基于注意力机制的图卷积网络
ATTENTION-BASED GRAPH NEURAL NETWORK FOR SEMI-SUPERVISED LEARNING
背景:
随着CNN在图像处理方面取得突破性成果,越来越多的人开始关注将卷积神经网络从规整的网格结构泛化到一般的图结构。本文在分析GCN重点工作Kipf & Welling (2016)后发现,图上的半监督学习任务可以通过去除非线性变换和加入简单的attention机制而获得更好的表现。
预备知识:
图卷积网络。
图卷积在半监督分类问题中的应用。
首先,作者在论文中重申了图上半监督分类问题的定义,即“The goal of such graph-based semi-supervised learning problems is to classify the nodes in a graph using a small subset of labeled nodes and all the node features.”。本文的解决思路是通过加入“注意力机制”的图卷积网络做表示学习,产生所有顶点的embedding。在学习过程中,一部分是通过图的自身结构信息作无监督训练,另一部分是加入少量结点的标签信息作有监督训练。
模型:
在模型方面,首先回顾了图卷积网络(Graph Convolutional Networks, GCN)的定义。通过对GCN的分析,对原网络模型稍做改动并提出了图线性网络(Graph Linear Networks, GLN)。为了解决GCN和GLN中平等对待所有邻居的问题,进一步使用attention机制学习不同邻居的影响力大小。
GCN:根据Kipf & Welling (2016),GCN的定义为:
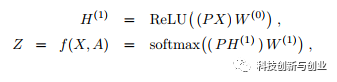
其中P矩阵为Symmetric normalized Laplacian,X为结点的原始特征(如文本特征),W为可学习参数,Z为每个节点的最终表示。在上面的定义中,每一层可以看成由两部分构成:1)传播层,即(PX)W^{0}。 2)非线性变换层,即ReLU(x)。 通过实验验证,作者认为非线性变换不是必须的,该模型的主要表达能力来自传播层。
GLN:基于上面的实验结果,作者去掉了非线性操作ReLU, 原始的GCN被改造为GLN,即Graph Linear Network。
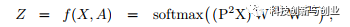
在标准benchmark上,去掉ReLu的GLN与原始的GCN表现相当, 甚至在某些实验中超过了GCN。同时,在与其它不使用图信息的半监督分类学习算法(如T-SVM)的比较中, 作者发现图结构能够显著提升预测性能。进一步,作者提出加入注意力机制为每个节点的邻居节点赋予权重,权重越大则该邻居越重要。
Attention-based GLN:对于一个无权图,原始GLN或者GCN的问题在于,结点的每个邻居被同等对待。比如对i的邻居j,P_{ij} = (|N(i)| * |N(j)|)^{-1/2} 。事实上,每个邻居对该结点的影响应该是动态的(dynamic)、自适应(adaptive)的。 因此,作者引入了注意力机制,对于一个结点i的所有邻居而言,传播矩阵中的参数不再是P_{ij} = (|N(i)| * |N(j)|)^{-1/2}, 而是
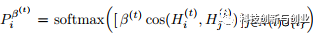
通过attention的定义看出,每层只多了一个可训练的参数bata(t)。 作者在文中提到曾尝试更加复杂的attention机制,但在半监督学习中,尤其是带有label的样本非常少时极其不稳定,因此最终选择了这个简单的模型。
实验结果:
论文在实验部分分析了attention的作用,发现在半监督学习的设定下,每个节点更倾向于融合相同label节点的特征,即在传播层中,具有相同label的节点的影响更大。同时,在Citeseer, Cora和PubMed三个数据集上都取得了半监督分类的最好效果。
总结:
在Hamilton et al., 2017的文章中,所有的邻居节点是通过采样获得的,并通过简单的机制(均值、LSTM等)来聚合邻居信息。本文最重要的贡献是加入了注意力机制,使得每个邻居被区分对待。类似的思想在ICLR 2018提交的论文中出现多次,都是为了解决原方法中均匀采样和简单聚集的限制。
参考文献:
W. L. Hamilton, R. Ying, and J. Leskovec. Inductive representation learning on large graphs. arXiv preprint arXiv:1706.02216, 2017.
T. N. Kipf and M. Welling. Semi-supervised classification with graph convolutional networks. arXiv preprint arXiv:1609.02907, 2016.
ATTENTION-BASED GRAPH NEURAL NETWORK FOR SEMI-SUPERVISED LEARNING. Under review at ICLR 2018.



