SLAM的动态地图和语义问题
点“计算机视觉life”关注,置顶更快接收消息!
本文原载于知乎自动驾驶的挑战和发展专栏,作者为奇点汽车美研中心首席科学家兼总裁黄浴,计算机视觉life非常荣幸取得黄先生授权转载。
https://zhuanlan.zhihu.com/p/58213757
https://zhuanlan.zhihu.com/p/58213848
上篇
近年来动态地图和语义地图好像在SLAM领域比较热,动态物体一直是个敏感的问题。当年计算机视觉唯一的工业落地场景“视觉监控”也在这个问题费了脑筋,比如我搬个凳子到新位置,然后就走了,系统是不是要自动更新背景呢?
以前说过SFM和SLAM的称呼,计算机视觉的同行多半说SFM,而机器人的行业流行说SLAM,到底区别在哪里?有说SFM是假设背景不动,那么outlier是什么?当年做IBR(image-based rendering)的时候,以panorama view为例,也是假设场景物体不动,可总是有不静止的物体,比如水,比如树叶,甚至不配合的人们走动,会产生鬼影吗?结果也提出了一堆的解决方法。SFM和MVG(multiple view geometry)紧密相关吧,都面临计算机视觉的共同问题,动态环境是回避不了的。
景物动态部分不一定是object,或者不一定能得到object,所以不一定是语义的。语义地图不一定就是动态的,所以语义地图和动态地图是有重叠的,不过最近深度学习的发展比如语义分割,目标检测和跟踪等等的确使二者渐渐走在了一起。在人的眼中,一切都是语义的存在,尽管对某些部分认识不够。
这里我还是把SLAM动态地图和语义SLAM分开,主要是文章太多。
先列个题目,动态地图放在上部分,而语义地图放下部分。
