基于NAS的GCN网络设计
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

作者:iker peng
https://zhuanlan.zhihu.com/p/97232665
本文已由作者授权,未经允许,不得二次转载
介绍下我们 AAAI2020的工作:Learning Graph Convolutional Network for Skeleton-based Human Action Recognition by Neural Searching

作者团队:奥卢大学&西安交通大学
链接:https://arxiv.org/abs/1911.04131
动作识别(Action recognition) 是计算机视觉领域中一个非常热门的研究话题。它具有很多有价值的应用,例如 安全监控,行为分析, 以及人机交互等等。但是,这个研究课题同时也是一个很有挑战的问题,尤其是对于背景极其复杂,或是存在遮挡的情况。Skeleton 数据的出现,很大程度上解决了这一类的问题。Skeleton数据当中包含和运动直接相关的信息,对背景具有更好的鲁棒性,同时也能够有效的改善遮挡以及自遮挡的问题。因此,基于skeleton数据的动作识别也是一个非常具有吸引力的研究课题。
但是对于skeleton这种不规则的具有图结构的数据,相对于image或者是video这种规整数据,使用经典的CNN 等神经网络进行特征提取就要困难很多了。但是,从2018年起,不断出现使用图卷积(Graph Convolutional Networks,GCN)来处理这个问题的工作。基于前面的工作,本文也是想要通过改善GCN来进一步的提升基于骨架信息的动作识别的性能。
虽然GCN极大的提高了动作识别的性能, 但是还是存在很多需要改进的地方。这里我们主要从以下的两个方面去改善现有的GCN。首先, 在这个任务当中大多数的GCN都是提供一个固定的矩阵(Embedding Matrix, EM)来编码数据节点之间的邻接关系,并且这个矩阵从第一层到最后一层一直都用。其次,在这个任务上,大部分的GCN都是基于ICLR2017 Max [2]他们的工作做的。也就是说这一类的GCN都是通过一阶的 切比雪夫多项式(Chebshev polynomial)进行估计的。而我们认为,将高层的特征表示限制是底层的拓扑结构当中是不合理的一种做法。此外,一阶的多项式估计并不能很好的捕捉到高阶的邻接关系。
