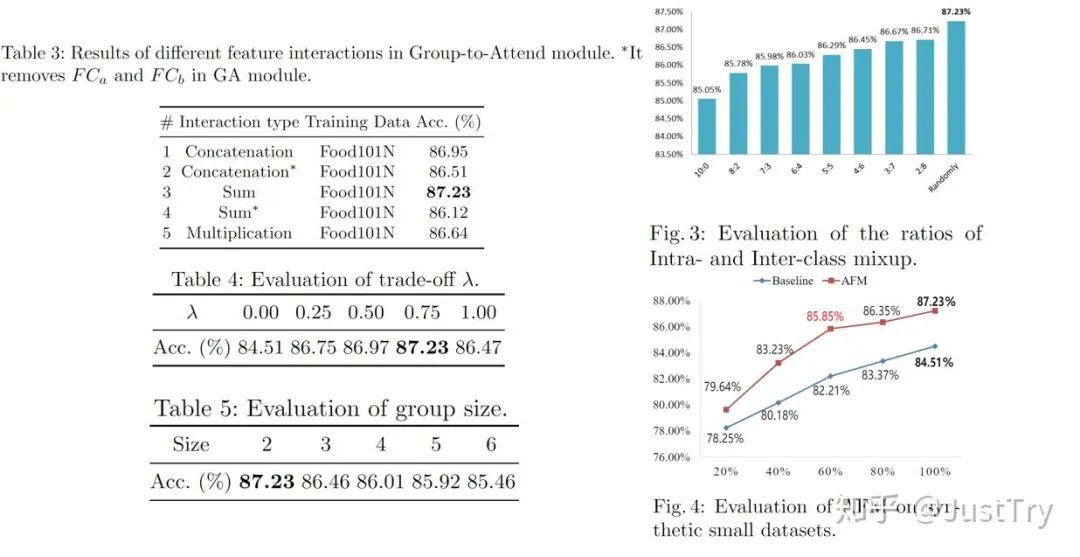
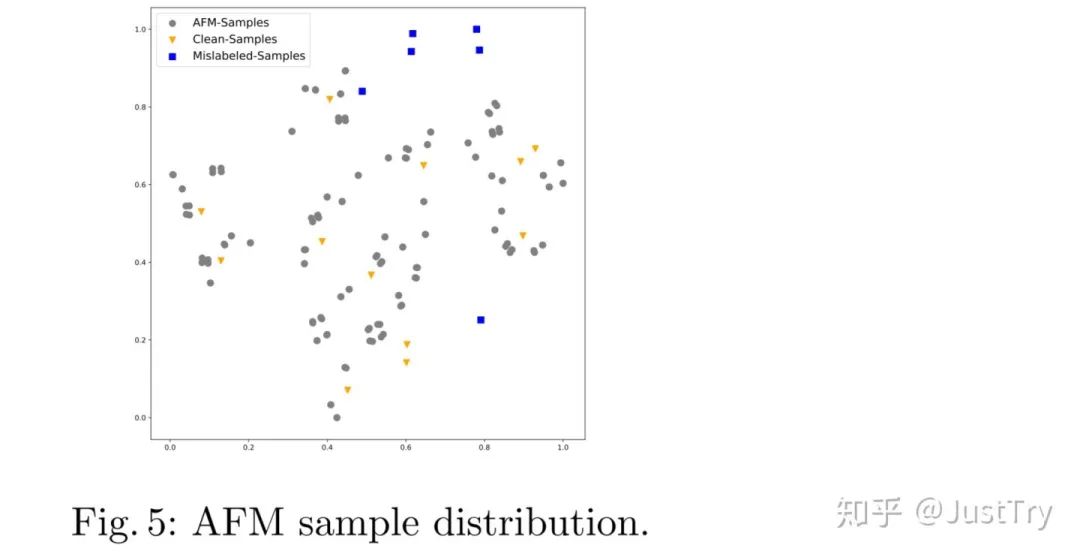
结果
作者在Food101N(标签准确度为80%)和Clothing1M(标签准确度为61.54%)进行训练,得到的结果增强了。(注:Clothing1M在只有噪声集下训练结果虽然不是最优,但是模型复杂度和计算复杂度比SMP(Final)低)
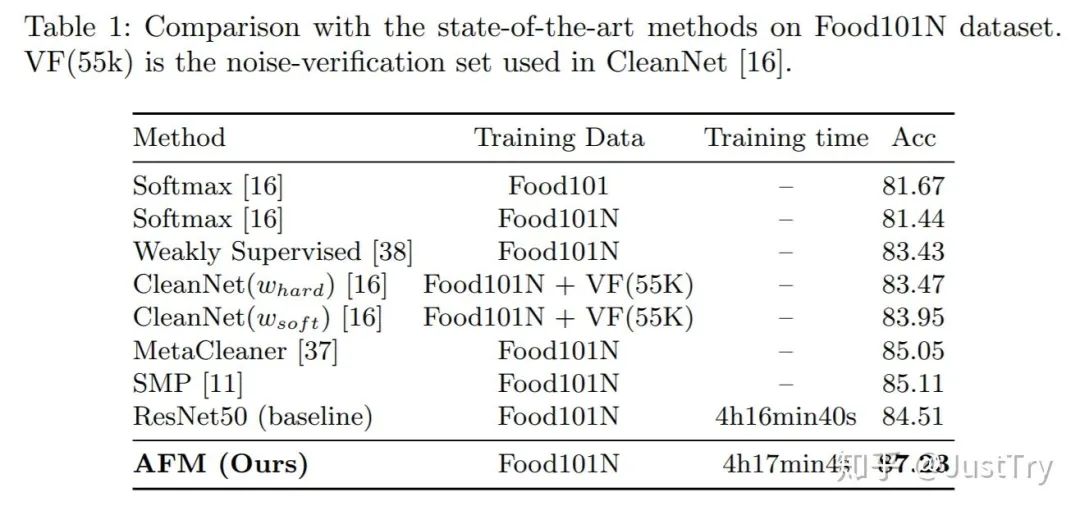
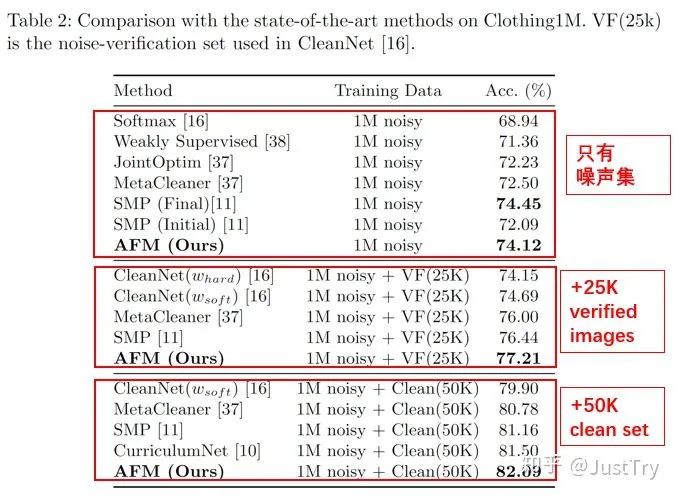
Ablation Study
下载1:动手学深度学习
在CVer公众号后台回复:动手学深度学习,即可下载547页《动手学深度学习》电子书和源码。该书是面向中文读者的能运行、可讨论的深度学习教科书,它将文字、公式、图像、代码和运行结果结合在一起。本书将全面介绍深度学习从模型构造到模型训练,以及它们在计算机视觉和自然语言处理中的应用。

下载2:CVPR / ECCV 2020开源代码
在CVer公众号后台回复:CVPR2020,即可下载CVPR 2020代码开源的论文合集
在CVer公众号后台回复:ECCV2020,即可下载ECCV 2020代码开源的论文合集
重磅!CVer-论文写作与投稿交流群成立
扫码添加CVer助手,可申请加入CVer-论文写作与投稿 微信交流群,目前已满2400+人,旨在交流顶会(CVPR/ICCV/ECCV/NIPS/ICML/ICLR/AAAI等)、顶刊(IJCV/TPAMI/TIP等)、SCI、EI、中文核心等写作与投稿事宜。
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如论文写作+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加微信群

▲长按关注CVer公众号
整理不易,请给CVer点赞和在看!



