深度 | SGD过程中的噪声如何帮助避免局部极小值和鞍点?
选自noahgolmant
作者:Noah Golmant
机器之心编译
参与:Geek AI、刘晓坤
来自 UC Berkeley RISELab 的本科研究员 Noah Golmant 发表博客,从理论的角度分析了损失函数的结构,并据此解释随机梯度下降(SGD)中的噪声如何帮助避免局部极小值和鞍点,为设计和改良深度学习架构提供了很有用的参考视角。
当我们着手训练一个很酷的机器学习模型时,最常用的方法是随机梯度下降法(SGD)。随机梯度下降在高度非凸的损失表面上远远超越了朴素梯度下降法。这种简单的爬山法技术已经主导了现代的非凸优化。然而,假的局部最小值和鞍点的存在使得分析工作更加复杂。理解当去除经典的凸性假设时,我们关于随机梯度下降(SGD)动态的直觉会怎样变化是十分关键的。向非凸环境的转变催生了对于像动态系统理论、随机微分方程等框架的使用,这为在优化解空间中考虑长期动态和短期随机性提供了模型。
在这里,我将讨论在梯度下降的世界中首先出现的一个麻烦:噪声。随机梯度下降和朴素梯度下降之间唯一的区别是:前者使用了梯度的噪声近似。这个噪声结构最终成为了在背后驱动针对非凸问题的随机梯度下降算法进行「探索」的动力。
mini-batch 噪声的协方差结构
介绍一下我们的问题设定背景。假设我想要最小化一个包含 N 个样本的有限数据集上的损失函数 f:R^n→R。对于参数 x∈R^n,我们称第 i 个样本上的损失为 f_i(x)。现在,N 很可能是个很大的数,因此,我们将通过一个小批量估计(mini-batch estimate)g_B: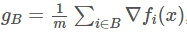
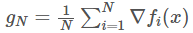
引理 1 (Chaudhari & Soatto 定理:https://arxiv.org/abs/1710.11029):在回置抽样(有放回的抽样)中,大小为 m 的 mini-batch 的方差等于 Var(g_B)=1/mD(x),其中
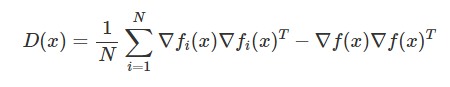
该结果意味着什么呢?在许多优化问题中,我们根本的目标是最大化一些参数配置的似然。因此,我们的损失是一个负对数似然。对于分类问题来说,这就是一个交叉熵。在这个例子中,第一项 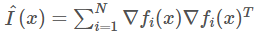
因此,mini-batch 噪声的协方差与我们损失的 Hessian 矩阵渐进相关。事实上,当 x 接近一个局部最小值时,协方差就趋向于 Hessian 的缩放版本。
绕道 Fisher 信息
在我们继续详细的随机梯度下降分析之前,让我们花点时间考虑 Fisher 信息矩阵 I(x) 和 Hessian 矩阵 ∇^2f(x) 之间的关系。I(x) 是对数似然梯度的方差。方差与损失表面的曲率有什么关系呢?假设我们处在一个严格函数 f 的局部最小值,换句话说,I(x∗)=∇^2f(x∗) 是正定的。I(x) 引入了一个 x∗附近的被称为「Fisher-Rao metric」的度量指标: d(x,y)=√[(x−y)^TI(x∗)(x−y) ]。有趣的是,参数的 Fisher-Rao 范数提供了泛化误差的上界(https://arxiv.org/abs/1711.01530)。这意味着我们可以对平坦极小值的泛化能力更有信心。
回到这个故事中来
接下来我们介绍一些关于随机梯度下降动态的有趣猜想。让我们做一个类似中心极限定理的假设,并且假设我们可以将估计出的 g_B 分解成「真实」的数据集梯度和噪声项:g_B=g_N+(1√B)n(x),其中 n(x)∼N(0,D(x))。此外,为了简单起见,假设我们已经接近了极小值,因此 D(x)≈∇^2f(x)。n(x) 在指数参数中有一个二次形式的密度ρ(z):
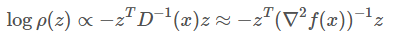
这表明,Hessian 矩阵的特征值在决定被随机梯度下降认为是「稳定」的最小值时起重要的作用。当损失处在一个非常「尖锐」(二阶导很大)的最小值,并且此处有许多绝对值大的、正的特征值时,我很可能会加入一些把损失从朴素梯度下降的吸引域中「推出来」的噪声。类似地,对于平坦极小值,损失更有可能「稳定下来」。我们可以用下面的技巧做到这一点:
引理 2:令 v∈R^n 为一个均值为 0 并且协方差为 D 的随机向量。那么,E[||v||^2]=Tr(D)。
通过使用这一条引理以及马尔可夫不等式,我们可以看到,当 Hessian 具有大曲率时,更大扰动的可能性越高。我们还可以考虑一个在局部最小值 x∗ 周围的「稳定半径」:对于给定的 ϵ∈(0,1),存在一些 r(x∗)>0,使得如果我们的起点 x_0 满足 ||x_0−x∗||<r(x∗),第 t 次迭代满足 ||x_t−x∗||<r(对于所有的 t≥0)的概率至少为 1−ϵ。在这种情况下,我们可以说 x∗ 是在半径 r(x∗) 内随机稳定的。将这种稳定性的概念与我们之前的非正式论证结合起来,我们得到以下结论:
定理 1: 一个严格的局部最小值 x∗ 的稳定性半径 r(x∗) 与 ∇^2f(x∗) 的谱半径成反比。
让我们把这个结论和我们所知道的 Fisher 信息结合起来。如果在随机梯度下降的动态下,平坦极小值更加稳定,这就意味着随机梯度下降隐式地提供了一种正则化的形式。它通过注入各项异性的噪声使我们摆脱了 Fisher-Rao 范数所带来的不利泛化条件。
深度学习的启示:Hessian 矩阵的退化和「wide valleys」
在深度学习中,一个有趣的现象是过度参数化。我们经常有比做示例运算时更多的参数(d>>N)。这时,D(x) 是高度退化的,即它有许多零(或者接近零)的特征值。这意味着损失函数在很多方向上都是局部不变的。这为这些网络描绘了一个有趣的优化解空间中的场景:随机梯度下降大部分时间都在穿越很宽的「峡谷」(wide valleys)。噪声沿着几个有大曲率的方向传播,这抵消了 g_N 朝着这个「峡谷」的底部(损失表面的最小值)推进的趋势。
当前关注点:批量大小、学习率、泛化性能下降
