陈天奇团队推出开源AI芯片栈VTA,降低芯片设计门槛

7月12日,陈天奇团队推出 Versatile Tensor Accelerator(VTA,发音为 vita),这是一种开放、通用、可定制的深度学习加速器。VTA是一种可编程加速器,提供了 RISC风格的编程抽象来描述张量级的操作。VTA的设计体现了主流深度学习加速器最突出和最常见的一些特征,比如张量操作、DMA加载 /存储和显式的计算 /内存调节。
更多干货内容请关注微信公众号“AI前线”,(ID:ai-front)
VTA不仅仅是一个独立的加速器,它其实是一个端到端的解决方案,包含了驱动程序、JIT运行时以及基于 TVM的优化编译器栈。当前版本包含了一个行为硬件模拟器,以及用于在低成本 FPGA硬件上部署 VTA(方便进行快速的原型设计)的基础设施。我们通过使用可定制的开源深度学习硬件加速器对 TVM栈进行了扩展,提供了一个从高级深度学习框架到实际硬件设计和实现的端到端深度学习栈,形成了一个真正的端到端开源软硬件栈。
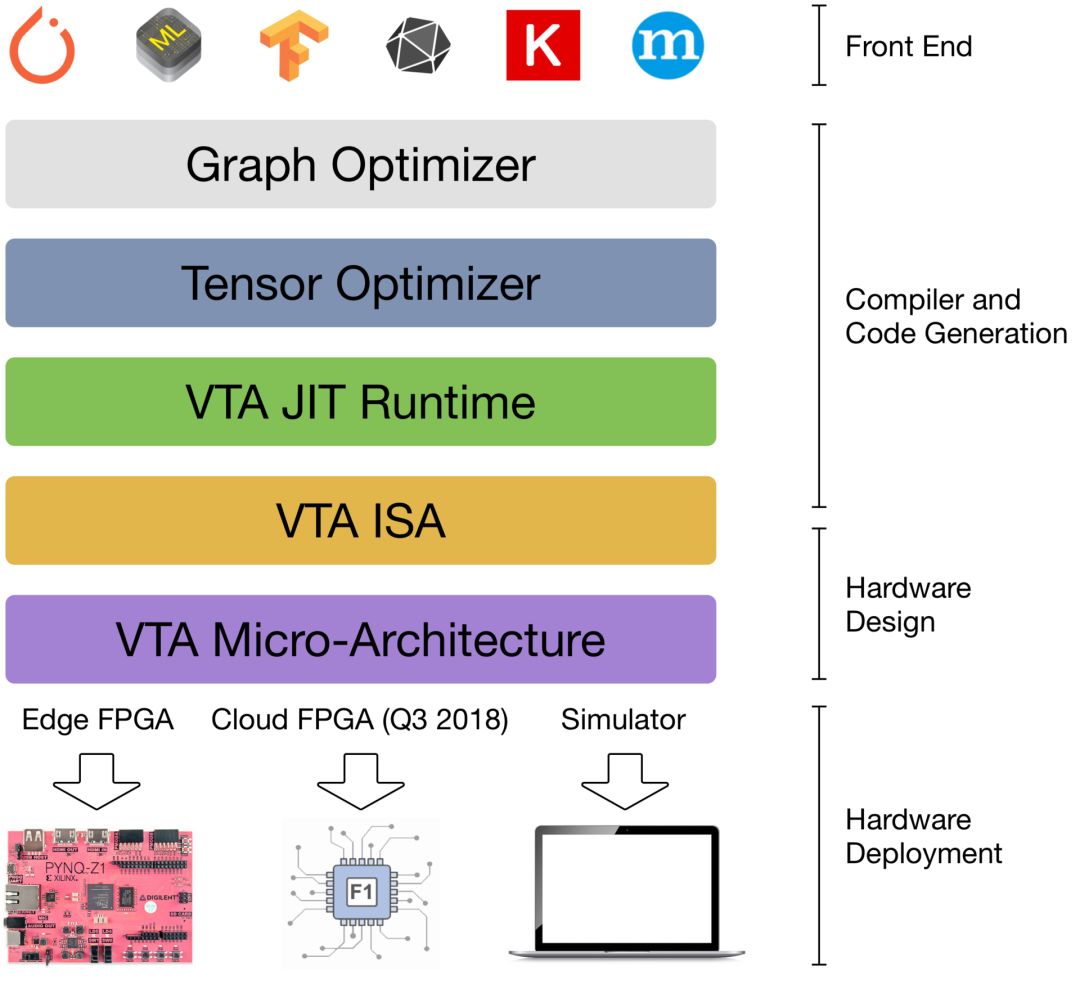
VTA和 TVM栈共同构成了以加速器为中心的、端到端的深度学习系统蓝图:
为硬件、编译器和系统研究人员提供开放的深度学习系统栈,以便集成优化和协同设计技术。
降低机器学习从业者的门槛,让他们能够体验需要专门硬件支持的新型网络架构、操作和数据表示。
我们将重点介绍 VTA与完整的 TVM软件栈相结合将给硬件、编译器和深度学习研究带来新的机会。
随着 ASIC的推陈出新,在新型硬件之上提供完整且可用的软件栈对于在学术和商业领域取得成功来说都至关重要。VTA为硬件加速器提供了 TVM软件栈参考实现。我们希望能够让硬件设计人员快速构建和部署优化的深度学习库,并将它们用在 TensorFlow或 PyTorch等高级框架中。软件支持对于在加速系统中执行全系统评估以了解系统的限制和性能瓶颈来说至关重要。通过将 FPGA用作硬件部署后端,我们为硬件设计原型的快速迭代提供了一个完整的解决方案。最后,我们希望能够将 VTA发展成为一系列硬件设计,最终形成一个开放的可定制化硬件加速器生态系统。