先推荐一篇ACM Computing Survey发表于2018年2月的综述文章“Visual SLAM and Structure from Motion in Dynamic Environments: A Survey“,它对动态环境的分析可以参考一下。
讨论的方法基本分三大类:一定位和重建为主,二动态目标分割和跟踪为主,三运动分割与重建联合估计的方法。

下图给出了各种方法之间的联系:
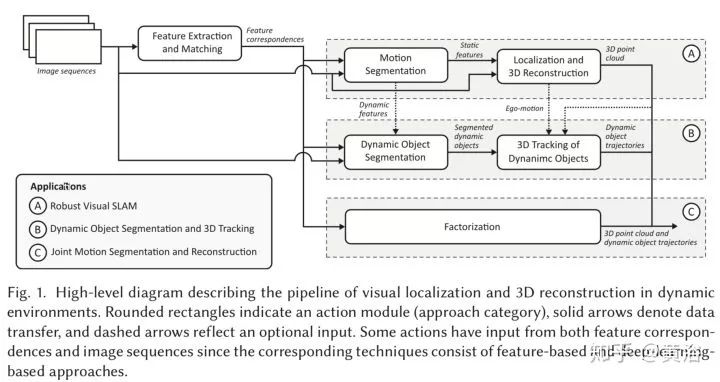
第一类 “A)Robust Visual SLAM”,下图给出框图结构:
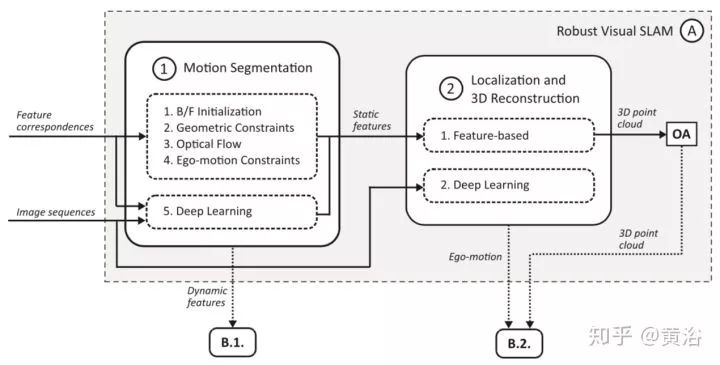
第二类 “B)Dynamic Object Segmentation and 3D Tracking“ ,同样的,其框架图如下:
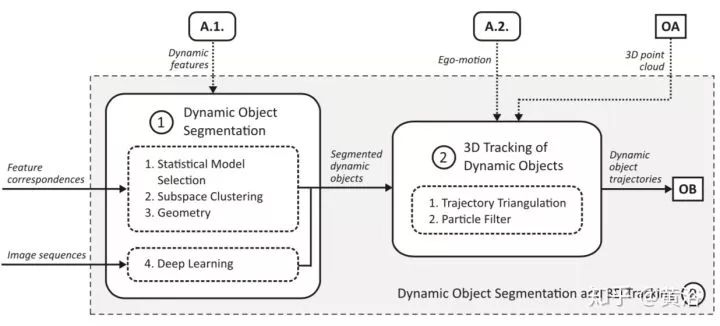
第三类 “C)Joint Motion Segmentation and Reconstruction“,其特性见下图:
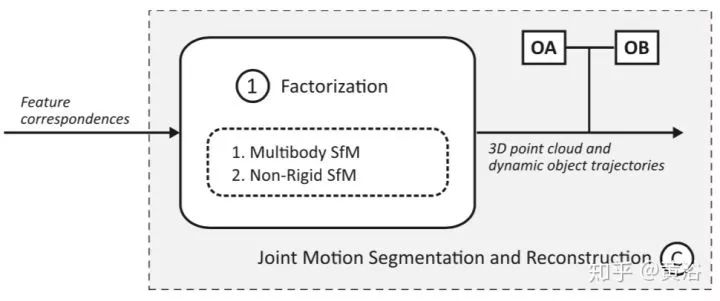
在这三类方法中都有深度学习的部分。
下面选一些论文作为参考(注:次序没有按时间排列)。
1.Simultaneous Localization and Mapping with Detection and Tracking of Moving Objects
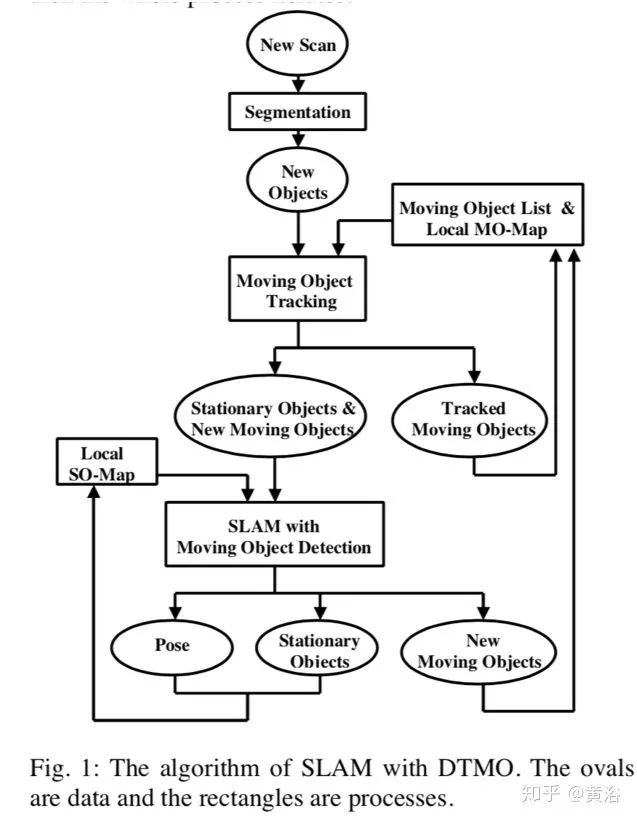
看上面的系统流程图,典型的方法:运动分割,运动目标检测和跟踪,静态目标和静态地图。
