CVPR 2020 | ADSCNet: 自纠正自适应膨胀率计数网络解读

【导读】在CVPR 2020上,商汤智慧交通产品线团队提出的自纠正自适应膨胀率计数网络,针对计数任务中点标注位置不一致和透视现象造成巨大的尺度变化的问题提出了有效的网络设计和监督方法。在监督方式方面,ADSCNet利用网络学习的结果来纠正不一致的人工标注从而更有效的训练;在网络设计方面,ADSCNet提出自适应膨胀率的卷积结构,不同位置采用不同的膨胀率来适应尺度的变化。ADSCNet在四个公开数据集上均有显著的提升。
问题和挑战
a. 由于密集的场景,对于目标多采用点标注的方式,这就带来标注位置不一致的问题,如下图(a)的黄点,点的位置可能在嘴上,眼睛,耳朵等。那么究竟哪里才是更有利于网络学习的位置呢?
b. 如下图(b)在监控的密集的场景下,不但在不同的场景中目标的尺度差异大,而且在同一张图中也有由于透视现象造成目标会有巨大的尺度变化。

方法介绍
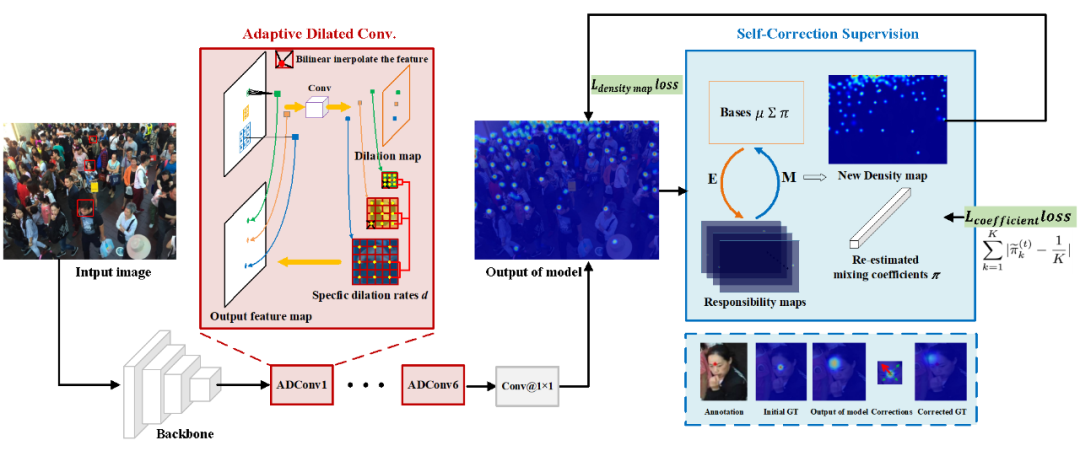
方法:
将高斯密度图看作一个高斯混合模型(GMM):
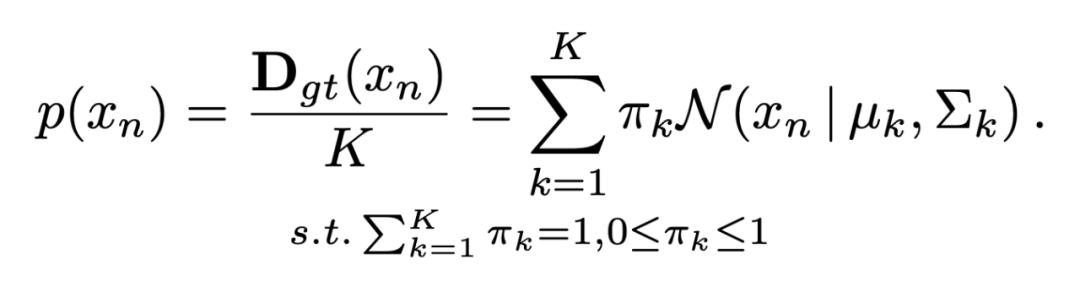
这里可以用人工标注的点作为均值,固定值为方差,生成高斯混合模型的初始分布,而网络预测的密度图可以近似看作网络根据图像特征预测的一个目标分布。我们的方法就是利用网络预测来以一种类似期望值最大化(EM)的方式更新高斯混合模型从而得到适合的标签。
具体方式如下:
E 步骤:

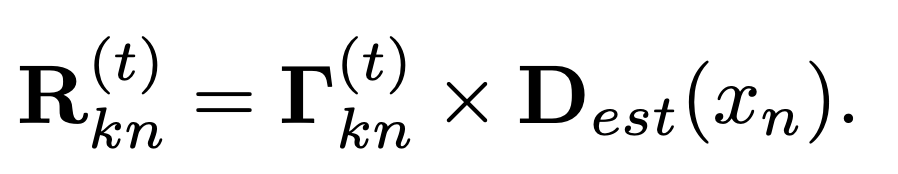
重新估计高斯混合模型的参数
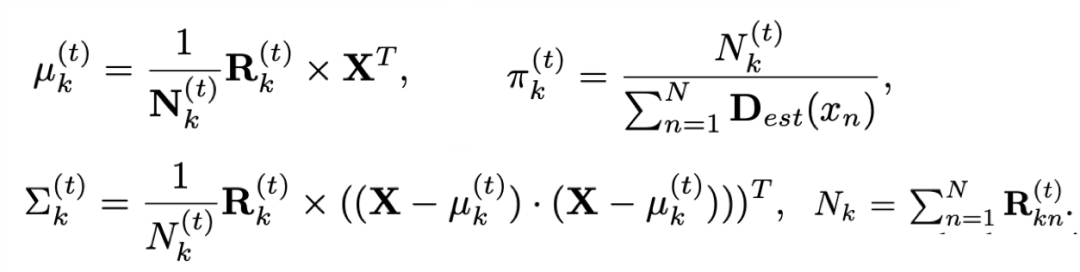
提出的自纠正损失函数包含两个部分,一个部分是直接全图和纠正后密度图比较L1距离,这部分关注整图数量上的误差,第二部分为权重系数的监督,主要关注个体,保证对于整体的贡献一致
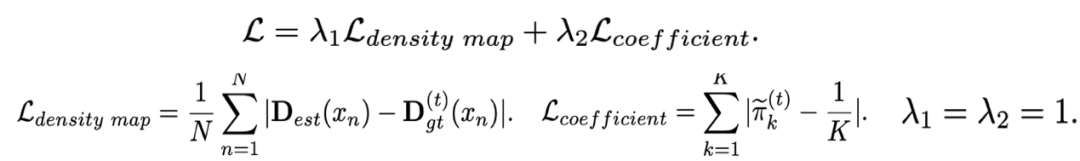

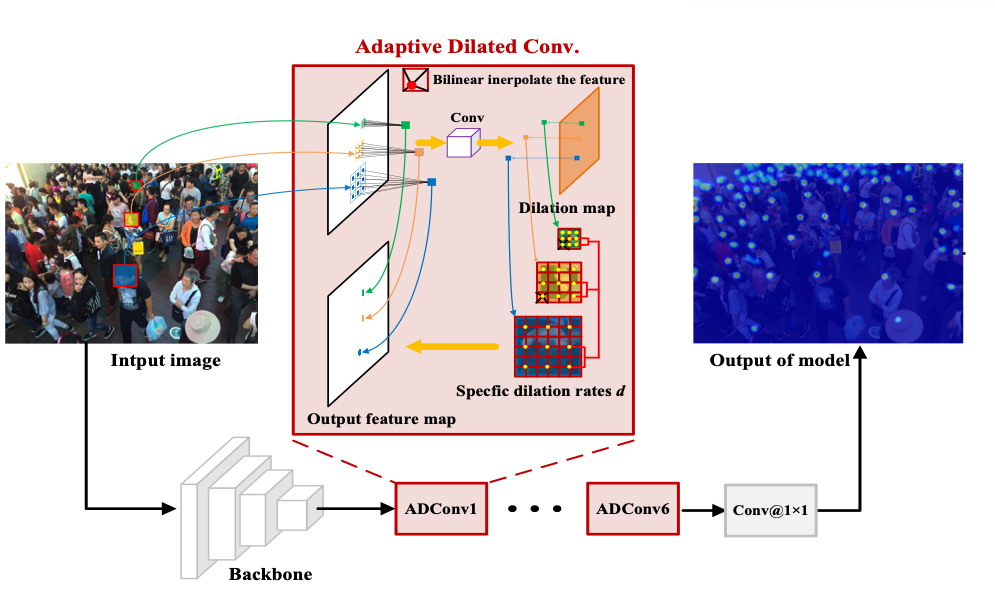
2. 自适应膨胀率网络结构
我们从两个角度设计了自适应膨胀卷积
1) 从尺度变化方面,我们使用连续的感受野也来匹配连续的尺度变化。
2) 为了学习空间感知,不同的位置回采用不同的膨胀率来进行采样。
下图为我们的自适应膨胀卷积的过程:
步骤1:以相同特征为输入,通过标准 3×3 卷积层得到一张与原图相同大小的单通道的膨胀率图。特别地,我们添加了一个 ReLU 层来保证膨胀率图上值都为非负数。
步骤2:对特征进行自适应感受野的采样,不同位置的采样网格大小为膨胀率图对应位置的值,这个值可能会是小数,这里我们采用了双线性插值进行采样
步骤3:对采样值进行加权求和得到新的特征
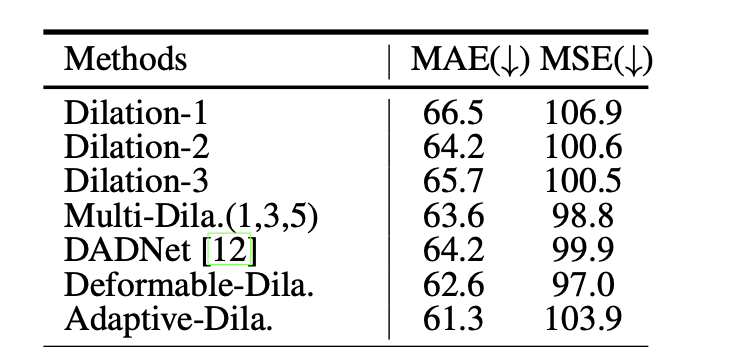
实验结果

