专栏 | CVPR 2017论文解读:基于视频的无监督深度和车辆运动估计
机器之心专栏
作者:单乐
本届 CVPR 2017大会上出现了很多值得关注的精彩论文,国内自动驾驶创业公司 Momenta 联合机器之心推出 CVPR 2017 精彩论文解读专栏,本文是此系列专栏的第四篇,介绍了 UC Berkeley 与谷歌在大会上展示的 Oral 论文《Unsupervised Learning of Depth and Ego-Motion from Video》,作者为 Momenta 高级研发工程师单乐。
给定一张图像,人类可以根据以往的视觉经验推断出 3D 景深,而如何让计算机从单张图片推断 3D 结构一直是计算机视觉领域的难点和热点。现有的一些 CNN+Depth 或者 CNN+SLAM 的工作大概可以分为:直接利用深度图进行监督学习,以及利用帧间转移的 ground-truth pose 进行监督学习。然而,这类监督学习的方法需要的数据成本较高,难以获取大规模训练数据。在小数据集上训练,往往导致这些方法在没有见过的场景下并不 work,给人的感觉是 CNN 与深度估计以及 SLAM 的结合都停留在实验室和 paper 上,尤其是自动驾驶场景下面临着复杂多变的道路场景,这些监督学习的方法都不太适用。而今天分享的这篇论文,采用了无监督的方法针对视频数据进行训练,从而对单张图片的深度以及连续帧之间的车辆运动进行估计,可以对大量已知相机内参的视频数据进行训练,为 CNN 在自动驾驶领域的应用带来的新的启发。
这篇论文用视频连续帧的不同视角的几何信息作为监督信号训练了一种端到端的单目图像深度估计和车辆运动估计的 framework,如图 1 所示,包括一个用于单一视角深度估计的 Depth CNN,以及用于连续帧间运动估计的 Pose CNN,通过将当前帧图像结合预测的深度图以及帧间转移投影到临近帧上,计算像素误差作为训练的 loss,对两个网络进行联合训练。预测阶段,两个网络可以独立使用进行推理。在 KITTI 数据集上的评估结果显示,该方法和之前用 ground-truth pose 或者 depth 进行监督的方法性能是相当的,并且运动估计的结果和现有的通用 SLAM 方法性能相当。
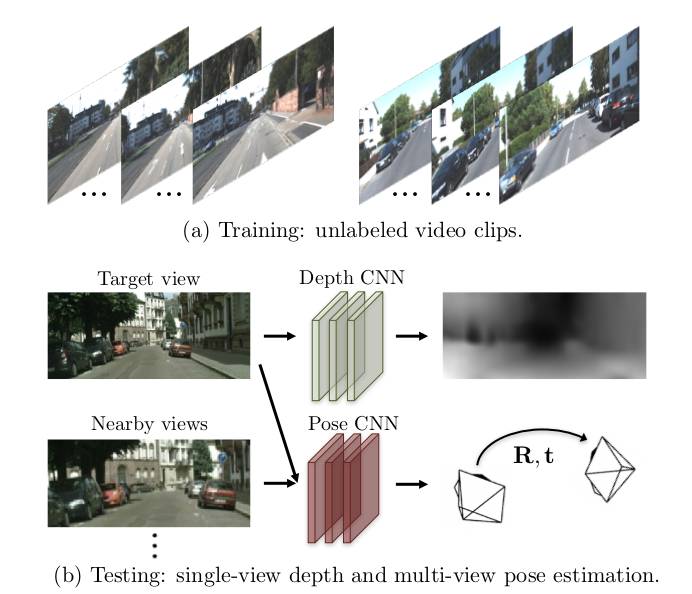
图 1
这种用 multi-view observations 来学习 single-view depth 以及帧间转移的方法是基于预测结果和多视角观察之间的「几何一致性」(geometrically consistent)。个人认为这篇论文的亮点主要在于:1、提出了一种无监督的方法,使网络可以用更多的场景进行训练; 2、显式的使用了 optical-flow 的 pipeline,这样可以保证网络必须同时学到深度估计和帧间转移估计才能使 loss 最小; 3、利用卷积-反卷积的网络结构以及引入了 multi-scale 和 smoothness loss 的机制来解决 gradient locality 的问题; 4、提出了 explainability mask, 用于解决图像中的运动物体以及随视角变化的遮挡情况。
算法介绍
首先介绍该方法的网络框架,如图 2 所示,对于 single-view depth 网络,输入为单张图像,网络结构是在 DispNet 的基础上加上了 multi-scale 的输出。对于 Pose/explainability network,输入为连续帧的切片,网络结构为两个网络共享前几层卷积,预测出 6-DoF 的帧间转移 pose 之后,再进行反卷积,输出不同 scale 的 explainability mask。这种卷积再反卷积的网络结构比较经典,广泛应用于深度预测(Flow-net 等),论文中给出的解释是这种结构有利于梯度传播以及得到全局 smooth 的深度图。