赛尔原创@ACL 2021 | 事理图谱知识增强的溯因推理
论文名称:Learning Event Graph Knowledge for Abductive Reasoning 论文作者:杜理,丁效,刘挺,秦兵 原创作者:杜理,丁效 转载须标注出处:哈工大SCIR
1. 简介
溯因推理指为观测事件找到最合理解释事件的过程。这一推理范式对于多种NLP任务具有重要意义,例如QA,阅读理解等。针对此,研究者提出了一个基于叙事文本的溯因推理数据集 NLI,并探索利用了预训练语言模型以进行溯因推理。但是,预训练语言模型中仍然缺乏溯因推理所必须的部分事件关系信息。为此,我们提出了一个基于变分自编码器的事理图谱知识增强的预训练语言模型ege-RoBERTa。该模型利用一个额外的隐变量,以捕获必要的事理图谱知识。实验结果显示,该模型相比于基线方法能够有效提高溯因推理的性能。此外,该模型还具有较强的灵活性,可有效结合多种事理图谱知识,并适用于多种事件相关推理任务。
2.动机
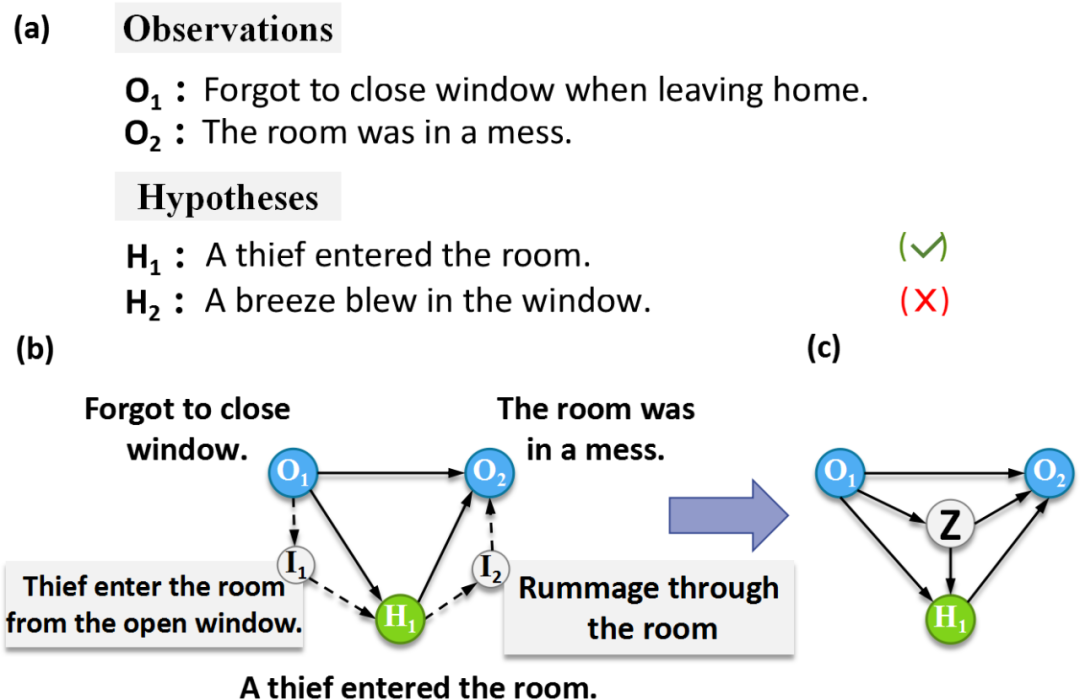
图1 (a) 溯因推理任务的一个例子。(b) 额外的常识知识(如事件 、 )有助于进行事件推理。此类常识知识可以用一事理图谱描述。(c) 我们引入一隐变量以学习此类知识。
溯因推理任务指为已观测事件寻找最合适解释的过程。例如,如图1 (a)所示,给定已观测事件 与 ,溯因推理任务要求模型从候选项中选择出观测事件的合理解释,如 。早期研究多局限于基于符号逻辑的溯因推理。然而,符号逻辑的僵硬特点使得其难以应用于基于自然语言形式的文本推理任务中。为方便相关研究,Bhagavatula等人 (2019) 提出了一个相应数据集 NLI和对应任务。图1 (a)给出了 NLI数据集中的一个例子。
在提出数据集的同时,Bhagavatula等人[1] 探索了利用预训练语言模型,如RoBERTa等[2],以及知识图谱增强的模型,如ERNIE[3] 等进行该任务。但是,虽然语言知识以及知识图谱信息有助于理解事件语义本身,溯因推理任务仍有赖于对于事件间关系的深入理解。例如,如图1所示,给定已观测事件 和 ,为选出合适的解释事件 A thief entered the room并排除错误的 A breeze blew in the window,模型需要知道风无法使得屋内变乱,反之贼可以从窗户进来 ( ),并在屋内翻找财物 ( ),从而使得屋内一团糟。