2.Simultaneous Localization and Mapping with Moving Object Tracking in 3D Range Data
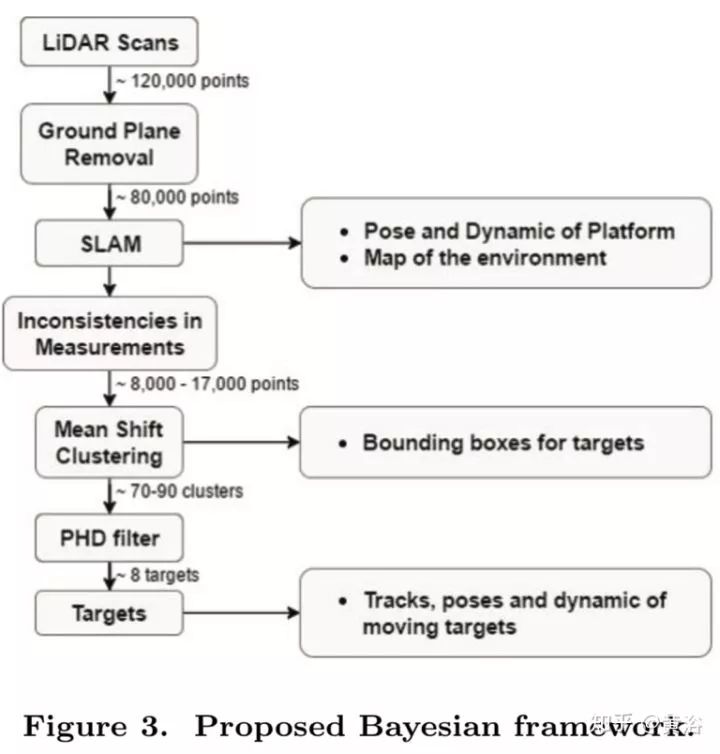
如上面框图所示,特点:采用occupancy grid maps,因为传感器是激光雷达,可以采用ICP算法定位,地面估计去除在先,Mean Shift做聚类得到目标检测,Probability Hypothesis Density (PHD) 做多目标跟踪。
3.Online Localization and Mapping with Moving Object Tracking in Dynamic Outdoor Environments

采用激光雷达数据,基于incremental scan matching方法定位,不受环境小运动的影响。
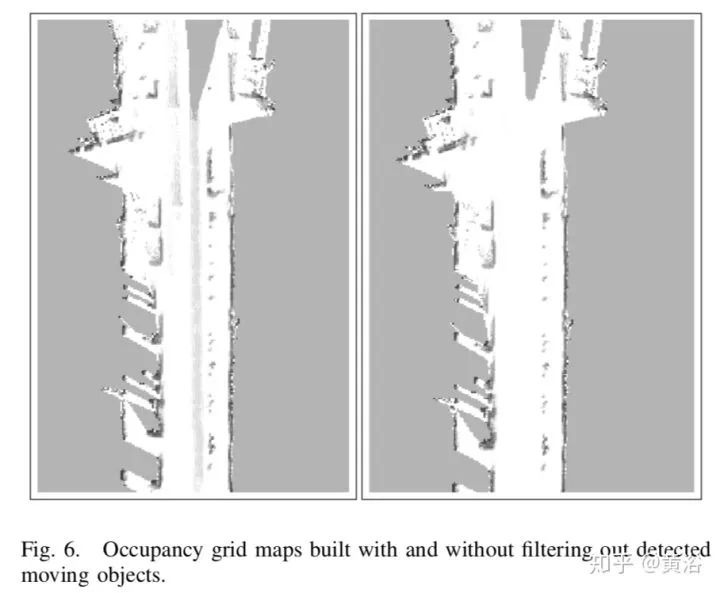
跟上一个文章一样采用occupancy map,环境地图步进更新,基于此检测运动目标,而目标跟踪基于Global NN算法。
4.SLAM method: reconstruction and modeling of environ. with moving objects using an RGBD camera
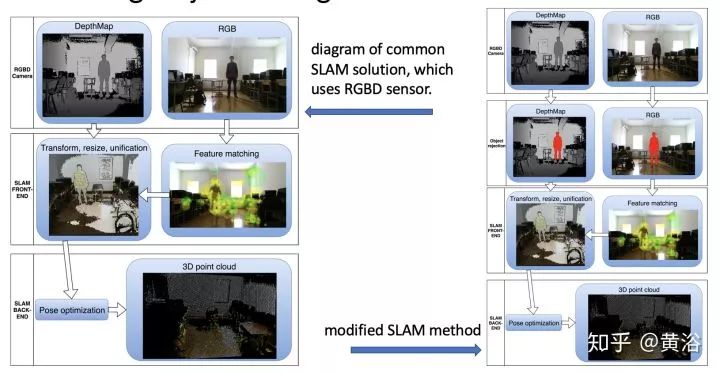
采用Kinect深度传感器,见上图,和一般SLAM比较,比较容易检测出运动目标(室内深度层次少)。
5.Generic NDT mapping in dynamic environments and its application for lifelong SLAM
