![]()
作者 | VincentLee
编辑 | Camel
本文来源于微信公众号:晓飞的算法工程笔记
本文对发表于 AAAI 2020 的论文《Fine-grained Recognition: Accounting for Subtle Differences between Similar Classes》进行解读。
![]()
论文地址:https://arxiv.org/abs/1912.06842
论文提出了类似于dropout作用的diversification block,通过抑制特征图的高响应区域来反向提高模型的特征提取能力,在损失函数方面,提出专注于top-k类别的gradient-boosting loss来优化训练过程,模型在ResNet-50上提升3.2%,算法思路巧妙,结构易移植且效果也不错,值得学习。
一、简介
在FGVC(fine-grained visual categorization)上,一般的深度学习模型都是通过学习输入图片到输出标签的映射,这样会导致模型倾向于专注少部分显著区域来同时区分模糊的种群内(inter-class)相似性和种群间(intra-class)的变化
![]()
图 1
如图1所示,一般的深度学习模型的attention经常密集地集中在小部分区域,因此只会提出有限的特征。因此,论文建议分散attention来构建多样的分布在特征图上的特征。因为在特征层面进行attention分散,在预测时则需要反过来,例如只关注最相似的类别来提高模型的辨别能力。通过关注相似的类别以及分散模型的attention,论文实际是在让模型避免对训练集的overfiting,增加泛化能力。论文的主要贡献如下:
提出gradient-boosting loss,通过适当地调整梯度更新的幅度来解决高度相关类别的模糊部分;
提出diversification block,掩盖显著的特征,从而迫使网络去寻找外观相似的类别的不易察觉的不同点;
论文提出的方法能够加速模型的收敛以及提高识别的效果。
二、方法
![]()
论文提出的方法能简单地接到所有分类网络中,结构如图2所示。使用论文的方法,需要将主干网络的所有global pooling layer和最后的fully conntected layer替换成1x1 convolution,ouput channel等于类别数,模型主要包含两个部分:
-
diversification module,用于迫使网络去获取更多不易察觉的特征,而非专注于明显特征;
-
gradient boosting loss,使模型在训练时专注于容易混淆的类别。
1、Diversification Block
考虑如图2中
个类别的多标签分类任务,
为训练图片,
是对应的GT,diversification block的输入是类别特定(category-specific)的特征图
,由修改后的主干网络输出。标记
,其中
是对应类别
的独立特征图。diversification block的核心思想是抑制
中的明显区域,从而迫使网络去提取其它区域的特征,主要面临两个问题:1) 抑制哪些特征?2) 怎么抑制?
下面解释如何产生用于指明抑制区域的mask,定义
,
是二值抑制mask对应特征图
,1表示抑制,0表示不抑制。
![]()
![]()
首先对特征图的峰值进行随机抑制,因为这是对分类器最显著的部分,
是
的峰值mask,'*'是element-wise的相乘,而
是服从伯努利分布的随机值,即有
的概率为1。
![]()
将每个
分成多个固定大小的patch,定义l行m列的patch为
,
为patch的集合,
![]()
对应
的抑制mask,跟峰值的mask一样,使用伯努利分布对块进行赋值,随机值为1的块将整块进行抑制,
![]()
![]()
2)Activation Suppression Factor
![]()
为抑制后的特征图,
为抑制因子,后面的实验设置为0.1,
![]()
在进行特征抑制后,对特征进行global average pooling来获取最后的置信度
2、Gradient-boosting Cross Entropy Loss
diversification module用于发现更多不易察觉的细微特征,而gradient-boosting loss则是避免容易混淆的类别的误分。