我们注意到这些中间事件( 和 )与 , , 一并构成了一个事理图谱。因而挑战在于如何有效学习这个事理图谱知识,并用于事件推理。为此,我们构建了一个事理图谱,并提出了一个事理图谱增强的RoBERTa模型ege-RoBERTa和相应的两阶段训练过程,以有效学习事理图谱知识。如图1 (c)所示,ege-RoBERTa引入了一个额外的隐变量 以建模额外的事理图谱知识。在预训练过程中,ege-RoBERTa模型在事理图谱相关的预训练数据集上利用隐变量 学习事理图谱知识。随后的微调阶段ege-RoBERTa模型学习将捕获的事理图谱知识迁移至 NLI任务上。
3.背景
3.1 问题定义
如图1 (a)所示, NLI数据集定义的溯因推理任务可以被视为一个多项选择问题:给定已观测事件 和 (其中 发生于 之前),模型需要从两个候选的解释事件 和 中选出一个更加合理的解释事件。在 NLI数据集数据集中, 被限制在发生与 和 之间。因而,我们进一步将该问题形式化为一个条件分布 ,其中 是由 构成的一个事件序列, 是一个分数以衡量该事件序列 的合理性。
3.2 事理图谱
我们将事理图谱 形式化为 ,其中 为节点集合, 为边集合。每个节点 对应一个事件 ,每条边 则对应于从事件 指向事件 的一条边。每条边带有一权重 。其中 代表 是 的后续事件的概率。给定 , 和 ,从事理图谱中我们可能获得额外的两类常识:(1) 中间事件 与 ;(2) 间的邻接关系。我们称 构成的事件序列为后验事件序列,并将其记作 ,将从事理图谱中初始化的描述 间邻接关系的矩阵记作
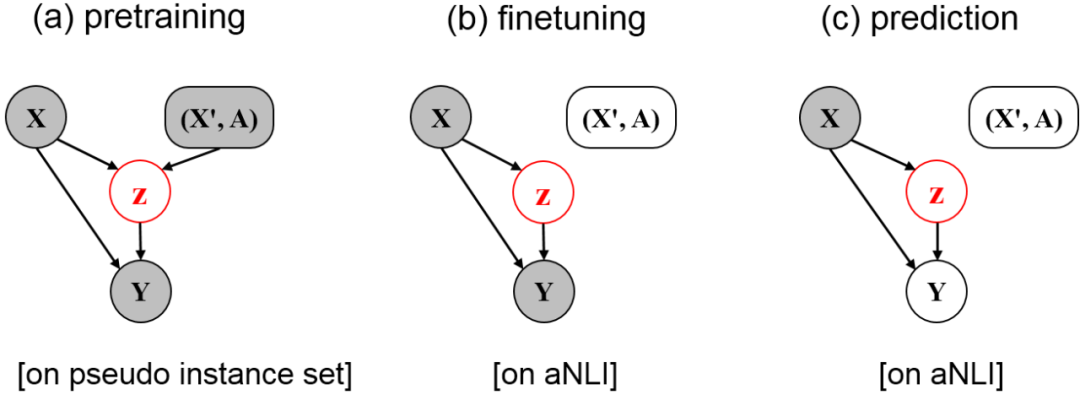
图2 ege-RoBERTa模型预训练、微调、预测过程的示意图。灰色圈代表已知信息。例如,预训练过程中,
和
为已知信息。然而在微调过程中,
和
未知。
4. ege-RoBERTa:基于条件变分自编码器的推理框架