同时我们也进行消融实验的对比,首先我尝试了有效的数据增加方式,加入 BN 和增大 batchsize 来确立新的 Baseline。我们这里复现了 CSRNet[2] 和 MCNN[3] 作为 Baseline 方法进行比较,如下图首先是自纠正监督的效果。自适应监督在三个 baseline上取得了一致的提升。 他们相对的 MAE 提升分别为 6.19%,8.57%,8.72%。

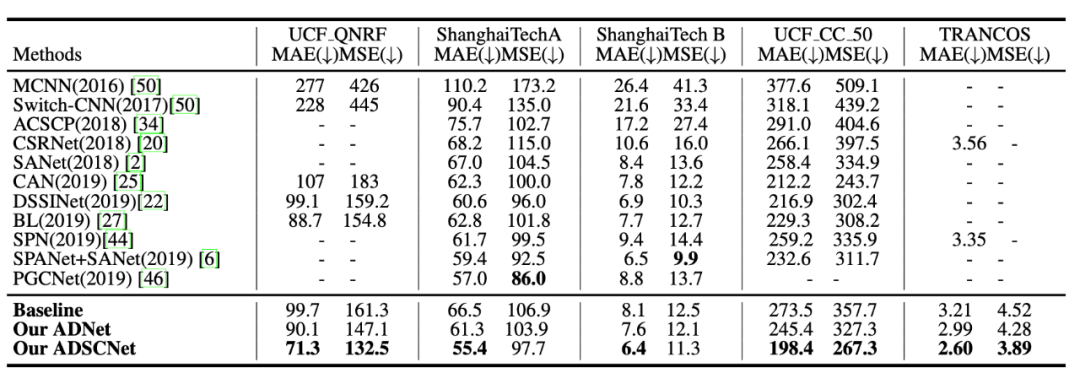
最后和当前 SOTA 的对比,ADSCNet 在四个公开数据集取得更优的表现,并有着明显的提升,表明了我们方法的有效性。
在本文中,我们为计数问题提出了一种新颖的监督学习框架。它利用模型估计来迭代地纠正 GT,并提出自纠正损失函数同时监督整体的数量和个体的分布。同时这种方法可以应用到所有基于 CNN 的方法中。另一方面,我们提出了自适应膨胀卷积,它通过每个位置的动态地学习不同的膨胀率以适应目标巨大的尺度变化。在四个数据集上进行的实验表明,它可以显著提升计数网络的性能。同时也说明了利用模型从图像特征上学习的信息能够被用于纠正标注来提升性能。
References
[1] Dai, Jifeng, et al. Deformable convolutional networks. In ICCV, 2017.
[2] Li, Yuhong, Xiaofan Zhang, and Deming Chen. Csrnet: Dilated convolutional neural networks for understanding the highly congested scenes. In CVPR, 2018.
[3] Zhang, Yingying, et al. Single-image crowd counting via multi-column convolutional neural network. In CVPR, 2016









