开什么玩笑,京东2个人管理数百万个容器
作者:集群技术部
转自订阅号:TIGCHAT,已授权运维帮转发
CNCF官方确认,京东目前运营着全世界最大规模的Docker集群、Kubernetes集群,以及最复杂的Vitess集群之一,全量100%实现了“All in Containers”,是目前全球容器化最彻底的互联网企业之一,也是CNCF开源项目最大的使用者与贡献者之一。目前京东生产环境运行着超过数百万个容器规模。

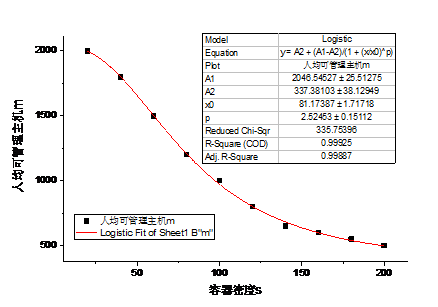
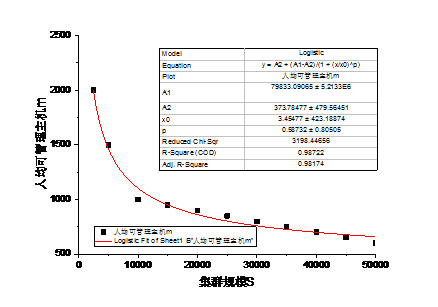
京东的容器建设始于2014年,随着集群规模的逐步增大,集群管理过程中暴露出的问题越来越多,管理难度越来越大。特别是容器数量超过百万级以后,常规的管理手段基本无法奏效。直接表现就是人效比下降非常快,单个故障的平均定位时间从5min衰减到30min。作为国内最早大规模在生产环境进行容器化部署的公司,超大规模容器集群的管理,对我们而言也是一个摸着石头过河的过程,国内外并没有太过成熟的经验可以借鉴。在严肃的现实需求的推动下,我们开启了JDOS运营平台的研发。图1和图2是我们根据日常集群运营过程的数据对集群规模S、容器密度s(平均每台服务器上部署容器的个数)、以及人均可管理服务器的台数m进行的回归分析。
我们对日常集群管理过程中的工作做了分析和总结发现,超大规模集群管理过程中,人效比下降的原因来源有几个:
随着集群规模的增大,运维人员操作带来的故障越来越多;
随着集群规模的增大,集群差异带来的运维难度越来越大;
随着集群规模的增大,一次全量环境检查时间越来越长;
随着集群规模的增大,单位时间内的告警数量越来越多;
随着集群规模的增大,单个故障的排障花费时间越来越长;
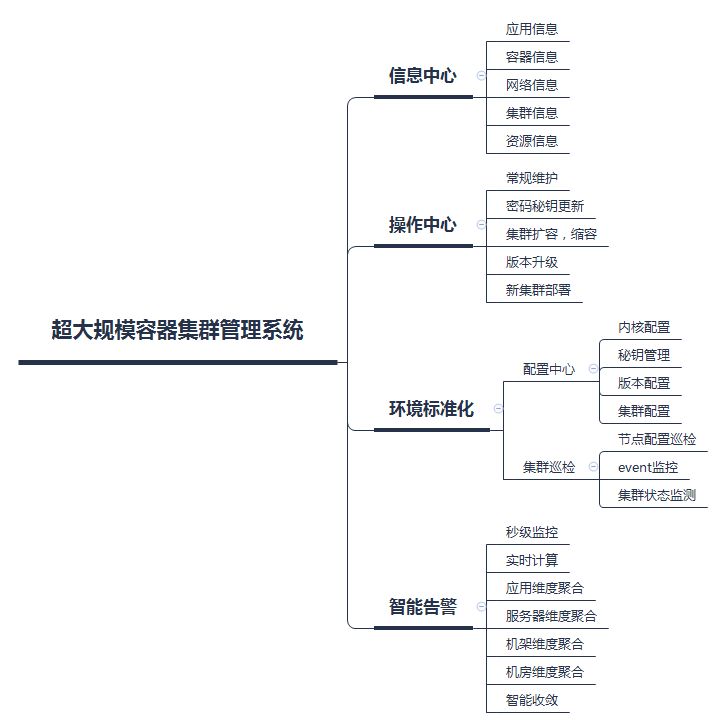
