AI部署:聊一聊深度学习中的模型权重

极市导读
本文简要介绍了模型权重的统计方法,以及在caffe,pytorch,TensorRT之间如何进行权重的转移,附有相关代码。 >>算法offer直通车、50万总奖池!高通人工智能创新应用大赛等你来战!
今天简单聊聊模型权重,也就是我们俗称的weight。
深度学习中,我们一直在训练模型,通过反向传播求导更新模型的权重,最终得到一个泛化能力比较强的模型。同样,如果我们不训练,仅仅随机初始化权重,同样能够得到一个同样大小的模型。虽然两者大小一样,不过两者其中的权重信息分布相差会很大,一个脑子装满了知识、一个脑子都是水,差不多就这个意思。
所谓的AI模型部署阶段,说白了就是将训练好的权重挪到另一个地方去跑。一般来说,权重信息以及权重分布基本不会变(可能会改变精度、也可能会合并一些权重)。
不过执行模型操作(卷积、全连接、反卷积)的算子会变化,可能从Pytorch->TensorRT或者TensorFlow->TFLITE,也就是实现算子的方式变了,同一个卷积操作,在Pytorch框架中是一种实现,在TensorRT又是另一种时间,两者的基本原理是一样的,但是精度和速度不一样,TensorRT可以借助Pytorch训练好的卷积的权重,实现与Pytorch中一样的操作,不过可能更快些。
权重/Weight/CheckPoint
那么权重都有哪些呢?他们长什么样?
这还真不好描述...其实就是一堆数据。对的,我们千辛万苦不断调优训练出来的权重,就是一堆数据而已。也就是这个神奇的数据,搭配各种神经网络的算子,就可以实现各种检测、分类、识别的任务。
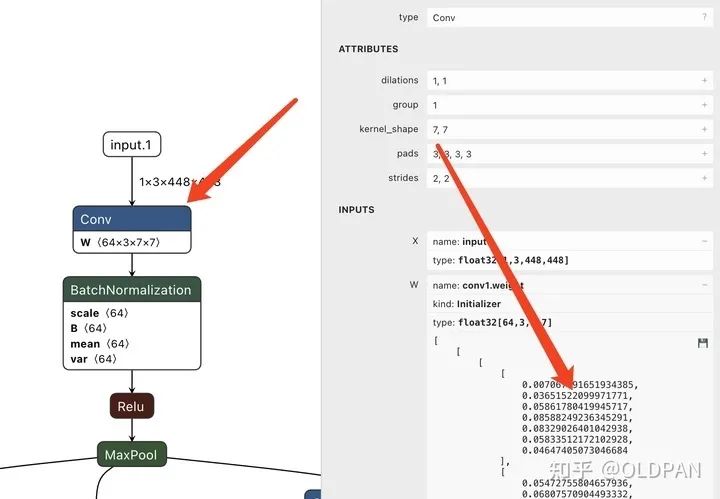
例如上图,我们用Netron这个工具去查看某个ONNX模型的第一个卷积权重。很显然这个卷积只有一个W权重,没有偏置b。而这个卷积的权重值的维度是[64,3,7,7],也就是输入通道3、输出通道64、卷积核大小7x7。
再仔细看,其实这个权重的数值范围相差还是很大,最大的也就0.1的级别。但是最小的呢,肉眼看了下(其实应该统计一波),最小的竟然有1e-10级别。

一般我们训练的时候,输入权重都是0-1,当然也有0-255的情况,但不论是0-1还是0-255,只要不溢出精度上限和下限,就没啥问题。对于FP32来说,1e-10是小case,但是对于FP16来说就不一定了。
我们知道FP16的普遍精度是~5.96e−8 (6.10e−5) … 65504,具体的精度细节先不说,但是可以很明显的看到,上述的1e-10的精度,已经溢出了FP16的精度下限。如果一个模型中的权重分布大部分都处在溢出边缘的话,那么模型转换完FP16精度的模型指标可能会大大下降。
除了FP16,当然还有很多其他精度(TF32、BF16、IN8),这里暂且不谈,不过有篇讨论各种精度的文章可以先了解下:https://moocaholic.medium.com/fp64-fp32-fp16-bfloat16-tf32-and-other-members-of-the-zoo-a1ca7897d407
话说回来,我们该如何统计该层的权重信息呢?利用Pytorch中原生的代码就可以实现:
# 假设v是某一层conv的权重,我们可以简单通过以下命令查看到该权重的分布
v.max()
tensor(0.8559)
v.min()
tensor(-0.9568)
v.abs()
tensor([[0.0314, 0.0045, 0.0182, ..., 0.0309, 0.0204, 0.0345],
[0.0295, 0.0486, 0.0746, ..., 0.0363, 0.0262, 0.0108],