另外,VTA是第一批软硬件可重现 ACM工件之一,可以作为可重复深度学习架构研究的模板。VTA工件可使用在 ReQuEST 2018上露过脸的 CK部署。
已经出现的最新中间表示和优化编译器(如 TVM)用于更好地利用深度学习工作负载的特点。作为 TVM的补充,VTA提供了以加速器为中心的优化和底层代码生成能力。我们开源的深度学习编译器栈向 LLVM看齐,通过社区一起改进以加速器为中心的编译器支持。编译器栈的可扩展性,以及修改硬件后端架构和编程接口的能力,将为深度学习带来令人兴奋的软硬件协同设计的可能性。
透明且可定制的软件和硬件栈帮助深度学习研究人员提出新颖的神经网络操作和数据表示,同时能够对端到端系统上的优化进行全面评估。二值化等技术目前仅限于 CPU和 GPU,除非有专门的工程资源可用于生成可评估这种技术节能潜力的 FPGA或 ASIC。VTA提供了可部署的参考硬件栈,从而为没有太多硬件设计背景的机器学习从业者降低了硬件定制化的门槛。
VTA深度学习加速器和 TVM栈可以弥合专注于提升生产效率的深度学习框架和关注性能的硬件基板(如 FPGA)之间的差距。
NNVM是图形级的优化器,提供了图形级的中间表示(IR),作为不同深度学习框架之间的通用语言,以便更好地利用图形级优化,例如操作数融合。NNVM IR还用于指定数据布局和数据格式约束:例如,张量平铺,以及用于超低精度计算的位组装。
TVM是张量级的优化器,基于 Halide DSL和调度原语,提供了一个优化编译器,为跨硬件后端的深度学习带来了性能可移植性。TVM带来了针对专用硬件加速器的新型调度原语,例如张量化,张量化将计算降到专门的张量到张量硬件指令级别。另外,它还提供了用于显式内存管理的调度原语和降级规则,以便最大限度地提高硬件加速器的资源利用率。