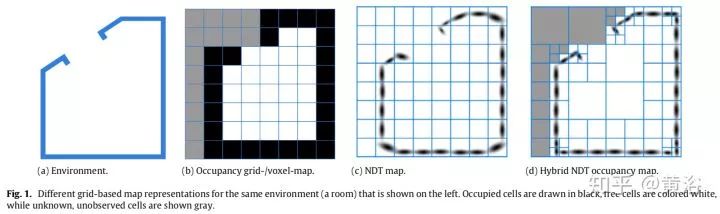
首先,采用Hybrid Normal Distribution Transform (NDT) occupancy maps,如上图。
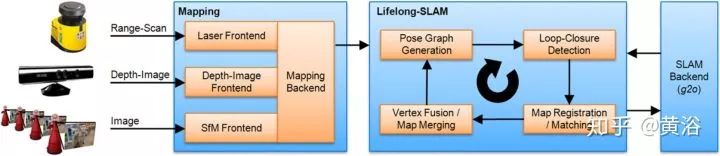
其次,系统可以检测跟踪运动目标,而graph-based SLAM能够实现lifelong SLAM。
6 RGB-D SLAM in Dynamic Environments using Static Point Weighting
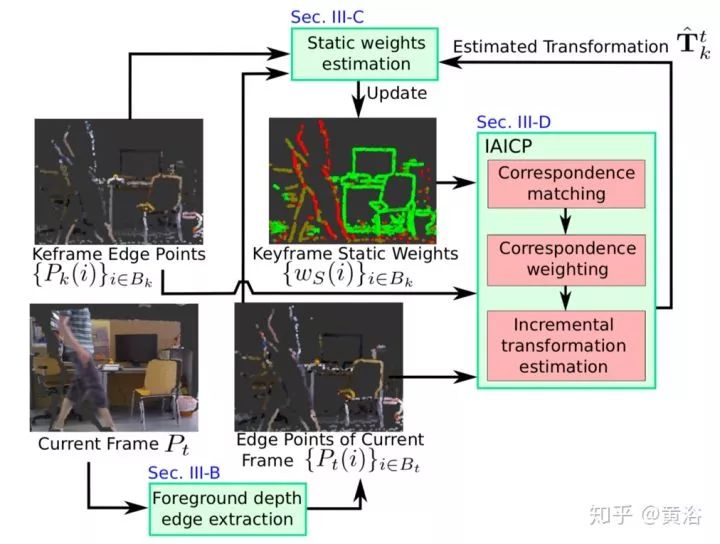
如图介绍,其特点:还是RGB image加深度数据,提出depth edge 做visual odometry, 而static weighting 是为了对付运动物体。Intensity Assisted ICP (IAICP) 是改进ICP做定位的算法。
7.EVO: A Geometric Approach to Event-Based 6-DOF Parallel Tracking and Mapping in Real-time
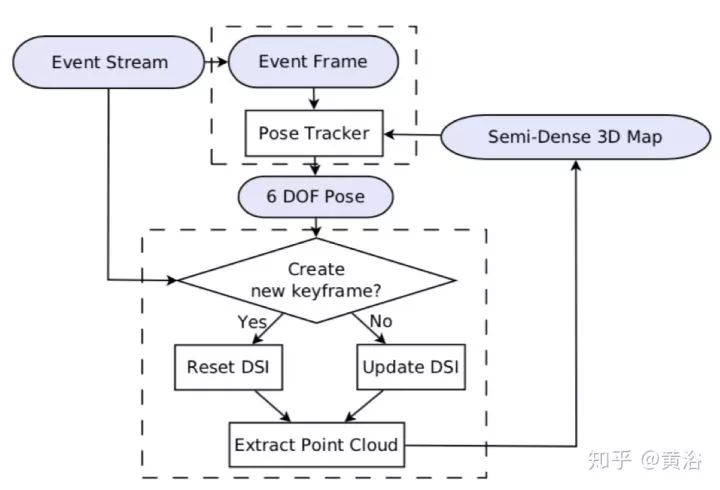
上图为算法流程图。EVO = Event-based Visual Odometry,就是用event cameras (类似Dynamic Vision Sensor)做运动跟踪,上图框架像PTAM。下面两个图是介绍Mapping方法EMVS:
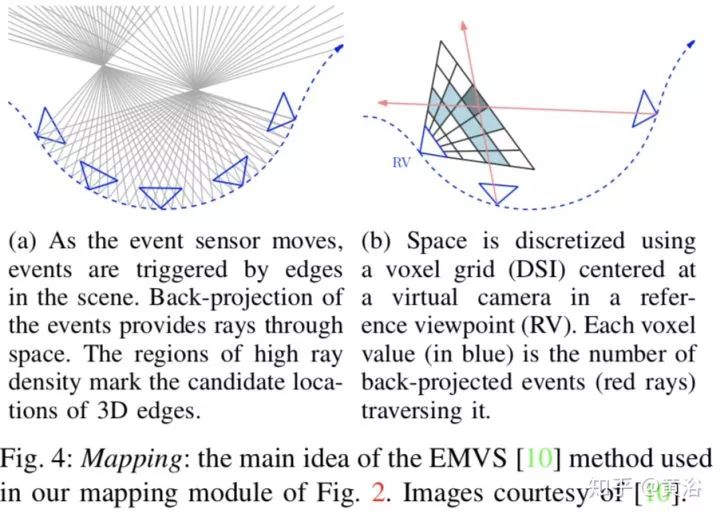
