
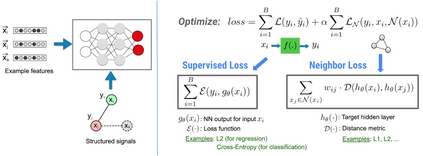
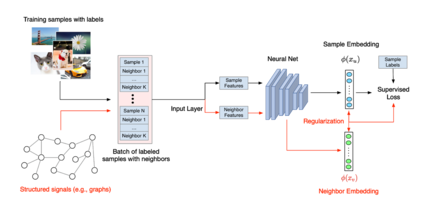
神经结构学习(NSL)是由谷歌推出的一套开源框架,负责利用结构化信号训练深度神经网络。它能够实现神经图学习,使得开发人员得以利用图表训练神经网络。这些图表可以来自多种来源,例如知识图谱、医疗记录、基因组数据或者多模关系(例如图像 - 文本对)等。NSL 还可延伸至对抗学习领域,其中各输入实例间的结构以对抗性扰动方式动态构建而成。
Github: https://github.com/tensorflow/neural-structured-learning
成为VIP会员查看完整内容

相关内容
神经结构学习(NSL)是由谷歌推出的一套开源框架,负责利用结构化信号训练深度神经网络。它能够实现神经图学习,使得开发人员得以利用图表训练神经网络。这些图表可以来自多种来源,例如知识图、医疗记录、基因组数据或者多模关系(例如图像 - 文本对)等。NSL 还可延伸至对抗学习领域,其中各输入实例间的结构以对抗性扰动方式动态构建而成。
专知会员服务
44+阅读 · 2020年6月29日
专知会员服务
20+阅读 · 2020年5月14日


相关VIP内容
专知会员服务
44+阅读 · 2020年6月29日
专知会员服务
20+阅读 · 2020年5月14日
相关资讯