实现基于自然语言的移动端任务自动化
文 / 研究员 Yang Li,Google Research
移动设备为日常活动的完成提供了无限可能,它提供了多种功能来协助或简化我们的日常操作。
但是,对于很多用户来说,其中的大部分功能很难轻松发现或直接上手。这使得用户不得不靠搜索来了解如何执行特定任务。例如,‘如何在地图中打开交通模式’ 或 ‘怎么更改 YouTube 中的通知设置’。
在网络上搜索到这些问题的详细说明很容易,但是用户仍然需要按照这些说明逐步操作,并通过很小的手机触摸屏实现这些繁琐又耗时的操作。这会极大地降低无障碍功能体验。如果可以设计一个计算智能体程序来将这些语言说明转换为各种动作并帮用户自动执行,将会怎样?
在 ACL 2020 上发布的“Mapping Natural Language Instructions to Mobile UI Action Sequences”中,我们提出了解决 自动动作序列映射 (Automatic Action Sequence Mapping) 问题的第一步,同时创建了三个新数据集,用于训练将自然语言说明定位到可执行移动界面操作的深度学习模型。
Mapping Natural Language Instructions to Mobile UI Action Sequences
https://arxiv.org/abs/2005.03776
这项工作为移动端任务自动化奠定了技术基础,从而减轻了通过界面细节进行操作的需求。并且,它对于存在视觉或情境障碍的用户可能特别有用。我们还通过 GitHub 代码库将我们的模型代码和数据流水线开源,以促进这项工作在研究界中的进一步发展。
GitHub 代码库
https://github.com/google-research/google-research/tree/master/seq2act
构建语言定位模型
人们经常相互提供说明建议、彼此协调、共同努力来完成涉及复杂动作序列的任务,例如,按照食谱来烘烤蛋糕,或者让朋友指导建立家庭网络。建立能够帮助进行类似交互的计算智能体是一个重要目标,它需要在动作发生的环境中提供真正的 语言定位 (Symbol Language Grounding)。
此处解决的学习任务包括:在给定一组说明的情况下预测移动平台的动作序列、系统从一个屏幕切换到另一个时生成的屏幕序列以及这些屏幕上的一组交互元素。端到端地训练这种模型需要成对的语言-动作数据,而这难以大规模获取。
我们将问题解构为两个连续的步骤:动作短语提取 (Action Phrase-extraction) 步骤和 定位 (Grounding) 步骤。
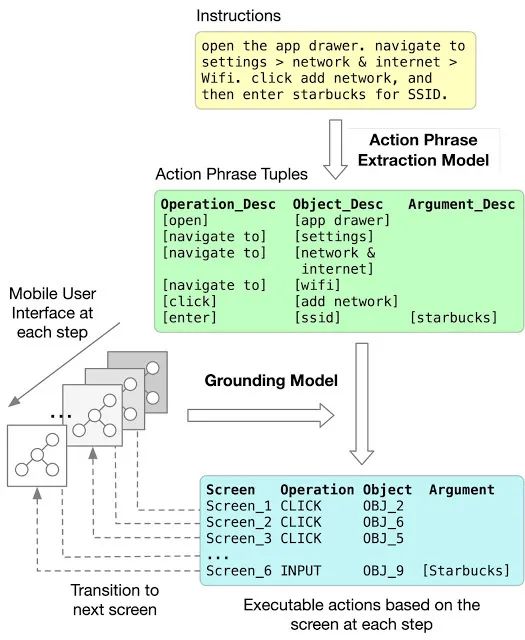
将语言说明定位到可执行动作的工作流
动作短语提取步骤使用支持区域注意力的 Transformer 模型来表示每个描述短语,从多步说明中识别操作、对象和参数描述。借助区域注意力 (Area attention),模型可以从整体上关注说明中的一组相邻单词(跨度,Span),对描述进行解码。
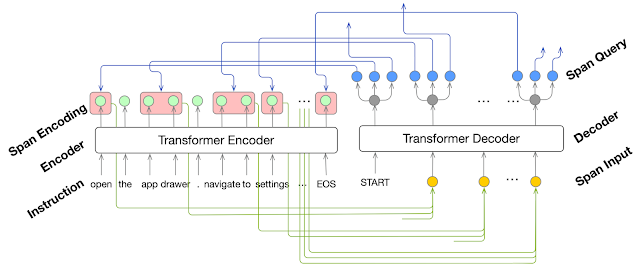
动作短语提取模型录入自然语言说明的单词序列,并输出一系列跨度(Span,用红色框表示),跨度描述了任务中每个动作的操作、对象和参数的短语