[0.0328, 0.0582, 0.0149, ..., 0.0932, 0.0444, 0.0221],
...,
[0.0337, 0.0518, 0.0280, ..., 0.0174, 0.0078, 0.0010],
[0.0022, 0.0297, 0.0167, ..., 0.0472, 0.0006, 0.0128],
[0.0631, 0.0144, 0.0232, ..., 0.0072, 0.0704, 0.0479]])
v.abs().min() # 可以看到权重绝对值的最小值是1e-10级别
tensor(2.0123e-10)
v.abs().max()
tensor(0.9568)
torch.histc(v.abs()) # 这里统计权重的分布,分为100份,最小最大分别是[-0.9558,0.8559]
tensor([3.3473e+06, 3.2437e+06, 3.0395e+06, 2.7606e+06, 2.4251e+06, 2.0610e+06,
1.6921e+06, 1.3480e+06, 1.0352e+06, 7.7072e+05, 5.5376e+05, 3.8780e+05,
2.6351e+05, 1.7617e+05, 1.1414e+05, 7.3327e+04, 4.7053e+04, 3.0016e+04,
1.9576e+04, 1.3106e+04, 9.1220e+03, 6.4780e+03, 4.6940e+03, 3.5140e+03,
2.8330e+03, 2.2040e+03, 1.7220e+03, 1.4020e+03, 1.1130e+03, 1.0200e+03,
8.2400e+02, 7.0600e+02, 5.7900e+02, 4.6400e+02, 4.1600e+02, 3.3400e+02,
3.0700e+02, 2.4100e+02, 2.3200e+02, 1.9000e+02, 1.5600e+02, 1.1900e+02,
1.0800e+02, 9.9000e+01, 6.9000e+01, 5.2000e+01, 4.9000e+01, 2.2000e+01,
1.8000e+01, 2.8000e+01, 1.2000e+01, 1.3000e+01, 8.0000e+00, 3.0000e+00,
4.0000e+00, 3.0000e+00, 1.0000e+00, 1.0000e+00, 0.0000e+00, 1.0000e+00,
1.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00,
1.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00, 2.0000e+00,
0.0000e+00, 2.0000e+00, 1.0000e+00, 0.0000e+00, 1.0000e+00, 0.0000e+00,
2.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00,
0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00, 1.0000e+00,
0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00,
0.0000e+00, 0.0000e+00, 0.0000e+00, 1.0000e+00])
这样看如果觉着不是很直观,那么也可以自己画图或者通过Tensorboard来时候看。
那么看权重分布有什么用呢?
