作者:牛力(上海交通大学仿脑计算与机器智能研究中心)
少样本图像生成是很有挑战性的任务,可用的方法也很少。近日,上海交大和 Versa-AI 的研究人员合作发表论文,提出了先融合后填充(fusing-and-filling)的思想,以便更合理地融合条件图片并完善生成图片的细节信息。目前,这篇论文已被 ACM MM2020 会议接收。
少样本图像生成(few-shot image generation)任务是指用已知类别(seen category)的大量图片训练出一个生成模型,然后给定某个未知类别(unseen category)的少量图片,即可为该未知类别生成大量真实且多样的图片。少样本图像生成属于图像数据增广的范畴,可用来辅助很多下游任务,如少样本图像分类等。
在少样本任务系列中,相比少样本分类(few-shot classification)、少样本物体检测(few-shot object detection)、少样本语义分割(few-shot semantic segmentation)等任务,少样本图像生成任务受到的关注较少,可做的空间较大。
虽然在少样本分类方法中,有一类方法是用数据增广的方式提升分类性能,但大多数方法都是做少样本特征生成(few-shot feature generation),即生成图像特征,或者少样本伪图像生成,即生成一些看起来不真实但仍然可以提升分类性能的图像。
而本文关注的少样本图像生成任务和上述任务不同,它致力于生成真实且多样的图片。因此,
少样本图像生成任务比少样本特征生成和少样本伪图像生成更具有挑战性
。
现有的少样本图像生成方法很少,可以大致归纳为三类:
基于优化的方法(optimization-based):这类方法和少样本分类中基于优化的方法类似,只不过它把同样的策略从分类模型转移到了生成模型。比如,FIGR [1] 把 Reptile 应用到生成模型,DAWSON [2] 把 MAML 应用到生成模型。
基于变换的方法(transformation-based):输入单张图片,对这张图片进行变换,得到另一张属于同一类别的图片。比如 DAGAN [3] 输入单张图片和一个随机向量,对输入图片进行微调得到新的同类图片。
基于融合的方法(fusion-based):输入多张图片,对这些图片进行信息融合,得到新的属于同一类别的图片,该图片包含输入的多张图片的信息。比如 GMN [4] 把 VAE 和 Matching Network 相结合。我们实验室之前的一项工作 MatchingGAN [5] 把 GAN 和 Matching Network 相结合,另外一项工作 F2GAN [6] 提出了融合填充的思想。
我们整理了少样本图像生成方法的论文和代码,参见:https://github.com/bcmi/Awesome-Few-Shot-Image-Generation。
本文重点介绍我们实验室被 ACM MM2020 接收的论文《F2GAN: Fusing-and-Filling GAN for Few-shot Image Generation》,代码将在整理后公布。
![]()
论文链接:https://arxiv.org/abs/2008.01999
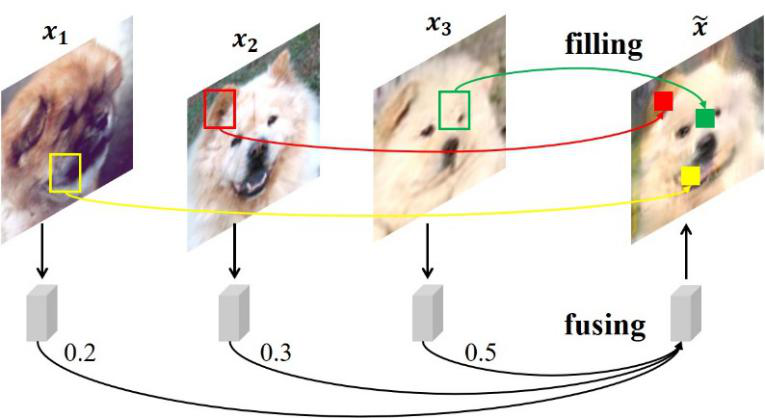
把三张属于同一类别的图片 x1, x2, x3,也叫做条件图片(conditional image),按照一定比例(比如 [0.2, 0.3, 0.5])进行融合,得到一张新的图片(比如 0.2 x1+0.3 x2+0.5 x3)。
一般做法是在潜在空间(latent space)做线性插值(linear interpolation),但
本文提出了先融合后填充(fusing-and-filling)的思想
,以便更合理地融合条件图片并完善生成图片的细节信息。因此该方法叫做 Fusing-and-filling GAN (F2GAN)。
![]()
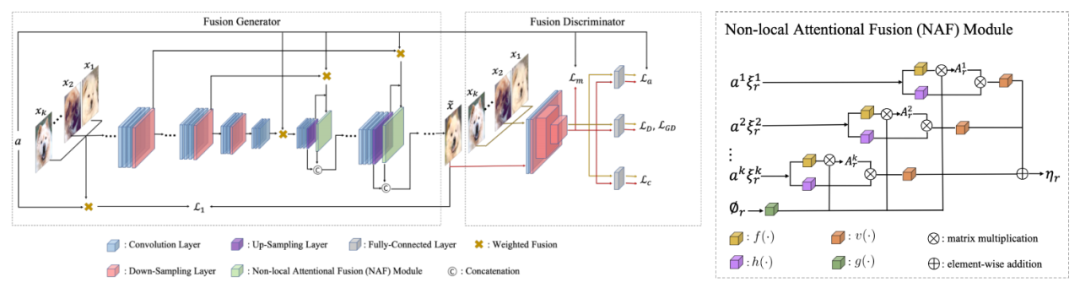
F2GAN 方法的具体网络结构参见下图左:对条件图片基于编码器得到的深层特征做线性插值,也就是融合(fusing);然后在解码器生成过程中,利用基于全局注意力机制的融合模块(non-local attentional fusion module, 具体结构参见下图右),对于解码器每层输出特征图的每一个空间位置,从所有条件图片的所有空间位置借取相关信息,再和解码器输出的特征图融合,得到新的特征图,并送入解码器的下一层,相当于在上采样过程中利用条件图片的相关浅层特征填充(filling)图像细节。
![]()
根据这种先填充后融合(fusing-and-filling)的思想,得到的图片按照一定比例融合了条件图片的深层语义信息,并且从条件图片获取相关的浅层特征来完善图片细节信息。具体的网络结构和技术细节参见原论文。