接下来,定位步骤将提取的操作和对象描述与屏幕上的 UI 对象进行匹配。我们仍然使用 Transformer 模型,但在这种情况下,它可以在上下文中表示 UI 对象,并将对象描述定位到这些对象。
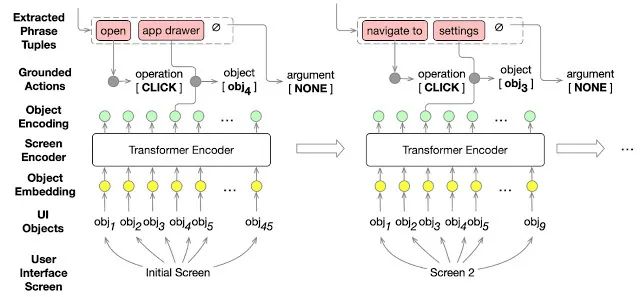
假设执行过程中的每个步骤都有 UI 屏幕,定位模型将提取的跨度作为输入,将其定位到可执行动作(包括施加动作的目标对象)
研究结果
为了研究这项任务的可行性和我们方法的有效性,我们构建了三个新数据集来训练和评估模型。第一个数据集包含用于操作 Pixel 手机完成其相应动作屏幕序列的 187 条多步英语说明,并且能够根据用于测试端到端定位质量的自然发生说明评估整个任务的性能。对于动作短语提取训练和评估,我们获得了可从网络上找到的大量英语“操作方法 (How-to)”说明,并注解了描述每个动作的短语。为了训练定位模型,我们综合生成了 29.5 万个界面动作单步命令,涵盖了公共 Android UI 语料库中 2.5 万个移动 UI 屏幕上的 17.8 万个不同的 UI 对象。
公共 Android UI 语料库
https://dl.acm.org/doi/10.1145/3126594.3126651
支持区域注意力的 Transformer 在预测与定位实况完全匹配的跨度序列时可以获得 85.56% 的准确率。在将语言说明端到端映射到可执行操作这一更具挑战性的任务中,短语提取器和定位模型在匹配定位实况动作序列方面一起获得了 89.21% 的局部准确率和 70.59% 的完全准确率。
我们还评估了 UI 对象的替代方法和表示,例如使用图卷积网络 (GCN) 或前馈网络,并发现当屏幕中对象表示有上下文时能够提高定位准确率。
在解决将自然语言说明定位到移动设备界面动作这一颇具挑战性的难题方面,这些新数据集、模型和结果迈出了重要的第一步。
结论
总的来说,这项研究以及语言定位是在图形用户界面将多步骤说明转换为操作的重要一步。将任务自动化成功应用于 UI 领域能显著提升无障碍功能服务,其中语言界面可以帮助存在视觉障碍的用户使用基于视觉预测的界面来执行任务。在用户因手头任务影响而无法轻松访问设备的情境障碍下,这也十分重要。
通过将问题分解为动作短语进行提取和语言定位,在这两个方面的进展都可以提升任务的整体性能,并降低对难以大规模收集的成对语言-动作数据集的需求。例如,动作跨度提取与语义角色标注和从文本中提取多个事实相关,并且可以从跨度识别和多任务学习的创新中受益。在之前的定位工作中应用的强化学习可能有助于改善 UI 中定位的样本外预测,并通过隐藏状态表示改善直接定位。尽管我们的数据集基于 Android 界面,但我们的方法通常可以应用于在其他界面平台上定位的说明。
最后,我们的工作为研究基于语言的人机交互中的用户体验提供了技术基础。
致谢
非常感谢我的合著者 Jiacong He、Xin Zhou、Yuan Zhang 和 Jason Baldridge 在 Google Research 的这项工作中做出的贡献。还要感谢为创建开源数据集提供慷慨帮助的 Gang Li,以及在注解方面提供大力帮助的 Ashwin Kakarla、Muqthar Mohammad 和 Mohd Majeed。
更多 AI 相关阅读:







