一骑绝尘的EfficientNet和EfficientDet
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

作者:张佳程
https://zhuanlan.zhihu.com/p/94576642
本文已由作者授权,未经允许,不得二次转载


EfficientDet还没开源,不过论文里说“Code will be made public”,暴风期待。
EfficientNet
《EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks》,论文传送门:https://arxiv.org/abs/1905.11946
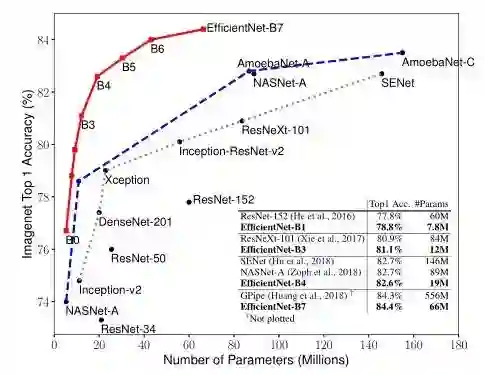
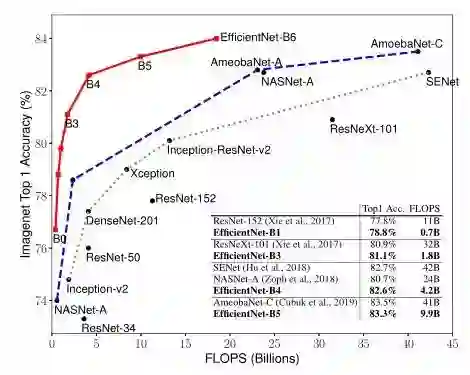
先上对比图吃吃惊。下面两图分别是Model Size vs. ImageNet Accuracy 和 FLOPS vs. ImageNet Accuracy。(作者比的可都是实打实的state of art的模型)
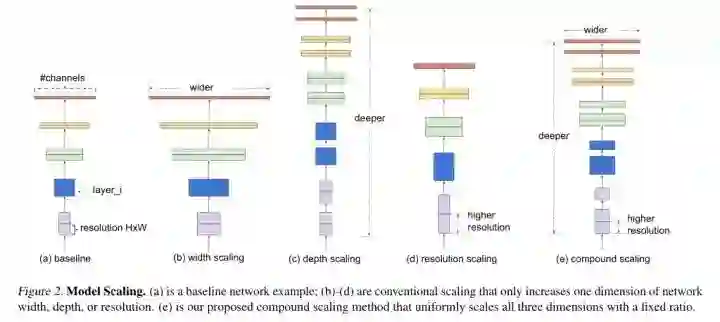
众所周知,扩展(scaling up)神经网络(ConvNets)可以获得更好的精度。一般大家从depth、width、image size三个维度来扩展,且常见做法是只扩展单一维度。那么如何联动地从上述三个维度来scale up ConvNets,同时实现更高的精度和效率呢?这便是作者在文中所讨论的问题。作者提出了compound scaling method( uniformly scales network width, depth, and resolution with a set of fixed scaling coefficients)。下面来康康他怎么做的。
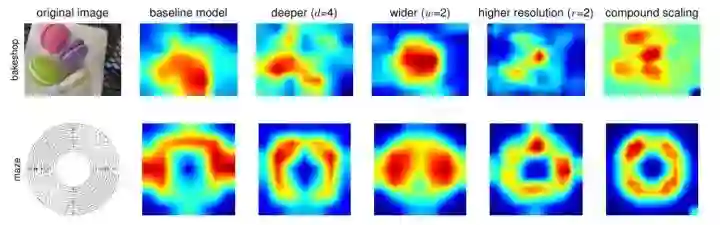
简单解释下Model Scaling。如下图所示,wider是指增加卷积层的通道数;deeper是指增加网络的深度(纵向增加卷积层的数量);higher resolution是指增大输入图片的尺寸。
首先,作者对ConvNets建模:(公式中 




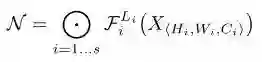
上面提到的三个维度便分别对应:depth( 

optimization problem可以表示为:(式中d, w, r是scaling coefficients)

然后,作者通过对比实验得到如下两点结论:1. 扩展网络宽度,深度或分辨率中的任一维度都可以提高精度,但随着模型的增大,精度增益会降低。2. 为了追求更好的准确性和效率,在ConvNet扩展过程中平衡所有的维度(宽度,深度和分辨率)至关重要。
作者提出了一种复合缩放的方法( compound scaling method ),就是引入一个复合因子 
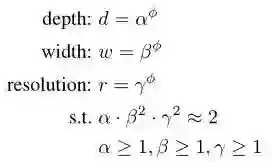
式中, 



