清华大学刘知远:知识表示学习及其应用(附视频、PPT下载)

本讲座选自清华大学计算机系副教授刘知远于2018年4月27日在第二届“大数据在清华”高峰论坛上所做的题为《知识表示学习及其应用》的演讲。
注:后台回复关键词“0520”,下载完整版PPT。

演讲视频:
视频时长约半个小时,建议使用wifi观看

刘知远:今天跟大家分享的题目叫"知识表示学习及其应用"。

大概在二三十年前,我们早就面临所谓的数据过载的问题,当时就有一个专门的领域叫信息检索,研究如何在大数据里面快速地获取相关的信息。
搜索引擎是一个非常重要的应用,我们每天都要无数次地使用,比如谷歌、百度,它们已经有快20年的历史了。
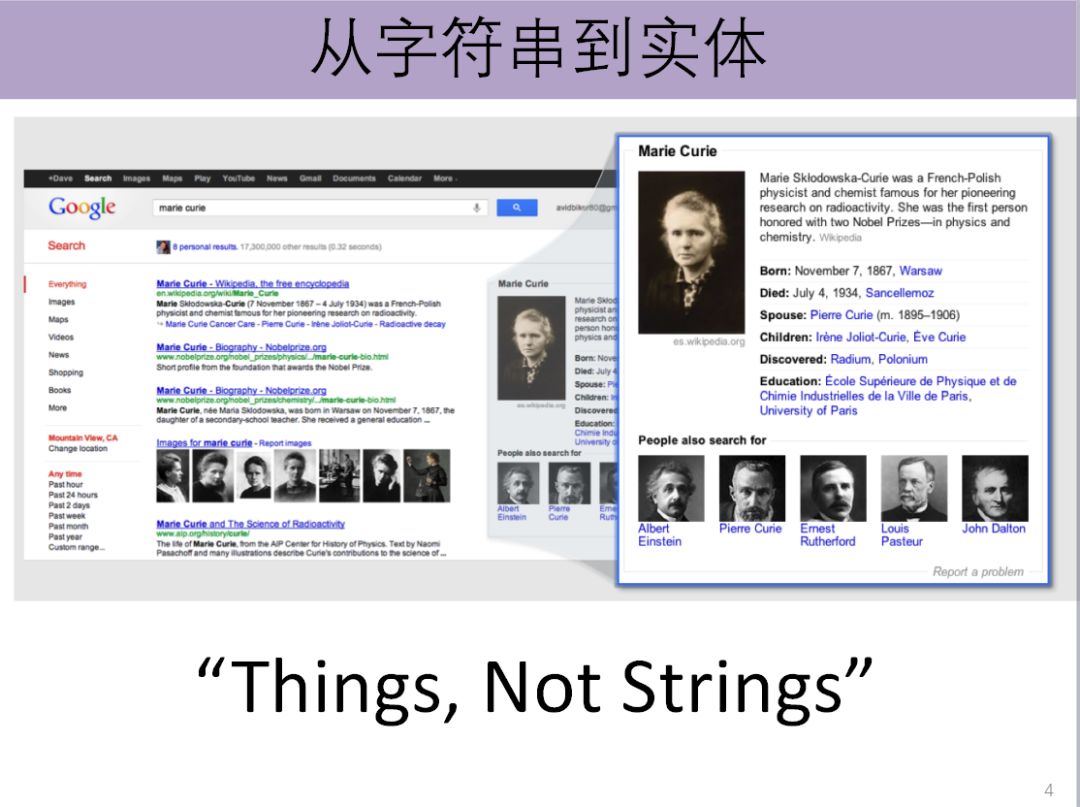
我们过去的搜索更多地是使用关键词匹配的形式。首先,用户写入若干关键词,然后搜索引擎进行关键词的匹配。2012年,谷歌提出新的口号,叫“Things,Not Strings”。它的意思是说搜索引擎不希望只是把用户输入的关键词或者它要处理的海量互联网数据,看成一个一个的字符串,而是希望能够真正地去认识,或者说真正地挖掘这些字符串背后所反映的现实世界的真实事情。

