MLSys 2020 | 支撑亿级终端设备,阿里淘系端上开源推理引擎MNN解读
机器之心编辑部
阿里巴巴有诸多的复杂端智能业务场景,对于深度学习引擎的性能、包大小、普适性都要很高的要求。在这样的背景下,阿里巴巴自研的端上推理引擎 MNN 应运而生。
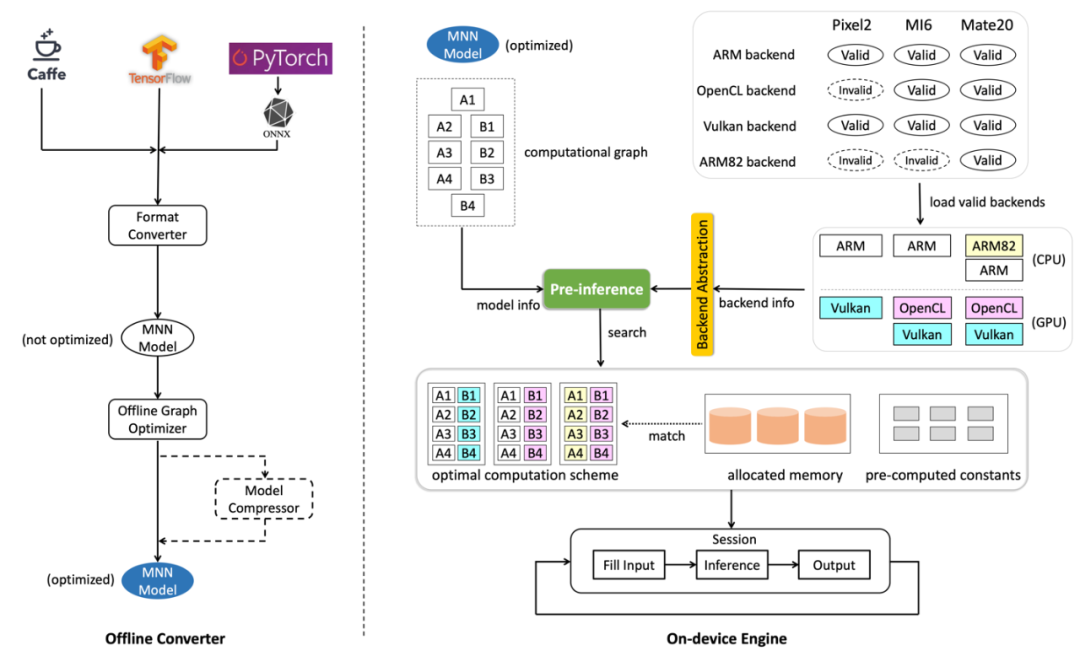
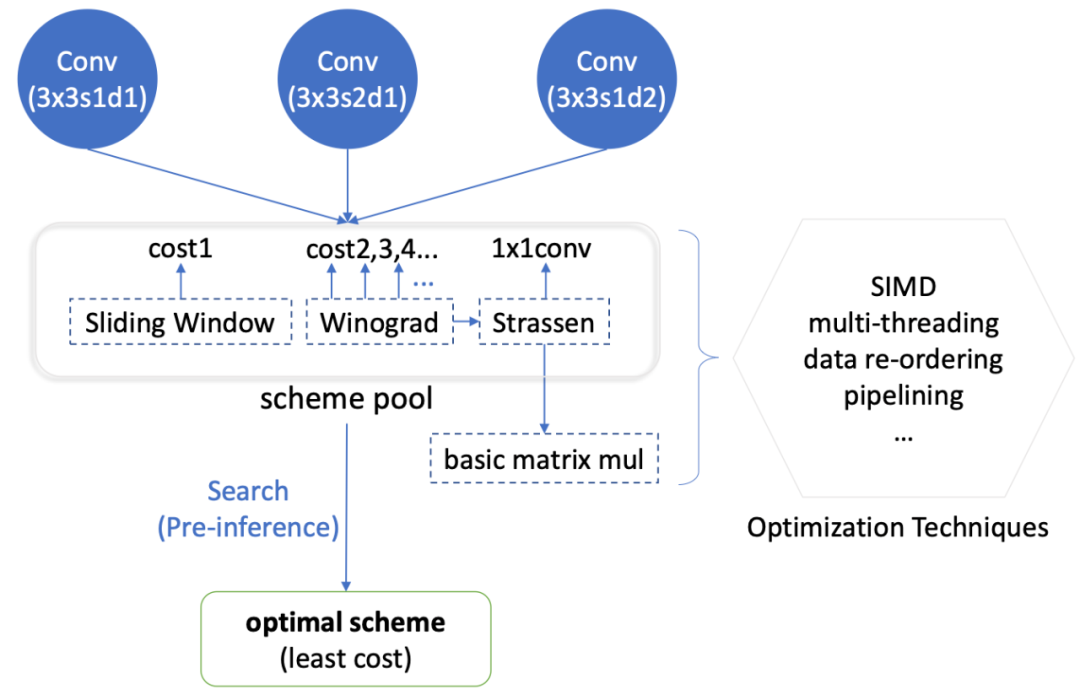
运行时半自动搜索架构
卷积算法优化创新
异构设备混合调度
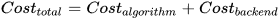
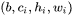 ,输出尺寸为
,输出尺寸为
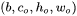 ,卷积核大小为
,卷积核大小为
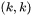 ,则有两种计算策略:
滑窗/矩阵乘 与 Winograd 算法。
,则有两种计算策略:
滑窗/矩阵乘 与 Winograd 算法。