研究者在五个数据集(Omniglot、EMNIST、VGGFace、Flowers、Animals Faces)上做实验,包括字符数据集和真实图片数据集,并和之前的少样本图像生成方法做比较。
下图汇总了 F2GAN 方法和之前方法在五个数据集上的生成结果。左边三列是作为输入的三张条件图片,右边是各个方法基于三张条件图片的生成结果。从下图中可以观察得到,不管是字符数据集还是真实图片数据集,基于三张条件图片,F2GAN 方法都能生成合理且多样的同类别图片。
![]()
这是因为该研究按照一定比例融合了多张条件图片。为了验证按比例融合的平滑性,研究者基于两张条件图片,用渐变的融合比例,得到基于 x1 和 x2 按不同比例融合的结果,如下图所示。上面一行是 MatchingGAN 的对比结果,下面一行是 F2GAN 方法的结果,从中可以看出基于 F2GAN 方法生成的图片过渡更加平滑自然。
![]()
该研究还对基于全局注意力机制的融合模块(non-local attentional fusion module)进行可视化分析,如下图所示:
![]()
左边一列图片是基于右边三列条件图片生成的结果。这项研究针对生成图片的某一空间位置(比如红色小方块),获取它从条件图片借取信息的空间位置(比如红色箭头覆盖的高亮区域)。用下面一行的图片举例,狗的额头是从 x1 借信息,脸颊是从 x2 借信息,舌头是从 x3 借信息,融合得到左边第一列的图片。
这篇论文还讨论了少样本图像生成和少样本图像翻译(few-shot image translation)的区别和联系。
少样本图像翻译对图片进行跨类别迁移,借助已知类别的大量图片,给定某个未知类别的少量图片,即可把已知类别的大量图片迁移到该未知类别。但是这种做法在测试生成阶段需要借助大量已知类别图片,做法不是很简洁,并且生成图片在类别相关特征的多样性方面不足。而且,如果解耦效果不够理想,生成图片可能会带有已知类别的类别相关特征。
相比较而言,少样本图像生成在测试生成阶段不需要借助已知类别图片。另外,生成图片在类别相关特征的多样性方面较好,且不会引入其他类别的类别相关信息。
少样本图像生成是非常有挑战性的任务,但受到的关注不是很多。目前,基于优化的方法在真实图片上生成的效果欠佳,尚未发挥出其优势。基于变换的方法生成的图片多样性不足,但是提升空间很大。基于融合的方法生成的图片通常和某一张条件图片比较接近,缺乏几何形变。
近年来,少样本生成方法在简单的真实数据库(Flowers、Animals Faces、NABirds)上已经取得了很大的进展,但是在复杂的真实数据库(如 MiniImageNet)上依然无法生成真实的图片。欢迎大家关注少样本生成任务。
[1] Louis Clouatre and Marc Demers. 2019. FIGR: Few-shot image generation with reptile. arXiv preprint arXiv:1901.02199 (2019).
[2] Weixin Liang, Zixuan Liu, and Can Liu. 2020. DAWSON: A domain adaptive few shot generation framework. arXiv preprint arXiv:2001.00576 (2020).
[3] Antreas Antoniou, Amos Storkey, and Harrison Edwards. 2017. Data augmentation generative adversarial networks. arXiv preprint arXiv:1711.04340 (2017).
[4] Sergey Bartunov and Dmitry Vetrov. 2018. Few-shot generative modelling with generative matching networks. In AISTATS.
[5] Yan Hong, Li Niu, Jianfu Zhang, and Liqing Zhang. 2020. MatchingGAN: Matching-based few-shot image generation. In ICME.
[6] Yan Hong, Li Niu, Jianfu Zhang, Weijie Zhao, Chen Fu, Liqing Zhang. 2020. F2GAN: Fusing-and-Filling GAN for Few-shot Image Generation. In ACM MM.
数据工程师专属福利!
1000
元
服务抵扣券免费领取,直充到 AWS 账户用以抵扣服务消费,轻松体验6大应用场景。
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com