机器之心ACL 2022论文分享会干货集锦,6月邀你来CVPR分享会





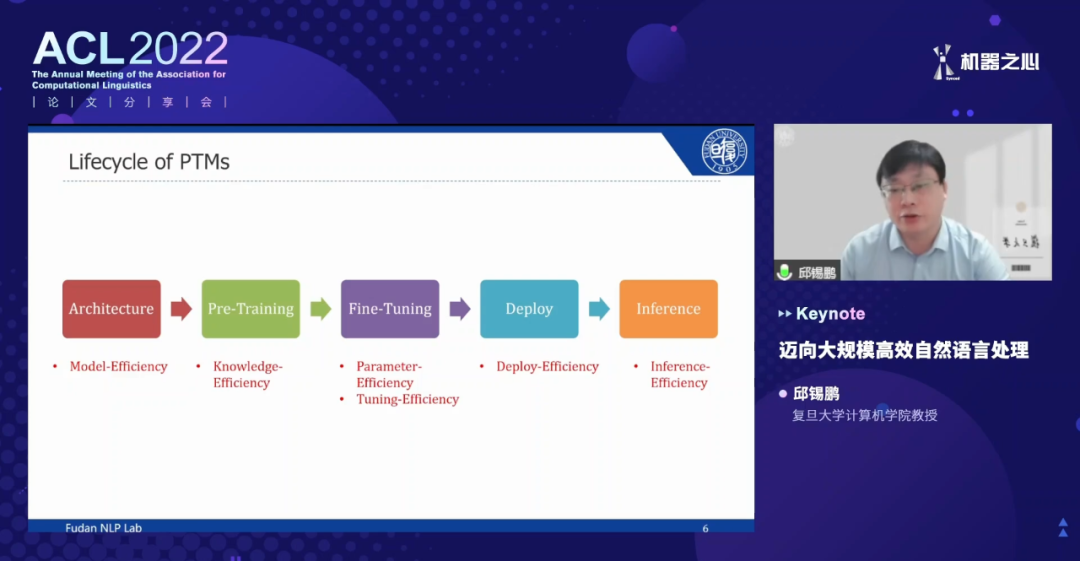

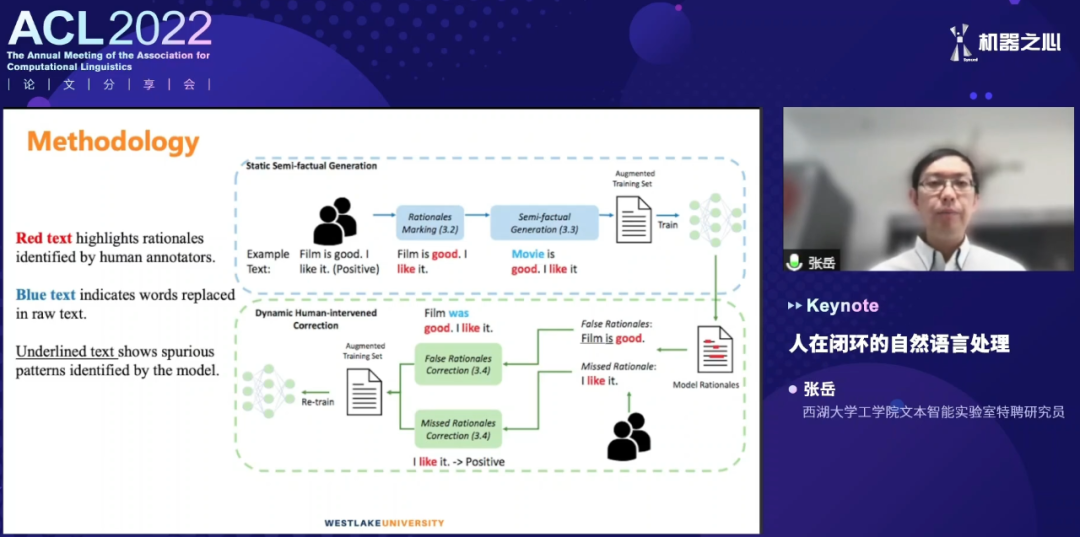
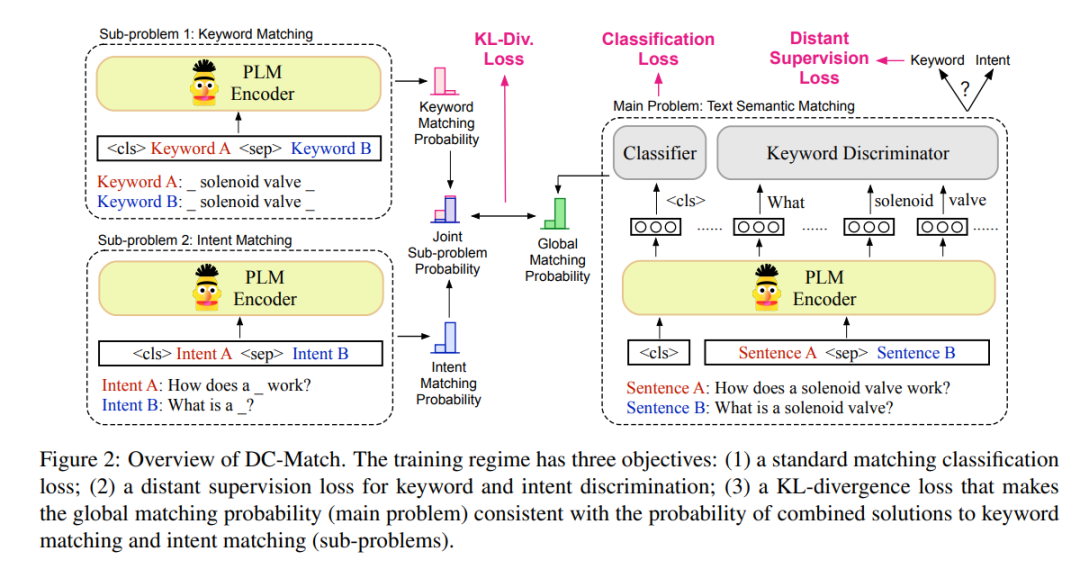
