目标检测小tricks之样本不均衡处理

作者丨燕小花
研究方向丨计算机视觉
引言
当前基于深度学习的目标检测主要包括:基于 two-stage 的目标检测和基于 one-stage 的目标检测。two-stage 的目标检测框架一般检测精度相对较高,但检测速度慢;而 one-stage 的目标检测速度相对较快,但是检测精度相对较低。one-stage 的精度不如 two-stage 的精度,一个主要的原因是训练过程中样本极度不均衡造成的。
目标检测任务中,样本包括哪些类别呢?
正样本:标签区域内的图像区域,即目标图像块;
负样本:标签区域以外的图像区域,即图像背景区域;
易分正样本:容易正确分类的正样本,在实际训练过程中,该类占总体样本的比重非常高,单个样本的损失函数较小,但是累计的损失函数会主导损失函数;
易分负样本:容易正确分类的负样本,在实际训练过程中,该类占的比重非常高,单个样本的损失函数较小,但是累计的损失函数会主导损失函数;
难分正样本:错分成负样本的正样本,这部分样本在训练过程中单个样本的损失函数教高,但是该类占总体样本的比例教小;
难分负样本:错分成正样本的负样本,这部分样本在训练过程中单个样本的损失函数教高,但是该类占总体样本的比例教小。
那么什么是样本不平衡问题?
所谓的样本不平衡问题是指在训练的时候各个类别的样本数量极不均衡。以基于深度学习的单阶段目标检测为例,样本类别不均衡主要体现在两方面:正负样本不均衡(正负样本比例达到 1:1000)和难易样本不均衡(简单样本主导 loss)。一般在目标检测任务框架中,保持正负样本的比例为 1:3(经验值)。
对于一个样本,如果它能很容易地被正确分类,那么这个样本对模型来说就是一个简单样本,模型很难从这个样本中得到更多的信息;而对于一个分错的样本,它对模型来说就是一个困难的样本,它更能指导模型优化的方向。
对于单阶段分类器来说,简单样本的数量非常大,他们产生的累计贡献在模型更新中占主导作用,而这部分样本本身就能被模型很好地分类,所以这部分的参数更新并不会改善模型的判断能力,这会导致整个训练变得低效。
实际训练过程中如何划分正负样本训练集?
近年来,不少的研究者针对样本不均衡问题进行了深入研究,比较典型的有 OHEM [1](在线困难样本挖掘)、S-OHEM [2]、A-Fast-RCNN [3]、Focal Loss [4]、GHM [5](梯度均衡化)。
样本不均衡的处理方法
OHEM(在线困难样本挖掘)
OHEM 算法 [1](Online Hard Example Mining,发表于 2016 年的 CVPR)主要是针对训练过程中的困难样本自动选择,其核心思想是根据输入样本的损失进行筛选,筛选出困难样本(即对分类和检测影响较大的样本),然后将筛选得到的这些样本应用在随机梯度下降中训练。