在这个理念的驱动下,诞生了谷歌的知识图谱产品。无论用户使用百度、搜狗还是谷歌,无论搜索名人、一个机构还是地名,都会出现关于机构或者人的一些结构化信息。
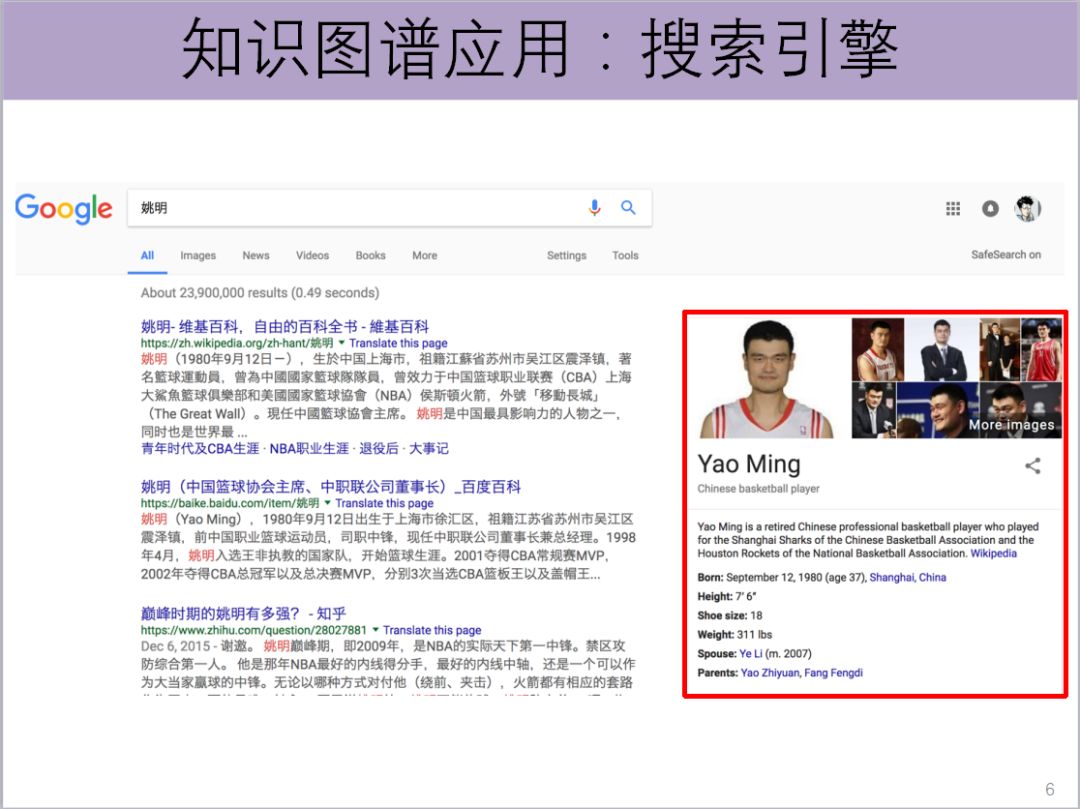
比如,我们搜索姚明,姚明的相关信息就会列出来,这些信息就是所谓的知识图谱。它尝试着把现实世界所有的信息都能够通过结构化的形式来存储。这种知识图谱,不只是为了支持我们的搜索引擎,能够把信息更精准地推送给我们,也是人工智能一些应用的基础设施。我们单从搜索引擎来看,在知识图谱的支持下,已经有了非常多新的应用。
在搜索引擎里,越来越多的时候不需要输入一些关键词,也不需要到网页里找答案,而是直接去问这个问题,搜索引擎就可以把答案告诉我们。
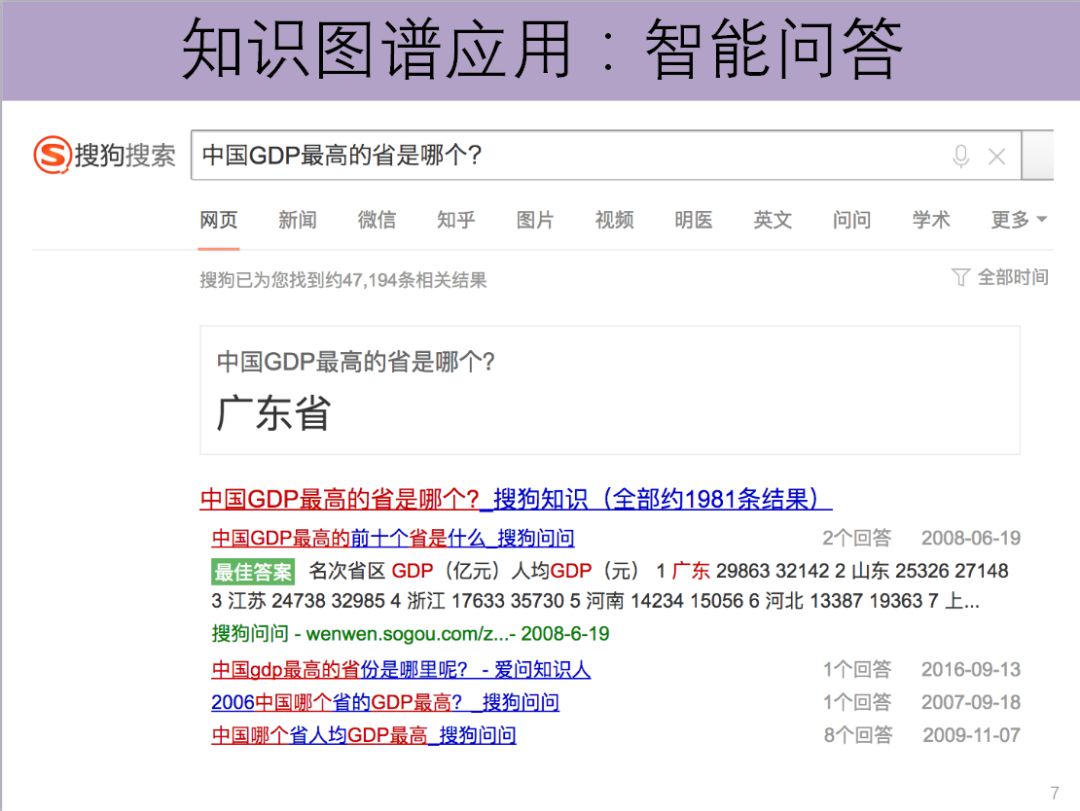
比如我们问"中国GDP最高的省份是哪个?",它就可以直接把相关的答案告诉你。如果可以的话,还可以点击进去了解相关的信息。

比如我们问“清华大学成立于哪一年?”,它会把相关的信息告诉你,这些信息都是存储在背后的知识图谱里,需要应用自然语言处理技术还有知识图谱的技术,来了解你的问题,然后到知识图谱里找到答案。