注:参考方法 EMVS = Event-based Multi-View Stereo,DSI = Disparity Space Image。

8.SLAM in a Dynamic Large Outdoor Environment using a Laser Scanner

上图SLAM,其中模块A的细节在红色圆圈里。其特点:还是运动目标检测和跟踪;采用GPS诊断pose误差,实现全局精准。
9.Realtime Multibody Visual SLAM with a Smoothly Moving Monocular Camera
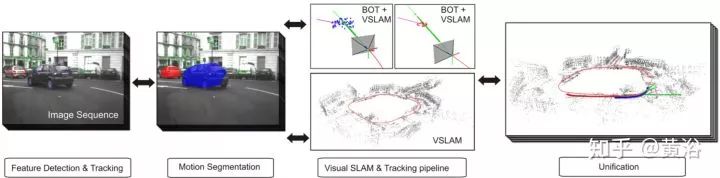
简单示意图如上,其特点:Bearing only Tracking (BOT) 基于particle filter,运动相机做motion segmentation保证静态景物3-D重建。
10.Localization in highly dynamic environments using dual-timescale NDT-MCL
Normal Distributions Transform (NDT)
Monte Carlo Localization (MCL)
MCL是基于particle filter的方法,地图采用Occupancy maps模式,这样NDT做定位。
MCL分三步:
1. prediction
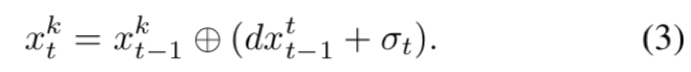
2. update
3. resampling.
下面是整个算法的伪代码:

11.SLAM With Dynamic Targets via Single-Cluster PHD Filtering