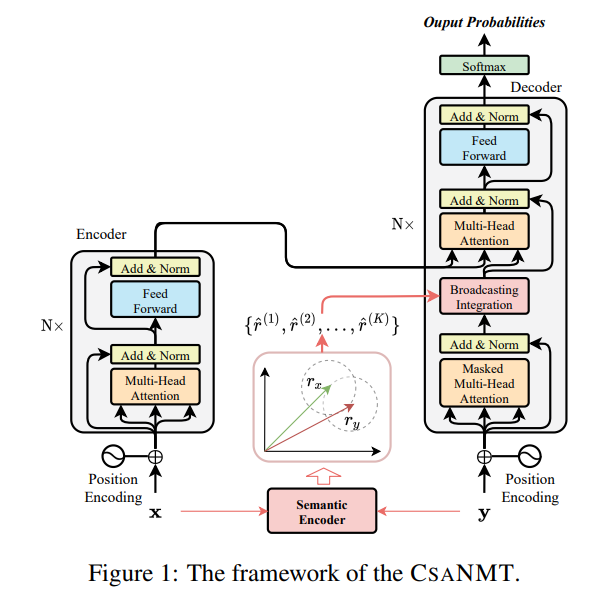
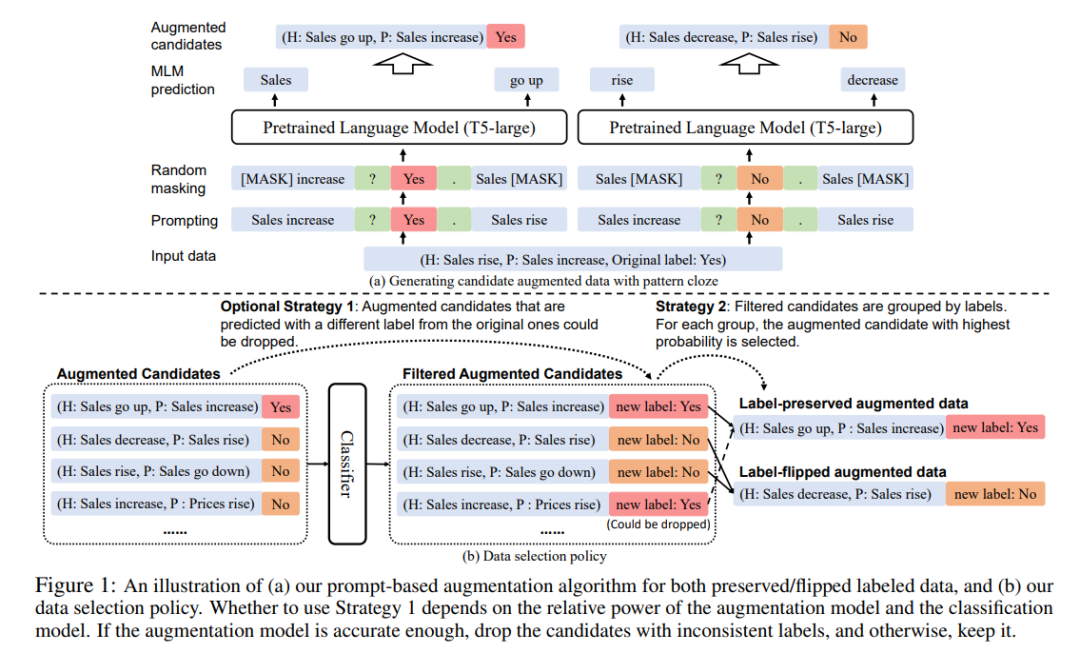

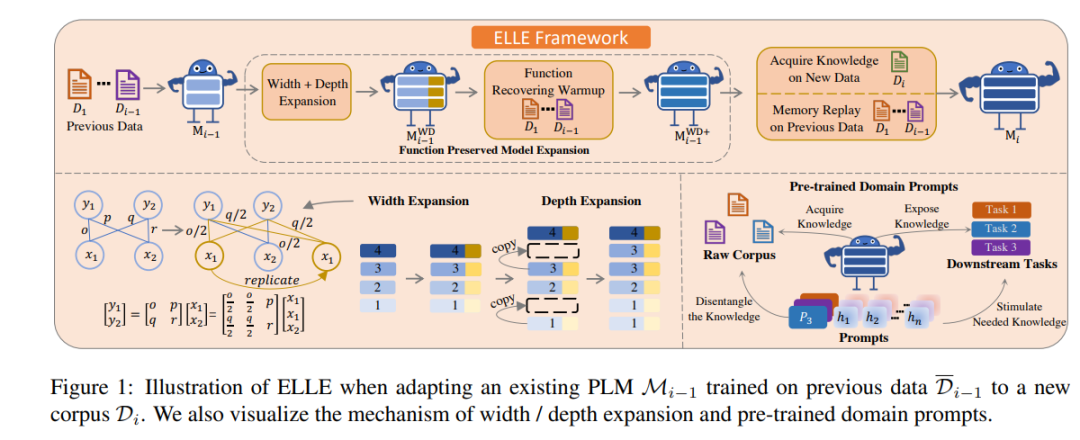
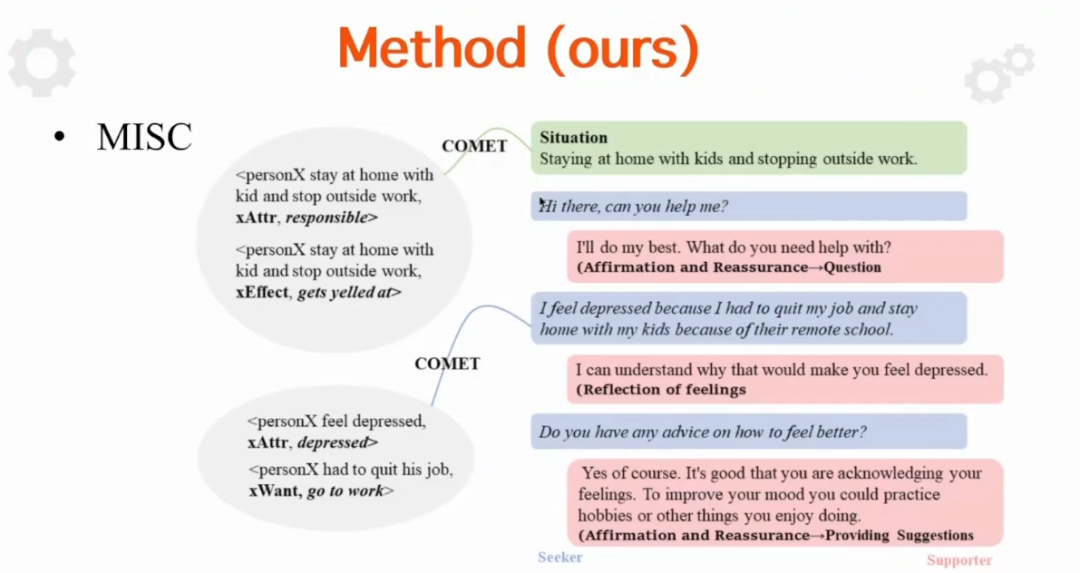
