大规模图训练调优指南


训练大规模图
Neighborhood Sampling
方法每次采样一部分输出节点,然后把更新它们所需的所有节点作为输入节点,通过这样的方式做 mini-batch 迭代训练。
具体的用法可以参考官方文档中的 Chapter 6: Stochastic Training on Large Graphs
[3]
。
但是 GATNE-T [4] 中有一种更有趣的做法,即只把 DGL 作为一个辅助计算流的工具,提供Neighborhood Sampling和Message Passing等过程,把Node Embedding和Edge Embedding等存储在图之外,做一个单独的Embedding矩阵。每次从 dgl 中获取节点的id之后再去Embedding矩阵中去取对应的 embedding 进行优化,以此可以更方便的做一些优化。

缩小图规模
从图的Message Passing过程可以看出,基本上所有的图神经网络的计算都只能传播连通图的信息,所以可以先用 connected_componets [5] 检查一下自己的图是否是连通图。如果分为多个连通子图的话,可以分别进行训练或者选择一个大小适中的 component 训练。
Neighborhood Sampling
采样一个子图进行训练。

减小内存占用
list
,使用
np.ndarray
或者
torch.tensor
。尤其注意不要显式的使用
set
存储大规模数据(可以使用
set
去重,但不要存储它)。
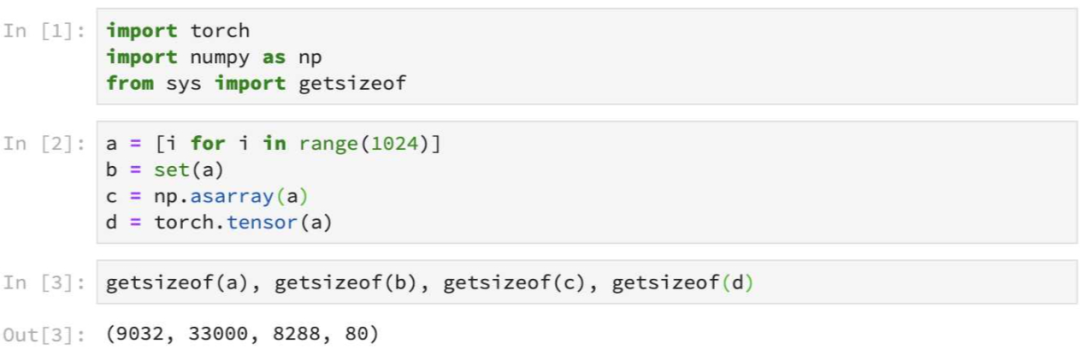
注意:四种数据结构消耗的内存之间的差别(比例关系)会随着数据规模变大而变大。
PyTorch
中,设置
DataLoader
的
num_workers
大于 0 时会出现内存泄露的问题,内存占用会随着 epoch 不断增大。查阅资料有两个解决方法:
根据Num_workers in DataLoader will increase memory usage? [6],设置
num_workers小于实际 cpu 数,亲测无效;根据 CPU memory gradually leaks when num_workers > 0 in the DataLoader [7],将原始
list转为np.ndarray或者torch.tensor,可以解决。原因是:There is no way of storing arbitrary python objects (even simple lists) in shared memory in Python without triggering copy-on-write behaviour due to the addition of refcounts, everytime something reads from these objects.

减小显存消耗
对于大规模图嵌入而言,Embedding矩阵会非常大。在反向传播中如果对整个矩阵做优化的话很可能会爆显存。可以参考 pinsage [8] 的代码,设置Embedding矩阵的sparse = True,使用 SparseAdam [9] 进行优化。SparseAdam是一种为 sparse 向量设计的优化方法,它只优化矩阵中参与计算的元素,可以大大减少backward过程中的显存消耗。
Embedding
矩阵放到 CPU 上。使用两个优化器分别进行优化。

加快训练速度
对于大规模数据而言,训练同样要花很长时间。加快训练速度也很关键。加快训练速度方面主要在两个方面:加快数据预处理和提高 GPU 利用率。
在加快数据预处理中,大部分数据集样本之间都是独立的,可以并行处理,所以当数据规模很大的时候,一定要加大数据预处理的并行度。
不要使用 for 循环逐条处理,可以使用 multiprocess [10] 库开多进程并行处理。但是要注意适当设置processes,否则会出现错误OSError: [Errno 24] Too many open files。
此外,数据处理好之后最好保存为pickle格式的文件,下次使用可以直接加载,不要再花时间处理一遍。
在提高 GPU 利用率上,如果 GPU 利用率比较低主要是两个原因:batch_size较小(表现为 GPU 利用率一直很低)和数据加载跟不上训练(表现为 GPU 利用率上升下降上升下降,如此循环)。解决方法也是两个:
增大
batch_size,一般来说 GPU 利用率和batch_size成正比;加快数据加载:设置
DataLoader的pin_memory=True, 适当增大num_workers(注意不要盲目增大,设置到使用的 CPU 利用率到 90% 左右就可以了,不然反而可能会因为开线程的消耗拖慢训练速度)。
DistributedDataParallel
有几个需要注意的问题:
-
最好参照 graphsage [11] 中的代码而不是使用官方教程中的 torch.multiprocessing.spawn函数开辟多进程。因为使用这个函数会不停的打印Using backend: pytorch,暂时还不清楚是什么原因。 -
和 DataParallel一样,DistributedDataParallel会对原模型进行封装,如果需要获取原模型model的一些属性或函数的话,需要 将model替换为model.module。 -
在使用 DistributedDataParallel时,需要根据 GPU 的数量对batch_size和learning rate进行调整。根据 Should we split batch_size according to ngpu_per_node when DistributedDataparallel [12] ,简单来说就是保持batch_size和learning rate的乘积不变,因为我们多 GPU 训练一般不改batch_size,所以使用了多少 GPU 就要把learning rate扩大为原来的几倍。 -
如何使 DistributedDataParallel支持Sparse Embedding? 可以参考我在 PyTorch 论坛上的回答 DistributedDataParallel Sparse Embeddings [13] ,设置torch.distributed.init_process_group中的backend=gloo即可,现在版本(1.6 以及 nightly)的 PyTorch 在nccl中仍然不支持Sparse Embedding。关于这个问题的最新进展可以看这个 PR:Sparse allreduce for ProcessGroupNCCL [14]
最后,PyTorch 1.6 中提供了混合精度训练 amp [15] 的 API,可以方便的调用,通过将一部分操作从torch.float32 (float)变为torch.float16 (half)来加快训练速度。但是它并不支持Sparse Embedding,如果你的模型中包含Sparse向量的话,最好不要使用。

参考文献
更多阅读




#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。