
【导读】现实应用中,不同硬件很多,对于IoT设备、以及FPGA、GPU和CPU的搜索结果的是不一样的。如果对于每一个硬件都需要重新训练并且重新搜索的话,是非常昂贵的,所以为了降低搜索成本,MIT韩松博士等学者提出一次训练一个Once for All(一劳永逸)的网络,可以从这个网络中抽取不同的子网络,定制到不同的硬件上,这样就做到了只需要训练一次,极大降低NAS的搜索成本。对很多IoT设备以及不同的手机,包括LG的手机、三星的手机、Google的手机,都定制了不同的网络,定制的开销是非常低的,无论是延迟还是准确率都全面超越了EfficientNet和MobileNetV3。
韩松博士在ICLR-NAS论坛做了报告,64页PPT详细讲述了Once-for-All Network.

地址:
https://sites.google.com/view/nas2020
训练和搜索来训练一个支持多种架构设置的一次性网络(OFA)。通过从OFA网络中进行选择,不需要额外的训练,就可以快速地得到一个专门的子网络。我们还提出了一种新的渐进式缩减算法,一种广义剪枝方法,它比剪枝方法(深度、宽度、内核大小和分辨率)在更多的维度上减少模型大小,从而可以获得数量惊人的子网络(> 1019),这些子网络可以适应不同的延迟约束。在边缘设备上,OFA始终优于SOTA NAS方法(与MobileNetV3相比,ImageNet top1精度提高了4.0%,或与MobileNetV3相同的精度,但比MobileNetV3快1.5倍,比有效净w.r快2.6倍)。减少了许多数量级的GPU时间和二氧化碳排放。特别是,OFA在移动设置(<600M MACs)下实现了新的SOTA 80.0% ImageNet top1精度。OFA是第四届低功耗计算机视觉挑战的获奖方案,包括分类跟踪和检测跟踪。
韩松 本科毕业于清华大学,博士毕业于斯坦福大学,师从 NVIDIA 首席科学家 Bill Dally 教授。他的研究也广泛涉足深度学习和计算机体系结构,他提出的 Deep Compression 模型压缩技术曾获得 ICLR'16 最佳论文,ESE 稀疏神经网络推理引擎获得 FPGA'17 最佳论文,对AI算法在移动端的高效部署影响深远。他的研究成果在 Xilinx、NVIDIA、Facebook、Samsung 得到广泛应用。韩松在博士期间与同为清华大学毕业的汪玉、姚颂联合创立了深鉴科技(DeePhi Tech),其核心技术之一为神经网络压缩算法,随后深鉴科技被美国半导体公司赛灵思收购。2018 年,韩松加入MIT担任助理教授,入选2019年度麻省理工科技评论35 Innovators under 35,并在2020年获得NSF CAREER Award。
ICLR 2020论文 Once for All: Train One Network and Specialize it for Efficient Deployment
作者:Han Cai、Chuang Gan、Song Han 论文链接:https://arxiv.org/pdf/1908.09791.pdf
将神经网络部署在各种硬件平台时,不同的部署场景需要匹配的网络架构,同时网络还要尽可能精简。传统的做法是手动设计、或者使用 AutoML 搜索网络架构,之后针对每个不同网络重新进行训练。这样的做法成本很高,也不具有扩展性。随着需要部署的环境数量增加,这种做法的成本呈线性上升。本文提出了一种名为「一次构建、处处部署(Once for all:OFA)」的方法,可以高效设计神经网络架构,并同时处理多种部署情况。研究人员的方法摒弃了给每一种情况设计一个专门模型的做法,而是提出训练一个网络,支持多种架构设定(网络深度、宽度、核大小和清晰度等)。给定部署场景后,网络可以搜索出一个特定的子网络。这个子网络是从原始网络中搜索出来的,而且不需要训练。
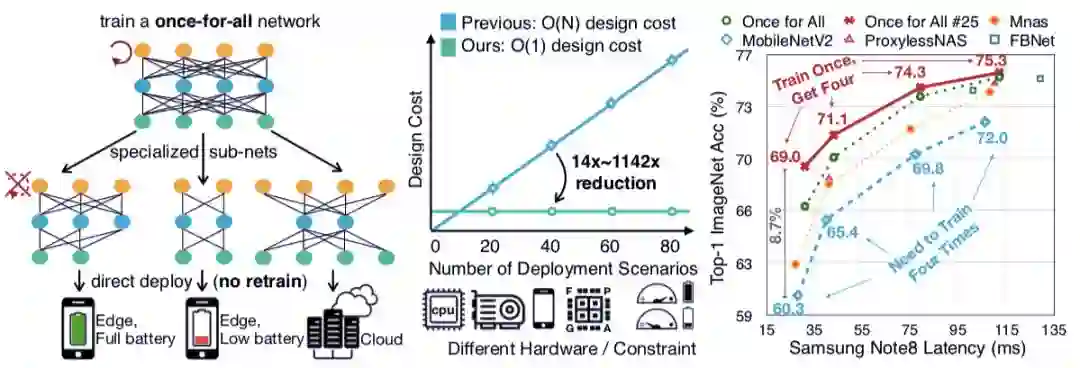
图 1:左图:当训练了一个网络后,根据部署条件的不同,从该网络中搜索出一个子网络。中图:这样的搜索方法的设计成本从 O(N) 降低到了 O(1)。右图:相比其他网络,论文提出的方法能够在降低延迟的情况下更好地提升效果。
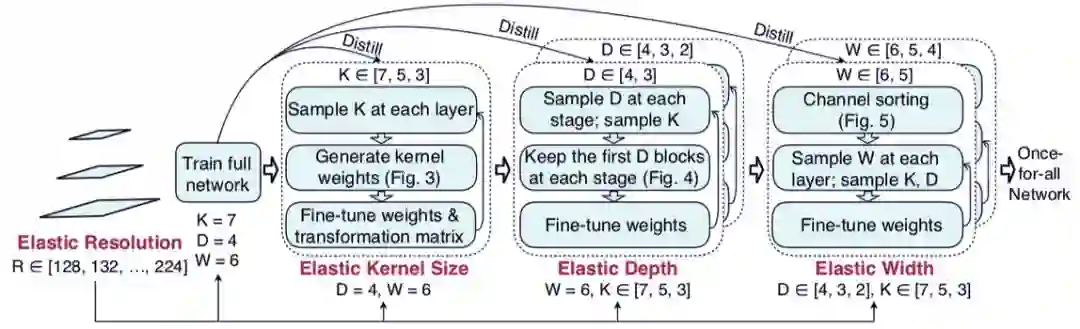
图 2:阶段性缩减流程示意。
