掌握BERT、GPT-3、图神经网络、知识图谱等大厂必备技能!
金三银四很快就到了,铁子们做好跳槽拿高薪的准备了吗?
回想去年的算法岗,可谓是从灰飞烟灭到人间炼狱。之后的趋势都变成了这样:转行的开始转行,换专业的开始换专业。

对于这位朋友的问题,我想从两方面开始回答。
很多大多数欲从事NLP相关工作的同学,往往都是通过自学的方式来进行学习,但是这样很明显的问题是:
-
我知道怎么做 -
我做过
为了真正全面系统的培养NLP人才,贪心学院推出了《自然语言处理终身升级版》课程覆盖了从经典的机器学习、文本处理技术、序列模型、深度学习、预训练模型、知识图谱、图神经网络所有必要的技术。并落地实操工业级项目,由资深的NLP负责人全程直播讲解,帮助你融会贯通,轻松拿offer。
助你成为行业TOP10%的工程师
对课程有意向的同学
扫描二维码咨询

第一章:自然语言处理概述
自然语言处理的现状与前景
自然语言处理应用
自然语言处理经典任务
时间复杂度、空间复杂度
动态规划
贪心算法
各种排序算法
逻辑回归
最大似然估计
优化与梯度下降法
随机梯度下降法
理解过拟合、防止过拟合
L1与L2正则
交叉验证
正则与MAP估计
各类分词算法
词的标准化
拼写纠错、停用词
独热编码表示
tf-idf与相似度
分布式表示与词向量
词向量可视化与评估
独热编码的优缺点
分布式表示的优点
静态词向量与动态词向量
SkipGram与CBOW
SkipGram详解
Negative Sampling
语言模型的作用
马尔科夫假设
UniGram, BiGram, NGram模型
语言模型的评估
语言模型的平滑技术
HMM的应用
HMM的Inference
维特比算法
前向、后向算法
HMM的参数估计详解
有向图与无向图
生成模型与判别模型
从HMM与MEMM
MEMM中的标签偏置
Log-Linear模型介绍
从Log-Linear到LinearCRF
LinearCRF的参数估计
理解神经网络
各种常见的激活函数
反向传播算法
浅层模型与深度模型对比
深度学习中的层次表示
深度学习中的过拟合
从HMM到RNN模型
RNN中的梯度问题
梯度消失与LSTM
LSTM到GRU
双向LSTM
双向深度LSTM
Seq2Seq模型
Greedy Decoding
Beam Search
长依赖所存在的问题
注意力机制的实现
基于上下文的词向量技术
图像识别中的层次表示
文本领域中的层次表示
ELMo模型
ELMo的预训练与测试
ELMo的优缺点
LSTM模型的缺点
Transformer概述
理解自注意力机制
位置信息的编码
理解Encoder和Decoder区别
理解Transformer的训练与预测
Transformer的缺点
自编码介绍
Transformer Encoder
Masked语言模型
BERT模型
BERT的不同训练方式
ALBERT
RoBERTa模型
SpanBERT模型
FinBERT模型
引入先验知识
K-BERT
KG-BERT
Transformer Encoder回顾
GPT-1, GPT-2, GPT-3
ELMo的缺点
语言模型下同时考虑上下文
Permutation LM
双流自注意力机制
信息抽取的应用和关键技术
命名实体识别
NER识别常用技术
实体统一技术
实体消歧技术
指代消解
关系抽取的应用
基于规则的方法
基于监督学习的方法
Bootstrap方法
Distant Supervision方法
句法分析的应用
CFG介绍
从CFG到PCFG
评估语法树
寻找最好的语法树
CKY算法
从语法分析到依存文法分析
依存文法分析的应用
基于图算法的依存文法分析
基于Transition-based的依存文法分析
依存文法的应用案例
知识图谱的重要性
知识图谱中的实体与关系
非结构化数据与构造知识图谱
知识图谱设计
图算法的应用
模型压缩重要性
常见的模型压缩总览
基于矩阵分解的压缩技术
基于蒸馏的压缩技术
基于贝叶斯模型的压缩技术
模型的量化
图的表示
图与知识图谱
关于图的常见算法
Deepwalk和Node2vec
TransE图嵌入算法
DSNE图嵌入算法
卷积神经网络回顾
在图中设计卷积操作
图中的信息传递
图卷积神经网络
图卷积神经网络的经典应用
从GCN到GraphSAge
注意力机制回归
GAT模型详解
GAT与GCN比较
对于异构数据的处理
Node Classification
Graph Classification
