一文读懂语音识别史
语音是最自然的交流方式,但还未能与机器自然交流。自从爱迪生发明了留声机,人们就开始了与机器的交谈—— 但是主要还是与人交流,而非机器本身。

到20世纪80年代,语音识别技术能够准确地将口语转化为文本。2001年,计算机语音识别达到了80%的准确度。从那时起,我们就可以提取口语语言的含义并作出回应。然而,多数情况下,技术仍然不能像键盘输入那样带给我们足够好的交流体验。
近几年来,我们取得了巨大的技术进步。语音识别引擎的准确性已经提高了很多,现在达到了95%的准确度,略高于人类的成功的速率。随着这项技术的进步,语音优先的基础设施变得越来越重要,因此亚马逊、苹果、谷歌、微软和百度都迅速部署了声音优先软件、软件构建快和平台。声音为王的时代来了!
现在我们来仔细谈谈以下两点:
我们是如何达到当前语音识别技术水平的;
以声音为基础的基础设施是如何发展的。
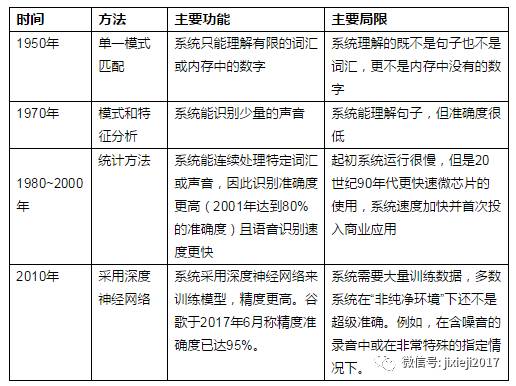
▍语言识别发展史
语音识别并非新生事物,可追溯至二十世纪50年代,只是过去采用了不同的方式来理解语音。为了更深刻地理解过去几十年的情况,我试着总结了大量相关文章。
文章来源见文末,这里特别要提到Chirs Woodford 的《语音识别软件》,为本文提供了主要依据。
1950/1960
第一个语音识别系统是基于单一模式匹配。这些早期系统的一个很好的例子就是公共事业公司曾采用的自动化系统,让客户自动抄表。在这个例子中,客户给系统的回应只是有限选项列表中的一个字或数字,计算机只需要区分有限数量的不同声音模式。
它通过将每个声音块与其内存中的类似存储模式进行比较来实现。在1952年,贝尔实验室的一个团队设计了能够理解口头数字的机器Audrey。
1970
技术进步使基于模式和特征分析的语音识别系统得以发展,其中每个字被分解成比特字节并通过关键特征(比如它包含的元音)进行识别。这种方法涉及到将声音数字化及将数字数据转换成频谱图,将其分解成声音帧,再分解单词并识别每一个的关键特征。
为了识别可能说到的内容,计算机必须将每个单词的关键特征与已知特征列表进行比对。用得越多,系统就越来越好,因为它集成了来自用户的反馈。这种方法比以前的方法要有效得多,因为口语的基本声音成本数量十分有限。
从1971年到1976年,DARPA投资了进行了五年的语音识别研究,目的是做成一台至少能理解1000个单词的机器。该计划使卡内基梅隆大学创造了一台能够理解1,011个单词的机器。
1980
但是以前的技术仍然不是超精确的,因为言语中太过复杂:不同的人会用不同的方式说出同一个词,还有许多发音相似的词(例如two和too)等等。为了进行统计,语音识别系统开始使用统计学方法。在此期间推出的关键技术就是Hidden Markov Model(HMM),被用于构建声学模型和随机语言模型。
声学模型表征音频信号和语音单元之间的关系,以重建实际发出的内容(特征→音素)。语言模型基于最后一个单词预测下一个单词,例如。与其他词语相比,“上帝保佑”的后续词更有可能是“女王”。
此外,还有一个语音字典/词典,可提供单词及其发音相关的数据,并联系声学模型和语言模型(音素→单词)。最终,当前单词的语言模型得分与其声学得分相结合,以确定假设的单词序列的可能性。
1987年,可对语音作出回应的玩具——朱莉娃娃将语音识别技术带入了普通家庭。
1990
直到20世纪90年代,语音识别系统还是太慢而无法开发有用的应用程序,但是当时推出的微处理器带来了重大进步,开始出现语音商业应用。
DragonDecitate的Dragon于1990年问世,是首个面市的语音识别产品。1997年,你可以在一分钟内对系统说出100个字。
2000
计算机语音识别在2001年达到了80%的准确度,但此后鲜有进展。
2010
过去十年里,机器学习算法和计算机性能的进步带来了更有效的训练深层神经网络(DNN)的方法。
因此,语音识别系统开始使用DNNs,更具体地说,是使用一种DNNs的特殊变体,即循环神经网络(RNNs)。此后,基于RNNs的模型表现出比传统模型更好的精度和性能。事实上,2016年的语音识别准确度达到了90%,Google在2017年6月声称已达到95%的准确率。
这太令人震惊了,要知道研究人员估计人类转录精度略还低于95%。然而,应小心对待这些公布的结果,因为它们通常是在完美的条件下的测量结果,例如,无背景噪音的录音和英语母语者的录音。在“非纯净条件下”的准确度可理解降至75-80%。
当您需要标记数据来训练算法时,现在面临的挑战是获得在现实生活中记录的数千小时的口语音频,以提供给神经网络并提高语音识别系统的准确性。这就是谷歌,亚马逊,苹果和微软正在通过置入Google Now所做的事情!