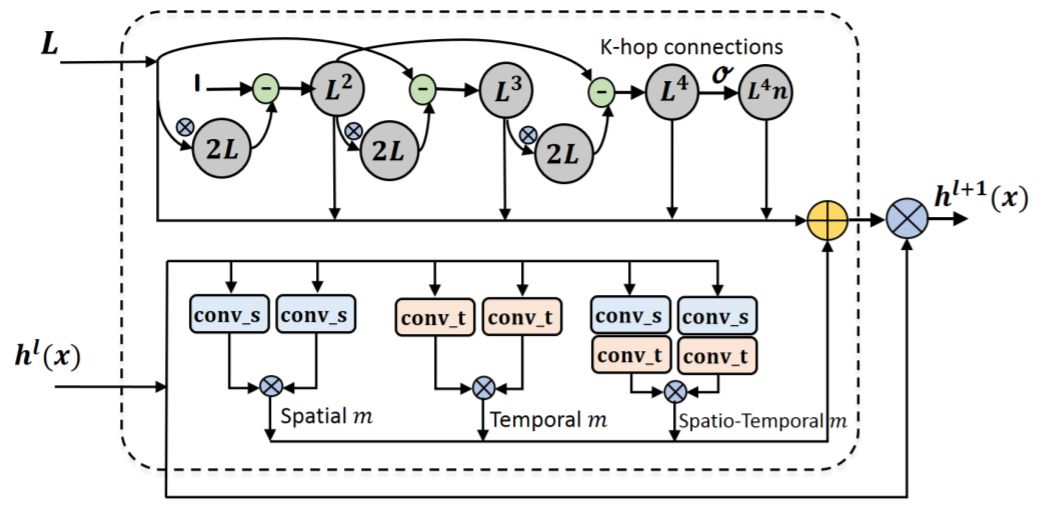
那么如何根据各个网络层的特点提供自动的EM,以及如何提供更加高阶的EM就是本文要解决的问题了。我们一个一个问题来看。首先, 如何提供一种自动化的EM生成机制。实际上,在CVPR2019的一篇工作[1]当中,已经提出了一种自适应生成EM的方式。但是在此工作当中,他们对每一层都采用同样的机制来自动的构建这个矩阵,而并没有去探究不同的生成机制,也没有探讨不同的层是否应该采用相同的矩阵的生成机制。基于此,我们提出了三种动态生成此EM的方式。基本的原理就是通过求解某一层 的特征表示的自相关矩阵,归一化此矩阵用作EM矩阵。但是,在求解该矩阵之前,对该层的特征表示先进行了投影以抽取和该矩阵更加相关的一种特征表示。而此处我们设计的三种EM的生成模块就是根据三种不同的投影方式构造的。具体如图1的下半部分当中的三个模块。
其次,我们来看如何捕捉更加高阶的图节点关系。其实,很简单。当前的GCN不能够很好的捕捉到该信息,是因为GCN采用的乃是一阶的切比雪夫多项式进行估计的。那么我们只需要引入高阶的切比雪夫多项式就可以捕捉到这种信息。然而新的问题是,各层都应该采用高阶的多项式估计吗?这显然会增加计算量,同时我们也不确定是不是每一层都要这样做。因为,我们知道通过网络的堆叠实际上是类似于增大了网络的感受野,因此也可以捕捉到高阶的节点关系。此外,多项式当中的每一项的贡献是一样的吗?可以减少吗?带着这样的疑问,我们构建了一个四阶的多项式,然后对于最高阶的输出还做一个规范化。并且我们将这总共五个部分,作为五个模块来生成不同阶数的矩阵。
因此,对于每一GCN层来讲,如图1所示,都有8种生成一个EM矩阵的方式可供选择。同时处在不同层级的特征表示的抽象程度不一样,因此我们认为应该提供一种layer-wise的 解决方案。显然,这将会有8的十次方(由于在这个任务当中通常会有10个GCN层)这么多种可能。通过手工的调节和寻找显然是不行的。因此,我们借助于自动网络搜索(NAS)的方式来解决这个问题。