基于此,JDOS运营平台设计之初,我们从线上操作、环境标准化、智能告警三个主要维度进行了相关考量。系统的整体功能树如图3所示:
系统主要的架构和组件如图-4所示。配置中心是整个系统的大脑,集群相关信息都在配置中心进行配置,包括各节点操作系统版本、kubernetes各组件版本、节点zone信息配置,各节点上百个内核参数的配置、集群硬件信息、硬件驱动版本配置、集群用途等信息。配置中心是整个系统的信息来源,巡检系统和操作中心的行为都依赖于配置中心的配置,配置中心也是保证集群标准化的信息来源。
操作中心负责节点实际操作,如版本升级、日志清理、密码更新、集群的扩容和缩容、控制节点故障恢复、新集群的部署等工作。实现了常规运维工作100%通过界面来操作,尽量避免人工输入命令带来的误操作概率。
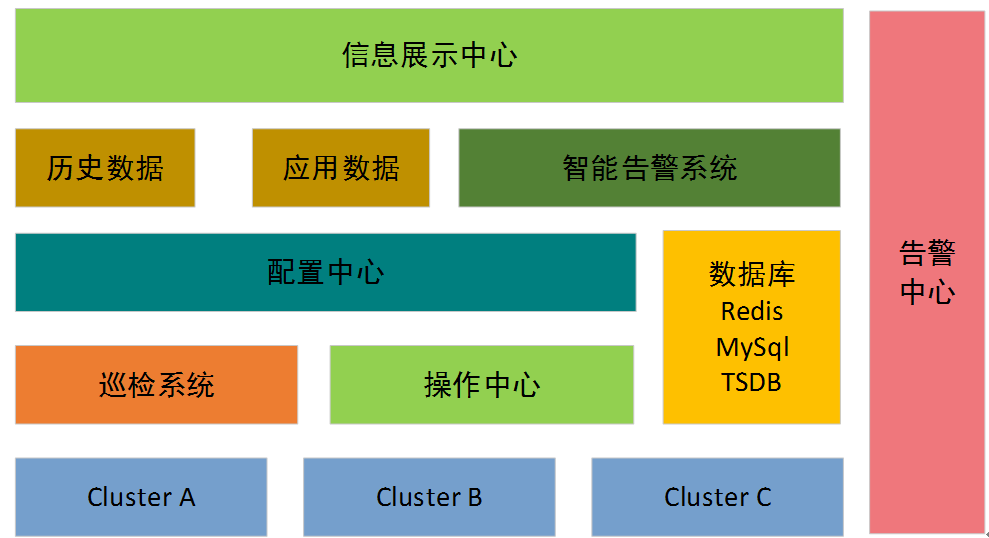
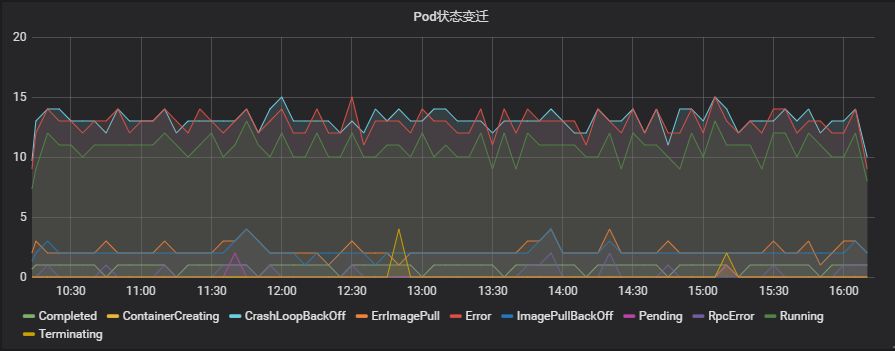
信息展示中心,负责各集群、各机房、各应用、不同维度的信息展示,也是京东内部的账单展示中心。在这里既能看到线上资源使用情况,也能查看各部门,不同应用的资源使用情况、应用的健康情况以及不同集群在过去某一时间周期内的告警、负载均衡流量信息、DNS解析情况等信息。除此之外,也可以查看各k8s集群的实时调度信息、容器状态变迁等信息,作为集群性能优化的依据。
如果说配置中心是线上集群的信息“大脑”,那么巡检系统就是线上集群的“眼睛”,及时发现任何和配置中心不符合的信息,然后通过操作中心这个“手”来做实际的操作,最终保证各集群配置和配置中心保持高度的一致,从而实现线上环境的标准化。京东的第一代线上巡检系统是基于ansible实现的,选择ansible的原因也比较简单。首先ansible使用简单,不需要任何客户端;其次京东第一代容器技术是基于openstack实现的,python语言非常熟悉,没有额外学习成本,非常容易进行相关的二次开发。在相当长时间内,这套巡检系统运行良好,但是随着集群规模的增大,ansible的性能缺点越来越明显。由于巡检项目比较多,数万节点,全部巡检完需要接近40分钟时间。每次做完线上变更后,需要快速巡检时,完全不能满足需求。