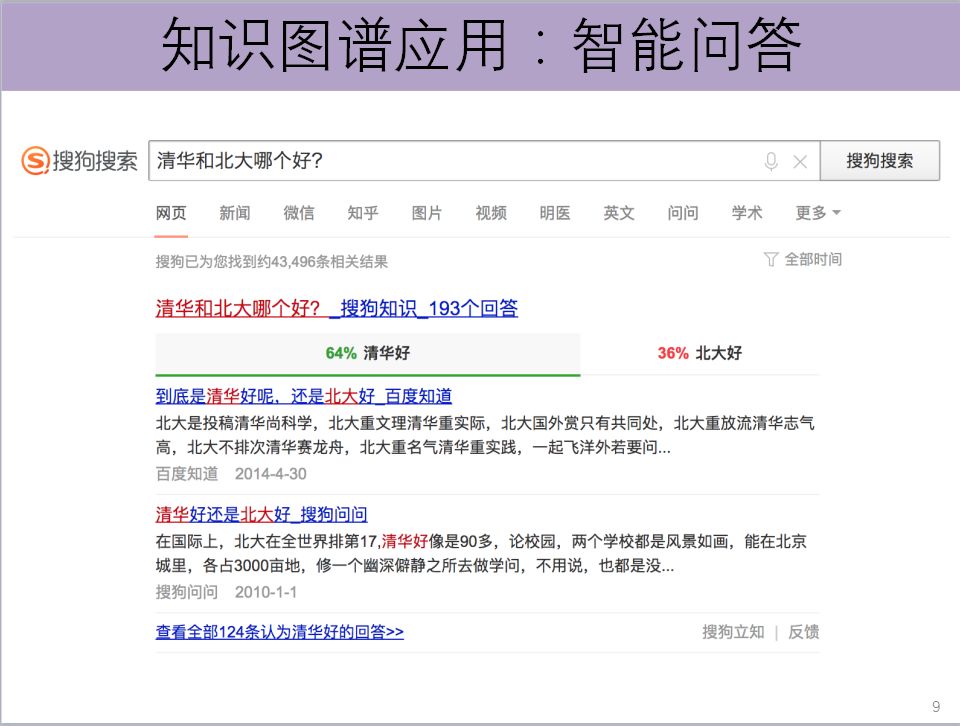
甚至还可以尝试着回答一些更复杂的问题,比如说“清华和北大哪个好?”。搜狗告诉我们:有64%的人认为是清华好。
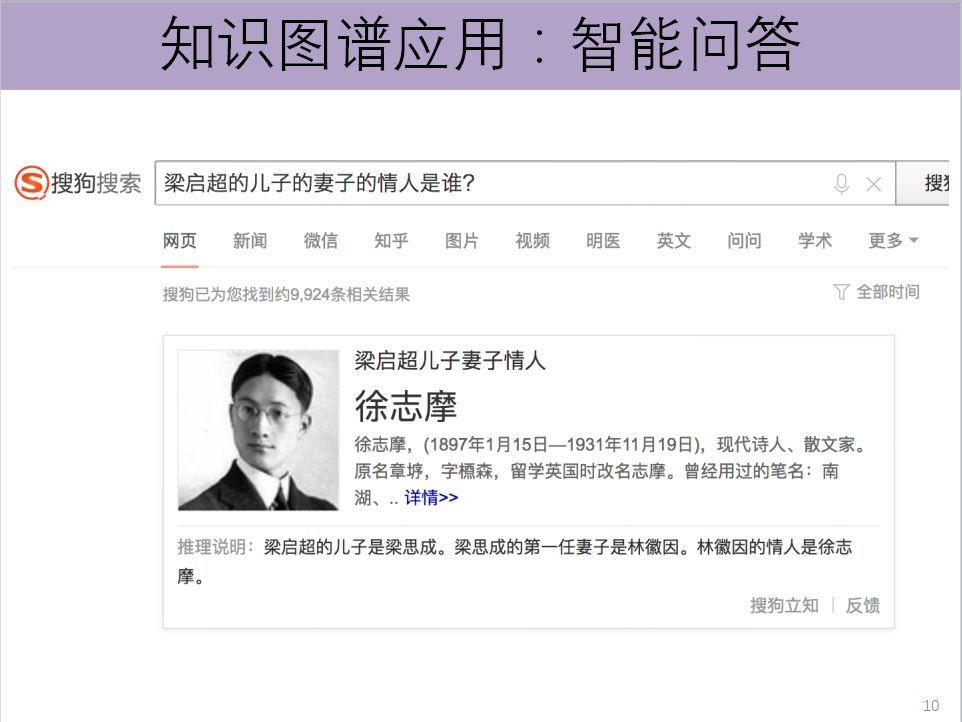
在知识图谱的支持下,我们还可以进行相关的智能推理。比如说“梁启超儿子的妻子的情人是谁?",它的答案并不直接存在知识图谱里,而是需要在知识图谱结构里,跳若干次才能找到答案。这本身需要相关的一些智能推理来完成。实际上无论是谷歌,还是中国的百度,这些相对的搜索引擎都在尝试构建大量的知识图谱,给用户提供更好的服务。对于大数据时代来说,这件事情非常重要。
甚至还可以尝试着回答一些更复杂的问题,比如说“清华和北大哪个好?”。搜狗告诉我们:有64%的人认为是清华好。
在知识图谱的支持下,我们还可以进行相关的智能推理。比如说“梁启超儿子的妻子的情人是谁?",它的答案并不直接存在知识图谱里,而是需要在知识图谱结构里,跳若干次才能找到答案。这本身需要相关的一些智能推理来完成。实际上无论是谷歌,还是中国的百度,这些相对的搜索引擎都在尝试构建大量的知识图谱,给用户提供更好的服务。对于大数据时代来说,这件事情非常重要。