在实际操作中是将原来的一个 ROI Network 扩充为两个 ROI Network,这两个 ROI Network 共享参数。其中前面一个 ROI Network 只有前向操作,主要用于计算损失;后面一个 ROI Network 包括前向和后向操作,以 hard example 作为输入,计算损失并回传梯度。该算法在目标检测框架中被大量使用,如 Fast RCNN。
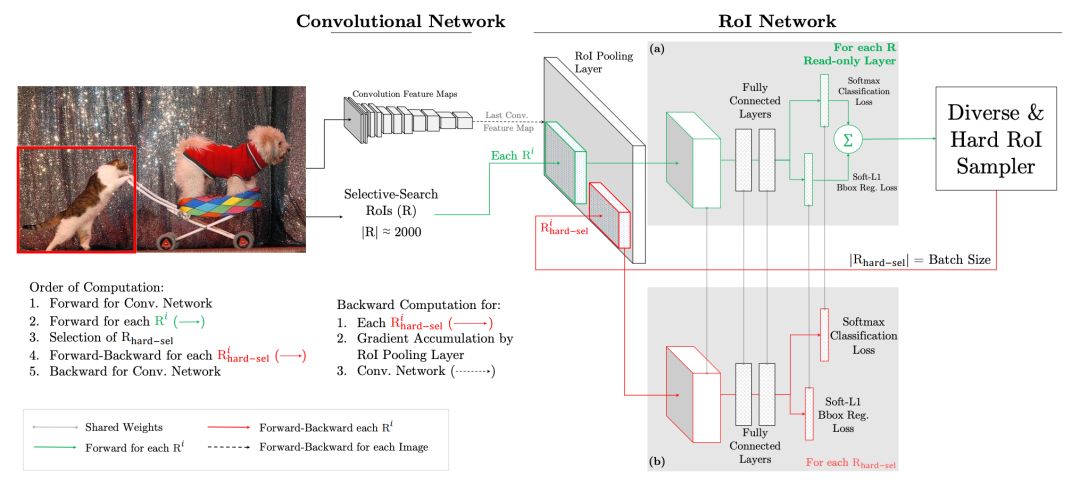
该算法的优点:1)对于数据的类别不平衡问题不需要采用设置正负样本比例的方式来解决,这种在线选择方式针对性更强;2)随着数据集的增大,算法的提升更加明显。
该算法的缺点:只保留 loss 较高的样本,完全忽略简单的样本,这本质上是改变了训练时的输入分布(仅包含困难样本),这会导致模型在学习的时候失去对简单样本的判别能力。
S-OHEM(基于loss分布采样的在线困难样本挖掘)
先来看看原生的 OHEM 存在什么问题?假设给定 RoI_A 和 RoI_B,其对应的分类和边框回归损失分别为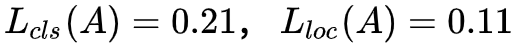
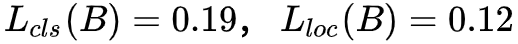
如果按照原生的 OHEM(假定各损失函数权重相同),此时 RoI_A 的总体 loss 大于 RoI_B,也就是说 A 相对于 B 更难分类;而实际上单从分类损失函数(交叉熵),RoI_A 和 RoI_B 的实际类别概率分别是 61.6% 和 64.5%,在类别概率上两者只相差 0.031,可以认为 A 和 B 具有相同的性能。
单从边框损失函数(Smooth L1),虽然 A 和 B 的损失函数只相差 0.01,但这个微小的差会导致预测边框和 groudtruth 有 0.14 的差距,此时,B 相对于 A 更难分类,因此单从 top-N 损失函数来筛选困难样本是不可靠的。
针对上述问题,提出了 S-OHEM 方法 [2](发表于 2017 年的 CCCV),主要考虑 OHEM 训练过程忽略了不同损失分布的影响,因此 S-OHEM 根据 loss 的分布抽样训练样本。它的做法是将预设 loss 的四个分段:
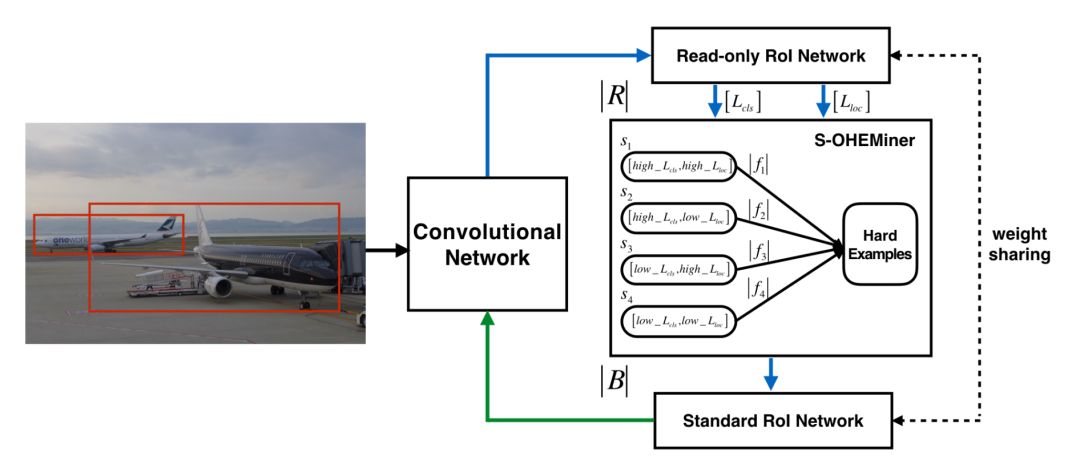
给定一个 batch,先生成输入 batch 中所有图像的候选 RoI,再将这些 RoI 送入到 Read only RoI 网络得到 RoIs 的损失,然后将每个 RoI 根据损失(这里损失是一个组合,具体公式为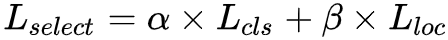
之所以采用这个公式是因为在训练初期阶段,分类损失占主导作用;在训练后期阶段,边框回归损失函数占主导作用)划分到上面四个分段中,然后针对每个分段,通过排序筛选困难样本。再将经过筛选的 RoIs 送入反向传播,用于更新网络参数。