抛开性能问题,这种基于ansible实现的集中式的巡检系统,还存在一些其他问题。比如某一时刻,巡检系统探测到某一节点不存活,事实上我们并没有办法确认节点是否真的不存活,也可能是ansible服务和节点之间的网络存在故障。
要想解决服务的单点问题,只能使用分布式架构。分布式系统离不开CAP理论,那么作为一个巡检系统,我们实际需求是一个弱一致性的系统,需要开发一套高性能的AP系统。Gossip协议就是符合我们需求的一个弱一致性协议。
Gossip协议利用随机的方式将信息散布到整个网络中,消息散布方式类似于病毒的传播。所以我们研究Gossip协议的性能,可以直接通过Epidemiology模型来研究。病毒传染模型里下面四个假设:
1) 所有n+1人是均匀分布的;
2) 任何两个人之间传染的概率是P,0<P<1;
3) 任意一个人只有两个状态,被传染或没有被传染;
4) 一旦一个人从未传染状态变成被传染状态以后,则永远停留在被传染状态。
任意t时刻,被感染的人数Yt,未被感染人数为Xt,则任意时刻都有Yt+Xt=n+1,假设初始时刻被传染人为1,那么t时刻,被感染人数为
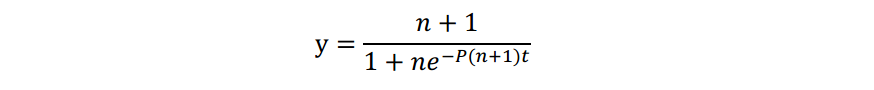
假定每个人每次感染的人数为m,那么任一时刻,某人被感染的概率P=m/n;
显然,当t=klog(n)时,y=n+1,即经过log(n)次传染,即可传染所有人,类比到Gossip协议,经过个回合,即可将信息发送到所有的节点。
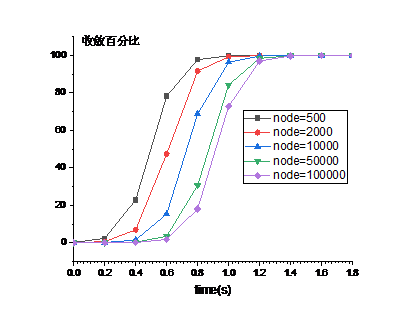