到目前为止,这些商业的知识图谱应用都秉承一种比较传统的表示,我们称为"符号表示"。在计算机里,要想把知识图谱表示进来,就要把每一个实体都表示成一个独一无二的符号,把它表示成一个非常长的向量,只有一个位置是1,其他的全是0,这样就可以把不同的对象区分开。
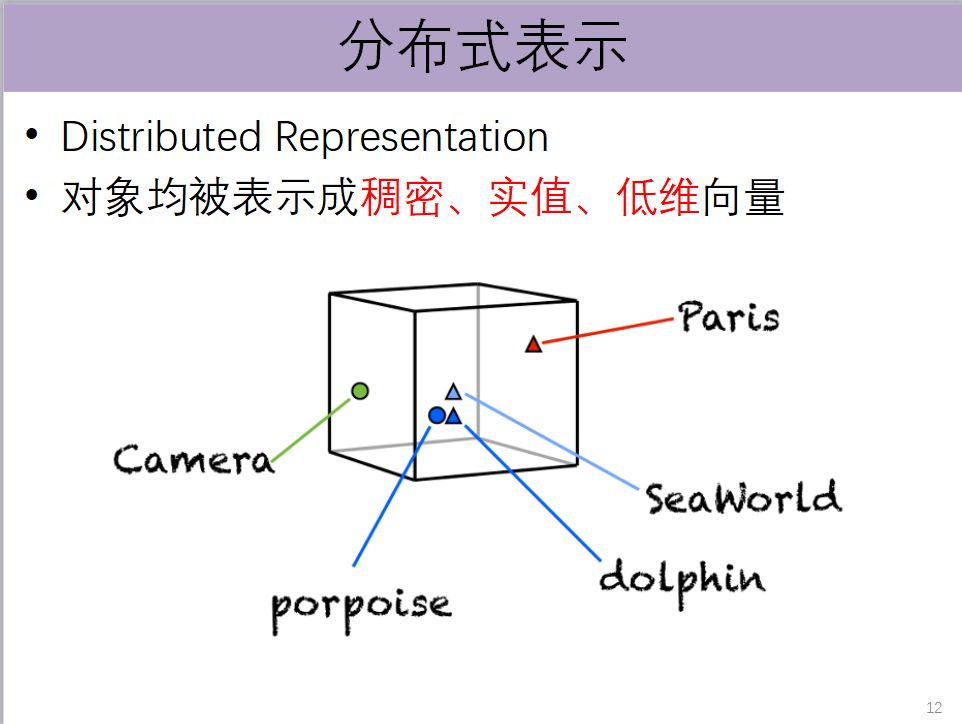
这次深度学习的浪潮,席卷了人工智能非常多的领域,包括自然语言处理领域。分布式表示的对象均被表示成一个低维的稠密、实值向量。通过这种方式,我们就可以利用对象在空间的相对距离,反映它们之间的语义关系。两个对象离得越近,说明关系越紧密,两个对象离得越远,说明它们之间没有太强的关系。
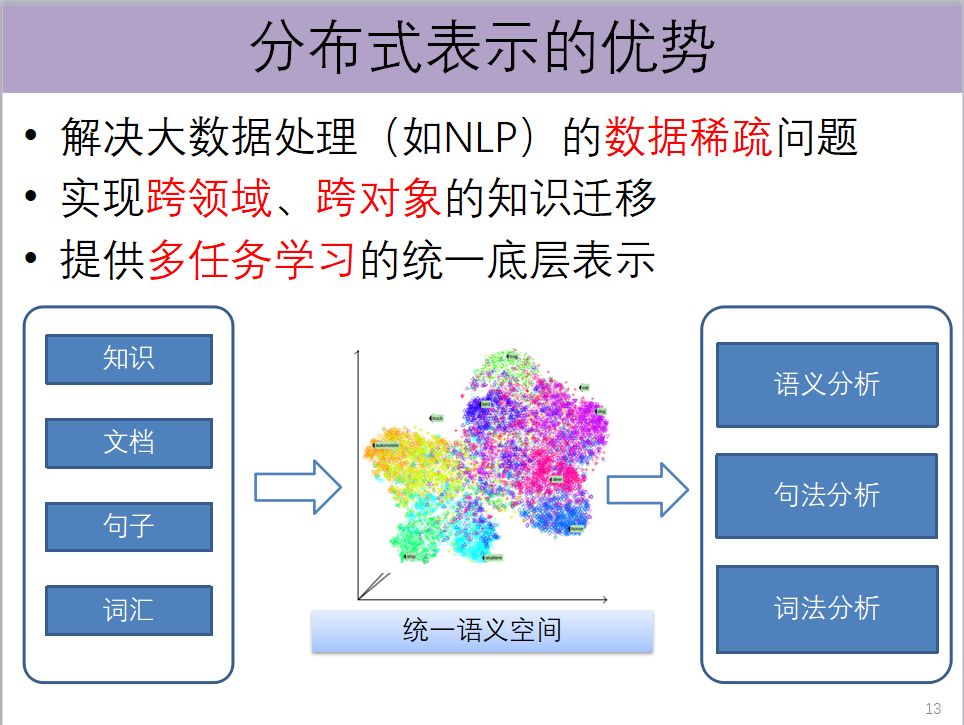
自然语言处理是一种典型的长尾分布的大数据,最大的特点是会在长尾的部分有非常显著的数据稀疏问题。如果把这些对象都表述在低维向量空间里面,可以在这个空间里面利用少量的但是特别高频的对象,学习得到这个空间里面不同位置上的语义。当把那些长尾上稀疏的数据也映射到这个空间的时候,就可以借助那些高频的数据,一定程度上可以帮助我们解决大数据里面典型的长尾分布带来的数据稀疏问题。