具体来讲,我们将这里设计的8种功能模块作为NAS搜索空间当中的8种操作子,也就是将其看作是一个类似于卷积核一样的操作,然后基于这8个功能模块,构建一个搜索空间。类似于著名的NAS算法DARTS [3],我们可以将所有的功能模块放到每一层,然后给每一个功能模块赋一个权重,将该权重看作是待搜索的网络的架构。然后, 基于此交替的在训练的数据集上面训练这个超级网络,在验证集上面更新架构的参数。最终得到一个性能最优的结构就可以了。
但是DARTS这种基于梯度的算法最大的问题就是耗内存,你需要在每一个时刻把架构所有的模块放到内存当中。但是,在我们的任务当中,我们并不想像图像识别当中NAS一样,在一个小的数据集(CIFAR10)上面搜索,然后到自己的目标数据集上面去训练。这种操作有几个问题:1.会引入domain shift的问题(你怎么知道在小数据集上面好使,在大的上面就好使啊?),2. 在自己的任务上不一定存在一个合适的代理数据集(proxy dataset),类似于CIFAR10。在我们这个任务说我们想直接在目标任务数据集上搜索,而不在额外的花精力去构建一个合理的代理数据集。
如此,基于以上的搜索空间,我们想同时提出一种内存高效的搜索算法。这种算法,他不局限于一个连续的搜索空间,当你有足够的卡的时候可以全部模块都激活,当你没有的时候,只激活其中的一个。因此,我们选择了一种不是基于梯度的搜索算法,其实是一种基于采样的演化算法策略。但是,一般的演化算法效率都非常的低,因此我们使用的是一种高效采样的演化策略。
具体来讲,我们算法叫做CEIM:Cross-Entropy method with Importance-Mixing. 这种搜索算法通过一种分布(这里高斯分布)来建模待搜索架构的分布,然后通过更新这个分布来更新架构搜索的过程。于此同时,该算法通过混合当前迭代和上一次迭代的样本来提高采样的效率。具体的步骤如下图:
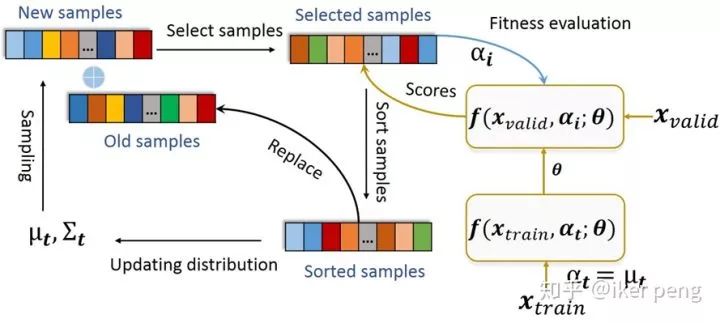
总的来讲, 在CEIM算法当中,主要有四个步骤。首先,对架构参数用高斯分布建模;接下来,从架构的分布当中采样一组样本(New samples),并且和上一轮迭代当中的样本共同组成候选的样本;然后,通过这些样本在当前分布以及在上一个迭代的分布当中的概率密度进行选择,采样一组样本(Importance-Mixing);最后,计算每一个样本的性能表现,由此对这一组样本分配不同的权重,然后加权来更新架构的分布。由于该算法是基于采样的一种算法,不需要对架构的参数进行求导。因此,在更新网络的过程中,完全可以通过多项式采样的方式只激活部分的架构,通过这种方式来减少内存的消耗。具体的算法如下:

OK这就是本文的核心思想,一些具体的细节可以参考文章。这里,我们来看一些实验结果。实验中使用的数据集是当前最大规模的两个数据集,一个是NTU-RGB D,另一个是Kinetics-Skeleton(这个是用Open Pose提的)。首先,我们来看一下搜索的结果。这里我们保留了权重大于0.1的模块。

这里我们可以发现,的确在不同的层GCN倾向于使用不同的EM的生成方式。我们看最右边的三列,我们发现在底层的时候,由于特征还比较低层GCN更喜欢使用更多的模块来生成这个矩阵。同时我们还发现,基于空间信息的投影主要出现在较底层的GCN,而基于时间的卷积投影却出现在了每一层,甚至在高层的时候只出现了后者。然后,我们再来看高阶的估计(左边的5列),我们会发现二阶的估计在中间的几层出现。然后到了最后一层,实际上是不需要任何一种多项式估计的。同时,我们还发现,原始的(手动设计的)矩阵并没有在任何一层被选中,这个给我了我们一些在设计GCN时候的新启发。
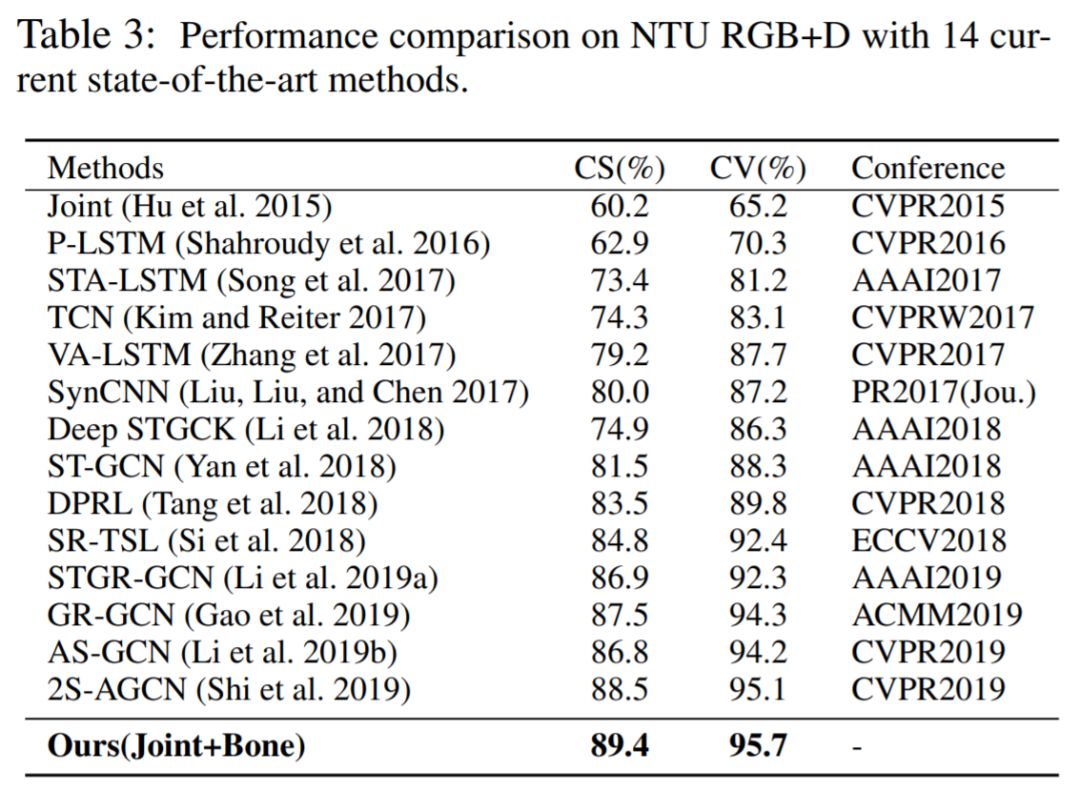
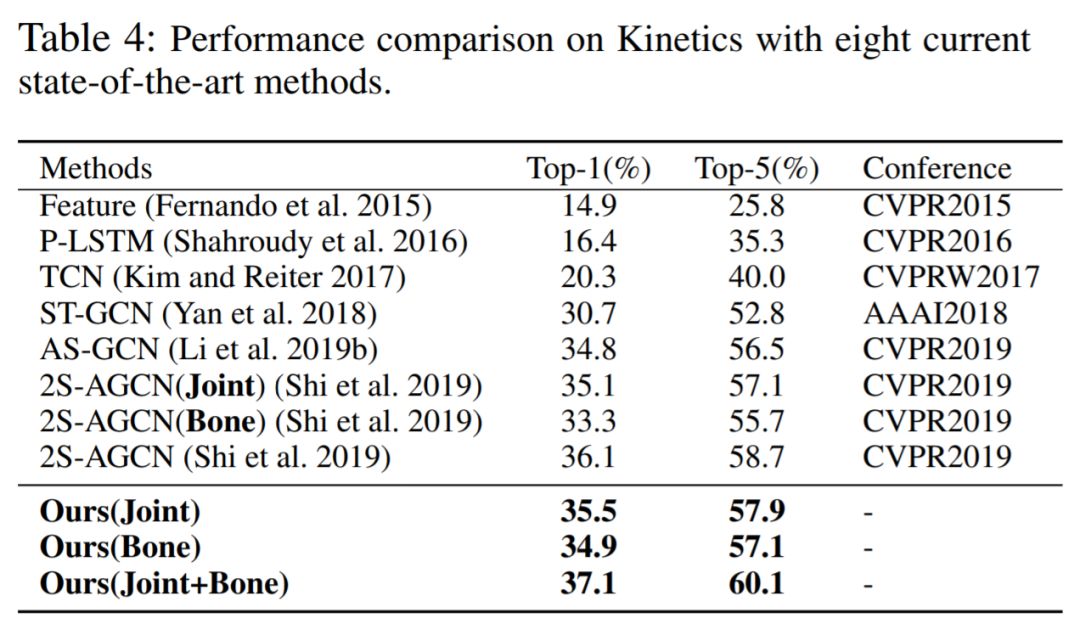
接下来我们看一下性能方面的比较。首先是Ablation study相关的实验。我们想验证我们采用这种方式的有效性。这部分的实验是在 NTU-RGB D数据集上的Corss-view 测评下进行的。首先,我们将本文当中设计的模块,手动的加到GCN网络当中。我们发现,他们几乎都能够提升baseline的表现,这证明我们设计的模块是合理的。同时,我们也发现,将所有的模块同时添加到GCN当中并不能保证得到最好的性能。这也证明了通过NAS进行自动设计的必要性。我们可以从最终的结果发现,使用我们的NAS算法,可以得到最好的性能,几乎都能够得到1%左右的提升。最后, 我们在这两个数据集上面和当前的State-of-the-art 方法进行比较。结果如下,在不同的测试协议和不同的数据库上面,我们都能够得到当前最好的性能。
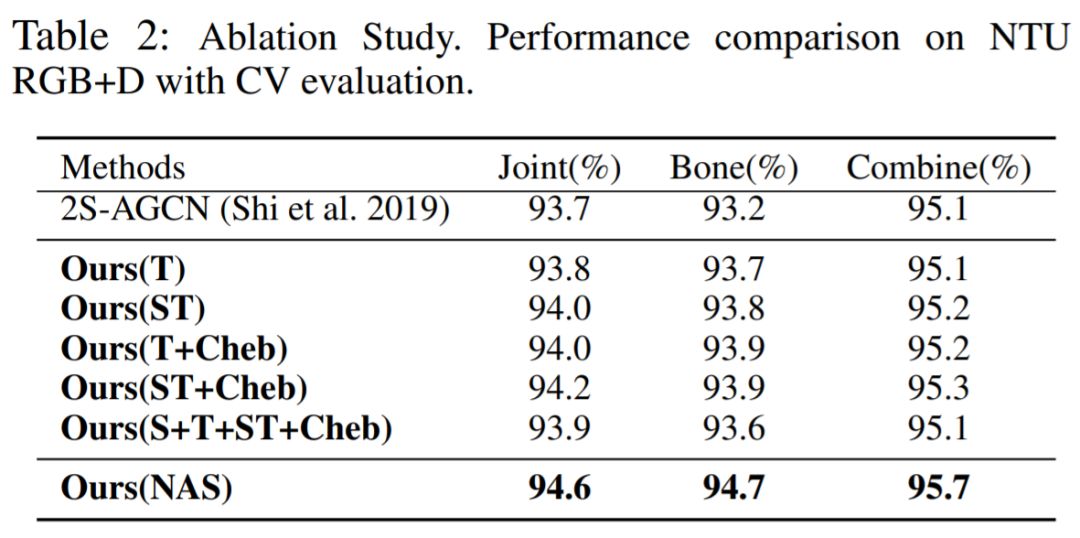