由于我们在将 n(x) 加到梯度之前,按照 1/√m 的因子将其进行缩放,因此增加了批处理的规模,降低了小批量估计的整体方差。这是一个值得解决的问题,因为大的批量尺寸可以使模型训练得更快。它在两个重要的方面使得训练更快:训练误差在更少的梯度更新中易于收敛,并且大的批量尺寸使得我们能利用大规模数据并行的优势。但是,不使用任何技巧就增大批量尺寸会导致测试误差增大。这个现象被称为泛化能力下降(generalization gap),并且目前还存在一些为什么会出现这种情况的假说。一个流行的解释是,我们的「探索性噪声」不再有足够的力量将我们推出一个尖锐最小值的吸引域。一种解决办法是简单地提高学习率,以增加这种噪声的贡献。这种缩放规则非常成功(https://arxiv.org/abs/1706.02677)。
长期关注点:逃离鞍点
虽然泛化能力下降「generalization gap」最近已经成为了一个热门话题,但之前仍有很多工作研究鞍点的影响。虽然不会渐进收敛到鞍点(http://noahgolmant.com/avoiding-saddle-points.html),我们仍然可能附近停留相当长的一段时间(https://arxiv.org/abs/1705.10412)。而且尽管大的批量尺寸似乎会更易于产生更尖锐的最小值,但真正大的批量尺寸会将我们引导到确定的轨迹上,这个轨迹被固定在鞍点附近。一项研究(https://arxiv.org/abs/1503.02101)表明,注入足够大的各项同性噪声可以帮助我们逃离鞍点。我敢打赌,如果噪声有足够的「放大」能力,小批量的随机梯度下降(mini-batch SGD)会在造成训练困难的维度上提供足够的噪声,并且帮助我们逃离它们。
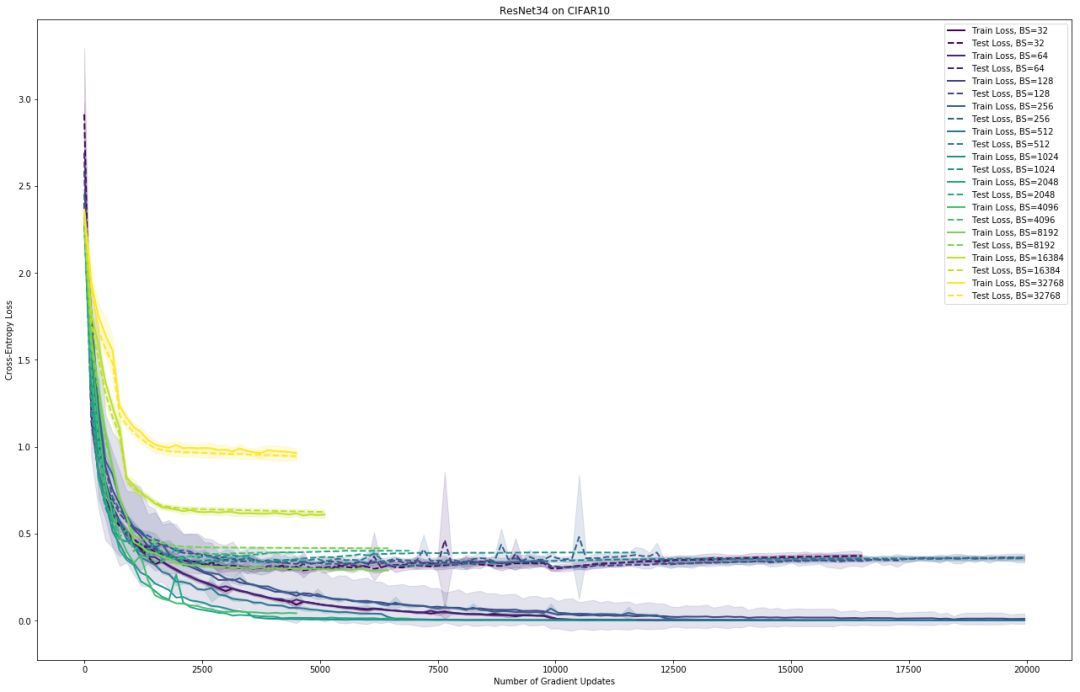
一旦我们解决了「尖锐的最小值」的问题,鞍点可能是下一个大规模优化的主要障碍。例如,我在 CIFAR-10 数据集上用普通的随机梯度下降算法训练了 ResNet34。当我将批量尺寸增大到 4096 时,泛化能力下降的现象出现了。在这一点之后(我最高测试了大小为 32K 的批量尺寸,有 50K 个训练样本),性能显著降低:训练误差和测试误差都仅仅在少数几个 epoch 中比较平稳,并且网络无法收敛到一个有效解上。以下是这些结果的初步学习曲线(即看起来比较丑、还有待改进):
进一步的工作
目前提出的大多数处理尖锐的最小值/鞍点的解决方案都是围绕(a)注入各向同性噪声,或(b)保持特定的「学习率和批量尺寸」。我认为从长远来看,这还不够。各向同性噪声在包含「wide valley」结构的解空间中做的并不好。增加学习率也增大了对梯度的更新,这使得权重更新得更大。我认为正确的方法应该是想出一种有效的方法来模拟小批量噪声的各向异性,这种方法从学习率和批处理大小的组合中「解耦」出来。存在能够使用子采样梯度信息和 Hessian 向量乘积去做到这一点的方法,我正在进行这个实验。我很希望听听其它的关于如何解决这个问题的想法。与此同时,我们还需要做大量的理论工作来更详细地理解这种动态,特别是在一个深度学习环境中。

原文链接:http://noahgolmant.com/sgd-noise.html
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com


