ICCV 2019:谷歌获最佳论文!中国入选论文最多,中科院、清华领跑

新智元报道
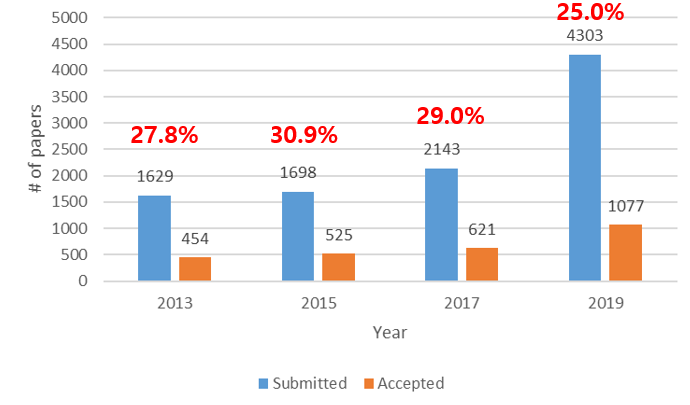
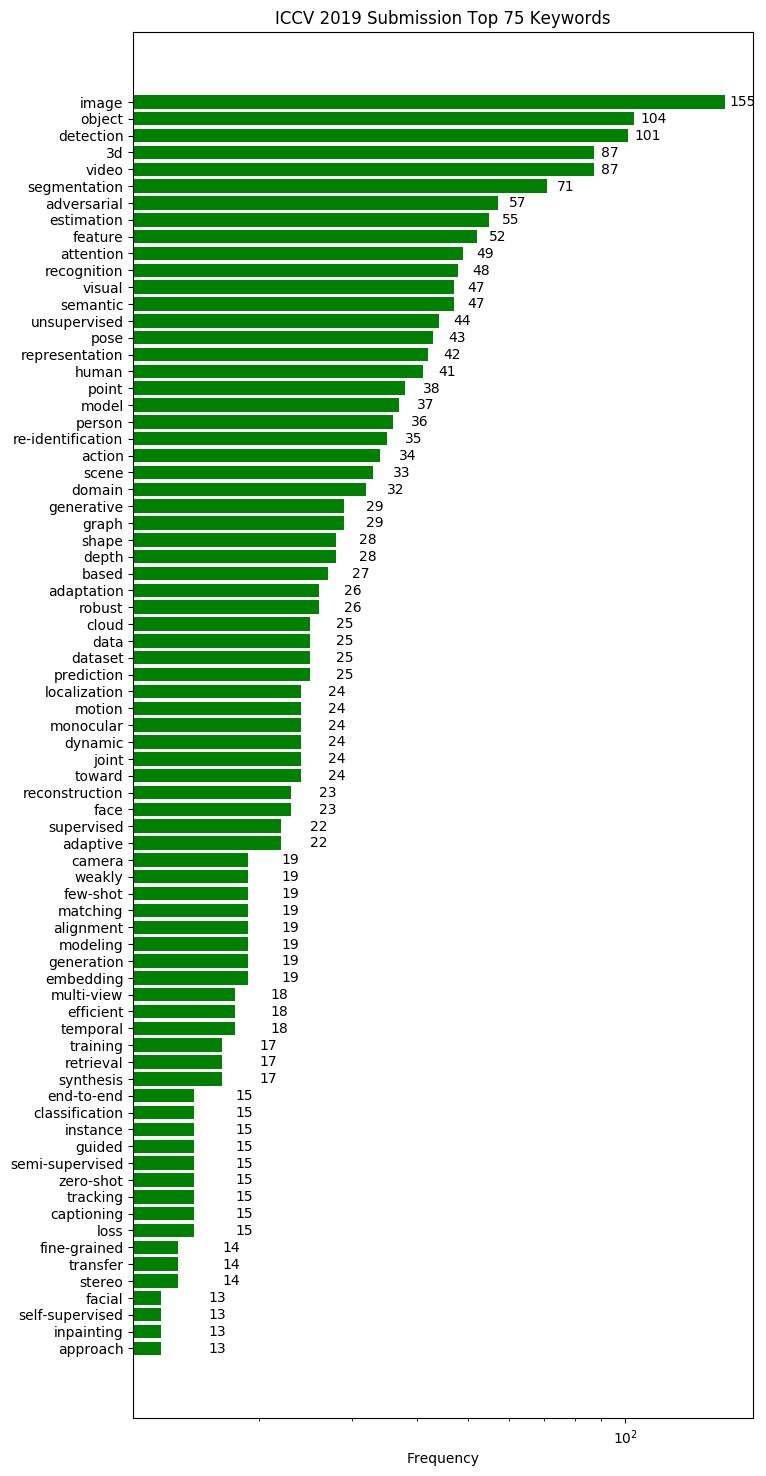
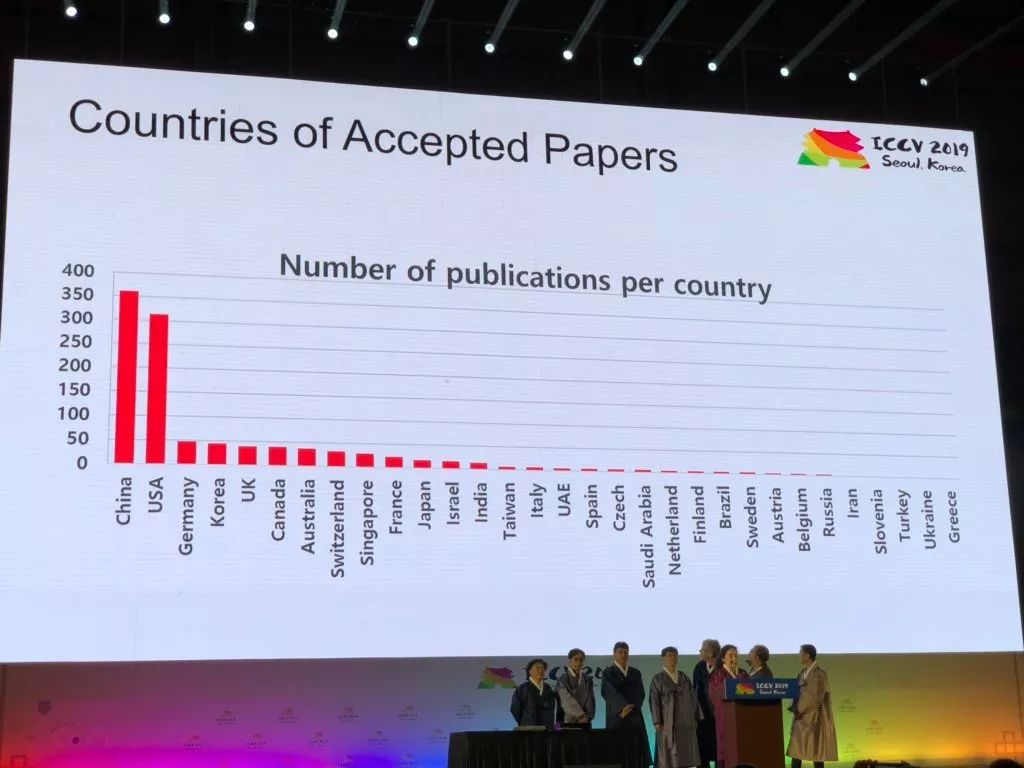
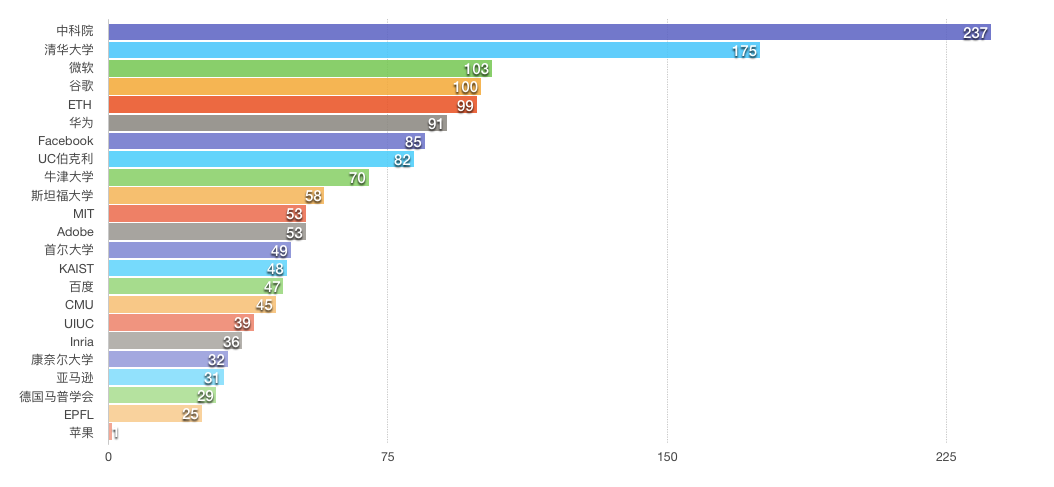
【新智元导读】ICCV2019最佳论文揭晓!来自谷歌和以色列理工学院的研究人员获最佳论文奖。来自中国的被接收论文超过350篇,位居世界第一。商汤、华为、腾讯优图、旷视等中国企业表现抢眼。本届ICCV投稿数达到4303篇,是上届的2倍,共收录1075篇,接收率为25%,较上届略有下降。来新智元 AI 朋友圈与AI大咖一起讨论吧~







登录查看更多
相关内容

Arxiv
15+阅读 · 2020年3月31日
Arxiv
5+阅读 · 2019年5月16日




相关VIP内容
相关资讯
相关论文
Arxiv
15+阅读 · 2020年3月31日
Arxiv
5+阅读 · 2019年5月16日