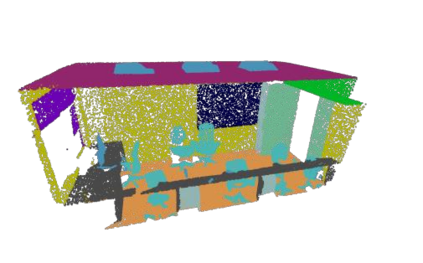
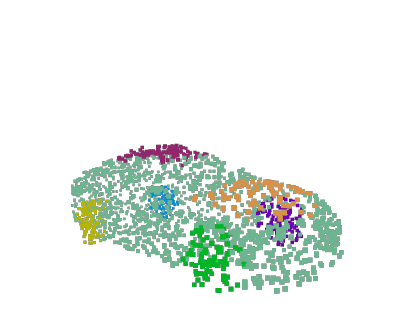
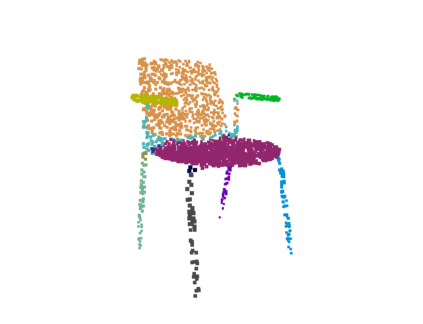A 3D point cloud describes the real scene precisely and intuitively.To date how to segment diversified elements in such an informative 3D scene is rarely discussed. In this paper, we first introduce a simple and flexible framework to segment instances and semantics in point clouds simultaneously. Then, we propose two approaches which make the two tasks take advantage of each other, leading to a win-win situation. Specifically, we make instance segmentation benefit from semantic segmentation through learning semantic-aware point-level instance embedding. Meanwhile, semantic features of the points belonging to the same instance are fused together to make more accurate per-point semantic predictions. Our method largely outperforms the state-of-the-art method in 3D instance segmentation along with a significant improvement in 3D semantic segmentation. Code has been made available at: https://github.com/WXinlong/ASIS.
翻译:3D点云准确和直观地描述真实场景。 到目前为止, 很少讨论如何在如此信息化的 3D 场景中分解多样化元素。 在本文中, 我们首先引入一个简单灵活的框架, 以同时在点云中分解事件和语义。 然后, 我们提出两种方法, 使两个任务相互利用, 导致双赢局面 。 具体地说, 我们通过学习语义识别点级实例嵌入, 使实例分解从语义分解中受益。 与此同时, 属于同一场景的点的语义特征被结合在一起, 以便做出更准确的点语义预测 。 我们的方法在 3D 场分解中基本上优于最先进的语义法, 并在 3D 语义分解中作出重大改进 。 代码已在 https://github. com/ WXinlong/ ASSIS 上公布 。