另外一个非常重要的挑战是,自然语言存在多种粒度语言单位。在进行自然语言处理的时候,往往需要专门设计算法进行不同粒度单位的语义计算,比如算一个词跟一个句子的相似度,算一个句子跟一个文档的相似度。如果能够把这些对象都放在低维的向量空间里面,我们就可以有一个统一的计算方案,可以算它们之间的相似度。
比如对于同一个研究对象,一个句子或者一个文档,都会有非常多不同的任务,要做词化分析、句法分析或者语义分析,底层的表示如果一致,也能够更好地帮我们提供多任务学习的支持,这是我们认为的分布式表示的一个优势。
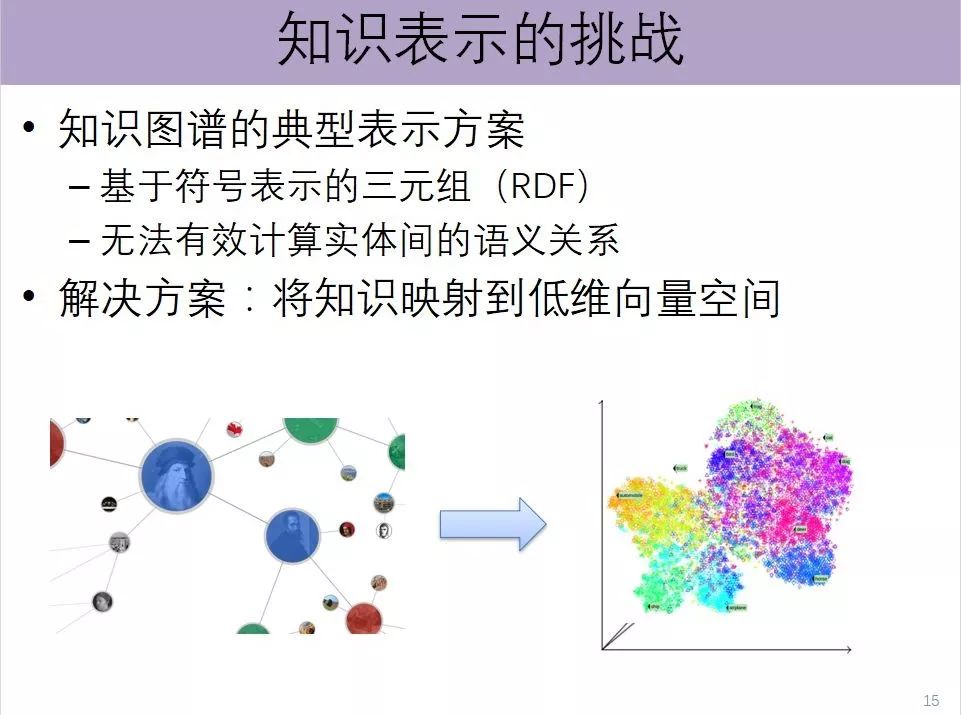
大规模知识图谱传统表示也是基于符号的方式,都是用独一无二的符号来进行表示。把知识图谱映射到低维的向量空间里面去,就是所谓的知识表示学习。
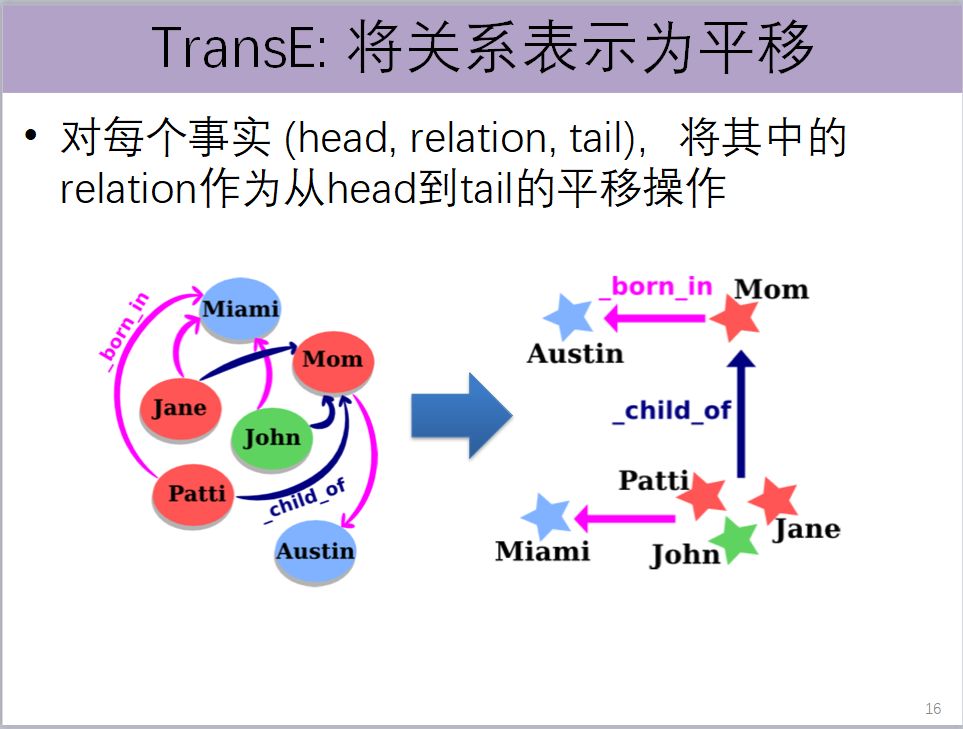
知识图谱里面有很多的事实,我们可以把每一个事实,它的向量看成是从头实体到尾实体向量平移的操作。
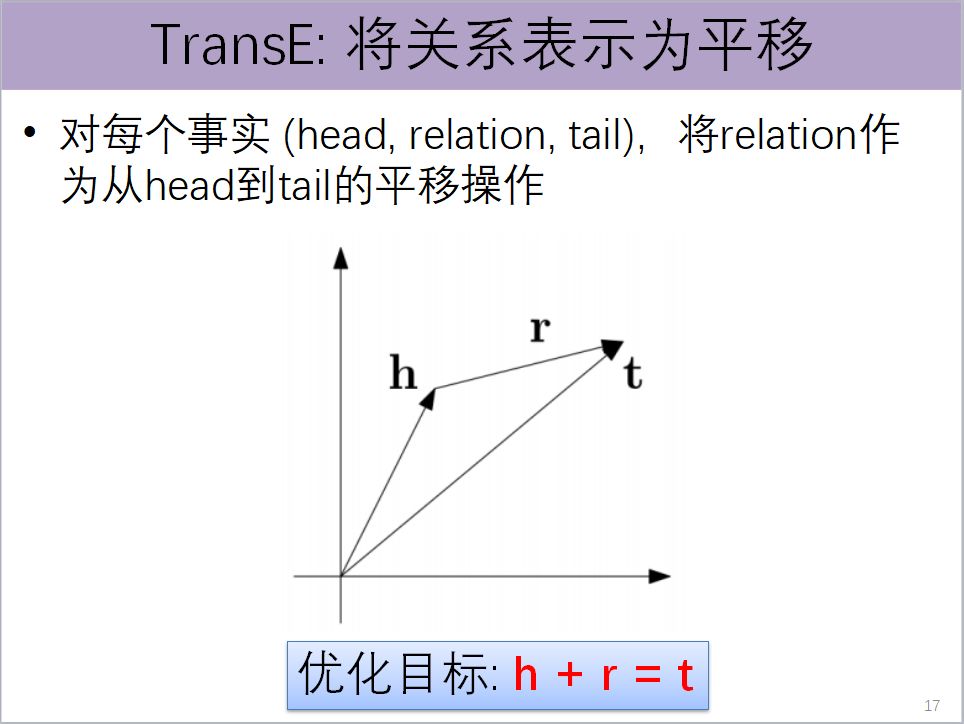