VTA运行时进行 VTA二进制文件(指令流和微内核代码)的 JIT编译,管理共享内存,并执行同步,将执行移交给 VTA。VTA运行时提供了一组在 TVM看来很通用的 API,隐藏了特定于平台的簿记任务的复杂性。它公开了一组可由 TVM模块调用的 C++ API,简化了在未来加入其他硬件加速器的过程,因为可以不需要大幅修改上层的 TVM。
VTA的两级 ISA提供了一个高级的 CISC ISA,用于描述可变延迟操作,如 DMA加载或深度学习操作符,以及一个低级的固定延迟 RISC ISA,用于描述低级的矩阵到矩阵的操作。这种两级 ISA让代码变得更紧凑和更具表述性。
最后,VTA的微架构提供了灵活的深度学习硬件设计规范,可以被方便地编译到其他 FPGA平台上。
Vanilla Tensor Accelerator(VTA)是围绕 GEMM核心而构建的通用深度学习加速器,可进行高吞吐量的密集矩阵乘法操作。它的设计灵感来自主流的深度学习加速器,就像谷歌的 TPU加速器一样。它的设计采用了解耦的访问 -执行机制来隐藏内存访问延迟,并最大化计算资源的利用率。VTA可以作为深度学习加速器的设计模板,为编译器栈提供了一个干净的张量计算抽象。
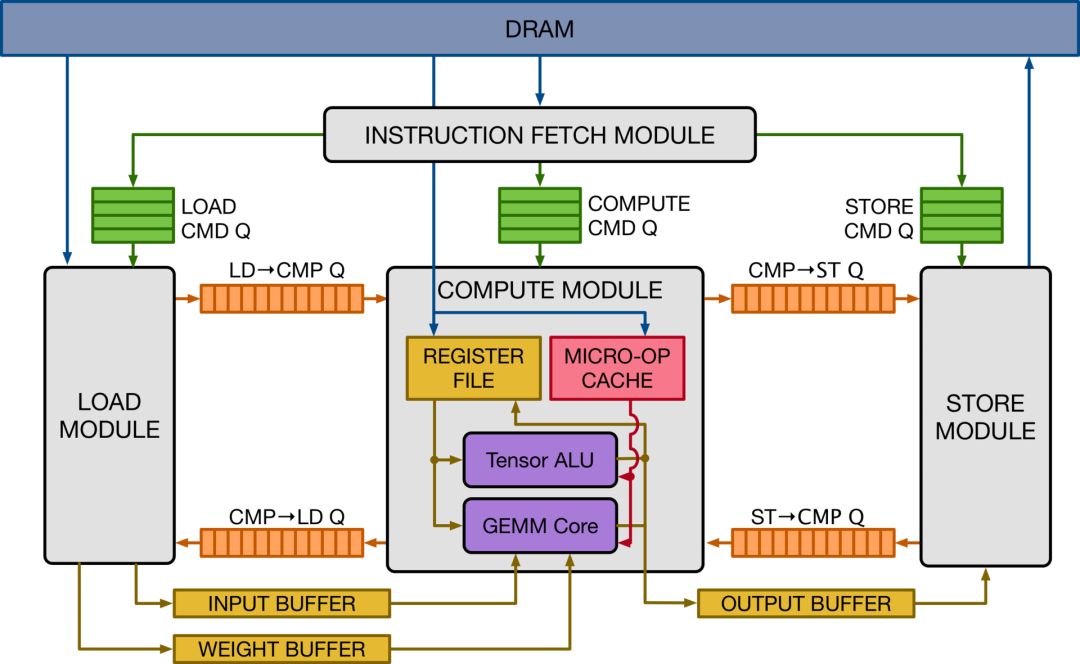
上图是 VTA硬件的高级概览。VTA由四个模块组成,这四个模块通过 FIFO队列和单写入器 /单读取器 SRAM内存块进行通信,以实现任务级的管道并行。计算模块使用 GEMM核心执行密集线性代数计算,并使用张量 ALU执行一般性计算。它直接操作一个寄存器文件,而不是进行标量值的存储,它存储的是等级 1或 2的张量。微操作高速缓存存储的是底层代码,这些代码通过执行一系列操作来修改寄存器文件。