Link Prediction
社区挖掘
推荐系统
图神经网络的未来发展
助你成为行业TOP10%的工程师
对课程有意向的同学
扫描二维码咨询
|
|
| 2. 从零实现Word2Vec词向量 |
| 3. 利用SkipGram做推荐 |
| 4. 从零实现HMM模型 |
| 5. 基于Linear-CRF的词性分类器实现 |
| 6. 从零实现深度学习反向传播算法 |
| 7. 实现AI程序帮助写程序 |
| 8. 实现AI程序帮助写文章 |
|
|
| 10. 基于KG-BERT的知识图谱学习 |
| 11. 基于知识图谱的风控系统 |
| 12. 基于知识图谱的个性化教学 |
| 13. 利用蒸馏算法压缩Transformer |
| 14. 利用GCN实现社交推荐 |
| 15. 基于GAT的虚假新闻检测 |
| (剩下20+个案例被折叠,完整请咨询...) |
豆瓣电影评分预测
中文分词技术
独热编码、tf-idf
分布式表示与Word2Vec
BERT向量、句子向量
智能客服问答系统
问答系统搭建流程
文本的向量化表示
FastText
倒排表
问答系统中的召回、排序
基于Linear-CRF的医疗实体识别
命名实体识别
特征工程
评估标准
过拟合
基于闲聊的对话系统搭建
常见的对话系统技术
闲聊型对话系统框架
数据的处理技术
BERT的使用
Transformer的使用
搭建基于医疗知识图谱的问答系统
医疗专业词汇的使用
获取问句的意图
问句的解释、提取关键实体
转化为查询语句
搭建基于医疗知识图谱的问答系统
文本摘要生成介绍
关键词提取技术
图神经网络的摘要生成
基于生成式的摘要提取技术
文本摘要质量的评估
| 主题 |
论文名称 |
| 机器学习 |
XGBoost: A Scalable Tree Boosting System |
| 机器学习 |
Regularization and Variable Selection via the Elastic Net |
| 词向量 | Evaluation methods for unsupervised word embeddings |
| 词向量 | Evaluation methods for unsupervised word embeddings |
| 词向量 | GloVe: Global Vectors for Word Representation |
| 词向量 | Deep Contexualized Word Representations |
| 词向量 |
Attention is All You Need |
| 词向量 |
BERT: Pretraining of Deep Bidirectional Transformers for Language Understanding |
| 词向量 | XLNet: Generalized Autoregressive Pretraining for Language Understanding |
| 词向量 |
KG-BERT: BERT for Knowledge Graph Completion |
| 词向量 |
Language Models are Few-shot Learners |
| 图学习 | Semi-supervised Classification with Graph Convolutional Networks |
| 图学习 | Graph Attention Networks |
| 图学习 | GraphSAGE: Inductive Representation Learning on Large Graphs |
| 图学习 | Node2Vec: Scalable Feature Learning for Networks |
| 被折叠 |
其他数十篇文章...... |
助你成为行业TOP10%的工程师
对课程有意向的同学
扫描二维码咨询
理工科相关专业的本科/硕士/博士生,毕业后想从事NLP工作的人
希望能够深入AI领域,为科研或者出国做准备
希望系统性学习NLP领域的知识
目前从事IT相关的工作,今后想做跟NLP相关的项目
目前从事AI相关的工作,希望与时俱进,加深对技术的理解
希望能够及时掌握前沿技术
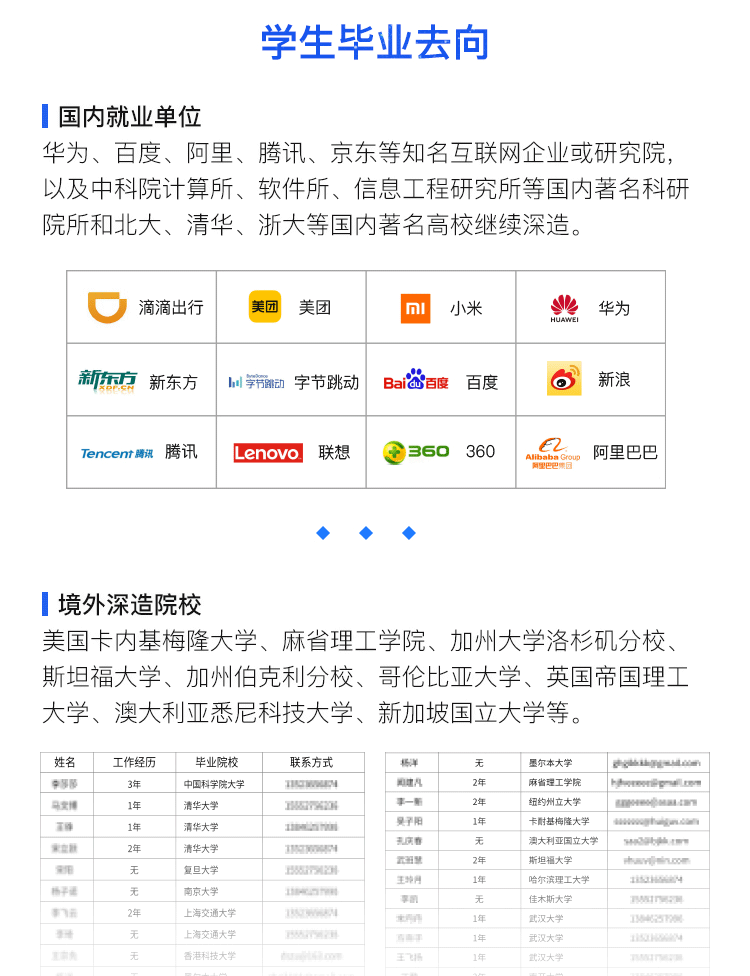
助你成为行业TOP10%的工程师
对课程有意向的同学
扫描二维码咨询