肯定是有用处的,训练和部署的时候权重分布可以作为模型是否正常,精度是否保持的一个重要信息。不过这里先不展开说了。
有权重,所以重点关照
在模型训练过程中,有很多需要通过反向传播更新的权重,常见的有:
-
卷积层 -
全连接层 -
批处理化层(BN层、或者各种其他LN、IN、GN) -
transformer-encoder层 -
DCN层
这些层一般都是神经网络的核心部分,当然都是有参数的,一定会参与模型的反向传播更新,是我们在训练模型时候需要注意的重要参数。
# Pytorch中conv层的部分代码,可以看到参数的维度等信息
self._reversed_padding_repeated_twice = _reverse_repeat_tuple(self.padding, 2)
if transposed:
self.weight = Parameter(torch.Tensor(
in_channels, out_channels // groups, *kernel_size))
else:
self.weight = Parameter(torch.Tensor(
out_channels, in_channels // groups, *kernel_size))
if bias:
self.bias = Parameter(torch.Tensor(out_channels))
也有不参与反向传播,但也会随着训练一起更新的参数。比较常见的就是BN层中的running_mean和running_std:
# 截取了Pytorch中BN层的部分代码
def __init__(
self,
num_features: int,
eps: float = 1e-5,
momentum: float = 0.1,
affine: bool = True,
track_running_stats: bool = True
) -> None:
super(_NormBase, self).__init__()
self.num_features = num_features
self.eps = eps
self.momentum = momentum
self.affine = affine
self.track_running_stats = track_running_stats
if self.affine:
self.weight = Parameter(torch.Tensor(num_features))
self.bias = Parameter(torch.Tensor(num_features))
else:
self.register_parameter('weight', None)
self.register_parameter('bias', None)
if self.track_running_stats:
# 可以看到在使用track_running_stats时,BN层会更新这三个参数
self.register_buffer('running_mean', torch.zeros(num_features))
self.register_buffer('running_var', torch.ones(num_features))
self.register_buffer('num_batches_tracked', torch.tensor(0, dtype=torch.long))
else:
self.register_parameter('running_mean', None)
self.register_parameter('running_var', None)
self.register_parameter('num_batches_tracked', None)
self.reset_parameters()
