
ExBert - A Visual Analysis Tool to Explore Learned Representations in Transformers Models
成为VIP会员查看完整内容

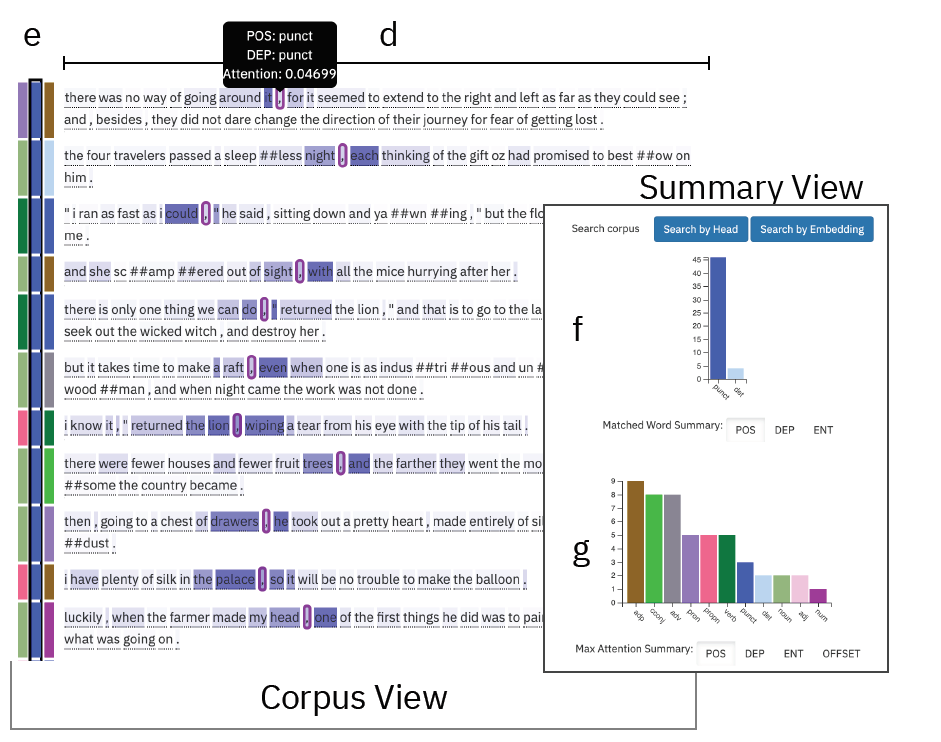
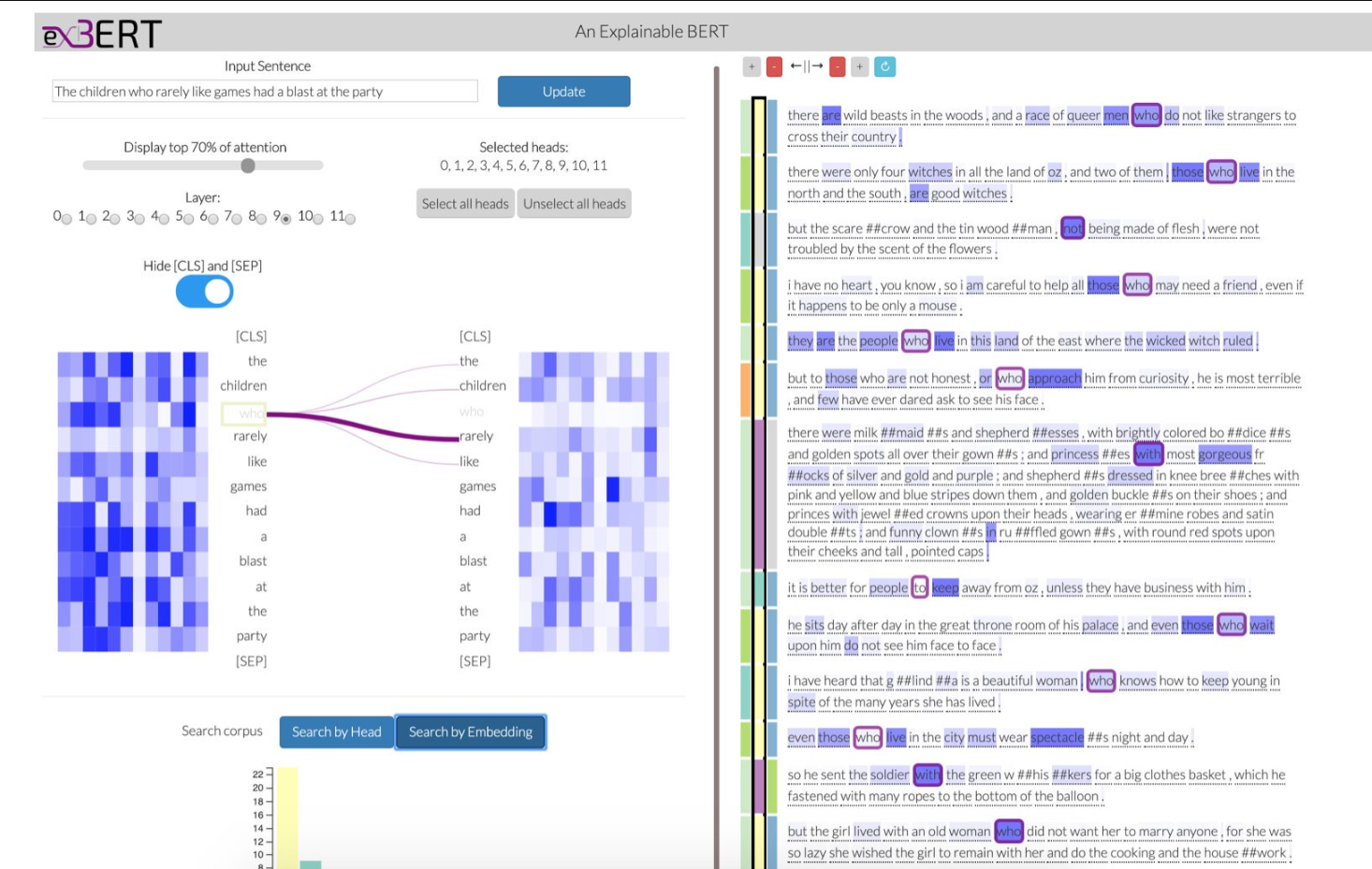
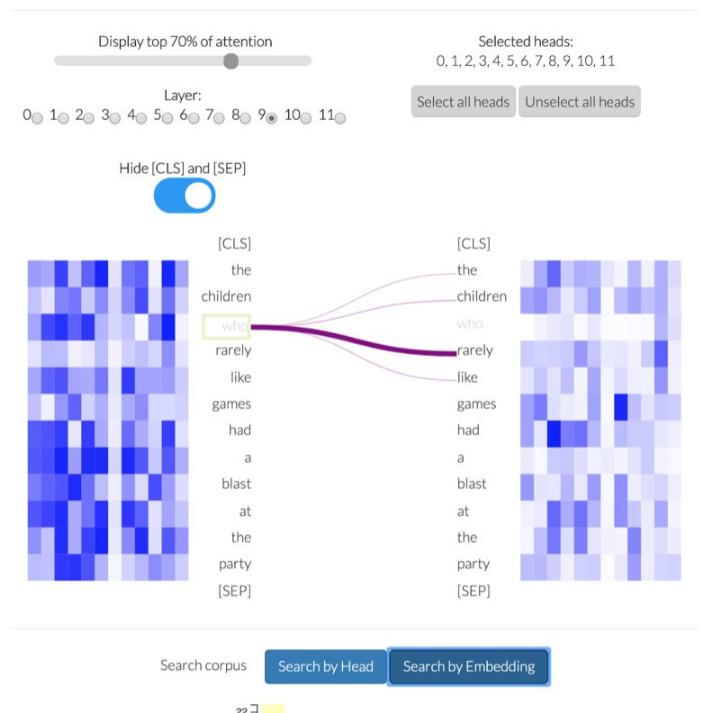
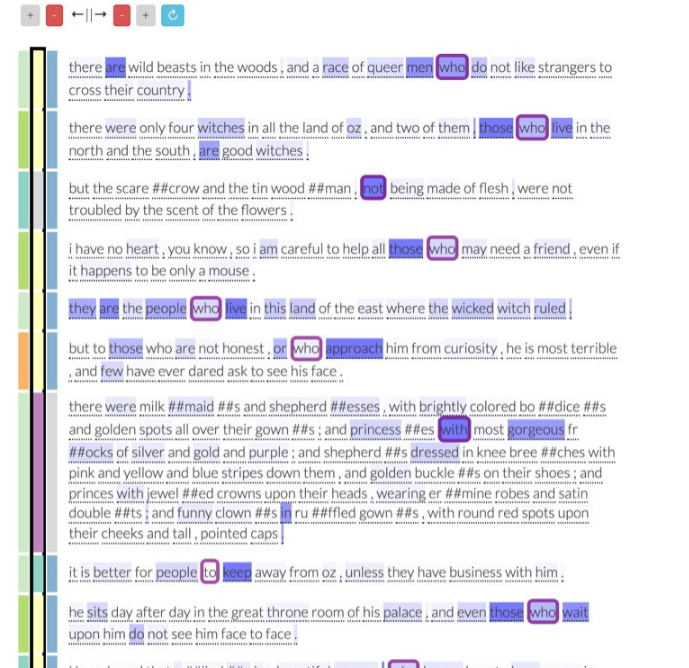
相关内容

Transformer是谷歌发表的论文《Attention Is All You Need》提出一种完全基于Attention的翻译架构
专知会员服务
36+阅读 · 2020年5月20日
专知会员服务
84+阅读 · 2019年10月18日
Arxiv
7+阅读 · 2019年9月17日
Arxiv
4+阅读 · 2019年9月11日
Arxiv
15+阅读 · 2018年10月11日
相关主题

相关VIP内容
专知会员服务
36+阅读 · 2020年5月20日
专知会员服务
84+阅读 · 2019年10月18日
相关资讯
相关论文
Arxiv
7+阅读 · 2019年9月17日
Arxiv
4+阅读 · 2019年9月11日
Arxiv
15+阅读 · 2018年10月11日