如上图,头实体用h表示,尾实体用t表示。假如说存在r的关系,这个r就是从头实体到尾实体的平移。简言之,我们的优化目标,就是要让h+r=t。这样有了成千上百万的三元组一起做优化,我们就可以得到所有实体和它们关系之间低维的向量表示。有了低维向量表示,就可以做非常多的相关的语义的计算。

从大规模知识图谱到低维向量空间过程中一定是有信息损失的,但是能够快速定位那些最有可能的实体集合,然后利用一些更复杂的算法找它的真正的答案。这是低维向量表示的应用意义。
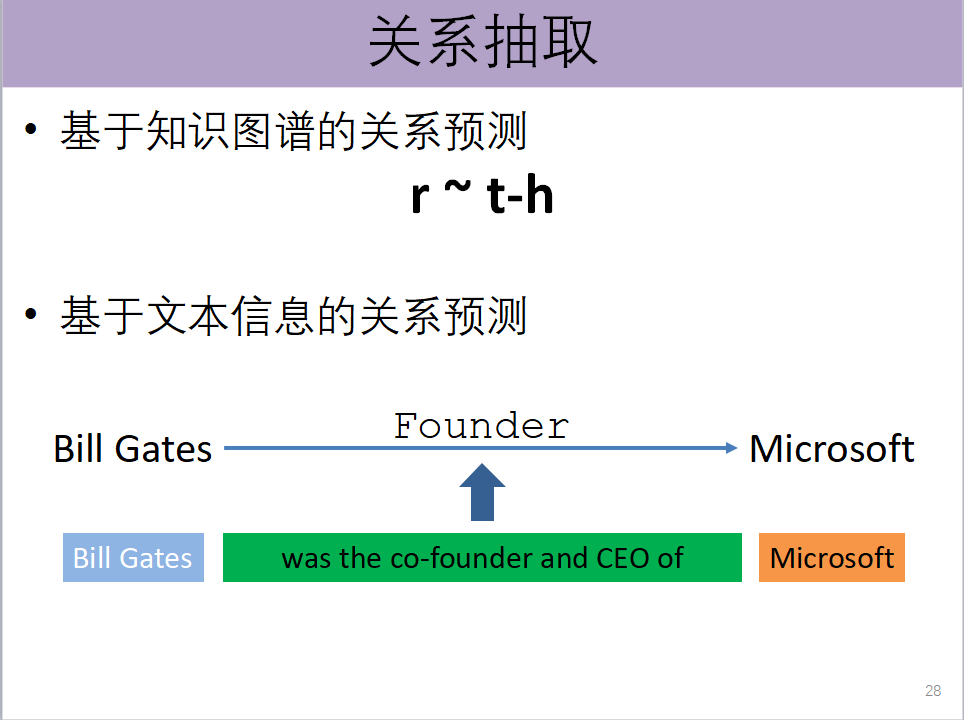
我们尝试利用知识图谱进行关系预测,得到了所有实体和关系之间的表示,用t-h就可以判断。
知识获取的另一个非常重要的来源是文本信息,可以通过一句话判断两个实体之间可能存在的关系。
如果把知识图谱映射到低维向量空间里面,能够非常好地把文本语义空间结合起来,相当于信息量能够充分地扩展出来,显著地提升知识获取的准确度。
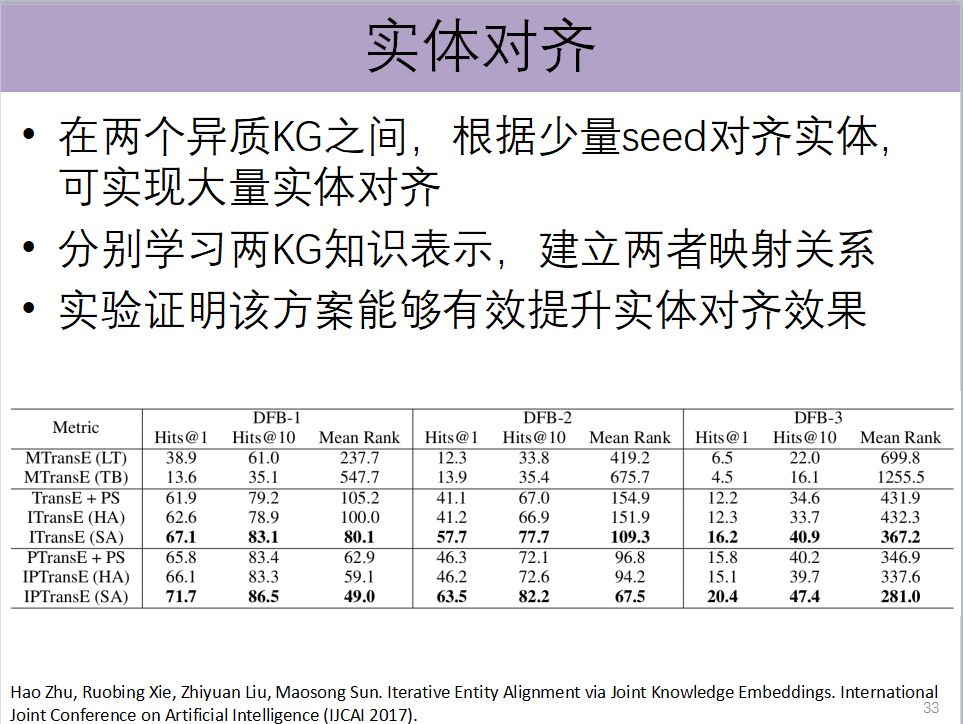