作者以MobileNet v2中的MBConv + squeeze-and-excitation optimization作为基本构建模块,利用论文《MnasNet: Platform-aware neural architecture search for mobile》中提出的NAS方法(此处将 
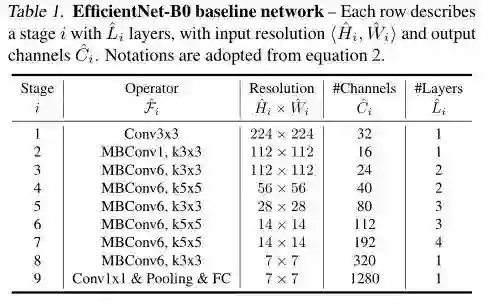
ok,baseline也有了,compound scaling method也有了,接下来就该搜索合适的系数了。分为两步:1. 固定 



实验效果当然是特别好的,下表是EfficientNet在ImageNet数据集上的表现,具有相似top-1/top-5精度的ConvNet被分到一组以进行效率比较:
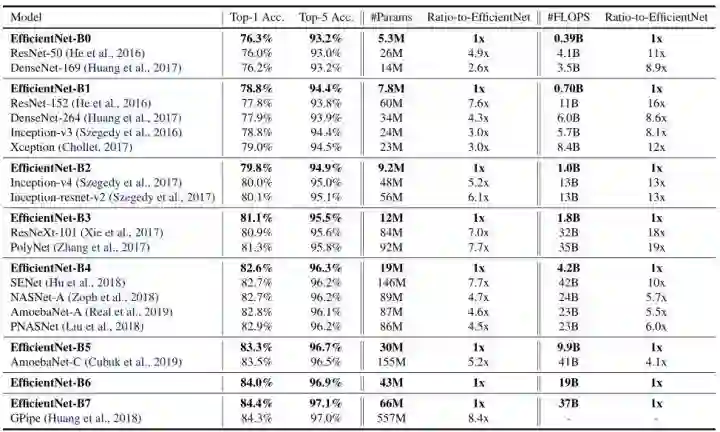
例如:66M parameters,37B FLOPS 的 EfficientNet-B7 达到了84.4% top1 / 97.1% top-5 accuracy,比之前最高精度的GPipe还高,而且比GPipe的参数量小8.4倍。
例如:EfficientNet-B3达到了比ResNeXt-101还高的精度,同时参数量比后者小18倍。
总结:EfficientNet可以利用小一个数量级的参数量和FLOPS,达到之前模型的精度。
另外,作者还做了Scaling Up MobileNets and ResNets、 Transfer Learning Results for EfficientNet的实验,效果都是很不错的,感兴趣的读者可以读下论文。
可视化来定性对比下,绘出模型的Class Activation Map (CAM),可以看到,EfficientNet确实可以专注于具有更多对象细节、更相关的图像区域。
EfficientDet
《EfficientDet: Scalable and Efficient Object Detection》,论文传送门:arxiv.org/abs/1911.09070
依旧先上对比图吃吃惊。下图是Model FLOPS vs COCO accuracy。(作者比的可都是实打实的state of art的模型)
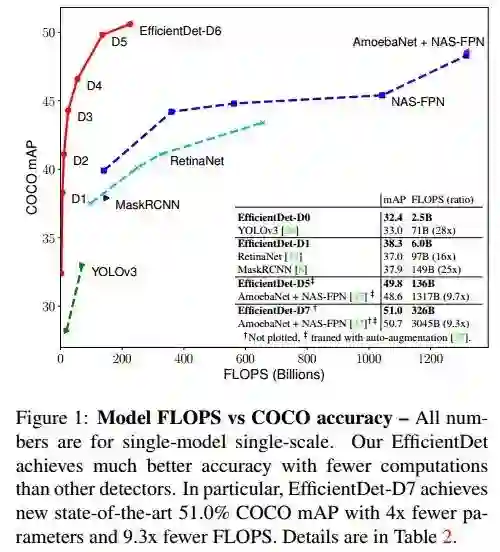