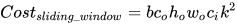
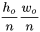 个小块(
个小块(
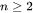 ,自行指定),然后针对这些小块执行四个步骤:
,自行指定),然后针对这些小块执行四个步骤:
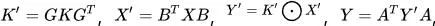
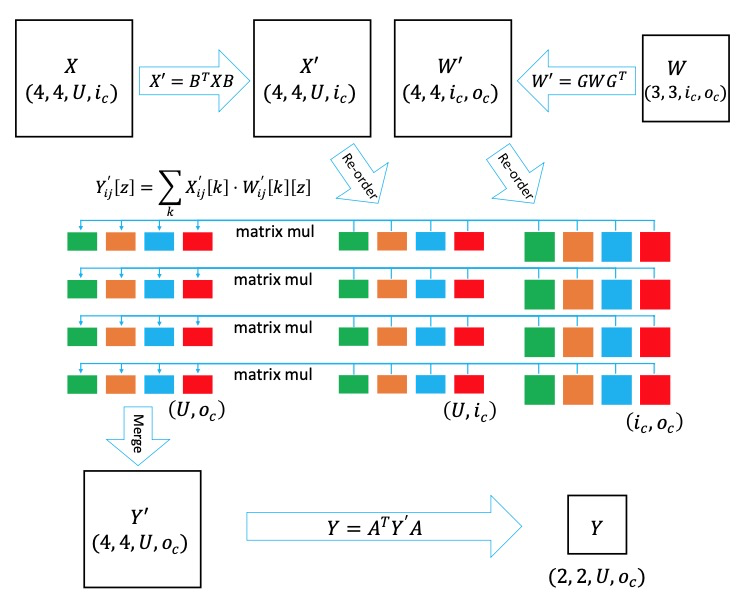
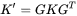 可以预先计算,实际计算过程为后三个步骤,这三步的计算量分别是
可以预先计算,实际计算过程为后三个步骤,这三步的计算量分别是
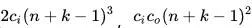 和
和
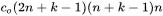 ,
所以
,
所以
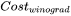 为:
为:
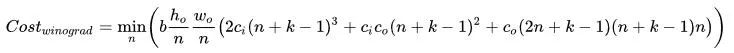 先降后升,需要找最小值。