值得一提的是论文提出的 explainability mask, 我们知道,这种 warping 图像的方式,如果两帧图像中存在运动物体或者有较大的随视角变化的遮挡情况,那即使利用 ground-truth pose 用于 warping,得到的 loss 也不为 0。explainability mask 就是为了解决这一问题,将 mask 乘在对应尺度的像素误差上,即得到最后的误差。这也会引入另一个问题,即该 mask 为全零时 loss 为 0, 为了解决该问题,通过计算该 mask 与 1 的交叉熵,加入了一个正则项。也就是说,只有在 single-view depth network 输出正确的深度,Pose network 输出了正确的帧间转移,同时 explainability mask 正确的覆盖了运动物体及遮挡区域以及算法无法解释的区域时,网络的 loss 才为最小。
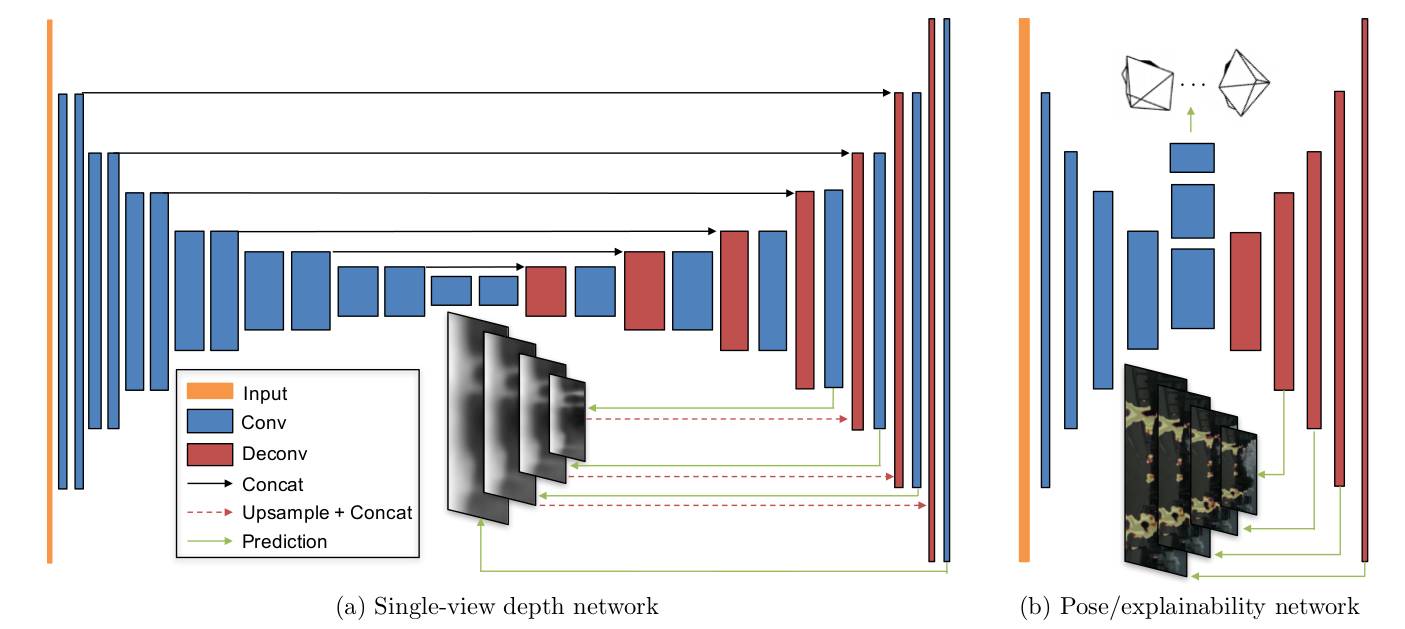
图 2
该方法利用 Cityscapes 及 KITTI 数据集进行训练和评估,性能和之前经典的监督学习方法相当,具体数据不再赘述。值得一提的是,该方法直接在 Make3D 数据集上进行 test,得到的结果也很好,说明该方法在某种程度上可以根据场景布局推理出深度信息。
拓展
从自动驾驶应用的角度来看这篇论文,首先是无监督的方法使大规模的训练成为可能,其次该方法即使 pose 估计的精度不能满足实际应用,但单张图像的深度图也对特征点的选择有很好的指导意义,比如可以筛选掉较远处的特征点,在近处区域提取更多的特征点等。最后,该方法提出的 explainability mask,该 mask 可以解决 SLAM 中的重要问题,即如何滤除场景中的运动物体,并且更近一步的来看,如果该 mask 确实得到了不利与计算帧间转移的图像部分,直接用该 mask 对特征点或者像素点进行筛选,也许能得到很好的效果。
Q & A
在 CVPR 的 poster 环节和作者进行了面对面的交流,以下为我提的问题以及作者的回答。
Q:网络的输出结果并不是真实的深度,缺少尺度信息?看起来网络要学习的任务很多,要学习预测 depth、学习预测帧间转移、学习可解释的 mask,会不会比较难训练?
A:这种无监督的方法的输出是尺度模糊的, 所以并不能得到真实的 depth,我在 SLAM 的相关实验中加入了一个 scale factor。关于网络的训练,code 已经开源,你可以自己试一下。
Q:网络的 loss 中的几个参数会不会对网络的 performance 有很大的影响?应该怎么调节?去掉 explainability mask 对于结果的影响怎么样?
A:网络的 performance 对那几个参数比较敏感,尤其是对最后一个 mask 的参数特别敏感。对不同的数据集,要在 validation 集上进行手动的参数调整。explainability mask 对结果的影响取决于训练的数据集,比如在 KITTI 数据集上,去掉 mask 对结果影响不大。
Q:如果 pose cnn 输出的两帧之间的转移过大时,怎么保证投影点和 match point 距离过远时 loss 仍有意义?
A:这个问题我也发现了,所以在训练时会以很小的帧间转移来初始化 pose cnn。
Q:有没有试过先监督 pose cnn,或者对 depth cnn 进行监督,然后在更大的数据集上进行 fine-tune?有没有在更大的数据集上试过?
A:还没有试过,但是先加上一定的监督肯定会对网络的 performance 有提高。网络训练需要已知内参的视频数据,条件所限,没有在其他数据集上试过。我知道一些做无人驾驶的公司有很丰富的已知内参的视频数据,他们可以尝试一下这种方法。

Momenta CVPR 2017 系列专栏:
本文为机器之心专栏,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com