可以看到上述代码的注册区别,对于BN层中的权重和偏置使用的是register_parameter,而对于running_mean和running_var则使用register_buffer,那么这两者有什么区别呢,那就是注册为buffer的参数往往不会参与反向传播的计算,但仍然会在模型训练的时候更新,所以也需要认真对待。
关于BN层,转换模型和训练模型的时候会有暗坑,需要注意一下。
刚才描述的这些层都是有参数的,那么还有一些没有参数的层有哪些呢?当然有,我们的网络中其实有很多op,仅仅是做一些维度变换、索引取值或者上/下采样的操作,例如:
-
Reshape -
Squeeze -
Unsqueeze -
Split -
Transpose -
Gather
等等等等,这些操作没有参数仅仅是对上一层传递过来的张量进行维度变换,用于实现一些”炫技“的操作。至于这些炫技吗,有些很有用有些就有些无聊了。
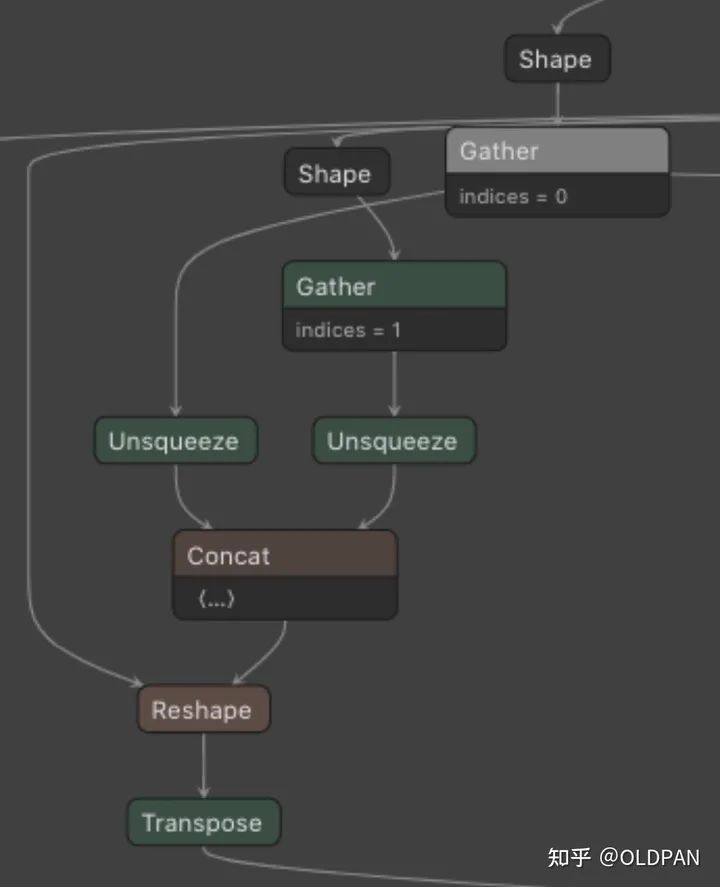
开个玩笑,其实有时候在通过Pytorch转换为ONNX的时候,偶尔会发生一些转换诡异的情况。比如一个简单的reshape会四分五裂为gather+slip+concat,这种操作相当于复杂化了,不过一般来说这种情况可以使用ONNX-SIMPLIFY去优化掉,当然遇到较为复杂的就需要自行优化了。
哦对了,对于这些变形类的操作算子,其实有些是有参数的,例如下图的reshap:
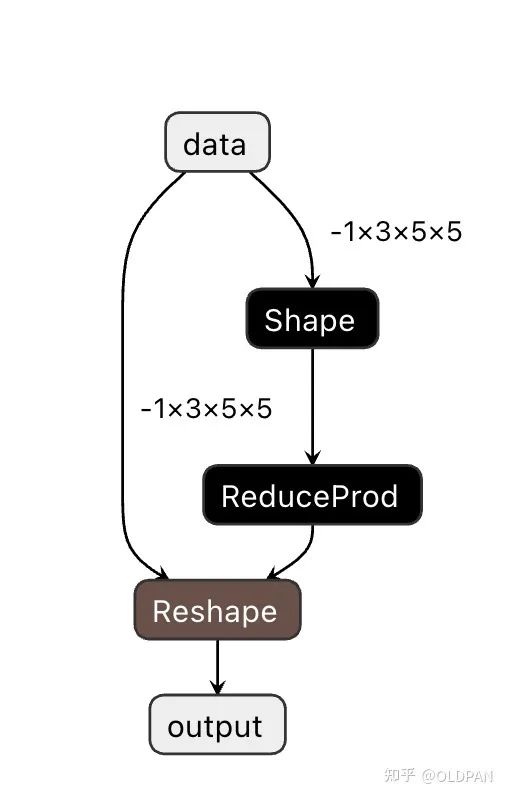
attribute
来处理,而ONNX的推理框架Inference则是支持的。
不过这些都是小问题,大部分情况我们可以通过改模型或者换结构解决,而且成本也不高。但是还会有一些其他复杂的问题,可能就需要我们重点研究下了。
提取权重
想要将训练好的模型从这个平台部署至另一个平台,那么首要的就是转移权重。不过实际中大部分的转换器都帮我们做好了(比如onnx-TensorRT),不用我们自己操心!
onnx-TensorRT:https://github.com/onnx/onnx-tensorrt
不过如果想要对模型权重的有个整体认知的话,还是建议自己亲手试一试。
Caffe2Pytorch
先简单说下Caffe和Pytorch之间的权重转换。这里推荐一个开源仓库Caffe-python(https://github.com/marvis/pytorch-caffe),已经帮我们写好了提取Caffemodel权重和根据prototxt构建对应Pytorch模型结构的过程,不需要我们重复造轮子。
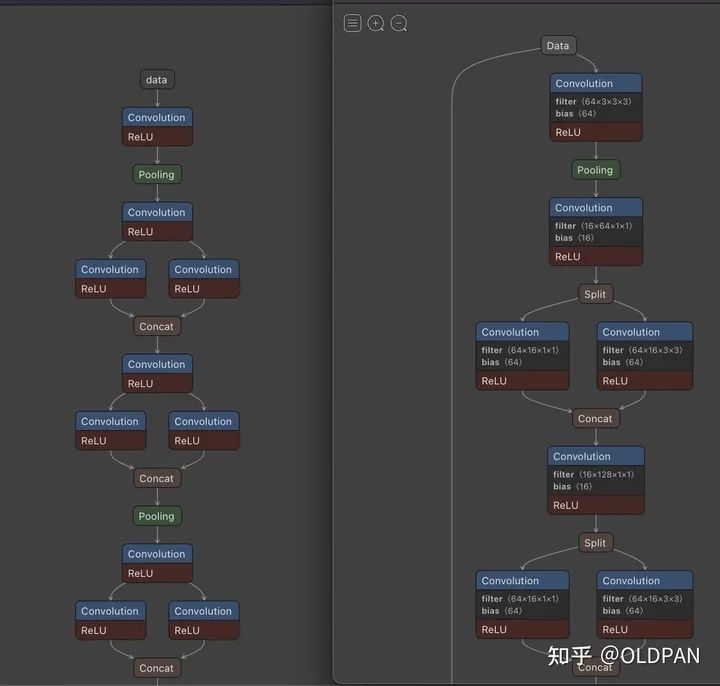
Caffemodel
表示,而相应的结构是
prototxt
。
如上图,左面是
prototxt
右面是
caffemodel
,而caffemodel使用的是protobuf这个数据结构表示的。
我们当然也要先读出来:
model = caffe_pb2.NetParameter()
print('Loading caffemodel: ' + caffemodel)
with open(caffemodel, 'rb') as fp:
model.ParseFromString(fp.read())
caffe_pb2就是caffemodel格式的protobuf结构,具体的可以看上方老潘提供的库,总之就是定义了一些Caffe模型的结构。
而提取到模型权重后,通过prototxt中的模型信息,挨个从caffemodel的protobuf权重中找,然后复制权重到Pytorch端,仔细看这句caffe_weight = torch.from_numpy(caffe_weight).view_as(self.models[lname].weight),其中self.models[lname]就是已经搭建好的对应Pytorch的卷积层,这里取weight之后通过self.models[lname].weight.data.copy_(caffe_weight)将caffe的权重放到Pytorch中。