另外一个尝试叫做实体对齐。我们面临一个问题,不同的机构和国家,他们可能会构建各种各样不同的知识图谱,这些知识图谱既有不同,也会存在一定共性。我们怎么能够把这些不同来源的知识图谱给融合成一个更大的知识图谱,这里面就面临一个实体对齐的问题。知识图谱里面的实体和另一个知识图谱的实体是同一个实体,我们叫做实体对齐。
两个知识图谱可以分别学习两个空间,然后用已知的两个知识图谱里面对齐的实体,就可以把这两个空间真正关联起来。我可以知道这个空间里面的一个位置,跟这个空间里面的另一个位置,它们之间有关联,相当于分别学习两个Knowledge Graph的表示空间,然后用非常有限的种子的实体,把这两个空间给融合在一起。
大量的实验证明,我们的方法能够显著地提高两个知识图谱进行对齐的效果,同时说明知识图谱有非常显著的长尾效应,把它映射到低维向量空间里,能够更好地利用知识图谱全局信息建立语义空间。
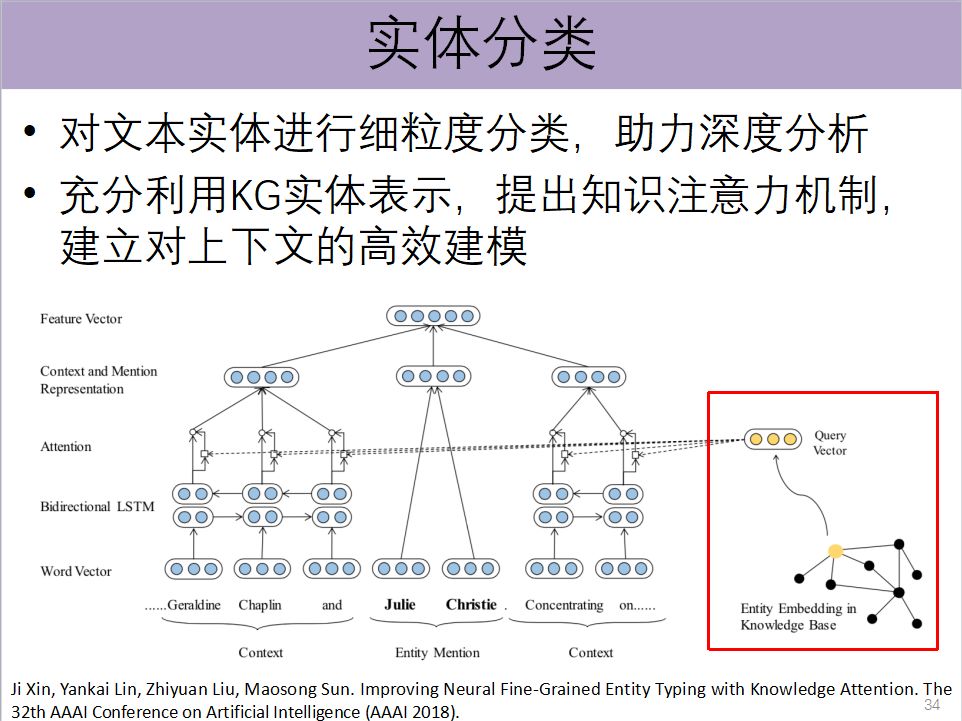
第三个任务叫实体分类,这对于理解一句话,或者从这句话中抽取实体之间的关系都非常重要。最大的问题在于知识图谱如果用符号表示,它很难能够跟深度学习结合在一起。现在由于可以进行分布式表示,那么很自然地可以把这两个模型融合在一起。
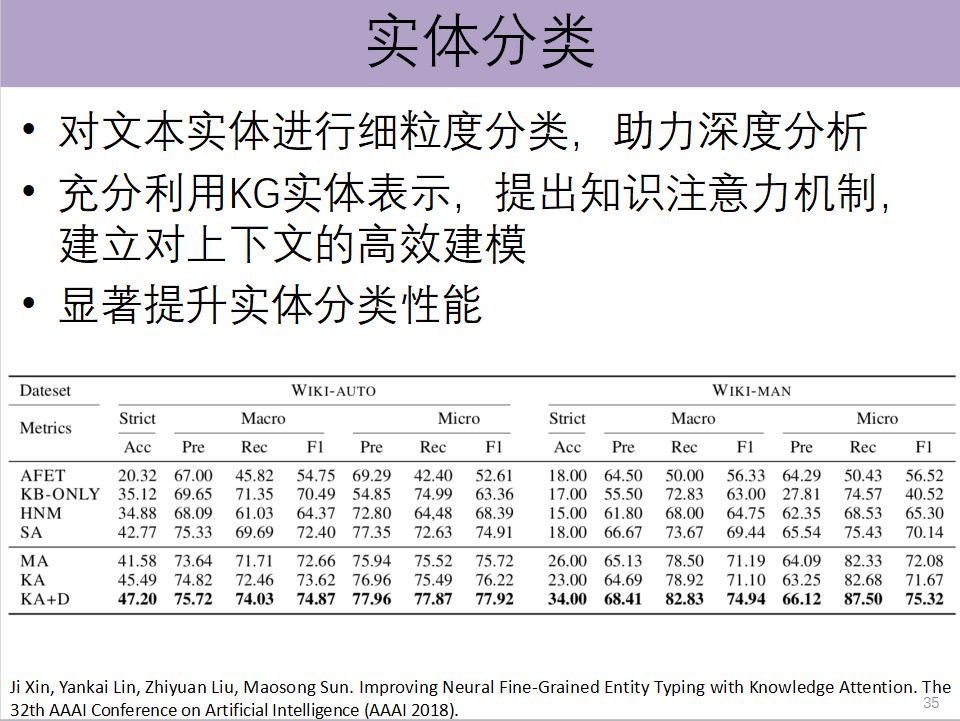