为有效学习事理图谱知识并服务于溯因推理任务,我们引入了一个额外的隐变量 。在 的存在下,ege-RoBERTa以如下的三个模块刻画条件分布 :(1) Prior Network (2) Recognition Network (3) Neural Likelihood 。进一步,类似于经典条件变分自编码器(Conditional Variational Autoencoder),我们选择最大化 的证据下界,而非直接优化 本身:
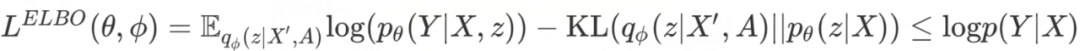
值得注意的是,在我们的框架中Recognition Network是直接以后验事件序列 和邻接矩阵 为条件的。这使得 能够直接接收到 中包含的中间证据事件信息,以及 中包含的事件邻接关系信息。从而,通过最小化KL项,Recognition Network中包含的事理图谱知识得以被直接传递至Prior Network。通过结合 与 以预测 ,我们得以利用 中包含的事理图谱信息进行溯因推理。
4.1 两阶段训练过程
预训练阶段 这一阶段模型在伪数据集上学习事理图谱知识。如图2所示,此时隐变量 可直接接收到关于 和 的信息。
微调阶段 这一阶段ege-RoBERTa模型在 NLI数据集上进行微调,以学习利用 捕获的事理图谱信息服务于溯因推理任务。
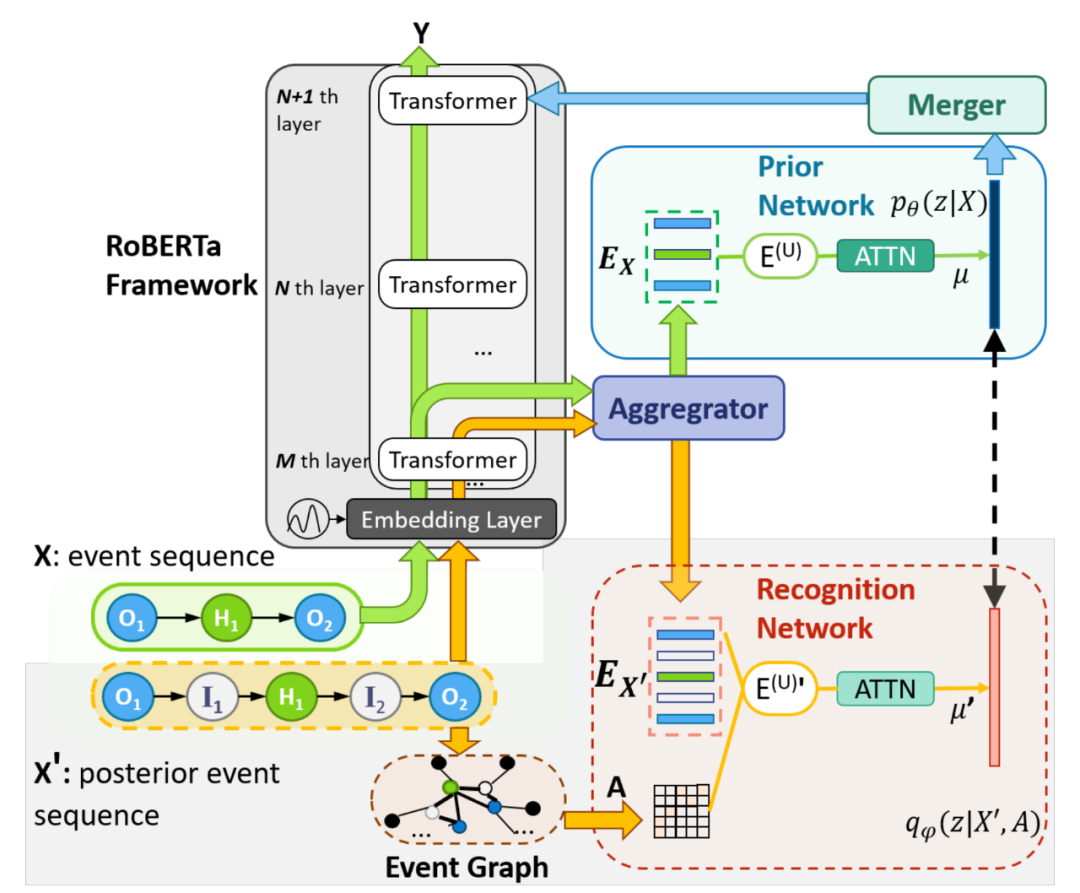
图3 ege-RoBERTa模型架构
5. ege-RoBERTa:模型架构
如图3所示,在RoBERTa模型的基础之上,ege-RoBERTa模型引入了四个额外模块以有效捕获事件知识。其中,Aggregator用以从RoBERTa的隐含状态中获得事件的向量表示,Prior Network用以建模 ,Recognition Network用以建模 ,Merger用以将隐变量 合并至RoBERTa模型中以服务于溯因推理任务。
Aggregator
Aggregator模块用以从RoBERTa的隐含状态中获得事件序列 以及后验事件序列 中各个事件的向量表示。具体而言,给定事件序列 所对应的一系列token [[CLS], ( ,..., ),...,( ,\dots, )] (其中[CLS]为一特殊token),RoBERTa模型的第 层Transformer可以将这一系列token编码至稠密向量 , ( ,..., ),..., ,..., )] 。从而,对于 中任一事件 ,我们以如下方式获得其表示向量: 。随后,我们利用多头注意力机制以基于这些节点的初始表示,从RoBERTa的隐含状态中选取相关信息,并得到节点表示矩阵 :