很简单吧。
if ltype in ['Convolution', 'Deconvolution']:
print('load weights %s' % lname)
convolution_param = layer['convolution_param']
bias = True
if 'bias_term' in convolution_param and convolution_param['bias_term'] == 'false':
bias = False
# weight_blob = lmap[lname].blobs[0]
# print('caffe weight shape', weight_blob.num, weight_blob.channels, weight_blob.height, weight_blob.width)
caffe_weight = np.array(lmap[lname].blobs[0].data)
caffe_weight = torch.from_numpy(caffe_weight).view_as(self.models[lname].weight)
# print("caffe_weight", caffe_weight.view(1,-1)[0][0:10])
self.models[lname].weight.data.copy_(caffe_weight)
if bias and len(lmap[lname].blobs) > 1:
self.models[lname].bias.data.copy_(torch.from_numpy(np.array(lmap[lname].blobs[1].data)))
print("convlution %s has bias" % lname)
Pytorch2TensorRT
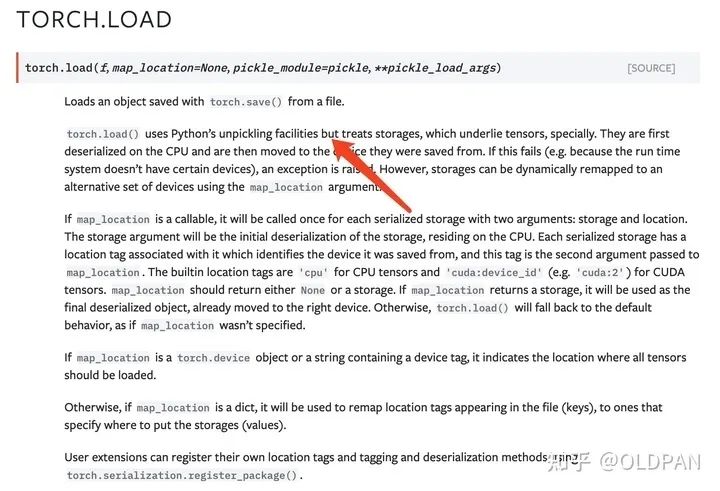
先举个简单的例子,一般我们使用Pytorch模型进行训练。训练得到的权重,我们一般都会使用torch.save()保存为.pth的格式。
PTH是Pytorch使用python中内置模块pickle来保存和读取,我们使用netron看一下pth长什么样。。
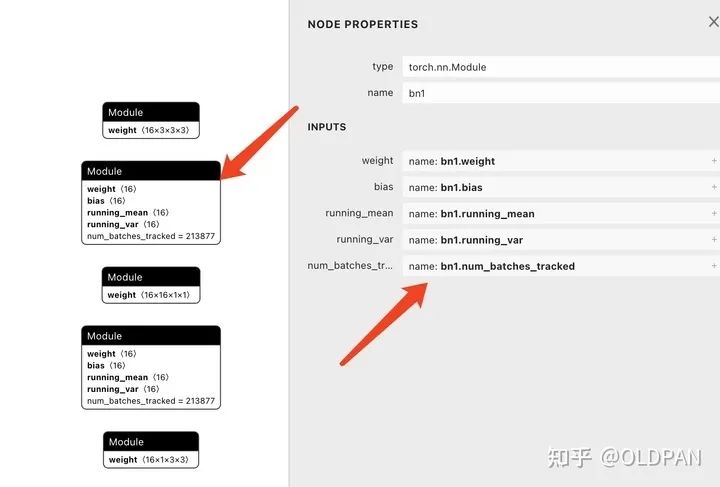
可以看到只有模型中有参数权重的表示,并不包含模型结构。不过我们可以通过.py的模型结构一一加载.pth的权重到我们模型中即可。
看一下我们读取.pth后,state_dict的key。这些key也就对应着我们在构建模型时候注册每一层的权重名称和权重信息(也包括维度和类型等)。

当然这个pth也可以包含其他字符段{'epoch': 190, 'state_dict': OrderedDict([('conv1.weight', tensor([[...,比如训练到多少个epoch,学习率啥的。
对于pth,我们可以通过以下代码将其提取出来,存放为TensorRT的权重格式。
def extract_weight(args):
# Load model
state_dict = torch.load(args.weight)
with open(args.save_path, "w") as f:
f.write("{}\n".format(len(state_dict.keys())))
for k, v in state_dict.items():