![]()
论文认为,目前使用最广的交叉熵损失函数平均地考虑了所有的负类别,而在细粒度分类中,模型更应该关注相似的负类别,因此提出gradient-boosting cross entropy(GCE),只专注于top-k个负类别,
![]()
首先定义
为所有的负类别,
,
为所有负类别的得分,
为负类别的top-k类别集合,将
分别top-k集合和非top-k集合,
![]()
对交叉熵进行改造,只考虑top-k类别的计算,k一般设置为15。
![]()
![]()
公式13和公式14分别是交叉熵和GCE的梯度回传公式,
![]()
根据公式10和公式11的定义,可以发现公式15的包含关系,
![]()
因此可以推出GCE的梯度是要比交叉熵的梯度要大的,使用GCE能够让模型专注于区分混淆类别。
3、Training and Inference
diversification block仅在训练阶段使用,在测试阶段不再使用,改为将完整的特征图输入到global average pooling中。
三、实验
实验在5个最常用的数据机上进行——
![]()
1、Quantitative Results
![]()
![]()
其中两个数据集的结果如表2、表3所示,可以看到,论文提出的方法在效果上的提升还是挺不错的,而且参数量比较小,在另外几个数据集上,论文提出的方法也是比其它方法要出色。
2、Ablation Study
1)Diversification block (DB)
![]()
使用diversification block能让ResNet-50的性能提升0.8%。
如表4所示,使用gradient-boosting loss能让ResNet-50+DB从86.3%提升到87.7%,提升要比其它损失函数方法要好。
![]()
从实验看出,抑制因子
对实验结果影响挺大的,选择0.1的时候表现最好。
![]()
top-k的数量选择对结果影响也是比较大的,选择top-15的时候效果最好。
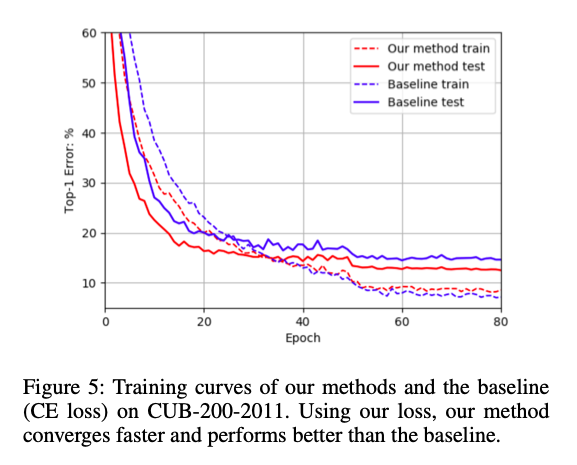
![]()
从图5可以看出,论文提出的方法收敛速度更快,尽管可以看到原始方法在训练集上的准确率比论文提出的方法要好,但是在测试集的表现不好,这说明原始方法对训练集有点过拟合了。
3、Qualitative Results
![]()
从图4可以看出,论文提出的方法提取了更多的特征区域。
4、ImageNet Results
为了进一步验证论文提出的模型的效果,在ImageNet上进行了实验。由于论文的方法专注于难样本,因此在50轮后的训练才进行对比,可以看到论文的方法的效果在ImageNet上还是不错的。
论文提出了diversification block以及gradient-boosting loss,diversification block通过随机抑制响应高的区域引导模型学习更多的不易察觉的特征,有点类似dropout的思想,而gradient-boosting loss则让模型专注于top-k个类别的学习,加大对应类别的梯度回传,使得训练收敛更快且提升性能。总体而言,论文的思路清晰,而且效果还是有的,可以实验下,然后当作基本方法加入到平时网络的架构中,特别是后面的gradient-boosting loss。
AAAI 2020 报道:
新型冠状病毒疫情下,AAAI2020 还去开会吗?
美国拒绝入境,AAAI2020现场参会告吹,论文如何分享?
AAAI 2020 论文解读系列:
13. [中科院自动化所] 通过解纠缠模型探测语义和语法的大脑表征机制
14. [中科院自动化所] 多模态基准指导的生成式多模态自动文摘
15. [南京大学] 利用多头注意力机制生成多样性翻译
16. [UCSB 王威廉组] 零样本学习,来扩充知识图谱(视频解读)
17. [上海交大] 基于图像查询的视频检索,代码已开源!
![]()
更多AAAI 2020信息,将在「AAAI 2020 交流群」中进行,加群方式:添加AI研习社顶会小助手(AIyanxishe2),备注「AAAI」,邀请入群。
![]()
![]()
![]()
![]() 点击“阅读原文” 前往 AAAI 2020 专题页
点击“阅读原文” 前往 AAAI 2020 专题页