如何将Numpy加速700倍?用 CuPy 呀
选自towardsdatascience
作为 Python 语言的一个扩展程序库,Numpy 支持大量的维度数组与矩阵运算,为 Python 社区带来了很多帮助。 借助于 Numpy,数据科学家、机器学习实践者和统计学家能够以一种简单高效的方式处理大量的矩阵数据。 那么 Numpy 速度还能提升吗? 本文介绍了如何利用 CuPy 库来加速 Numpy 运算速度。
就其自身来说,Numpy 的速度已经较 Python 有了很大的提升。当你发现 Python 代码运行较慢,尤其出现大量的 for-loops 循环时,通常可以将数据处理移入 Numpy 并实现其向量化最高速度处理。

pip install cupy
i7–8700k CPU
1080 Ti GPU
32 GB of DDR4 3000MHz RAM
CUDA 9.0
import numpy as np
import cupy as cp
import time
### Numpy and CPU
s = time.time()
*x_cpu = np.ones((1000,1000,1000))*
e = time.time()
print(e - s)### CuPy and GPU
s = time.time()
*x_gpu = cp.ones((1000,1000,1000))*
e = time.time()
print(e - s)
### Numpy and CPU
s = time.time()
*x_cpu *= 5*
e = time.time()
print(e - s)### CuPy and GPU
s = time.time()
*x_gpu *= 5*
e = time.time()
print(e - s)
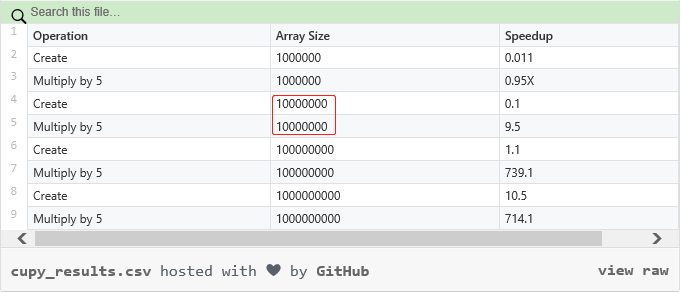
数组乘以 5
数组本身相乘
数组添加到其自身
### Numpy and CPU
s = time.time()
*x_cpu *= 5
x_cpu *= x_cpu
x_cpu += x_cpu*
e = time.time()
print(e - s)### CuPy and GPU
s = time.time()
*x_gpu *= 5
x_gpu *= x_gpu
x_gpu += x_gpu*
e = time.time()
print(e - s)
登录查看更多
相关内容

专知会员服务
35+阅读 · 2020年1月6日
Arxiv
5+阅读 · 2018年4月25日
Arxiv
10+阅读 · 2018年1月29日
相关主题



相关VIP内容
专知会员服务
35+阅读 · 2020年1月6日
相关资讯
相关论文
Arxiv
5+阅读 · 2018年4月25日
Arxiv
10+阅读 · 2018年1月29日