
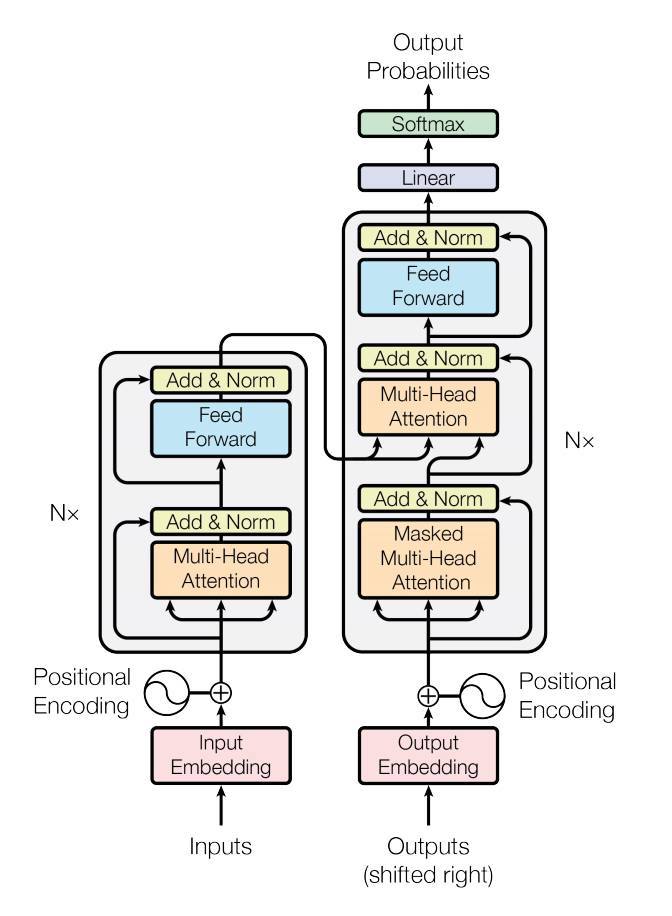
Transformer模型(基于论文《Attention is All You Need》)遵循与标准序列模型相同的一般模式,即从一个序列到另一个序列的注意力模型。
输入语句通过N个编码器层传递,该层为序列中的每个单词/令牌生成输出。解码器关注编码器的输出和它自己的输入(自我注意)来预测下一个单词。
实践证明,该Transformer模型在满足并行性的前提下,对许多顺序-顺序问题具有较好的求解质量。
在这里,我们要做的情感分析,不是顺序到顺序的问题。所以,只使用Transformer编码器。
References Attention Is All You Need
SEQUENCE-TO-SEQUENCE MODELING WITH NN.TRANSFORMER AND TORCHTEXT
Transformer model for language understanding
成为VIP会员查看完整内容
相关内容

Transformer是谷歌发表的论文《Attention Is All You Need》提出一种完全基于Attention的翻译架构
专知会员服务
31+阅读 · 2020年5月20日
专知会员服务
76+阅读 · 2020年1月16日
专知会员服务
84+阅读 · 2019年10月18日
Arxiv
15+阅读 · 2018年10月11日
相关主题

相关VIP内容
专知会员服务
31+阅读 · 2020年5月20日
专知会员服务
76+阅读 · 2020年1月16日
专知会员服务
84+阅读 · 2019年10月18日
相关资讯
相关论文
Arxiv
15+阅读 · 2018年10月11日