算法核心是particle/Gaussian mixture,single- cluster process是指feature-based SLAM,其中车辆运动是主,而特征运动为附。下面是四个算法的概略:




12.Exploiting Rigid Body Motion for SLAM in Dynamic Environments
基于factor graph处理SLAM的动态物体的运动干扰。下面三个图都是SLAM的factor graph。
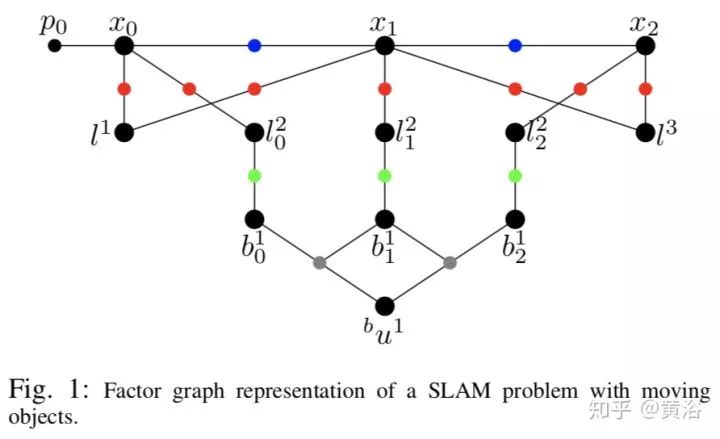

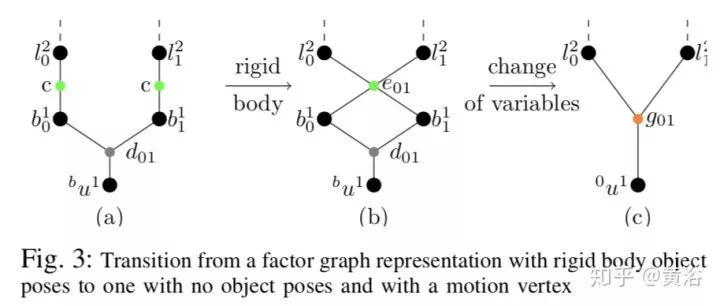
下图是特征提取和跟踪的结果例子:

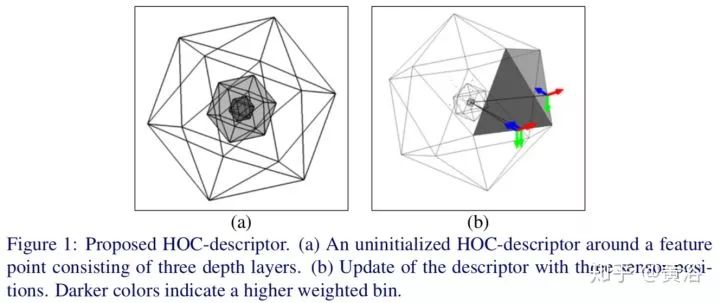
13.Histogram of Oriented Cameras - A New Descriptor for Visual SLAM in Dynamic Environments
提出一个3-D描述子Histogram of Oriented Cameras (HOC) ,如下图:
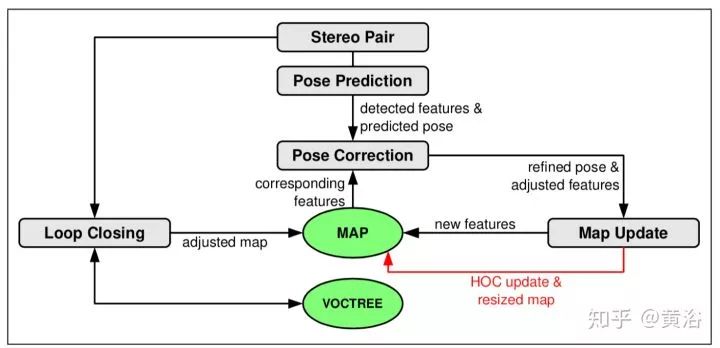
下图是SLAM框架:双目视觉,关键在地图更新环部分。
14.Event-based 3D SLAM with a depth-augmented dynamic vision sensor
采用event camera,即DVS(dynamic vision sensor)处理动态环境。系统展示图如下:

这里DVS和RGB-D深度传感器进行融合做定位。
