
报告主题: 生成对抗网络
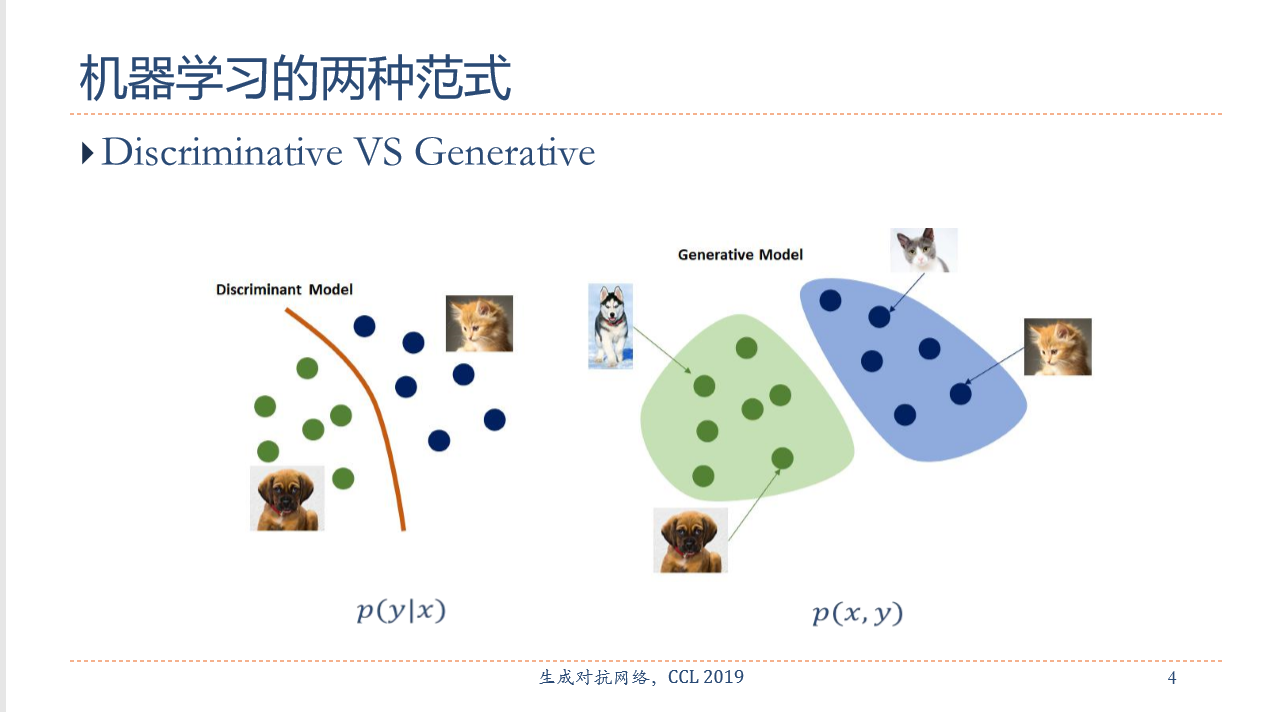
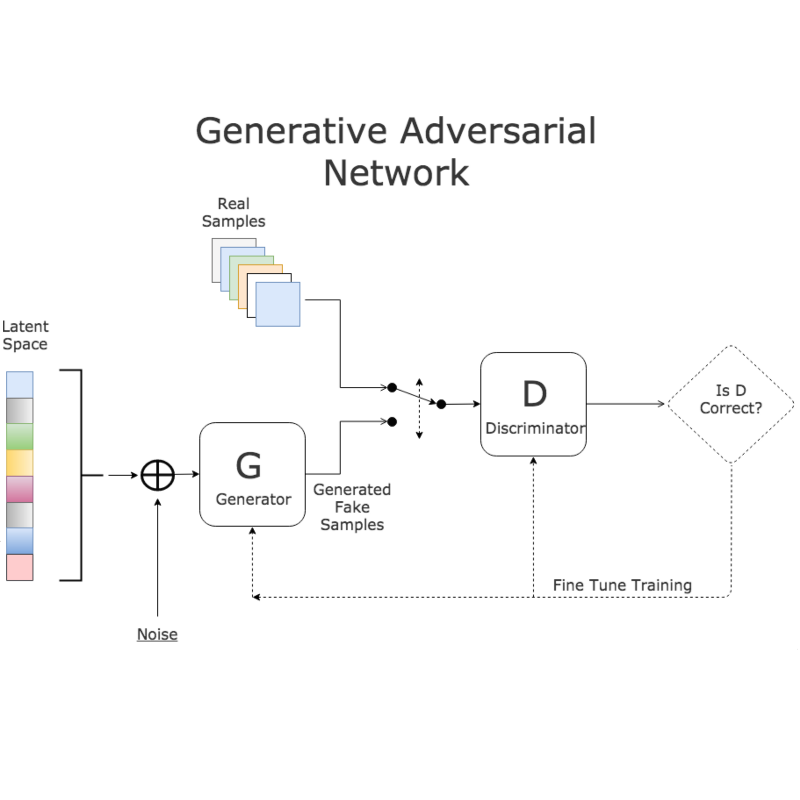
报告摘要: 生成对抗网络(Generative Adversarial Network,GAN)是非监督式学习的一种生成模型,其由一个生成网络与一个判别网络组成,通过让两个神经网络相互博弈的方式进行学习。生成网络从潜在空间(latent space)中随机取样 作为输入,其输出结果需要尽量模仿训练集中的真实样本。判别网络的输入则为真实样本或生成网络的输出,其目的是将生成网络的输出从真实样本中尽可能分辨出来。而生成网络则要尽可能地欺骗判别网络。两个网络相互对抗、不断调整参数,最终目的 是使判别网络无法判断生成网络的输出结果是否真实。虽然生成对抗网络原先是为了无监督学习提出的,它也被证明对半监督学习、监督学习、强化学习同样有用。本报告主要讲述生成对抗网络的基本原理和最新研究进展。
邀请嘉宾: 复旦大学计算机科学技术学院副教授,博士生导师。于复旦大学获得理学学士和博士学位。主要从事自然语言处理、深度学习等方向的研究,在ACL、EMNLP、AAAI、IJCAI等计算机学会A/B类期刊、会议上发表50余篇学术论文,引用 1900余次。开源中文自然语言处理工具FudanNLP作者,FastNLP项目负责人。2015年入选首届中国科协人才托举工程,2017年ACL杰出论文奖,2018年获中国中文信息学会“钱伟长中文信息处理科学技术奖—汉王青年创新奖”。
成为VIP会员查看完整内容


相关内容
专知会员服务
43+阅读 · 2019年11月12日
专知会员服务
48+阅读 · 2019年10月21日
专知会员服务
84+阅读 · 2019年10月18日
Arxiv
6+阅读 · 2019年7月17日
Arxiv
5+阅读 · 2018年4月3日
Arxiv
3+阅读 · 2017年8月2日




相关VIP内容
专知会员服务
43+阅读 · 2019年11月12日
专知会员服务
48+阅读 · 2019年10月21日
专知会员服务
84+阅读 · 2019年10月18日
相关资讯
相关论文
Arxiv
6+阅读 · 2019年7月17日
Arxiv
5+阅读 · 2018年4月3日
Arxiv
3+阅读 · 2017年8月2日