优点:相比原生 OHEM,S-OHEM 考虑了基于不同损失函数的分布来抽样选择困难样本,避免了仅使用高损失的样本来更新模型参数。
缺点:因为不同阶段,分类损失和定位损失的贡献不同,所以选择损失中的两个参数 α,β 需要根据不同训练阶段进行改变,当应用与不同数据集时,参数的选取也是不一样的.即引入了额外的超参数。
A-Fast-RCNN(基于对抗生成网络的方式来生成困难样本)
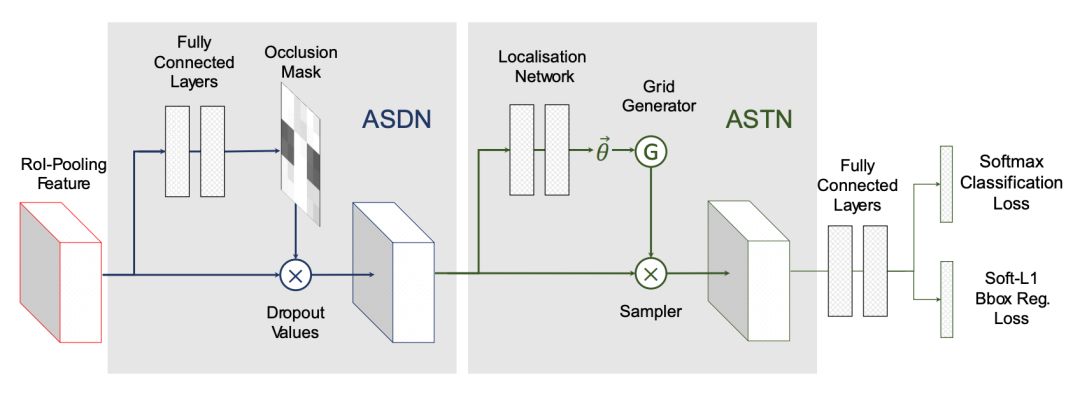
从更好的利用数据的角度出发,OHEM 和 S-OHEM 都是发现困难样本,而 A-Fast-RCNN [3] 的方法(发表于 2017 年 CVPR)则是通过 GAN 的方式在特征空间产生具有部分遮挡和形变(本文主要考虑旋转特性)的困难样本,而这部分样本数据很难出现在实际训练数据集中。
本文通过生成的方式来教网络什么是“遮挡”和“变形”,区别于传统的直接生成样本图片的方法,这些变换都是基于特征图的:1)通过添加遮挡 mask 来实现特征的部分遮挡;2)通过操作特征响应图来实现特征的部分变形。
本文设计了两个对抗网络 ASDN 和 ASTN,分别对应于样本的遮挡和样本的变形,并将这两种变形相融合(ASDN 的输出作为 ASTN 的输入),使得检测器在训练的时候可以更加鲁棒。
优点:与 OHEM 相比,区别在于文本的方法是构建不存在的 Hard Poistive 样本,而 OHEM 是挖掘现有样本中的 Hard 样本。
缺点:从改善效果上来讲,A-Fast-RCNN 的方法的效果并不比 OHEM 好太多,也许是仿造的数据和真实性还存在差距,此外 GAN 网络也比较难训练。
Focal Loss(损失函数的权重调整)
针对 OHEM 算法中忽略易分样本的问题,本文提出了一种新的损失函数 Focal Loss(发表于 2017 ICCV),它是在标准交叉熵损失基础上修改得到的。这个损失函数可以通过减少易分类样本的权重,使得模型在训练时更专注于难分类的样本。
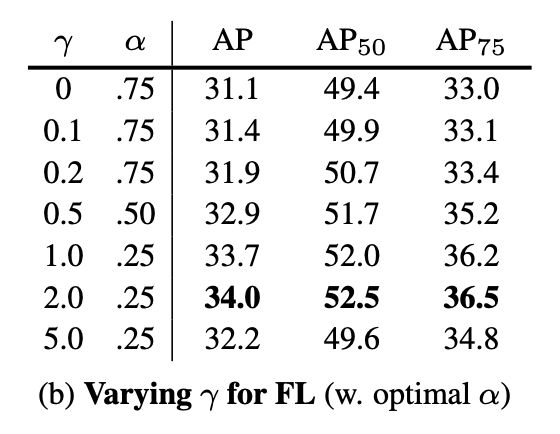
为了证明 Focal Loss 的有效性,作者设计了一个 dense detector:RetinaNet,并且在训练时采用 Focal Loss 训练。实验证明 RetinaNet 不仅可以达到 one-stage detector 的速度,也能有 two-stage detector 的准确率。
先来看看 Focal Loss 损失函数的公式:
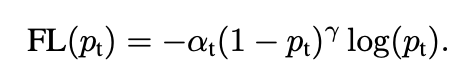
其中用于控制正负样本的权重,当其取比较小的值来降低负样本(多的那类样本)的权重;
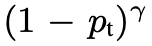
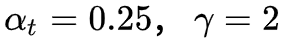
进一步来看看 Focal Loss 函数有什么性质?
