![]()
——免费加入AI技术专家社群>>
——免费加入AI高管投资者群>>
目前最前沿的说话人识别系统中,有不少是基于 i-vector + PLDA (probabilistic linear discriminant analysis)的。在 2017 年的 ICASSP 和 Interspeech 会议中,基于 PLDA 的说话人识别论文数量与基于神经网络的说话人识别论文数量可以抗衡。
在神经网络席卷了机器学习众多领域的今天,为什么 PLDA 依然能够坚挺地存在呢?它有什么优点是神经网络所没有的?
相信这个问题是很多说话人领域的研究者所关心的,每个人也都有自己的考量。更明确一点,其实不限于PLDA, 而是整个ivector 框架都不容易被神经网络beat掉(虽然坚挺,但是正在逐步被beat,只是进度不像语音识别里那样势如破竹)。在此,谈一点我自己的看法。(本文中提到的所有dnn均指代深度神经网络,不特指某一种网络架构)
1. 深度学习在说话人识别领域的应用现状
写论文的时候经常写“深度学习在语音识别领域中的成功应用鼓励着研究者将它运用在说话人识别中去”。 但是实际上呢,14、15年的说话人识别论文是几乎看不到DNN的存在的。仅有的几篇也是代替ivector 框架中的gmm 去计算统计量[1],提取一些bottleneck 特征等等非本质性、变革性的工作。直到google d-vector[2]的出现,它虽然简单,但是有重要意义,因为这算是一个纯dnn 框架下的说话人识别系统。我们实验室也做了部分工作,比如bottleneck feature,文本相关任务中的j-vector等等[3,4]。清华王东老师组也是一直在沿着d-vector的框架在做。2016年的icassp上,google 发布了第一篇end2end的说话人识别系统[5],标志着DL-based SID的第二个阶段吧。这个工作思路清晰,针对最终的评价指标直接优化整个网络,存在的问题当然就是这种binary loss的 学习非常的greedy,很难去学到比较generalizable的东西。Google 的任务和数据量,并不适用于大多数情况,所有的训练、注册、测试数据都是“ok,google”,而在现实中,很难找到这种如此匹配,如此大量的训练数据。后续的基于triplet loss 的end2end [6,7]系统算是暂时成熟的系统,复现出来的结果也确实是work的,但是这更像是一种embedding 的学习,而不是端到端(给我测试句子,直接输出接受或者拒绝)的系统。现阶段的基于深度学习的embedding(或者end2end架构)[6,7,8,9],一般都在各自的数据集上达到了跟i-vector comparable 甚至略好的结果
2. 隐变量空间学习的重要性
为什么在语音识别中dnn的应用会带来如此明显的性能提升,在说话人任务却给人一种挣扎的感觉? 我觉得这跟任务属性是直接相关的。 语音识别的深度学习框架,输出是senone,本质上不存在集外的概念。任何一句话里边的音素都可以在输出层找到它对应的节点,当帧准越高,一般语音识别的正确率也就越高。相对于GMM 这种生成模型,类别确定,不存在集外情况,当然是鉴别性训练(dnn + softmax ce)会好了。但是说话人识别不一样,我们不可能要求测试的人在训练过程中出现过,更不可能直接训练一个所有人的分类器。因此我们希望找到一个隐变量空间,每个人都是这个空间里的一个点,可以用这个空间的一组基来表示。ivector 就是找到了这样的一个隐变量空间。怎么用DNN 学到这样的一个隐变量空间? 拿简单的d-vector框架来讲,output 层标签是说话人类别,当这个类别数目远大于最后一个隐层节点个数的时候,可以在某种程度上认为最后一个隐层可以建模这个隐变量空间。假设训练数据共有1000个说话人,如果隐层节点也是1000,甚至大于1000,我认为这个时候训练过程中的最优解是把不同的人映射成一个1-hot 向量,更别说什么学到隐空间基的表示了。但是当隐层节点是500,output 层有5000类,甚至10000类的时候,神经网络就不得不找到某种内在的更复杂的表示了。
3. 什么样的embedding 才是好的embedding?
embedding 是真的火啊,今年interspeech 有18篇文章里边都提到了embedding。fixed-dimension, low-dimension embeddings 优点很多,便于存储,容易打分,还容易当做其他任务的输入进行训练。那么什么样的embedding是好的呢?针对这个问题,答案是确定的:small within-class variance, large between-class distance
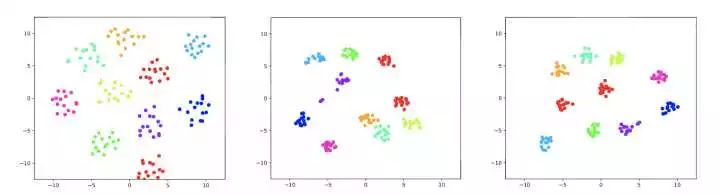
这也是ivector 的后处理过程中采用LDA, PLDA 等变换的一个出发点,希望投影后的向量空间中,同类说话人的embedding 越相似越好,不同类说话人的embedding 差别越大越好。triplet loss 的设计,会在训练过程中产生类似的constraint, 下图是我们复现出来的triplet loss end2end 系统提出来的embedding 和 ivector 的对比图,左边是ivector,中间是end2end,右边是我们正在做的工作(submitted to icassp2018)。
![]()
4. 为什么一般来讲PLDA 对 ivector work,但是对神经网络提出来的embedding 并不work[10]
但是无论是LDA也好,PLDA也好,对数据分布都是有高斯假设的,况且这类模型最高也就只考虑到second-order statistics(高斯也是只考虑到二阶,variance),更复杂的分布是需要更高阶的描述的。我们又很难说神经网络的输出是符合什么分布。简单的Length-norm 是可以高斯化embedding,但是并不够。 更新:经chunlei 师兄提醒,PLDA 对embedding 还是有一些效果的,特别是对noisy data。 可能是我自己的实验数据属于比较clean的,因此PLDA的优势没有完全发挥出来,gauss 分布只是部分原因;当然,在深度学习框架下有很多的抗噪算法,个人更倾向的方向是整体集成在同一个框架下,通过神经网络进行抗噪鲁棒性训练~
5. 那说话人识别中深度学习的未来的方向会是什么呢?
今年interspeech 说话人session非常神奇,开了好几个panel 都是在讨论一些比较general, 定基调的东西。其中有一场就是讨论说话人识别的未来十年。下边是这个panel 上Niko 的一页ppt,我也思考过类似的东西,所以当时比较关注。IS17结束的时候刚好跟他坐同一班飞机,聊了一路,甚是开心。我们都认为现在的神经网络缺乏对uncertainty的建模,希望把bayes的东西引入进来(Niko跟Najim 这次的interspeech上发了一篇VAE代替PLDA的文章[11],我之前也尝试过VAE 在说话人里替换ivector 的想法,没做出来就去忙其他的事情了……他问我有没有遇到什么问题,我说了之后他说他们也遇到了同样问题,所以就先退而求其次去替换PLDA了,猜测他们会在这次的icassp上发表新的相关的东西,这帮大佬太喜欢推公式了,我等渣渣数学还是瓶颈啊)
![]()
总而言之,深度学习在说话人任务上前景还是很好的,但是需要想想怎么去更好的学习上述提到的这种隐空间表示。之所以ivector/PLDA这么坚挺,是因为隐变量模型确实适合说话人任务啊!
说话人识别任重而道远啊!距离真正可用还有很大差距,同志们加油。。。
原文:https://www.zhihu.com/question/67471632/answer/253347640
黑科技|Adobe出图象技术神器!视频也可以PS了!!
史上第一个被授予公民身份的机器人索菲亚和人对答如流!
浙大90后女黑客在GeekPwn2017上秒破人脸识别系统!
周志华点评AlphaGo Zero:这6大特点非常值得注意!
汤晓鸥教授:人工智能让天下没有难吹的牛!
英伟达发布全球首款人工智能全自动驾驶平台
未来 3~5 年内,哪个方向的机器学习人才最紧缺?
中科院步态识别技术:不看脸 50米内在人群中认出你!
厉害|黄仁勋狂怼CPU:摩尔定律已死 未来属于GPU!
干货|7步让你从零开始掌握Python机器学习!