携程金融自动化迭代反欺诈模型体系


文章作者:携程技术团队
编辑整理:Hoh
内容来源:《携程人工智能实践》
导读:支付欺诈风险是携程金融风控团队的主要防控对象,它一般是指用户卡片信息或账号信息泄露后,欺诈分子利用这些信息在携程平台进行销赃,侵害用户资金安全,给用户和携程平台带来损失。携程金融风控团队需要在不影响正常用户自由出行的前提下,对这样的风险交易进行精准识别并实时拦截,从而保护用户资金安全。支付欺诈风险具备以下3点特性。
1. 高对抗性
欺诈分子的作案手段绝非一成不变,他们也会根据我们的策略拦截结果对作案方式不断调整,不断形成风险转移,如果我们的策略模型不及时追踪这种变化,则无法做到"见招拆招"。
2. 复杂性
为了躲避风险控制的策略规则,欺诈分子也会尽力模仿正常用户的消费行为,而且从目前的数据来看,支付欺诈场景的批量操作行为比业务作弊场景少很多,原因是在携程平台上,欺诈分子相当于一个承接正常用户需求的代订中介,在没有需求的情况下,他们没有必要通过走量的形式进行销赃。这样的业务特性导致支付欺诈多为无规律性的单点攻击,普通规则在模拟这种复杂逻辑场景的时候会存在一定劣势,通常要么精度不够,造成误拦截过多,要么无法捕捉作案手法。与普通规则不同的是,模型可以在多变量前提下进行数据拟合,从而捕捉复杂作案手法。
3. 坏样本稀少
在支付反欺诈场景中,坏样本的主要来源有两部分:在风控运营过程中,人工拦截或规则、模型自动拦截的风险订单;风控策略无法识别并最终产生损失的风险订单。在风险订单中,风控策略能够拦截的占绝大部分,而我们需要注意的恰恰是无法识别的那部分,但这部分案件样本相当稀少,这给规则和模型的学习带来不小的挑战。
携程金融风控团队为了应对支付欺诈风险的特性,使用了一套自动化迭代反欺诈模型体系,以加快模型迭代速度,学习最新作案手法,在整个过程中尽量减少工程师的人力投入成本,并且用生成式对抗网络辅助,增加稀少案件样本的数量,使模型的学习更加充分,最终达到"见招拆招"的目的。
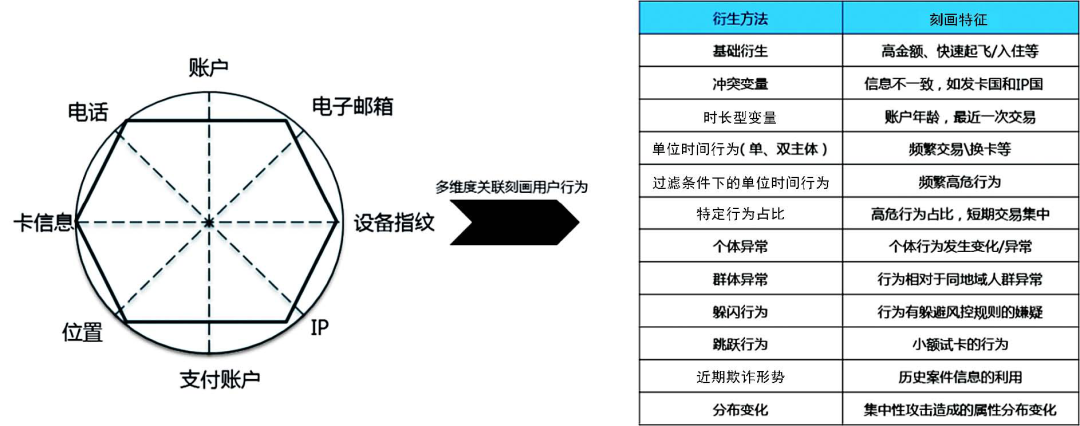