当一个样本被错分的时候, Pt 是很小的,那么调制系数
当 γ 增加时,调制系数也会增加。假设 γ=2 ,对于一个易分样本(Pt=0.9)的损失函数要比标准的交叉熵小 100 倍;当 Pt=0.968 时,要小 1000+ 倍,但是对于难分样本(Pt < 0.5),loss 最多小了 4 倍。由此可见难分样本的权重相对提升了很多,从而增加哪些错误分类的重要性。
GHM(损失函数梯度均衡化机制)
对于一个样本,如果它能很容易地被正确分类,那么这个样本对模型来说就是一个简单样本,模型很难从这个样本中得到更多的信息,从梯度的角度来说,这个样本产生的梯度幅值相对较小。而对于一个分错的样本来说,它产生的梯度信息则会更丰富,它更能指导模型优化的方向。
对于单阶段分类器来说,简单样本的数量非常大,他们产生的累计贡献在模型更新中占主导作用,而这部分样本本身就能被模型很好地分类,所以这部分的参数更新并不会改善模型的判断能力,这会导致整个训练变得低效。因此单阶段目标检测中样本不均衡性的本质是简单困难样本的不均衡性。
受 Focal loss 启发,本文通过深入分析 one-stage 目标检测框架中样本分布不平衡(正负样本不均衡和难易样本不均衡)的本质影响,提出了基于梯度分布的角度来缓解 one-stage 中的训练样本不平衡(简称 GHM,Gradient Harmonizing Mechanism,发表于 AAAI 2019,并获得了 Oral),从而改善 one-stage 的目标检测的检测精度。
本文提出了梯度密度,并将梯度密度的倒数作为损失函数的权重分别引入到分类损失函数(GHM-C)和边框损失函数(GHM-R)。
损失函数的权重(梯度密度的倒数)
就是把梯度幅值范围(X 轴)划分为 M 个区域,对于落在每个区域样本的权重采取相同的修正方式,类似于直方图。具体推导公式如下所示。
X 轴的梯度分为 M 个区域,每个区域长度即为 ε,第 j 个区域范围即为,用
表示落在第 j 个区域内的样本数量。定义 ind(g) 表示梯度为 g 的样本所落区域的序号,那么即可得出新的参数
。
由于样本的梯度密度是训练时根据 batch 计算出来的,通常情况下 batch 较小,直接计算出来的梯度密度可能不稳定,所以采用滑动平均的方式处理梯度计算。

这里注意 M 的选取。当 M 太小的时候,不同梯度模上的密度不具备较好的方差;当然 M 也不能太大,因为 M 过大的时候,受限于 GPU 限制,batch size 一般都比较小,此时如果 M 太大的话,会导致每次统计过于稀疏(分得太细了),异常值对小区间的影响较大,导致训练不稳定。本文根据实验统计,M 取 30 为最佳。
GHM-C 分类损失函数
