用于语音识别的数据增强

本文为 AI 研习社编译的技术博客,原标题 :
Data Augmentation for Speech Recognition
作者 | Edward Ma
翻译 | 类更里、敬爱的勇哥 编辑 | 咩咩咩鱼、唐里
原文链接:
https://towardsdatascience.com/data-augmentation-for-speech-recognition-e7c607482e78
注:本文的相关链接请访问文末【阅读原文】

来自 Unsplash 的摄影:Edward Ma
语音识别的目标是把语音转换成文本,这项技术在我们生活中应用很广泛。比如说谷歌语音助手和亚马逊的 Alexa ,就是把我们的声音作为输入然后转换成文本,来理解我们的意图。
语音识别和其他NLP问题一样,面临的核心挑战之一是缺少足够的训练数据。导致的后果就是过拟合以及很难解决未见的数据。Google AI Resident 团队通过做几种数据增强的方式来解决这个问题。
本文将会讨论关于 SpecAugment:一种应用于自动语音识别的简单的数据增强方法(Park et al.,2019),将涵盖以下几个方面:
数据
结构
实验
数据
为了处理数据,波形音频转换成声谱图,然后输入神经网络中进行输出。做数据扩充的传统方式通常是应用在波形上的,Park 等人则是直接应用在声谱图上。
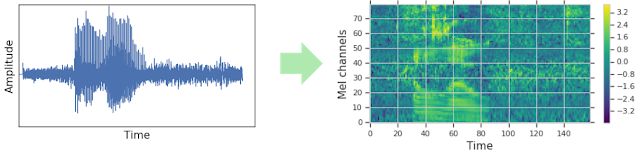
波形音频到声谱图(Google Brain)
对于一个声谱图,你可以把它看成一个横轴是时间,纵轴是频率的图像。
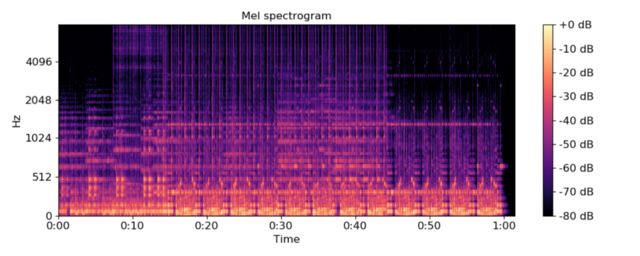
声谱图表示 (librosa)
直观上来看,声谱图提高了训练速度。因为不需要再进行波形图和声谱图之间的变换,而是扩充了声谱图的数据。
Park等人介绍了 SpecAugment 的数据扩充的方式应用在语音识别上。扩充数据有三种基本的方式:时间规整、频率掩蔽和时间掩蔽。
在他们的实验中,他们把这些方式整合在一起,并介绍了四种不同的整合方式,分别是:LibriSpeech basic (LB), LibriSpeech double (LD), Switchboard mild (SM) 和Switchboard strong (SS)。
时域调整
随机选取时间上的一个点并在该点左右进行调整,调整的范围w来自于一个参数是从0到参数W均匀分布。
频率覆盖
对 [f0, f0 + f)范围内的频谱进行掩码覆盖,f的选取来自于从0到参数F的均匀分布,f0选自(0, ν − f)范围内,其中ν是频谱通道的总数。
时域覆盖
对[t0, t0 + t)上连续时间的频谱进行覆盖,t来自于参数0到T之间的均匀分布,t0是在[0, τ − t)之间。