vr = v.reshape(-1).cpu().numpy()
f.write("{} {} ".format(k, len(vr)))
for vv in vr:
f.write(" ")
f.write(struct.pack(">f", float(vv)).hex())
f.write("\n")
需要注意,这里的TensorRT权重格式指的是在build之前的权重,TensorRT仅仅是拿来去构建整个网络,将每个解析到的层的权重传递进去,然后通过TensorRT的network去build好engine。
// Load weights from files shared with TensorRT samples.
// TensorRT weight files have a simple space delimited format:
// [type] [size] <data x size in hex>
std::map<std::string, Weights> loadWeights(const std::string file)
{
std::cout << "Loading weights: " << file << std::endl;
std::map<std::string, Weights> weightMap;
// Open weights file
std::ifstream input(file);
assert(input.is_open() && "Unable to load weight file.");
// Read number of weight blobs
int32_t count;
input >> count;
assert(count > 0 && "Invalid weight map file.");
while (count--)
{
Weights wt{DataType::kFLOAT, nullptr, 0};
uint32_t size;
// Read name and type of blob
std::string name;
input >> name >> std::dec >> size;
wt.type = DataType::kFLOAT;
// Load blob
uint32_t *val = reinterpret_cast<uint32_t *>(malloc(sizeof(val) * size));
for (uint32_t x = 0, y = size; x < y; ++x)
{
input >> std::hex >> val[x];
}
wt.values = val;
wt.count = size;
weightMap[name] = wt;
}
std::cout << "Finished Load weights: " << file << std::endl;
return weightMap;
}
那么被TensorRT优化后?模型又长什么样子呢?我们的权重放哪儿了呢?
肯定在build好后的engine里头,不过这些权重因为TensorRT的优化,可能已经被合并/移除/merge了。
模型参数的学问还是很多,近期也有很多相关的研究,比如参数重参化,是相当solid的工作,在很多训练和部署场景中经常会用到。
后记
先说这些吧,比较基础,也偏向于底层些。神经网络虽然一直被认为是黑盒,那是因为没有确定的理论证明。但是训练好的模型权重我们是可以看到的,模型的基本结构我们也是可以知道的,虽然无法证明模型为什么起作用?为什么work?但通过结构和权重分布这些先验知识,我们也可以大概地对模型进行了解,也更好地进行部署。
至于神经网络的可解释性,这就有点玄学了,我不清楚这里也就不多说了~

极市干货
“
点击阅读原文进入CV社区
收获更多技术干货