接下来我们看一下性能方面的比较。首先是Ablation study相关的实验(Table 2)。我们想验证我们采用这种方式的有效性。这部分的实验是在 NTU-RGB D数据集上的Corss-View 测评下进行的。首先,我们将本文当中设计的模块,手动的加到GCN网络当中。我们发现,他们几乎都能够提升baseline的表现,这证明我们设计的模块是合理的。同时,我们也发现,将所有的模块同时添加到GCN当中并不能保证得到最好的性能。这也证明了通过NAS进行自动设计的必要性。我们可以从最终的结果发现,使用我们的NAS算法,可以得到最好的性能,几乎都能够得到1%左右的提升。最后, 我们在这两个数据集上面和当前的State-of-the-art 方法进行比较。结果如下Table3 4,在不同的测试协议和不同的数据库上面,我们都能够得到当前最好的性能。
结论
我们这篇文章应该是第一个尝试采用NAS来设计GCN的工作吧(据我所知)。由于GCN并没有很多的算子(operations),并且这个EM矩阵对于GCN来说更加的重要。因此,我们尝试设计一系列的EM生成模块,然后基于这些模块来构建一个NAS的搜索空间。同时,我们也为这个搜索空间提出一种新的,基于高效的演化策略的搜索算法。最终,我们在动作识别上,通过搜索得到一个最优的架构,同时在当前最大的两个数据集上面得到最好的性能。
[1] Two-stream adaptive graph convolutional networks for skeleton-based action recognition. CVPR2019.
[2] Semi-supervised classification with graph convolutional networks. ICLR2017.
[3] Darts: Differentiable architecture search. ICLR2019.
CVer 推荐阅读
YOLOv3最全复现代码合集(含PyTorch/TensorFlow和Keras等)
重磅!CVer-学术交流群已成立
扫码可添加CVer助手,可申请加入CVer大群和细分方向群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索等群。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加群

▲长按关注我们
麻烦给我一个在看!