上图展示了对数梅尔频谱图的多种调整,从上到下分别是不做增强的原始图,时域调整,频谱覆盖以及时域覆盖。(Park et al., 2019)
多种基础策略的组合
通过对时域和频谱覆盖的组合,可以生成四种新的增强策略,它们的符号表示如下:
W:时域调整参数
F:频域覆盖参数
mF:频域覆盖的个数
T:时域覆盖参数
mT:时域覆盖的个数
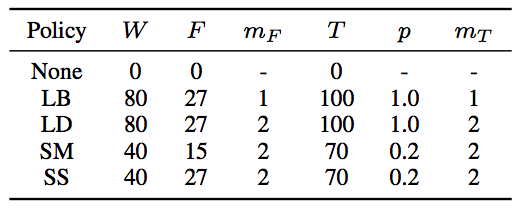
LB, LD, SM 和 SS的参数(Park et al., 2019)
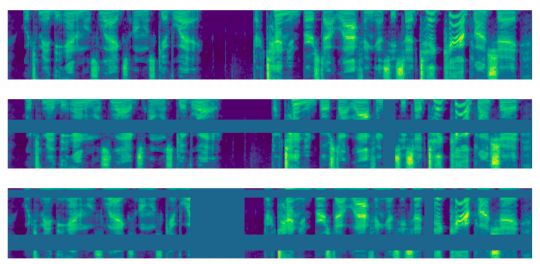
从上到下分别展示了原始的以及应用了LB和LD的对数梅尔频谱图. (Park et al., 2019)
网络结构
LAS(Listen, Attend and Spell)网络结构
Park等人使用LAS结构来验证数据增强的效果,该结构包含两层卷积神经网络(CNN),一个注意力层(Attention)以及一个双向的长短期依赖(LSTMs)。 因为本文主要关注数据增强,模型只是验证增强效果的方法,如果你想深入的了解LAS,可以点击原文查看。
学习率的策略
学习率的设置对训练模型的性能有重要的影响,与Slanted triangular learning rates (STLR)相似,我们采用了一个动态的学习率,它会指数级的衰减,一直下降到所设置最大值的1/100时停止,其后会一直保持在该值。它的主要参数如下:
sr:从 0 学习率开始的起步爬坡阶段完成经过的步骤数量
si:指数衰减的起始值
sf:指数衰减的结束值
另一个学习率的策略是统一标签平滑。我们将正确分类的标签置信度设为0.9,其他标签的置信度依次增加。主要参数为:
snoise:变化的权重噪音
在接下来的试验中,我们定义了如下三种学习率:
B(asic): (sr, snoise, si, sf ) = (0.5k, 10k, 20k, 80k)
D(ouble): (sr, snoise, si, sf ) = (1k, 20k, 40k, 160k)
L(ong): (sr, snoise, si, sf ) = (1k, 20k, 140k, 320k)
语言模型(Langauge Models,LM)
语言模型的作用是进一步提升模型效果,通常来说,语言模型是在已有的字符上去预测下一个字符,新的字符被预测出来后,又会迭代的用它去预测后面一个。这种方法在诸如BERT或者GPT-2等很多现代的NLP模型中都有使用。
实验
我们用词错误率( Word Error Rate,WER)来评价模型的效果。
在下图中,“Sch”表示学习率的选取,“Pol”表示增强策略。可以看到,有6层LSTM和1280个词嵌入向量的LAS模型取得了最好的效果。
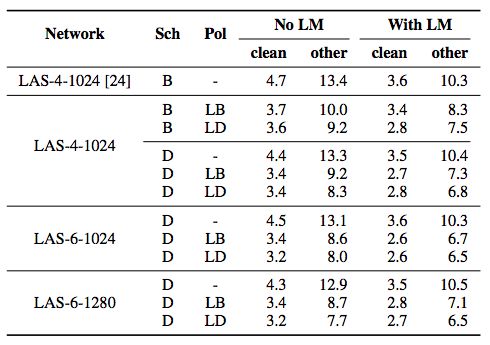
LibriSpeech数据集的评估结果(Park et al., 2019)
下图所示,在诸多模型以及没有数据增强的LAS模型对比中,上文提到的“LAS-6–1280”性能最好。
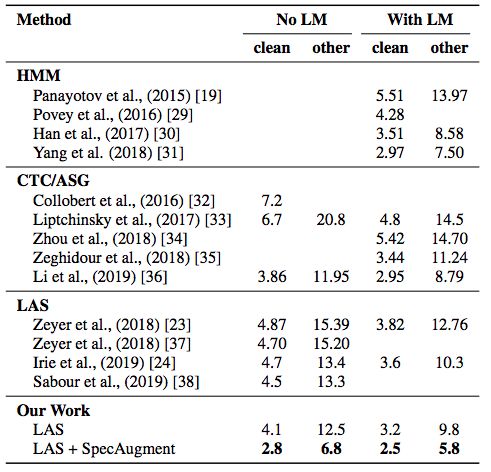
在960小时的LibriSpeech数据集上对比频谱增强的效果(Park et al., 2019)
在300小时的Switchboard数据集上,选取四层LSTM的LAS模型作为基准,可以看到频谱增强对模型效果有明显的提升。
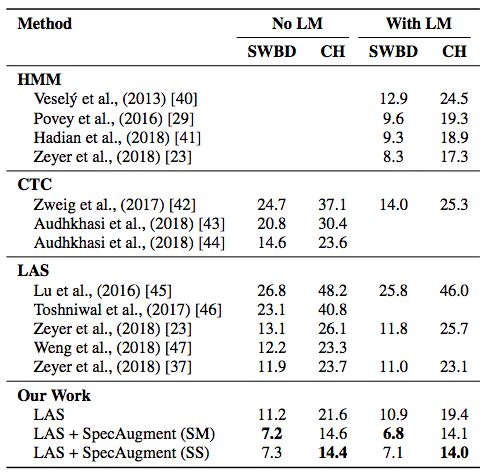
在300小时的Switchboard数据集上对比增强的效果(Park et al., 2019)
要点
时域调整并不能很明显的提升模型性能,如果资源有限,可以无视这种方法。
标签平滑的方法在训练中很难稳定的收敛。
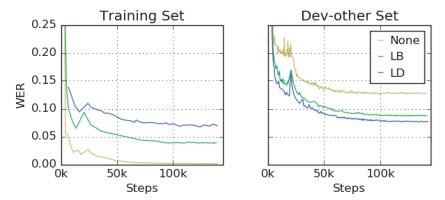
数据增强的方法把过拟合的问题变成了欠拟合,在下图中,可以看到没有数据增强的模型在训练集上有近乎完美的效果,但是在其他测试集上的结果却没有那么好。
为了在语音识别中更方便的应用数据增强,nlpaug已经支持频谱增强的方法了。
关于作者
他是一个湾区的数据科学家,专注于领先的数据科学技术,人工智能,尤其是自然语言处理及平台相关的方向,通过以下方法可以联系上他:LinkedIn,Medium 以及 Github。
扩展阅读
Official release of SpecAugment from Google
Slanted triangular learning rates (STLR)
Bidirectional Encoder Representations from Transformers
Generative Pre-Training 2
参考文献
D. S. Park, W. Chan, Y. Zhang, C. C. Chiu, B. Zoph, E. D. Cubuk and Q. V. Le. SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition. 2019
W. Chan, N. Jaitly, Q. V. Le and O. Vinyals. Listen, Attend and Spell. 2015
想要继续查看该篇文章相关链接和参考文献?
点击底部【阅读原文】即可访问:
https://ai.yanxishe.com/page/TextTranslation/1705
滑动查看更多内容


<< 滑动查看更多栏目 >>