数据决定模型的上限。图1是风控变量体系。该体系主要基于携程平台的账户、支付、出行、金融及 IP Location 等数据构建。我们的风控变量体系主要从衍生方法的多样性、业务含义的完备性两个角度去考虑。
上文介绍了我们的风控变量体系,下面介绍自动化迭代反欺诈模型框架,如图2所示。
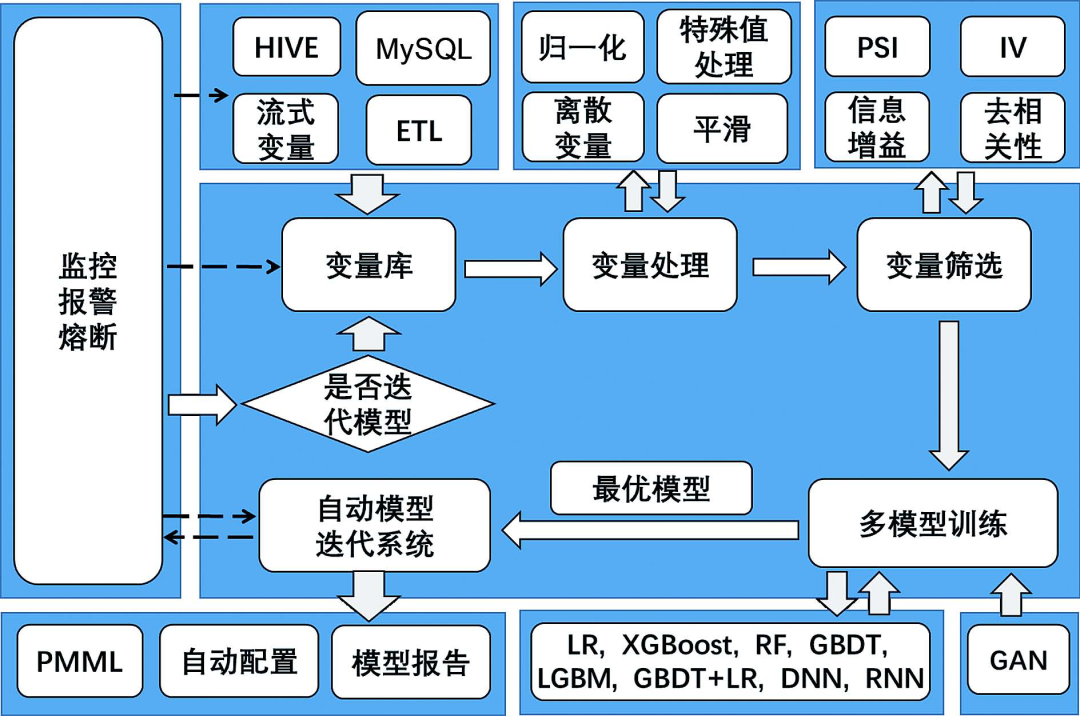
1. 迭代触发
迭代触发的条件可以自行设定,该模型可以按照时间周期迭代,也可以在实际业务效果下降后触发迭代。
2. 变量库
我们的变量库由线上实时计算的变量和离线 T+1 清洗的变量组成,当新的模型触发迭代时,近期的样本会构成候选变量池。
3. 变量处理和变量筛选
我们对候选变量先进行一轮特征工程。这主要包含两个步骤。
变量检查。我们将包括变量自身分布的稳定性指标 ( PSI ) 在内的有问题的变量剔除。
缺失值/特殊值填充。因为我们的流程中会用到 DNN 深度学习的方法,而此类方法对缺失值较为敏感,所以我们需要将这部分特殊情况用正常的取值情况去替代。我们目前使用的替代方法是找到与特殊值黑样本率最接近的正常值区间,用区间中的值进行特殊值替代。如果变量是离散型变量,那么我们需要将其转成 one-hot 形式。
4. 算法衍生变量
利用上一步的结果,通过深度学习的方法进行表征学习,目的是在基于业务衍生的变量之外,通过算法自动生成一些变量。由于目前对深度学习的弱解释性没有较好的解决方案,所以,为了保证主模型的可控性,我们建议限制深度学习模型的网络结构复杂性,同时控制最终入选模型的变量个数。我们以业务衍生变量为主,以算法衍生变量为辅。
5. GANs
我们利用 GANs 模型,通过对真实欺诈样本集数据分布的学习,自动合成符合该分布的欺诈样本,将人造欺诈样本纳入样本库,改善欺诈案件稀少的情况,增强模型对欺诈样本的学习。
6. 主模型
原则上主模型的类型没有限制,只要能实现分类器的功能都可以。为了提高自动化迭代效率,我们推荐使用随机森林、GBM、GBDT、XGBoost 或 LGBM 等基于决策树的模型作为主模型,原因如下。
