120万美元机器24分钟训练ImageNet,UC Berkeley展示全新并行处理方法
本文经机器之心(微信公众号:almosthuman2014)授权转载,禁止二次转载。
来源:机器之心编译自UC Berkeley
参与:李泽南、蒋思源
今年 6 月,Facebook 实现 1 小时训练 ImageNet 的成绩之后,通过增加批量大小以加快并行训练速度的方式引发了人们的关注。最近 UC Berkeley 的研究人员们为我们展示了 24 分钟训练 ImageNet 的成绩,他们将批量大小增加到了 32k。研究人员表示,在同样成绩下,新的方法使用的计算设备成本(120 万美元)大大低于 Facebook(410 万美元)。
对于深度学习应用而言,模型、数据集越大,结果就越精确,但同时也意味着训练时间的增长。例如,用 ResNet-50 模型在 ImageNet-1k 上完成 90 个 epoch 需要 14 天时间,这样的训练共需要 10^18 次单精度计算(single precision operations)。另一方面,世界目前最为强大的超级计算机可以在每秒钟进行 2×10^17 次单精度计算。如果我们可以完全利用超级计算机的能力,那么使用 ResNet-50 模型在 ImageNet-1k 上应该可以在五秒内完成 90 个 epoch 的训练。然而,目前我们面临的 DNN 训练瓶颈在算法层面上。具体来说,目前我们使用的批量过小(如 512),这让处理器并行处理的效率很低。所以,我们需要为可扩展的 DNN 训练设计有效的并行算法。
使用大批量SGD是大规模 DNN 训练的基础。但是,此前的方法只能将 AlexNet 和 ResNet-50 的批量大小扩大到 1024 和 8192 这样的程度。更大的批量大小会导致结果准确度的显著降低。在 UC Berkeley 最近发表的论文中,研究人员使用层级对应的适应率缩放(Layer-wise Adaptive Rate Scaling,LARS)算法,让批量大小可以扩大到更大的级别(如 32k)而不损失结果准确度。
大批量可以让我们更加有效地利用分布式系统的计算能力。UC Berkeley 的研究人员使用 AlexNet 模型在 ImageNet 上训练 100 个 epoch 只花费了 24 分钟,这是一个新的世界纪录。和 Facebook 此前的结果类似(参见:Facebook 新研究:大批量 SGD 准确训练 ImageNet 仅需 1 小时)新的方法也可以在一小时内使用 ResNet-50 模型在 ImageNet 上训练 90 个 epoch,但硬件花费约为 120 万美元——远少于 Facebook 今年 6 月时使用的 410 万美元。
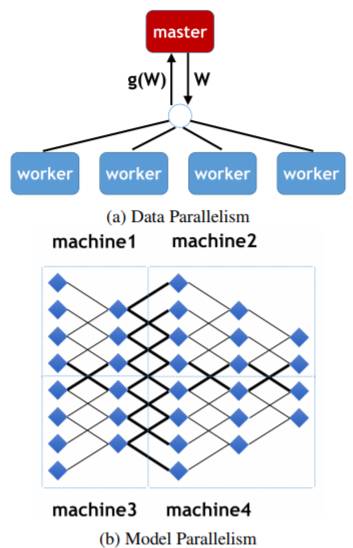
图 1.(a)是数据并行化的一个示例。每个工作器将自己的梯度∇w^j 发送给控制器,随后控制器更新自己的权重。随后,控制器将更新后的权重 w˜发送给所有工作器。(b)是模型平行化的示例。其中包含一个五层神经网络和本地连接,它被分割成四个部分。只有在跨区域边缘位置的节点需要在连接处(粗线)共享它们的状态。即使节点位置与多条边相连,它也只会对其他部分的节点总共发送一次自己的状态。。