先降后升,需要找最小值。
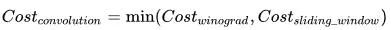
没有考虑算子内部需要缓存的问题,在不同的计算策略下,算子自身可能需要或不需要缓存(比如卷积用滑窗不需要缓存,用 Winograd 算法需要),这时候算子内部的缓存无法复用或预先分配,会增加内存占用或者影响性能。
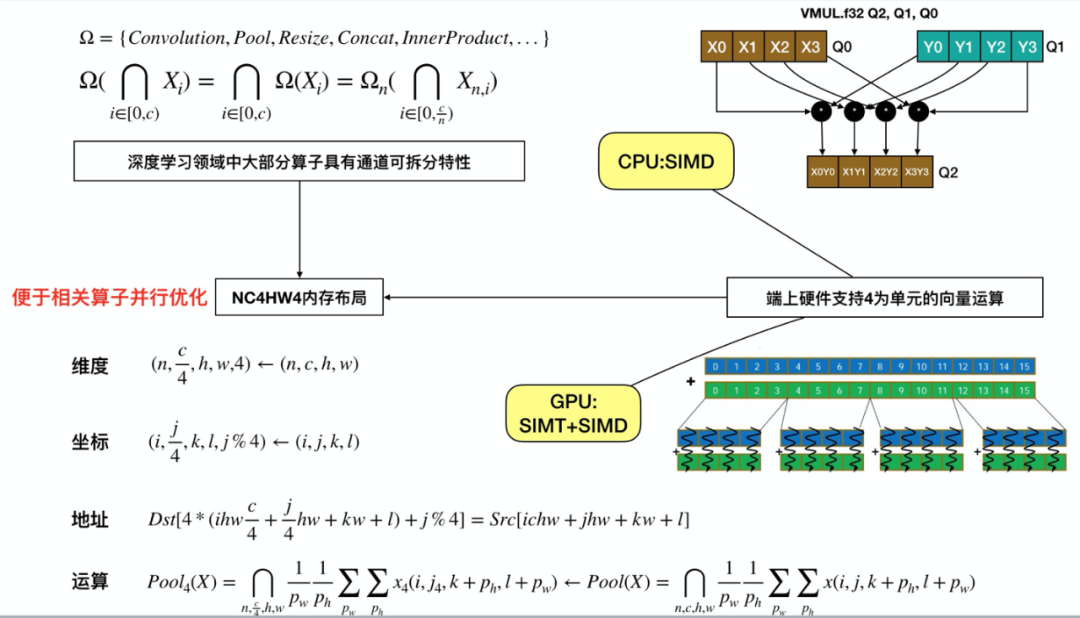
Feature map 对于异构设备而言(主要是 GPU),所需要的资源往往不仅是一块连续内存,因此异构端无法用同一套内存复用机制,往往需要另外写。
网络中有可能需要做多路并行,比如 CPU、GPU 各一路,这样之前按整个网络算出来的内存地址就无效了。
端上硬件支持以 4 为单元的向量运算。CPU SIMD 与 GPU SIMT+SIMD 均是如此。
深度学习领域中大部分算子具有通道可拆分特性
Winograd 每次需要计算更多的像素,对于尺寸比较小的 feature map 会有冗余,影响性能
在一些情况下,Winograd 需要前处理/后处理,有可能抵消掉其减少的乘法数收益
