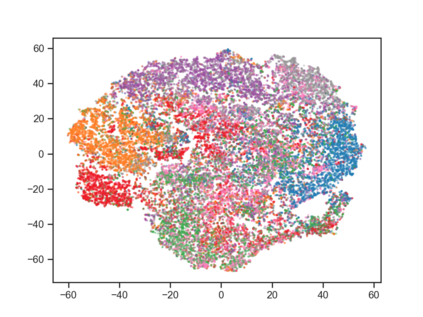
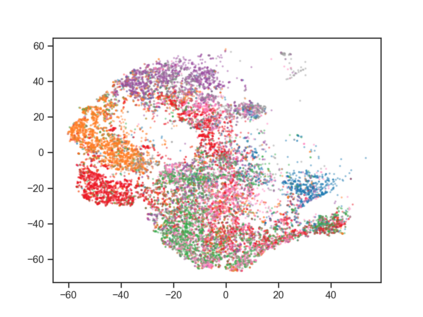
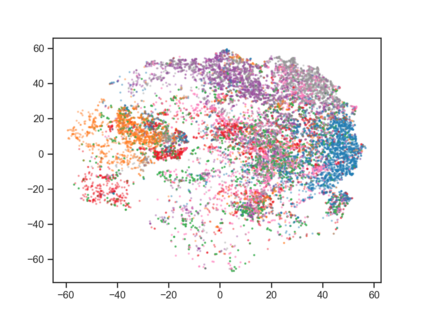
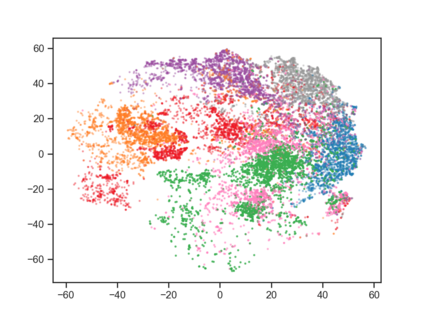
User behavior data in recommender systems are driven by the complex interactions of many latent factors behind the users' decision making processes. The factors are highly entangled, and may range from high-level ones that govern user intentions, to low-level ones that characterize a user's preference when executing an intention. Learning representations that uncover and disentangle these latent factors can bring enhanced robustness, interpretability, and controllability. However, learning such disentangled representations from user behavior is challenging, and remains largely neglected by the existing literature. In this paper, we present the MACRo-mIcro Disentangled Variational Auto-Encoder (MacridVAE) for learning disentangled representations from user behavior. Our approach achieves macro disentanglement by inferring the high-level concepts associated with user intentions (e.g., to buy a shirt or a cellphone), while capturing the preference of a user regarding the different concepts separately. A micro-disentanglement regularizer, stemming from an information-theoretic interpretation of VAEs, then forces each dimension of the representations to independently reflect an isolated low-level factor (e.g., the size or the color of a shirt). Empirical results show that our approach can achieve substantial improvement over the state-of-the-art baselines. We further demonstrate that the learned representations are interpretable and controllable, which can potentially lead to a new paradigm for recommendation where users are given fine-grained control over targeted aspects of the recommendation lists.
翻译:推荐者系统中的用户行为数据是由用户决策过程背后许多潜在因素的复杂相互作用驱动的。 这些因素是高度纠缠的, 可能包括管理用户意图的高层因素, 以及用户在执行意图时偏好特征的低层次因素。 学习发现和分解这些潜在因素的展示可以带来更强的稳健性、 可解释性和可控性。 但是, 了解用户行为中这种分解的表达方式具有挑战性, 并且在很大程度上仍然受到现有文献的忽视。 在本文中, 我们介绍MACRo- mIcro Disentanged Variational Aut- Eccoder( MacridVAE)用于学习用户行为中分解的表达方式( MacridVAE) 的高级因素, 以及从用户行为中解析的低层次因素。 我们的方法通过推断与用户意图相关的高层次概念( 例如购买衬衫或手机手机), 并且可以进一步显示用户对不同概念的偏向。 我们的分解调, 我们的分解方法的每个层面, 然后将迫使用户的每个分解方式的每个方面, 能够独立地反映一个分解的分解。