对于 中包含的一系列事件,我们均可以按照同样方式得到其表示向量。将这些事件的向量表示组成一个表示矩阵 。按照类似的方式,我们同样可以获得由后验事件序列 中各个事件的向量化表示构成的表示矩阵 。
Recognition Network
Recognition Network利用 的表示矩阵 和邻接矩阵 为基础建模 。类似于经典VAE结构,我们假设 服从一正态分布:
为得到 ,我们希望首先融合 和 。具体而言:
随后,我们引入一个额外的自注意力操作,以促进事件表示与邻接关系信息的融合:
最后,我们利用一个平均池化操作以从 中得到 :
因此, 得以能够包含有关于 与 的信息。
Prior Network
Prior Network以 中事件的表示矩阵 为基础建模 。与Recognition Network情况类似, 也为一正态分布:
而不同于Recognition Network下的情形,Prior Network中事件表示矩阵 仅通过一自注意力机制升级:
随后,使用一个自注意力操作以得到事件的深度表示:
最后,为估计 ,我们同样利用平均池化汇集 中的信息:
Merger
Merger模块将隐变量 中蕴含的有关于事理图谱的相关知识融入RoBERTa模型中。具体而言,我们基于多头注意力机制从 和 中选取相关信息。具体而言,在训练过程中:
其中 是RoBERTa中的第 层transformer。
而在微调和预测过程中:
因而,通过将 作为后续transformer层的输入,ege-RoBERTa模型得以利用 中捕获的事理图谱知识以支撑溯因推理过程。
5. 实验
5.1 事理图谱与伪样本的构建
我们基于ROCStory[4]、VIST[5]和TimeTravel[6]这三个短故事数据集构建了事理图谱。数据集中每个短故事均由5句话组成。数据集中每个短故事的每个句子被视作事理图谱中的一个节点。为了得到两个事件间的转移概率 ,我们在这三个故事数据集上通过Next Sentence Prediction任务微调了一个额外的RoBERTa模型。因而,给定任意两个事件 和 ,该微调后的RoBERTa模型能够输出 是 的后续事件的概率。