VTA硬件设计模板为用户提供了模块化,可选择修改硬件数据类型、内存架构、GEMM核心维度、硬件操作符和管道阶段。将多个 VTA变体暴露给编译器栈有助于编译器的开发,因为我们可以针对多个硬件加速器测试 TVM的能力。
VTA为用户提供了两种方式来体验硬件加速和以加速器为中心的编译器优化。第一种不需要特殊的硬件,直接在 VTA的行为模拟器上运行深度学习工作负载。开发人员可以很方便地使用这个模拟器后端。第二种方法需要使用现成的低成本 FPGA开发板——Pynq板,它提供了可重配置的 FPGA构造和 ARM SoC。
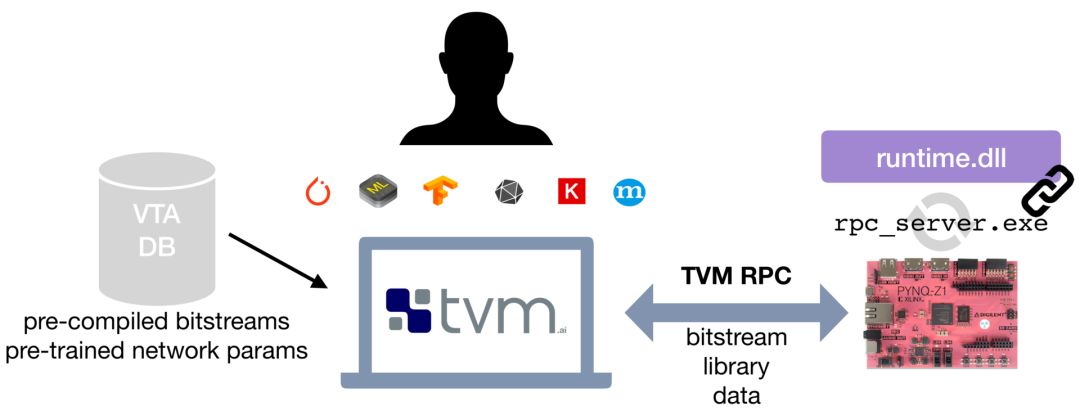
VTA借助 RPC服务器接口,为 Pynq平台提供了简单的 VTA硬件设计和 TVM工作负载的编译和部署流程。RPC服务器负责处理 FPGA重配置任务和 TVM模块调用。VTA运行时系统运行在 Pynq嵌入式系统的 ARM CPU上,并在 FPGA硬件上动态生成 VTA二进制文件。这个完整的解决方案可实现在低成本 FPGA上进行开箱即用的原型设计,并提供了一个交互式的 Python环境,为用户隐藏了大部分 FPGA设计方面的复杂性和麻烦。
对于熟悉硬件和 FPGA的程序员,我们公开了使用 HLS C表示的 VTA设计,并提供了基于 Xilinx工具链构建的脚本,用以将 VTA编译成 FPGA比特流。我们目前正在构建一个 VTA变体的仓库,这样用户就可以针对不同的深度学习工作负载使用不同的变体,而无需经历耗时的 FPGA编译过程。
VTA还处于早期开发阶段,我们期待后续会有更多的性能改进和优化。截至目前,我们提供了基于低成本 Pynq板的端到端性能评估,Pynq板采用了过时的 28nm FPGA构造。虽然该平台主要用于原型设计(FPGA 2012无法与现代 ASIC匹敌),但我们正在致力于将 VTA移植到更新的高性能 FPGA平台,以提供更具竞争力的性能。