原生的Gossip协议并不能直接拿来实现巡检系统。我们选择Serf作为第二代巡检系统的基础框架。Serf是Hashicorp公司的开源项目,对Gossip协议进行了优化。和原生协议相比有着更好的收敛速度,更快的信息传播速度。图-6是不同节点场景下,Serf收敛测试。测试时,我们设置每个节点每次传播5个节点,生产环境中正常情况下没有丢包和失败,任意两个节点之间信息的传递时间小于100ms,网卡MTU值设置为1500,每次信息传播过程中,单个节点消耗最大带宽约为1000kbps。明显可以看出,serf的收敛速度非常快,在10万节点的集群中,消息可以在2秒内完成传递。
Serf的优势在于快速的收敛速度和信息传播速度。节点的探活我们使用了Serf的故障检测机制来进行。但是集群巡检需要有结果的返回,所以Serf的event功能并不能实现巡检功能。我们使用Serf的query功能来是实现待巡检节点上巡检脚本的执行和巡检结果的返回。由于query命令返回结果的过程使用UDP协议,返回值大小有一定的限制。所以我们的系统中,正常的巡检过程完全在巡检节点上进行,最终只返回成功或失败。然后通过ansible对失败节点进行二次确认,获取巡检异常节点的详细信息。和第一代完全基于ansible的巡检系统相比效率大大提高,在京东一个典型的10000台节点的集群,基本能在3min内完成全部巡检。
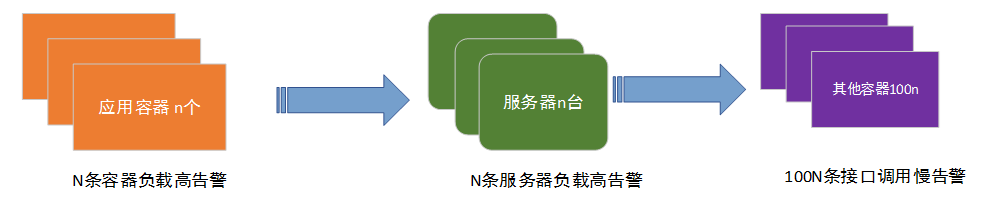
根据IBM的研究发现,在大规模集群(node数量超过10000)中,单个节点平均36小时会出现异常,异常就会触发告警。再加上平均每个节点上超过100个的容器,正常情况,会出现大量的告警。海量告警大幅度降低了运维人员的效率,而且很多场景下,会由于单一原因造成多条告警。在没有智能告警系统之前,某业务进程bug导致容器负载和服务器负载双高场景下触发的告警情况如图-7所示,假设该应用有50个容器,平均每台服务器上运行100个不同业务容器。那么由于该业务bug导致的告警会有50+50+100*50 = 5100条。这类场景下,实际告警只需要一条,就是初始应用维度的一条告警。