对于分类损失函数,这里采用的是交叉熵函数,梯度密度中的梯度模长是基于交叉熵函数的导数进行计算的,GHM-C 公式如下:
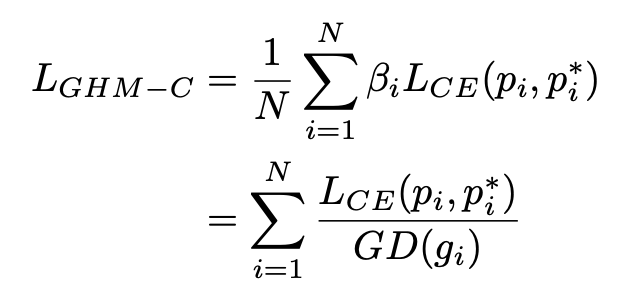
HM-R 边框回归损失函数
对于分类损失函数,由于原生的 Smooth L1 损失函数的导数为 1 时,样本之间就没有难易区分度了,这样的统计明显不合理。
本文修改了损失函数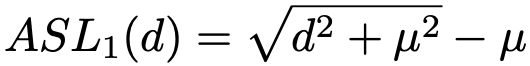
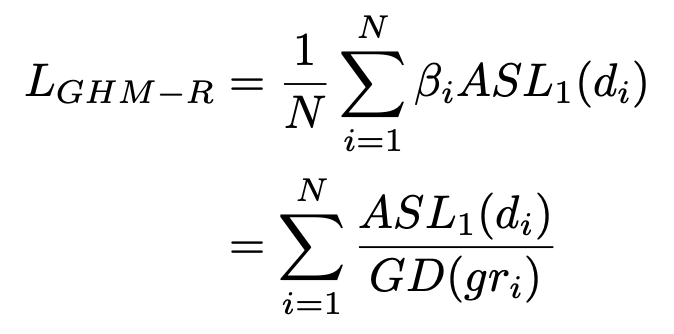
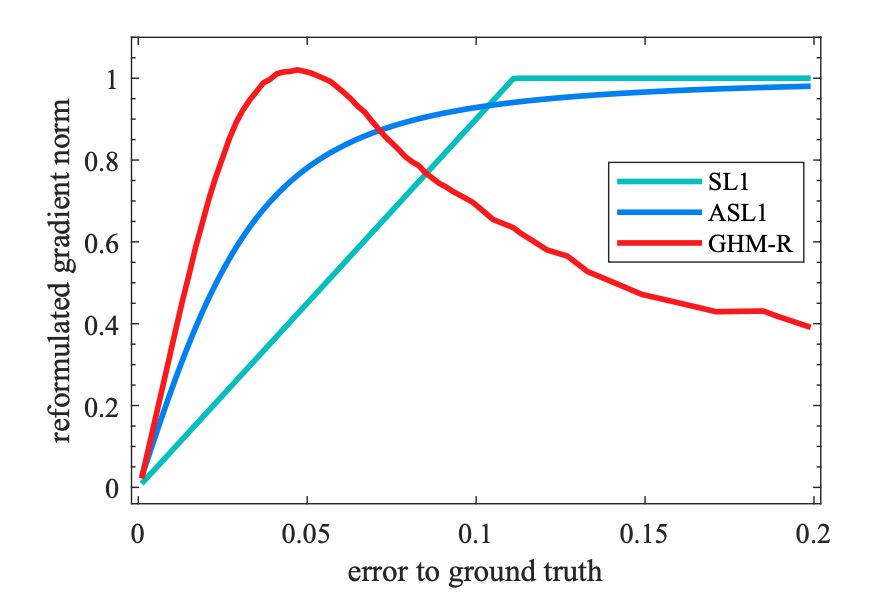
总结与困惑
总结
1. OHEM 系列的困难样本挖掘方法在当前的目标检测框架上还是被大量地使用,在一些文本检测方法中还是被经常使用;
2. OHEM 是针对现有样本并根据损失 loss 进行困难样本挖掘,A-Fast-RCNN 是构建不存在的 Hard Poistive 样本(即造样本),Focal Loss 和 GHM 则从损失函数本身进行困难样本挖掘;
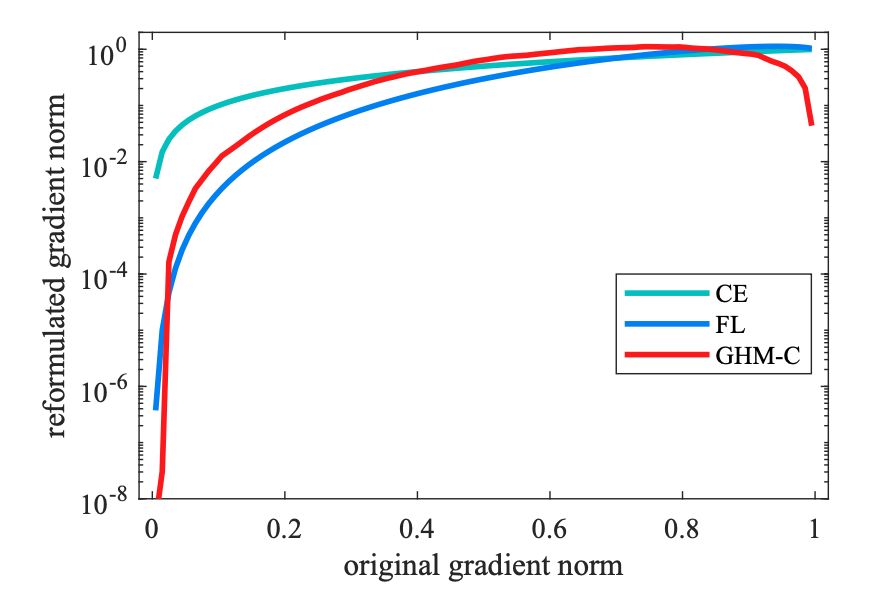
3. 相比 Focal loss,本文提出的 GHM 是一个动态的损失函数,即随着不同数据的分布进行变换,不需要额外的超参数调整(但是这里其实还是会涉及到一个参数,就是 Unit region 的数量);此外 GHM 在降低易分样本权重的同时,对 outliner 也会有一定程度的降权;
4. 无论是 Focal Loss,还是基于 GHM 的损失函数都可以嵌入到现有的目标检测框架中;Focal Loss 只针对分类损失,而 GHM 对分类损失和边框损失都可以
5. GHM 方法在源码实现上,作者采用平均滑动的方式来计算梯度密度,不过与论文中有一个区别是在计算梯度密度的时候,没有乘以 M,而是乘以有效的(也就是说有梯度信息的区间)bin 个数;
6. 之前尝试过Focal Loss用于多分类任务中,发现在精度并没有提升;但是我试过将训练数据按照训练数据的原始分布并将其引入到交叉熵函数中,准确率提升了;GHM 方法的本质也是在改变训练数据的分布(将难易样本拉匀),但是到底什么的数据分布是最优的,目前尚未定论。
困惑
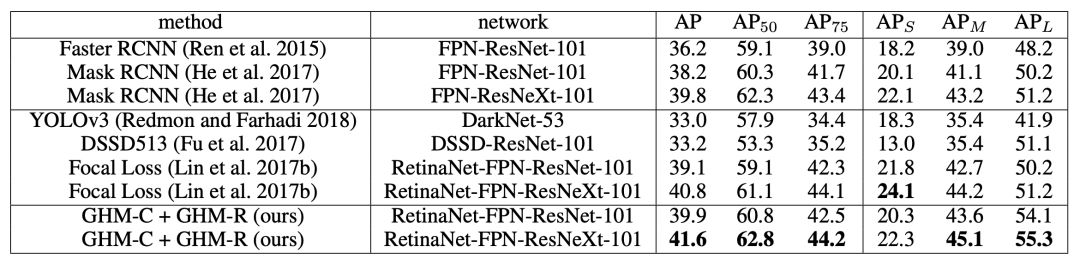
从 GHM 与其它经典方法的对比中,不难看出在相同框架的基础上,GHM 对中大型目标的检测(特别是大目标)优于 Focal loss,但对于小目标的检测不如 Focal loss 好,这里是什么原因导致的?
本文仅是个人的理解和总结,若有错误或遗漏的地方,欢迎指正和补充。
参考文献
[1] Abhinav Shrivastava, Abhinav Gupta and Ross Girshick. Training Region-based Object Detectors with Online Hard Example Mining. In Proceedings of Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
[2] Minne Li, Zhaoning Zhang, Hao Yu, Xinyuan Chen, Dongsheng Li. S-OHEM: Stratified Online Hard Example Mining for Object Detection. In Proceedings of Computer Vision - Second CCF Chinese Conference, CCCV 2017.
[3] Xiaolong Wang, Abhinav Shrivastava, and Abhinav Gupta. A-Fast-RCNN: Hard Positive Generation via Adversary for Object Detection. In Proceedings of Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
[4] Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, Piotr Dollár. Focal Loss: Focal Loss for Dense Object Detection. In Proceedings of the International Conference on Computer Vision (ICCV), 2017.
[5] Buyu Li, Yu Liu and Xiaogang Wang. GHM: Gradient Harmonized Single-stage Detector. In Proceedings of the AAAI Conference on Artificial Intelligence, 2019.

点击以下标题查看更多往期内容:

让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢? 答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 获取最新论文推荐