此类模型能实现在每次拆分时自行从候选变量池中挑选变量的功能,可以节省根据变量重要性手动挑选入模变量的时间。
此类模型可以捕捉变量与目标之间的非线性关系,并且自动交互组合变量,减少特征工程时间。
此类模型在每次拆分时,能够有效利用变量的碎片化信息。
7. 部署
框架输出:输出 PMML 格式模型打分文件、特征工程过程代码、算法衍生变量生成方法。其中,特征工程过程代码可以认为是原始变量到入模变量之间的映射方法。
变量配置:如果模型有新变量 ( 原本生产环境未配置,只能离线清洗计算 ) 入选,则需要将这部分变量配置至生产环境。
8. 确定阈值
在传统情况下,我们一般通过跨期测试集的效果来确定模型的阈值,由于支付欺诈场景的高对抗性,我们建议将近期样本放入模型中进行训练,这样可以压缩跨期测试集的空间,甚至使模型没有跨期测试集。针对这种情况,我们采用的方案是,先将模型部署上线但不使其生效,短期观察一段时间后,根据生产环境的真实表现确定阈值,参考的依据主要有阈值以上的交易占比及相应的准确率。
与传统建模流程相比,自动化迭代模型框架在追求快捷高效的同时有两个问题。
自动化迭代模型框架缺少了对所有入模变量人工审核的过程,减少了我们对入模变量的了解,降低了模型的可控性。
由于支付欺诈场景的高对抗性,所以我们建议使近期样本进入训练集,让模型学习近期的风险特征,这样会造成每次迭代几乎没有用来检验模型是否会出现过拟合的跨期测试集。
针对这些问题,为了最终实现自动化迭代模型体系对支付欺诈风险的高对抗性、复杂性的克服,达到模型效果与模型可控性的平衡,我们需要一套完备的监控体系为模型保驾护航。
9. 监控体系
变量监控:对生产环境中的变量监控 PSI、特殊值 ( 包括缺失率 ) 占比变化。
模型监控:通过模型打分进行 PSI 监控。
业务效果监控:针对支付反欺诈场景,我们主要监控模型线上交易的真实拦截率与预估拦截率是否有差异,以及通过事后的人工定性监控模型拦截的准确率是否符合预期。
在运营维护自动化迭代模型框架的过程中,我们认为除了新变量配置流程目前需要人工介入,对业务的深入了解和对支付欺诈案件的人工分析也是不能节省人工投入的,毕竟任何模型算法只是工具,一个好的业务沉淀转化的变量给模型的效果带来的提升,要远远大于算法优化带来的提升。