智能告警系统的架构如图-8所示。容器和物理机的秒级监控数据都通过Nodemonitor这个agent进行采集,经过数据预处理以后,存入TSDB。智能告警系统通过数据聚合以后,进行智能告警,智能告警最大的好处有两个,一个是告警数量的收敛,另一个是告警原因的预判。
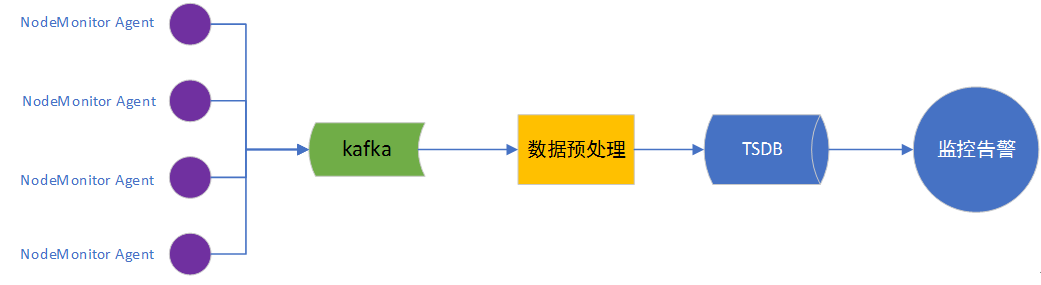
告警收敛主要采用关联分析来实现。从机房开始、一直到容器级别,各个层面指标的关联分析,最终得出告警源,从而实现告警的类别和告警数量的收敛。决策系统主要用来查找告警之间的因果关系,确认最终告警的类型和告警目标。
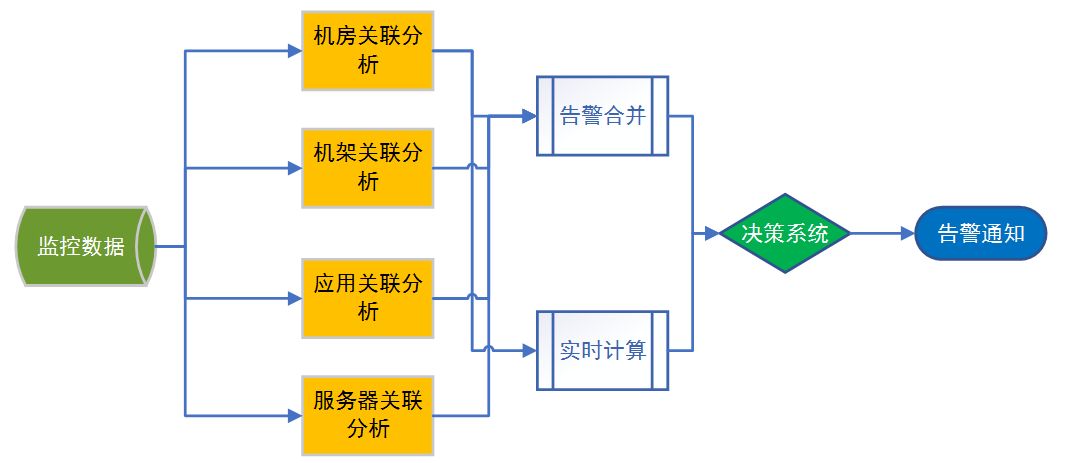
告警收敛能有效减少告警数量,也能提高告警的准确度。告警原因和告警预判则能帮助系统维护人员提前发现问题,并快速定位问题的根因。决策系统主要通过评分机制,对当前指标的健康度进行打分评价,如果异常指标过多,那么该节点的健康度指标就会非常低,健康度指标越低,越容易触发告警。
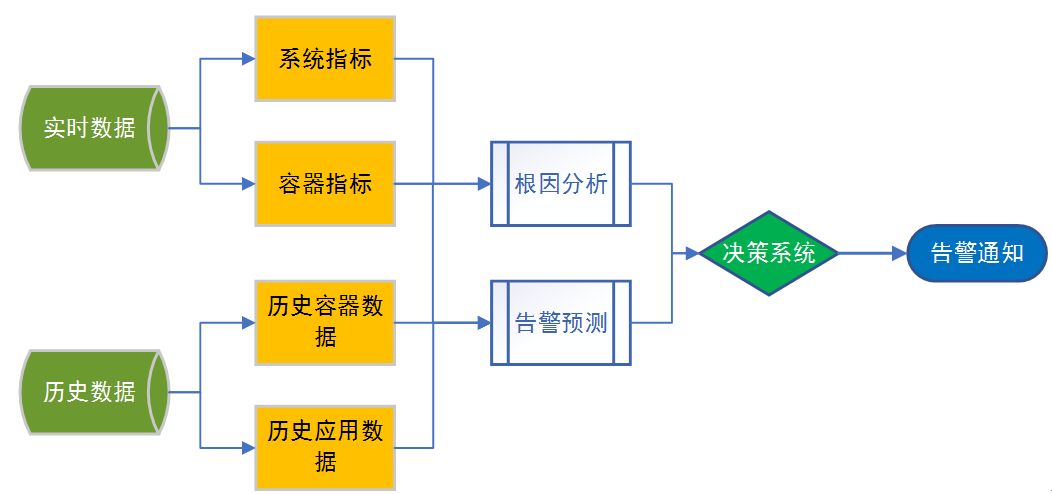
通过历史数据的比对和当前数据的实时计算分析,对于内存泄漏、异常流量、线程泄漏等问题,可以做到提前发现,提前告警,快速定位。能大大提高运维人员处理告警时的效率。
JDOS运营平台并不神秘,我们只是通过技术手段,降低了线上环境的不一致性,减少了运维人员对线上环境的直接登陆操作,通过智能告警系统,在大幅减少待处理告警的同时对告警的根因进行了分析和预测,提高了运维人员处理问题的效率。
运维帮提供购买云主机大优惠
主流云厂商都已和运维帮达成战略合作,不管是1台还是100台,都可以享受到价格优惠,请联系群秘书。
欢迎加入「运维帮地方群」,现在有北京地方群、上海地方群、深圳地方群、成都地方群、广州地方群、杭州地方群。入群请先加群秘书(长按识别下方二维码),加群秘书时请告知所在城市及公司。
群秘书微信,扫描下方二维码