用于评估硬件资源利用率的常用方法是顶线图(roofline diagram):在给定硬件设计的情况下,不同的工作负载在计算和内存资源方面的利用率。下面的顶线图显示了在 ResNet-18推断基准不同的卷积层上实现的吞吐量。每层具有不同的算术强度,即计算到数据移动比率。在左半部分,卷积层受限于带宽,而在右半部分,它们受限于计算。
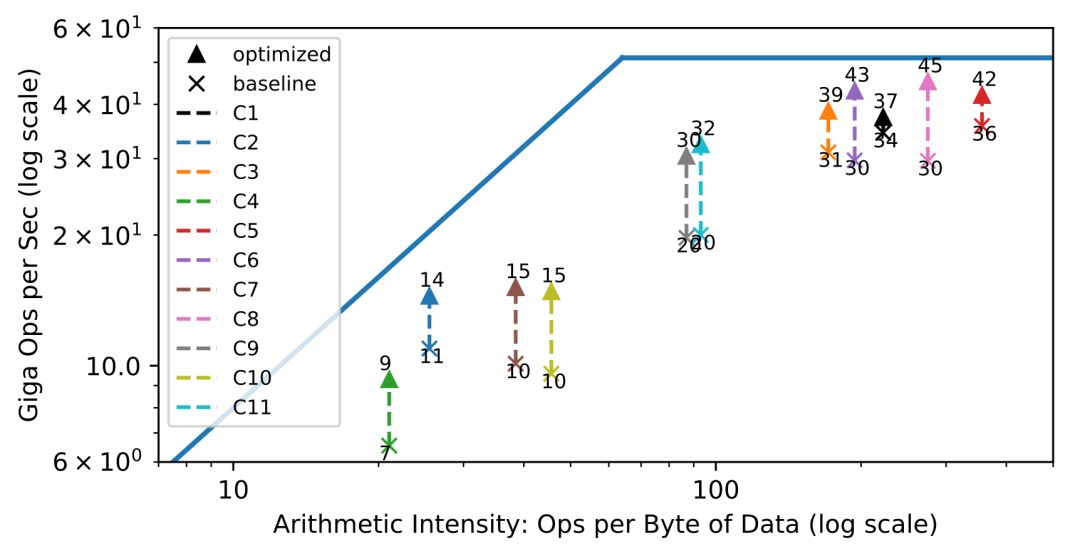
设计硬件架构和编译器栈的目标是让每种工作负载尽可能地接近目标硬件的顶线。顶线图显示了硬件和编译器协同工作以最大限度地利用可用硬件资源的效果。顶线图展示的是延迟隐藏技术,需要在硬件级别进行显式依赖跟踪,需要编译器支持分区工作,需要在代码生成期间在指令流中显式插入依赖。其结果是带来了更高的计算和内存资源的总体利用率。
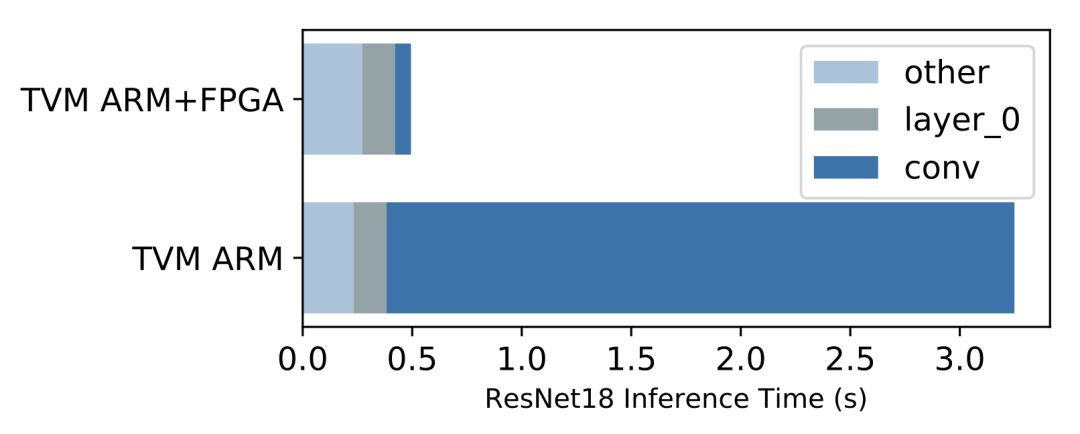
为 VTA构建完整的编译器栈的好处是能够运行端到端工作负载。这在硬件加速器领域是非常具有吸引力的,因为我们需要了解性能瓶颈,以及获得更高性能的安达尔局限性。上面的条形图显示了在 Pynq板的 ARM Cortex A9 SoC上,将 ResNet卷积层装载到基于 FPGA的 VTA上的推理性能以及没有装载到 VTA上的推理性能。结果很明显,VTA实现了它的目标,减少了在 CPU上执行卷积所需的时间(深蓝色)。然而,很明显的是,其他操作也需要装载,因为它们现在成了新的瓶颈所在。对于希望了解系统如何影响端到端性能的系统设计人员而言,这种高级可见性至关重要。
阿里巴巴最新实践:TVM+TensorFlow提高神经机器翻译性能
英文原文:
https://tvm.ai/2018/07/12/vta-release-announcement.html

如果你喜欢这篇文章,或希望看到更多类似优质报道,记得给我留言和点赞哦!