进一步,在短故事数据集上,我们构建了一个伪数据集用以预训练ege-RoBERTa模型。伪数据集中的每个样本由一个短故事而来。我们将短故事的第1句、第5句定义为观测事件 和 ,将第3句定义为观测事件 ,将第2、4句定义为中间事件 和 。图4给出了一个例子。

图4 伪样本的构建
5.2 实验结果
表1 NLI测试集上模型的准确率
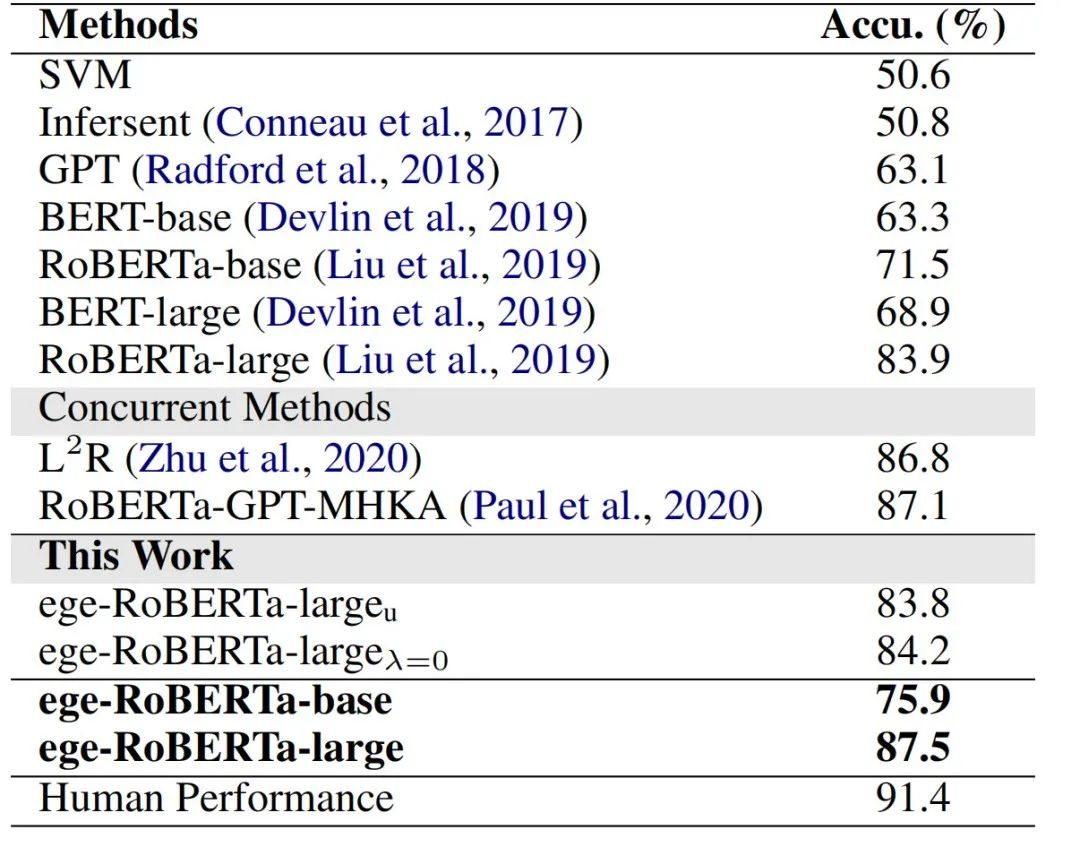
我们在溯因推理数据集 NLI[1]上进行了实验。基线模型及本文提出的ege-RoBERTa的表现见表1。从中我们可以得出如下结论:
(1) 相比于SVM和InferSent,基于预训练语言模型的一系列方法ESIM+ELMo, GPT, BERT, RoBERTa和ege-RoBERTa显著较优。这是因为预训练过程中捕获的语言学知识有助于理解事件语义。
(2) 将ege-RoBERTa-large 与ege-RoBERTa-large进行比较可以发现,预训练过程有助于溯因推理性能提高。进一步,比较ege-RoBERTa-large 与ege-RoBERTa-large显示,预训练过程中ege-RoBERTa-large可能可以捕获事理图谱知识,并运用之以增强溯因推理表现。而ege-RoBERTa-large 与ege-RoBERTa-large 的相近性能则提示ege-RoBERTa-large的主要性能提升是来自于预训练过程中捕获的事理图谱知识。
(3) 相比于RoBERTa, ege-RoBERTa在两个尺寸的模型中均取得了性能的提升。这说明事理图谱知识对于溯因推理任务的助益。
(4) 人类在 NLI数据集上的表现是91.4%[1]。这暗示后续性能提升的困难程度。然而此前的SOTA baseline模型RoBERTa-large表现已达 83.9%. 因而,在RoBERTa-large基础上的提升是具有挑战性的。本文中,通过引入事理图谱知识,我们提出的ege-RoBERTa将准确率进一步提升至87.5%.