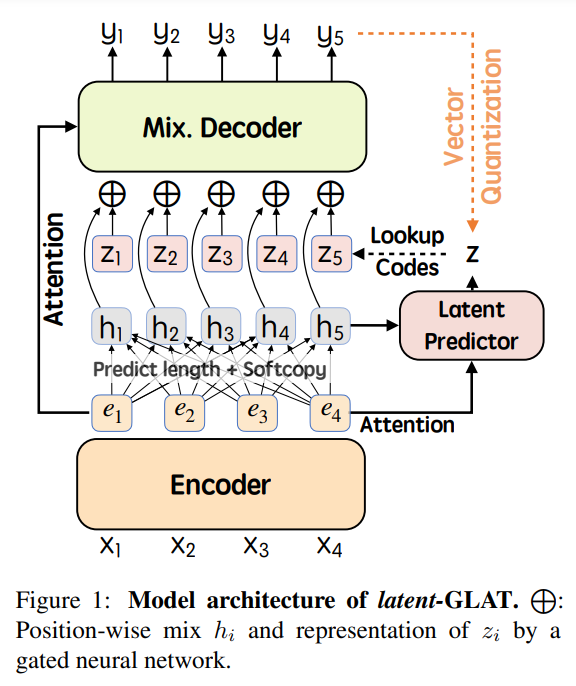
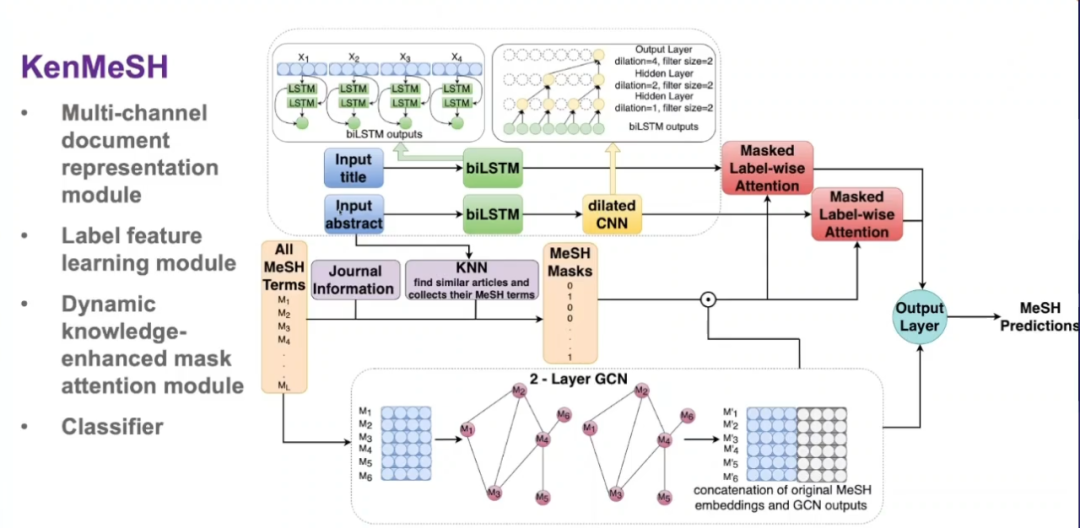
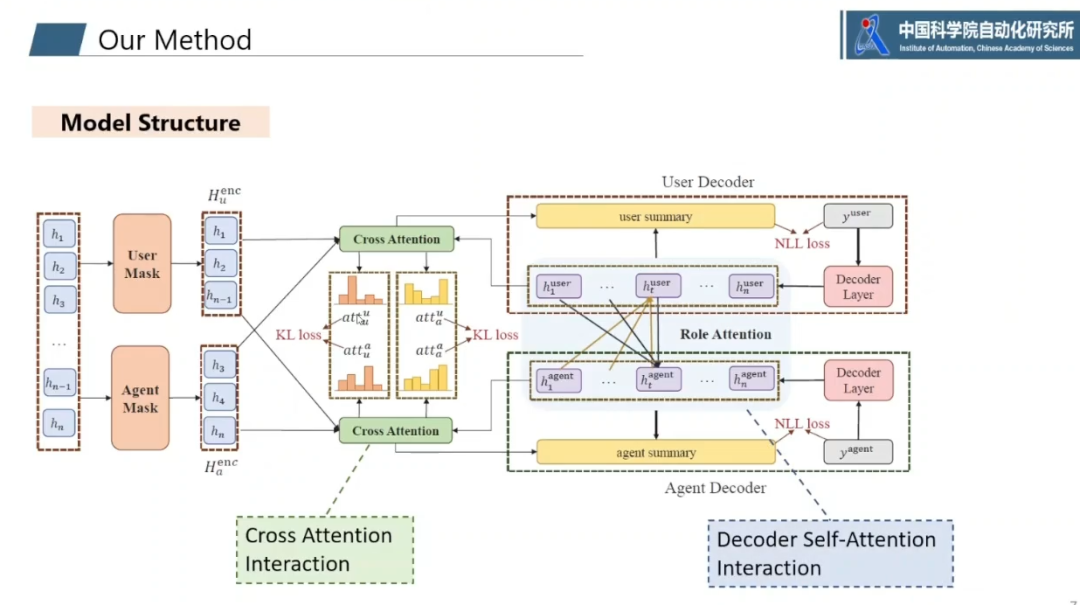


登录查看更多
相关内容
专知会员服务
43+阅读 · 2019年11月12日
专知会员服务
33+阅读 · 2019年10月23日
Arxiv
0+阅读 · 2022年7月26日




相关VIP内容
专知会员服务
43+阅读 · 2019年11月12日
专知会员服务
33+阅读 · 2019年10月23日
相关资讯
相关论文
Arxiv
0+阅读 · 2022年7月26日