显然,EfficientDet是EfficientNet的延续和发展。作者旨在各种各样的资源限制条件下,构建一系列更高精度、更高效率的scalable detector。一般而言,detector由三部分组成:backbone、feature network和box/class prediction network。作者研究的两个出发点是:寻求高效的多尺度特征融合方式(efficient multi-scale feature fusion)和模型扩展方式(model scaling)。
来看下作者自己总结的三点贡献:
We proposed BiFPN, a weighted bidirectional feature network for easy and fast multi-scale feature fusion.
We proposed a new compound scaling method, which jointly scales up backbone, feature network, box/class network, and resolution, in a principled way.
Based on BiFPN and compound scaling, we developed EfficientDet, a new family of detectors with significantly better accuracy and efficiency across a wide spectrum of resource constraints.
第一步,多尺度特征融合方式。
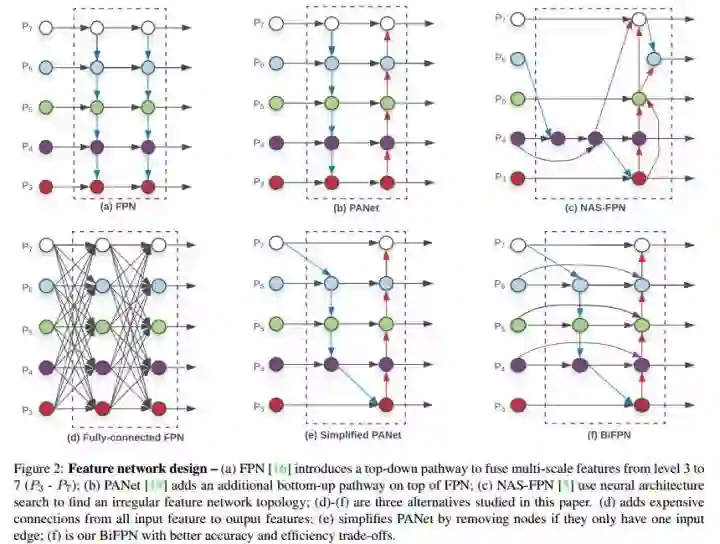
如上图所示,FPN引入了一条自顶向下的通道来融合特征;PANet在FPN基础上增加了一条自底向上的通道;NAS-FPN使用了搜索出来的不规则的拓扑结构。(d)-(f) 是作者所探讨的三种FPN结构的候选。(d)是全连接的FPN;(e)是PANet的一种简化版,去除掉只有一条输入边的结点;(f)是作者最终使用的BiFPN,在(e)的基础上,若输入和输出结点是同一level的,则添加一条额外的边,在不增加cost的同时融合更多的特征。(注意,PANet只有一条top-down path和一条bottom-up path,而本文作者是将BiFPN当作一个feature network layer来用的,重复堆叠它们来获得更高级的特征融合方式)
一般的做法是:不同resolution的特征融合时直接相加,但实际上它们对最后output的贡献是不同的,所以作者希望网络来学习不同输入特征的权重,即weighted feature fusion。作者讨论了三种融合方式:unbounded fusion( 


还有一点值得注意,作者为了提高效率,是用了DW Conv来做特征融合,并在每个卷积层后都添加BN和激活操作。
小结一下本文的多尺度特征融合方式——
FPN的融合方式可以描述为:
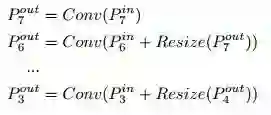
2.BiFPN的融合方式可以描述为:
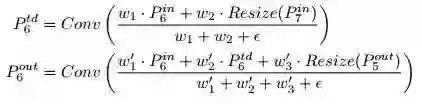
第二步,EfficientDet Architecture。
采用EfficientNet作为backbone;堆叠BiFPN Layer来获得高级别的融合特征;box/class network可以共享所有级别的特征。

第三步,模型扩展。
一般的做法是:为了追求更高的精度,scale up model时希冀于一个更大的backbone,但实际上,scale up feature network和box/class prediction network也是至关重要的。作者提出一种compound scaling method来联动地scale up这三部分,与EfficientNet类似,作者引入一个简单的compound coefficient
backbone:直接采用EfficientNet作为backbone,这样可以利用它们在ImageNet上的预训练权重。
BiFPN network:
,
,即指数增加BiFPN的宽度、线性增加BiFPN的深度。
Box/class prediction network:
,
,即宽度与BiFPN一致、线性增加其深度。
Input image resolution:
,由于下采样7次(2^7=128),所以输入分辨率必须是128的倍数。
 ,
,  ,即指数增加BiFPN的宽度、线性增加BiFPN的深度。
,即指数增加BiFPN的宽度、线性增加BiFPN的深度。 ,
,  ,即宽度与BiFPN一致、线性增加其深度。
,即宽度与BiFPN一致、线性增加其深度。 ,由于下采样7次(2^7=128),所以输入分辨率必须是128的倍数。
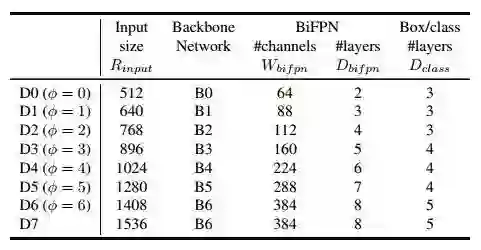
,由于下采样7次(2^7=128),所以输入分辨率必须是128的倍数。利用上面的公式,我们得到了EfficientDet-D0 (φ = 0) to D6 (φ = 6)。作者称φ = 7时,训练时内存不够,除非改变batch size,为了保持一样的training settings,仅扩展输入分辨率来得到EfficientDet-D7。下表是EfficientDet-D0 to D7的配置:
实验效果当然是特别好的,下表是EfficientDet在COCO数据集上的表现,具有相似精度的ConvNet被分到一组以进行效率比较:
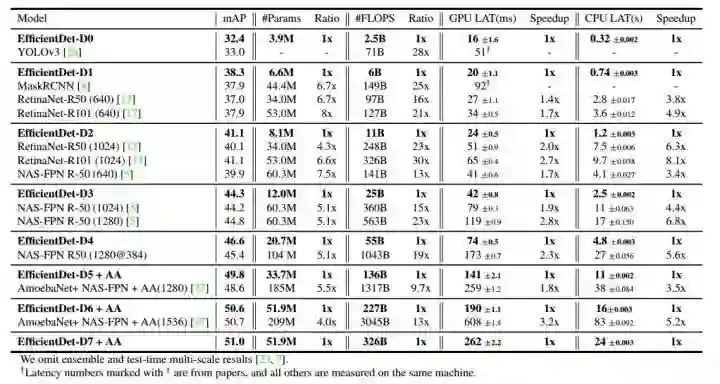
例如:EfficientDet-D0 achieves similar accuracy as YOLOv3 with 28x fewer FLOPS.
例如:Compared to RetinaNet and Mask-RCNN, EfficientDet-D1 achieves similar accuracy with up to 8x fewer parameters and 25x fewer FLOPS.
EfficientDet-D7 achieves a new state-of-the-art 51.0 mAP for single-model single-scale.
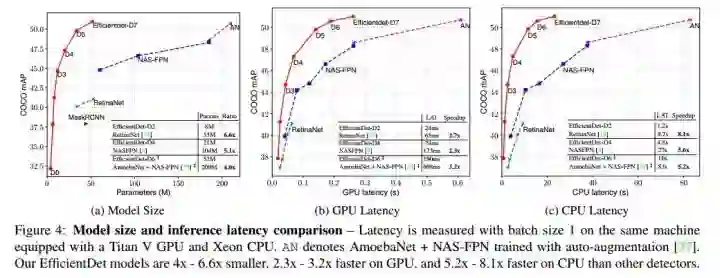
在Titan-V GPU and single-thread Xeon CPU上进行latency的实验,结果如上图。EfficientDet models are up to 3.2x faster on GPU and 8.1x faster on CPU, suggesting they are efficient on real-world hardware.
此外,作者还做了消融实验,来证明EfficientNet、BiFPN、Fast Normalized Fusion和Compound Scaling在EfficientDet中的重要性,感兴趣的读者可以读下论文。
EfficientNet和EfficientDet把数据集指标又刷到了一个新的高度,但我觉得主要的增益还是通过NAS的方法搜出来的,这个方向现在很火,不过感觉也只有大公司有实力去搞吧,毕竟对算力要求太高。这两点也是我给这篇分享起名“一骑绝尘”的原因。之前总说计算机视觉会把一些行业“消灭”,现在来看是不是CVer先把CVer给“消灭”了,哈哈哈。当然是开玩笑,CV领域可做的东西还是有很多的,一起努力吧!
才疏学浅,若有错误,请不吝指出。
推荐阅读
目标检测三大开源神器:Detectron2/mmDetectron/SimpleDet
一文看尽16篇目标检测最新论文(ATSS/MnasFPN/SAPD/CSPNet/DIoU Loss等)
重磅!CVer-目标检测交流群已成立
扫码可添加CVer助手,可申请加入CVer大群和细分方向群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索等群。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加群

▲长按关注我们
麻烦给我一个在看!