(5) 此前的SOTA方法RoBERTa-GPT-MHKA在RoBERTa基础上,引入了GPT2中蕴含的信息,以及有关于社会生活以及人类情感的常识。相比于RoBERTa-GPT-MHKA,我们的方法取得了可比的预测准确率。后续将两者的结合将有可能进一步提升其结果。
案例分析
表2 利用ege-RoBERTa与RoBERTa进行溯因推理结果的案例

表2提供了一个溯因推理结果的案例。给定已观测事件
I hate fall与
became happier because didn’t have to experience Fall in Guam, 合理的解释事件是
: moved to Guam. 然而,
作为合理解释建立在一个隐含的前提之上,即在Guam,秋天能够被规避开。如表1所示,事理图谱中的事件
提供了这一信息。对于这个例子,ege-RoBERTa做出了正确的判断,而RoBERTa选择了错误的答案。这显示ege-RoBERTa能够有效学习事理图谱相关知识,并用于溯因推理任务。
6. 讨论
表3 不同后验事件序列设置下ege-RoBERTa模型进行溯因推理的性能

前文中,为引入事理图谱知识,我们将后验事件序列的形式设置为 。事实上,我们的模型支持多种后验事件序列的形式,以适应于多种情况的数据。表3展示了一系列后验事件序列的形式与相应的溯因推理性能。此外,通过设置不同的后验事件序列的形式,ege-RoBERTa还能够引入多种事件相关信息。例如,通过将后验事件序列设置为如下形式:,其中 为事件序列 的背景事件序列,ege-RoBERTa能够引入事件背景知识。类似地,还可引入事件结局信息等等。这显示了ege-RoBERTa的灵活性。
7. 总结
针对溯因推理任务,本文提出了一个基于变分自编码器的事理图谱知识增强的语言模型,和相应的两阶段训练过程。在预训练阶段,ege-RoBERTa利用额外的隐变量捕获两类事理图谱知识。从而,在微调阶段,将已捕获的事理图谱知识适应与溯因推理任务。实验结果显示,模型取得了相对于基线方法的提升。
参考文献
[1]. Bhagavatula C, Le Bras R, Malaviya C, et al. Abductive Commonsense Reasoning[C]//International Conference on Learning Representations. 2019.
[2]. Liu Y, Ott M, Goyal N, et al. RoBERTa: A Robustly Optimized BERT Pretraining Approach[J]. 2019.
[3]. Zhang Z, Han X, Liu Z, et al. ERNIE: Enhanced Language Representation with Informative Entities[C]//Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019: 1441-1451.
[4]. Mostafazadeh N, Chambers N, He X, et al. A corpus and cloze evaluation for deeper understanding of commonsense stories[C]//Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2016: 839-849.
[5]. Huang T H, Ferraro F, Mostafazadeh N, et al. Visual storytelling[C]//Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2016: 1233-1239.
[6]. Qin L, Bosselut A, Holtzman A, et al. Counterfactual Story Reasoning and Generation[C]//Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019: 5046-5056.
长按下图即可关注哈尔滨工业大学社会计算与信息检索研究中心微信公众号『哈工大SCIR』。