每台手机上的Siri和Cortana免费或以便宜的价格销售Alexa。这都是为了获取训练数据!
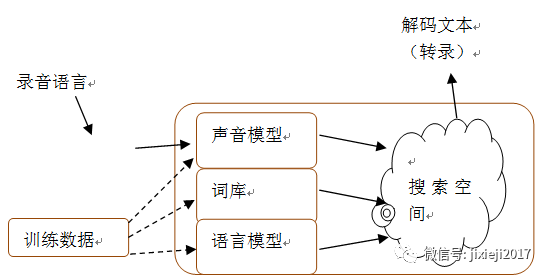
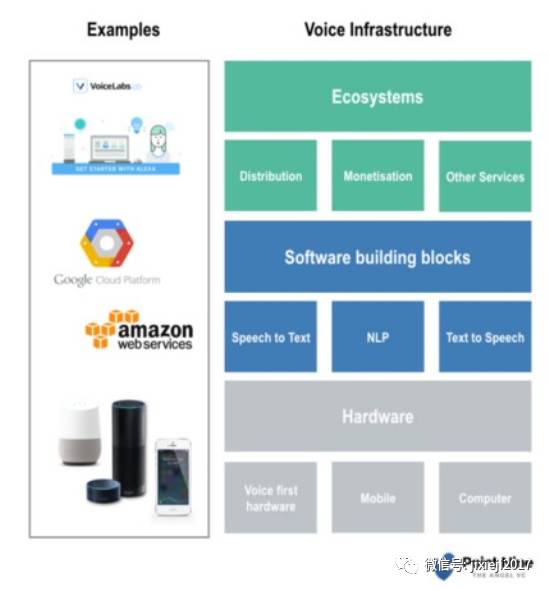
▍语音基础设施开发
语音基础设施开发,可以分为三个必要层次来产生新的应用程序:
硬件允许更多的人使用语音作为接口;
软件构建块允许开发人员构建相关的语音优先应用程序;
生态系统能实现有效分配和收益。
语音硬件的发展
Voicelabs将语音优先设备定义为始终在线的智能硬件,其中主借口是语音,包括输入和输出。市场上首个语音优先硬件是亚马逊2014年底推出的Echo。
VoiceLabs2017报告称,2015年发售的语音优先设备达170万台,2016年为650万台,而2017年将会达到2450万台,因此使用中的语音优先设备有3300万台。市场上的主要代表是亚马逊的 Echo(2014年11月)和谷歌的Home(2016年11月)。
然而,新玩家不如涌现:索尼推出了基于谷歌助手(2017年9月)的LF-S50G;苹果即将推出Homepod(2017年12月);三星最近也宣布将“即将发布”同类产品;还有Facebook可能会推出触摸屏的智能扬声器。
谷歌助手还将来迎来新的播放器,其中包括Anker推出的Zolo Mojo、Mobvoi的TicHome Mini以及Panasonic的GA10。
毫无疑问,声音优先硬件发展迅猛,且有望增长!
语音软件的发展
白手起家构建语音应用程序并非易事。Nuance和其他大公司已经向第三方开发者提供语音识别APIs,但使用这些APIs的成本达到历史新高,却没有获得惊人的成果。
随着语音识别技术开始取得更好的成果,语音优先应用的潜力越来越大,像谷歌、亚马逊、IBM、微软和苹果以及Speechmatics这样的大型公司开始以较低价格提供各种API产品。
一些最常用的包括2016年7月发布的Google Speech API,及2016年11月推出的Amazon Lex和Amazon Polly于2016年11月发布。
现在,大量开发者可以以合理的成本开始构建语音优先应用程序。
语音生态系统
随着越来越多的语音应用和硬件催生了语音的入口,平台不仅要负责分销和盈利,而且类似于分析和营销自动化这类第三方服务也变得非常重要。
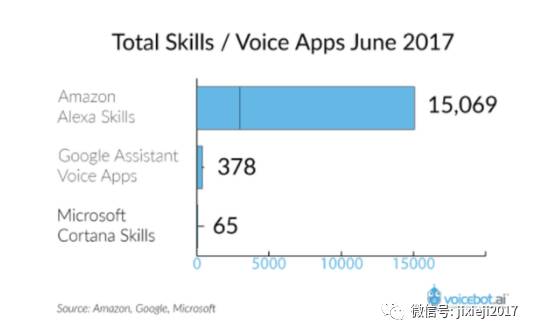
亚马逊、谷歌和微软已经开始建立这样的生态系统,苹果也即将开始。整体技能是衡量这些生态系统是否成功的一个好方法:
编译:vivian
来源:medium
★推荐阅读★
长期招聘志愿者
加入「AI从业者社群」请备注个人信息
添加小鸡微信 liulailiuwang