在支付反欺诈场景中,传统方法衍生的特征一般刻画用户在某个时间窗口内进行了几笔交易、换了几张信用卡、累计消费了多少金额等,也就是量化用户在这段时间内干了什么,但是这种衍生方法在用户时序行为信息表达上有不足之处,它没有刻画用户先干了什么后干了什么。我们可以利用 RNN 捕捉时序行为的特性,在主模型进行训练前,先基于用户 UBT 行为数据训练一个 RNN 子模型,将这个模型的隐藏层输出作为主模型的输入变量,如图3所示。
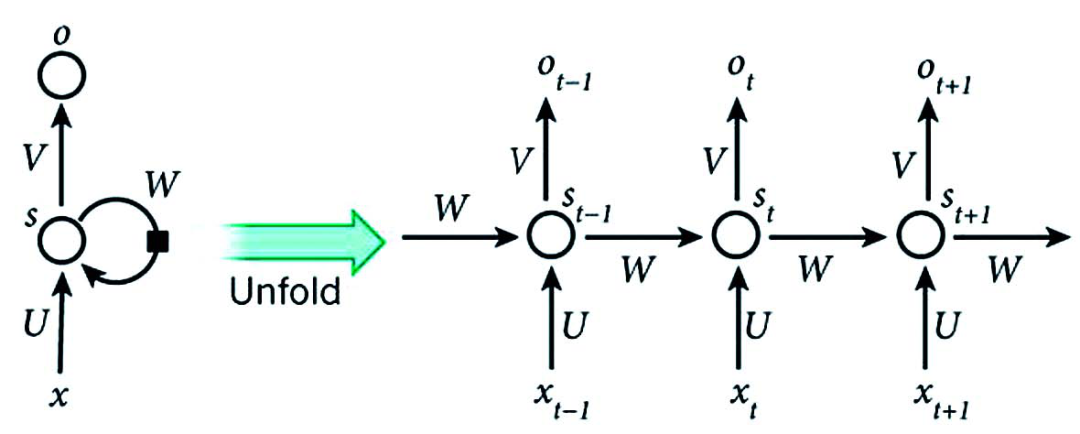
UBT 数据主要分为 action、pageview 数据,action 是指用户在浏览时进行的细节操作,如筛选、排序、填写等,pageview 数据是用户在浏览的页面的 ID,每个页面都有对应的 ID,同样是酒店详情页,如果酒店不相同,则页面的 ID 也不一样。我们以 pageview 数据的应用为例,介绍利用 UBT 数据建模的主要步骤。
1. 业务转化
如果直接将 pageview 数据作为模型的输入,那么会出现两个问题。
用户的相同的浏览动作,如浏览页面详情,会因页面来自不同的酒店或航司而产生不同输入,即输入不稳定。
页面的 ID 在作为输入时,从业务角度理解起来过于枯燥,不够生动。
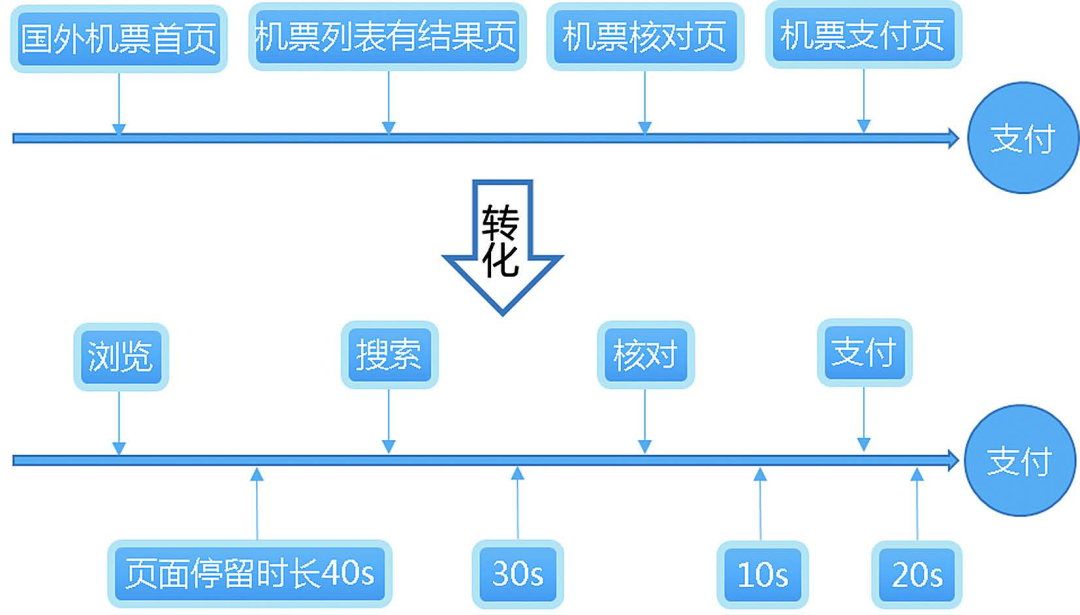
针对以上问题,我们花了大量时间对 UBT 数据进行了人工汇总,以业务理解为核心,有选择地将原本枯燥无味的页面转化为用户的行为动作,并将用户在页面的停留按照停留时长的分组转化为几种输入动作。业务转化示例如图4所示。
2. 动作字典
我们将希望能采集到的用户浏览动作汇编成一个输入字典,如表1所示。
3. one-hot
用传统的 one-hot 的方式将这些动作逐一量化为向量,使其生成矩阵,并将矩阵输入模型。