在过去,知识图谱虽然很大很重要,但是很难用,因为它是一个典型的结构化的信息,跟文本的信息很难融合。但是现在有了低维向量表示,就真正地可以把知识图谱的知识,和文本信息放在一个空间里面进行相关的操作。在这个方面,我们认为未来对于知识图谱的大规模表示的语义空间,会在非常多的方向上有应用。但是,我们发现在一些通用的知识图谱上,学一个大规模知识图谱表示学习的模型还是比较难。所以我们做了一个平台,把目前来看比较有效的一些知识表示的模型全都实现,都用统一的接口。

我们面向两个通用的大规模知识图谱WikiDATA和Freebase,基于表示学习的技术将知识图谱映射到一个低维的语义空间里面,有望深入地应用到多个领域,如信息检索、推荐系统。这两个领域都在积极考虑使用大规模知识图谱信息,我们也正尝试把知识用低维空间提升检索效果,效果非常明显。

在金融、医疗、法律等垂直领域,构建知识图谱的过程非常复杂且耗时耗力,我们认为表示学习能够在知识获取方面发挥一些作用。目前,大规模知识图谱对日常知识的覆盖度以及更新的速度都非常有限。未来我们希望能够做一些深入的工作,花足够多的力气在知识图谱技术上。以上就是今天希望跟大家分享的主要内容,谢谢大家!

整理:杜佳豪