表 1. 在 ImageNet 数据集上训练神经网络,tcomp 是计算时间,tcomm 是通信时间。研究人员将 epoch 数量设为 100。越大的批量大小需要越小的迭代次数。研究人员首先将批量大小设为 512,随后不断增加计算设备数量,由于训练 ResNet-50 的 Infiniband 网络和 GPU 效率足够高,单次迭代时间可能接近常数,总训练时间会不断减少。
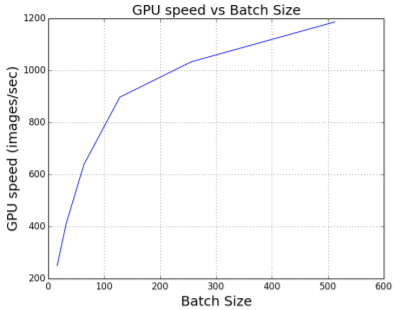
图 2. 在一定范围内,大批量提升了系统(GPU)的处理性能。本图中的数据是 AlexNet 在 ImageNet 数据集上的训练效果,使用的 GPU 是英伟达 M40,每个 GPU 的批量大小为 512——这是我们能得到的最高速度。Batch=1024 会导致内存溢出。
此前,英伟达曾经表示使用 DGX-1 工作站在 ImageNet 中训练 AlexNet 90 个 epoch 需要花费两个小时。然而,他们使用了半精度(half-precision)或 FP16,计算资源消耗是标准单精度计算的一半。在本研究中,UC Berkeley 的研究者们使用了标准单精度计算,在英伟达 DGX-1 工作站中,批量大小为 512 时花费了 6 小时 9 分钟。因为 LARS 算法的存在,我们可以在保证精度的情况下大幅增加批量大小。如果我们将批量大小增加至 4096,在英伟达 DGX-1 上我们就只需要 2 小时 10 分钟即可完成任务了(这也是单机最快的成绩)。所以,通过 LARS 增加批量大小的方法可以显著提高 DNN 的训练速度。在 AlexNet 上,当批量大小为 32k 时,研究人员将算法扩展到 512 个 KNL 芯片(约 32,000 个处理器核心)。每个 KNL 的批量大小为 64,所以总批量大小为 32678。最终,UC Berkeley 实现了 24 分钟训练 100 个 epoch 的成绩,这也是目前业内最佳的成绩。

表 7. 训练 AlexNet 的速度和硬件花费,批量大小为 32k,研究人员已将 AlexNet 中的局部响应范数(local response norm)改为批范数。
在今年 6 月份,Facebook 在 ImageNet 上训练 ResNet-50 时(90 epoch)花费一小时,使用了 32 个 CPU 和 256 个英伟达 P100 GPU(32 个 DGX-1 工作站),目前单个 DGX-1 的价格为 129,000 美元,整个硬件系统的成本为 410 万美元。
在将批量大小扩展到 32k 之后,UC Berkeley 的研究人员们将计算任务交给了相对便宜的计算机芯片——KNL 上,同样在一个小时的时间里跑完了 90 个 epoch。他们使用的 KNL 搭载英特尔 Xeon Phi 7250 处理器,单个售价 2436 美元,整个系统花费 120 万美元。

表 8. 训练 ResNet-50 的速度和硬件成本,研究中未使用数据增强。
论文:ImageNet Training in 24 Minutes

论文链接:https://www2.eecs.berkeley.edu/Pubs/TechRpts/2017/EECS-2017-155.html
摘要:想要在 ImageNet-1k 上完成 90 个 epoch 的 ResNet-50 模型训练,使用英伟达 M40GPU 需要花上 14 天。这种训练共需要 10^18 次单精度计算(single precision operations)。另一方面,世界目前最快的超级计算机可以每秒钟进行 2×10^17 次单精度计算。如果我们可以充分利用超级计算机的性能用于深度神经网络讯联,我们应该可以使用 ResNet-50 模型在 5 秒钟内完成 90 个 epoch 训练。然而,目前的 DNN 训练瓶颈在算法层面上。具体来说,目前我们使用的批量大小(如 512)过于小,无法有效利用多处理器。
对对于大规模 DNN 训练,我们专注于使用大批量数据并行化同步(large-batch data-parallelism synchronous)SGD 在固定 epoch 中保证不损失精度。You、Gitman 与 Ginsburg 在 2017 年提出的 LARS 算法允许我们将批量大小扩大到 32k 的水平。在此之上,我们只花费了 24 分钟即完成了在 ImageNet 上,100 个 epoch 的 AlexNet 训练——这是一个世界纪录。与 Facebook 的结果相同,我们在 ImageNet 上训练 ResNet-50 花费了一个小时,而使用的硬件成本仅为 120 万美元,比 Facebook 使用的 410 万美元降低了很多。
继1小时训练ImageNet之后,大批量训练扩展到了3万2千个样本
学界 | Facebook 新研究:大批量SGD准确训练ImageNet仅需1小时
本文为机器之心编译,转载请联系出处。
✄--------------------------------

限时干货下载
Step 1:长按下方二维码,添加微信公众号“数据玩家「fbigdata」”
Step 2:回复【2】免费获取完整数据分析资料「包括SPSS\SAS\SQL\EXCEL\Project!」