针对每一种卷积核大小与计算数的组合,都需要实现一份代码,优化的工程成本高昂
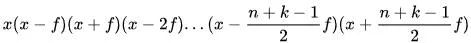
-
需要递归,影响效率 -
在矩阵不是足够大时,不如通常的矩阵乘有效率 -
计算过程中需要申请-释放内存,影响运行效率。
-
把递归申请-"执行"-释放的放到预推理中完成,"执行"步骤仅产生 lambda 函数,供推理时调用 -
用内存读写的大小去估 Strassen 算法的收益,判断是否进一步递归,对 的矩阵乘法,判断公式为 -
在推理过程中:按顺序调用预推理产生的 lambda 函数数组即可,无需递归或者申请/释放资源。
-
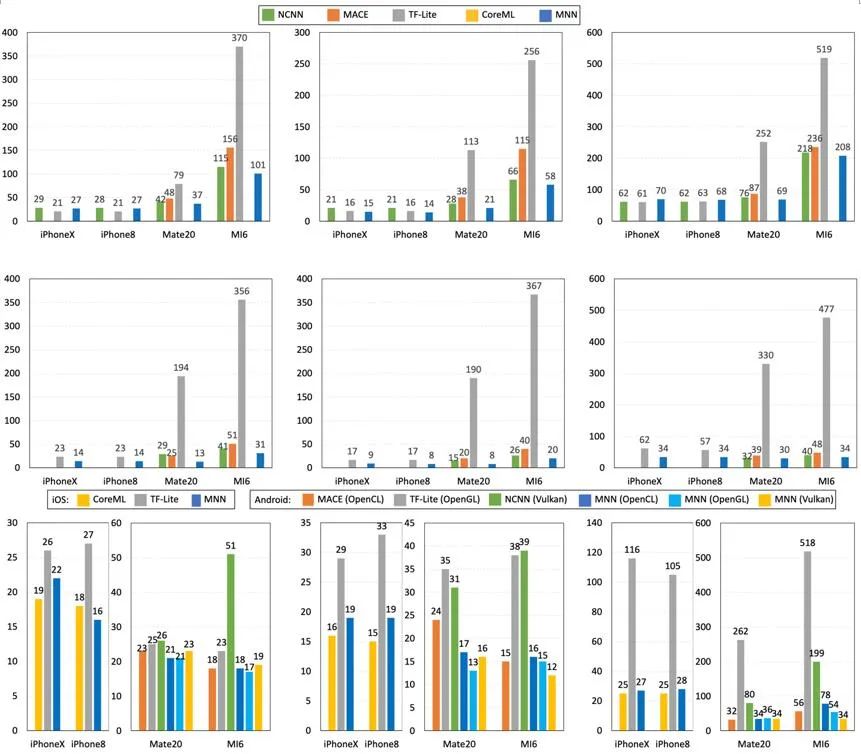
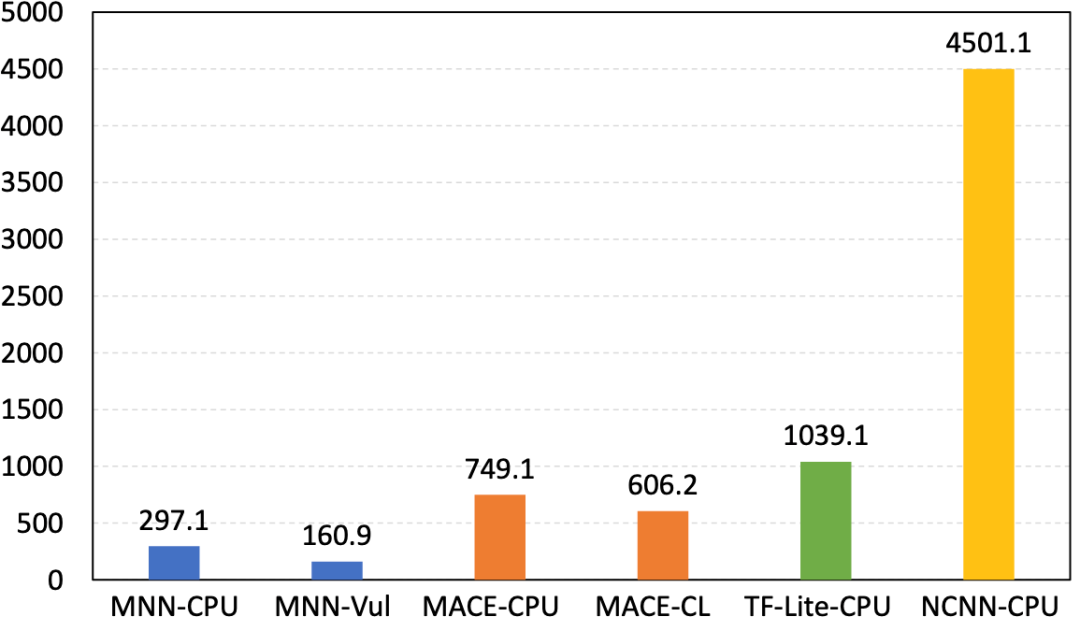
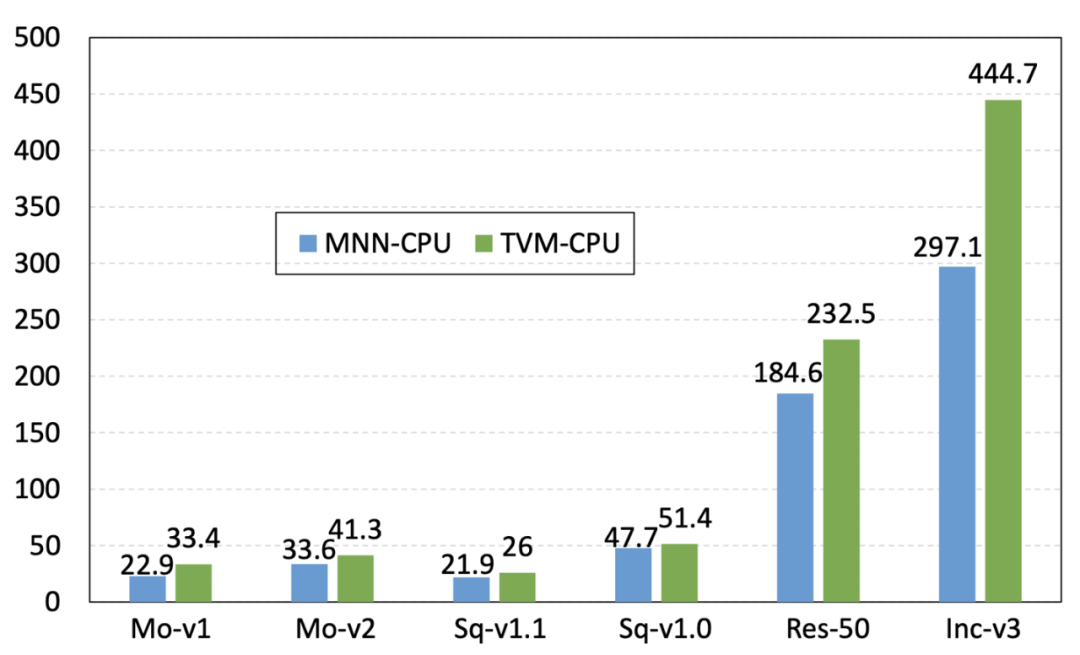
MNN 后端 API 帮助实现异构设备的 「混合调度」 :TFLite 这样的后端 Delegate,会在遇到不支持的算子的时候,回退到算子的 CPU 实现。可以说,TFLite 后端设计是「被动式」的。与 TFLite 这样的后端 Delegate 不同,MNN 的异构调度是「主动式」的,我们称之为「混合调度」:MNN 在创建推理会话时,可以针对算子配置后端,且配置多于一个后端时,会根据后端实现动态选择对性能最优的后端。同时,会话负责衔接后端间的数据拷贝,单一后端仅需实现到数据缓存区域的读写,而无需感知其他后端的存在。这样,就可以在单会话内或多会话间实现后端的自由组合。在后端不支持或性能不适合实现特定算子时,就可以借助其他后端的实现,完成整个推理过程。 -
MNN 后端 API 的为 算子抽象级别 ,而非例如 TFLite 的子图抽象级别。也就是说,在 MNN 的后端实现中,每个算子是单独实现的,后端实现不需要考虑子图的拓扑结构与优化。这一点,与前文所提的「半自动搜索」有关:在预处理过程中,整个计算图的图优化已经统一提前完成,所以不需要在后端子图实现。另外,算子级别的后端抽象,也极大的提高了后端实现的可调试性:可以将实现有误的后端算子快速定位。

登录查看更多
相关内容
Arxiv
4+阅读 · 2018年1月11日

相关VIP内容
相关资讯
相关论文
Arxiv
4+阅读 · 2018年1月11日