最后,在训练完模型后,提取模型隐藏层的输出,将它们作为特征输入主模型。由于这部分特征表达的是用户的时序行为信息,其数据来源和表达信息的维度都与以往传统的衍生变量有所不同,所以我们在实践中发现,这部分特征与传统衍生特征之间的冗余性非常低,对主模型来说是一个非常好的信息补充。
1. 传统方法
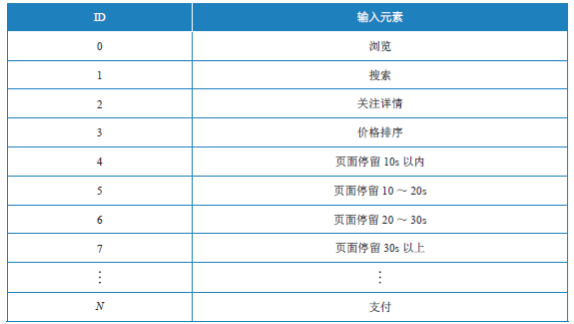
在传统情况下,我们构建一个模型的时间成本要高于构建规则的时间成本,因此以往当我们上线一个模型时,稳定性是我们参考的重要指标。我们希望上线一个模型后,模型能正常表现几个月甚至半年。然而,以风控支付反欺诈模型──天眼模型为例,在天眼一期的时候,我们构建了一个模型,在 OOT1 ( 第一个跨期测试数据集 ) 中,当准确率为80%时,模型的召回率为12%以上;仅仅过了一个月,在 OOT2 ( 第二个跨期测试数据集 ) 中,同样当准确率为80%时,模型的召回率衰减到7.9%左右,如图5所示。
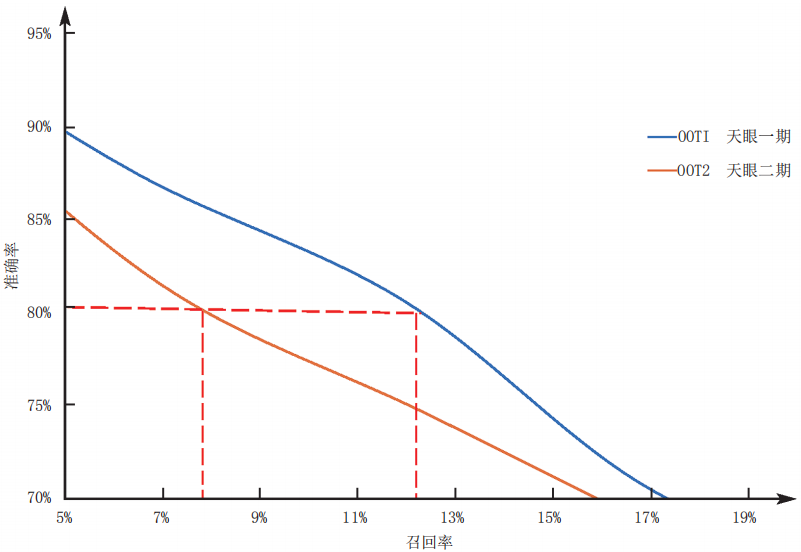
由于模型的衰减发生在两个跨期测试集之间,而不是发生在训练集与测试集之间的,所以我们排除了模型本身的过拟合造成的效果衰退。分析后发现,造成模型覆盖率降低的原因是支付欺诈场景的高对抗性,欺诈分子在不断变换他们的欺诈手法,因此历史数据训练的模型无法覆盖最新的手法。
2. 自动化迭代 vs 传统方法
在天眼二期的时候,我们采用了自动化迭代的流程框架,在降低建模成本的同时使模型与欺诈形势保持同步。如图6所示:
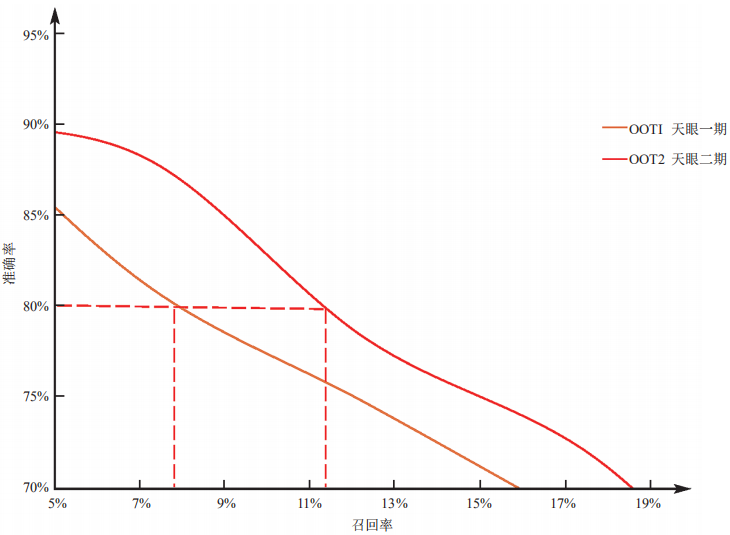
在天眼一期效果已经下降的 OOT2 中,天眼二期的召回率能在准确率为80%的情况下重新回到11.5%左右。
如果您喜欢本文,欢迎点击右上角,把文章分享到朋友圈~~

新书推荐:



关于我们:

🤔你今天写BUG了么?👇
相关内容

目前业务主要为:机票(国内/国际)、酒店(国内/海外/惠选/团购)、度假(旅游/票务/租车/邮轮)、商旅(企业商旅)、铁友网(动车/高铁)、订餐小秘书(订餐/婚宴)、社区(驴评网)、松果网、古镇网、途家网、鸿鹄顶级旅游、携程自由行杂志