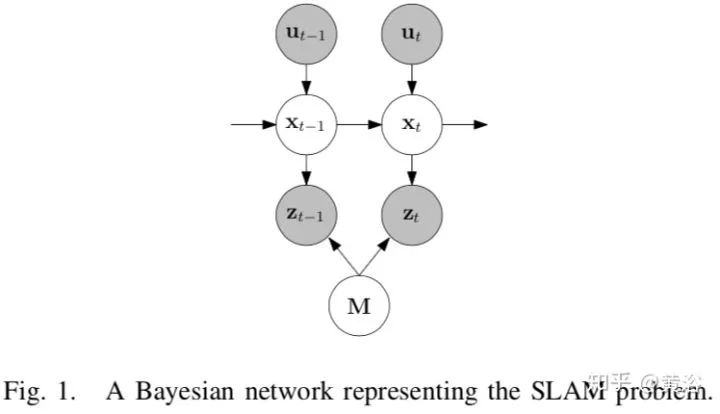
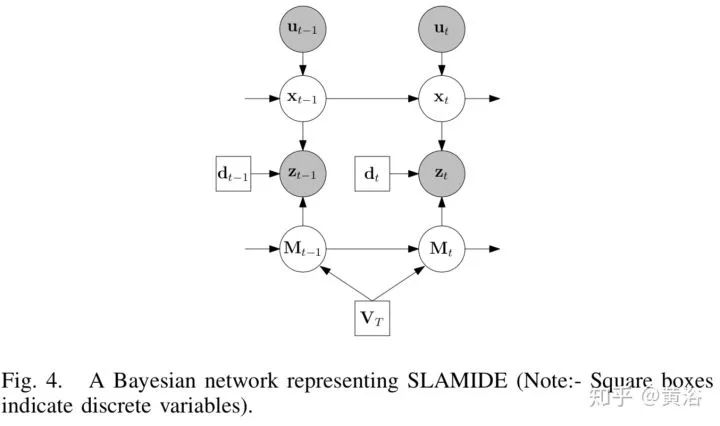
15.Simultaneous Localisation and Mapping in Dynamic Environments (SLAMIDE) with Reversible Data Association
采用广义EM(expectation maximisation)算法处理动态环境下的SLAM,求解的问题定义在一个Bayesian Network框架,如下图:采用sliding window SLAM而不是EKF方法。
加了Reversible Data Association处理动态目标,如下图:实现Data Association可以通过NN或者joint compatibility branch and bound (JCBB) 算法。
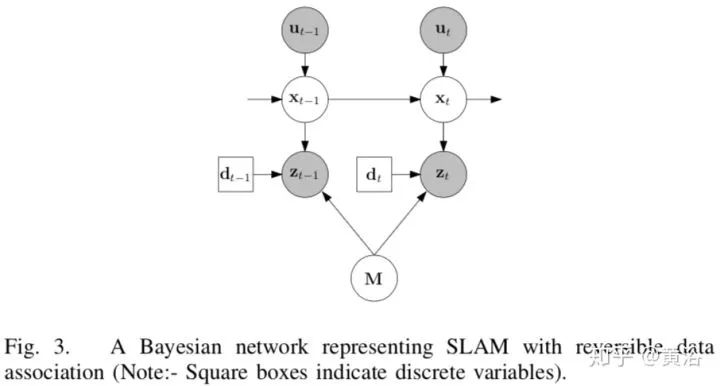
其中的Bayesian Network就是HMM实现,如下图SLAMIDE:
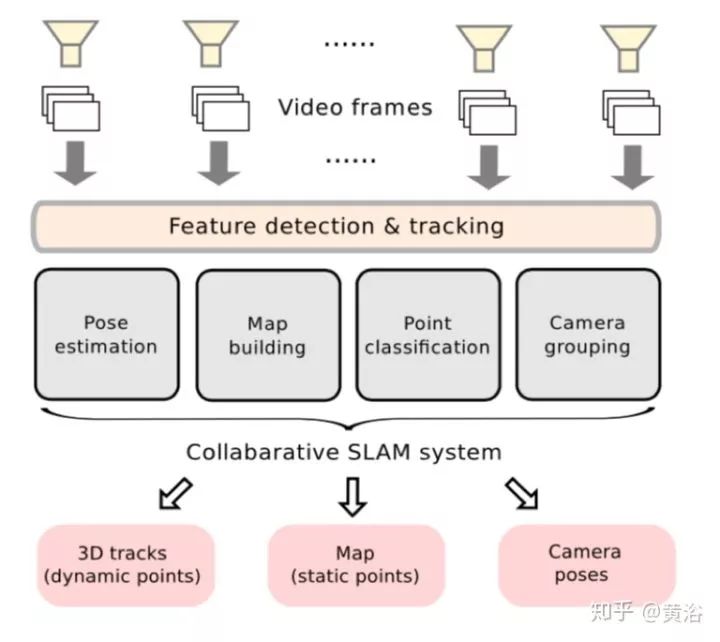
16.CoSLAM: Collaborative Visual SLAM in Dynamic Environments
采用多个独立摄像头协同工作的SLAM系统,如下图:
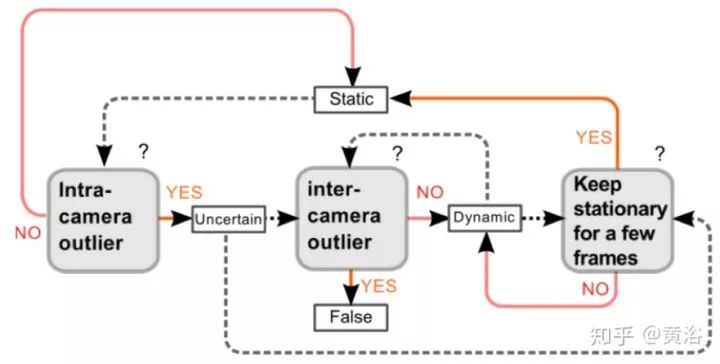
关于地图中的point classification,分类类型即‘static’, ‘dynamic’, ‘false’ 或者 ‘uncertain‘,判别流程见下图:
这里显示各个camera如何协同估计自身的pose:
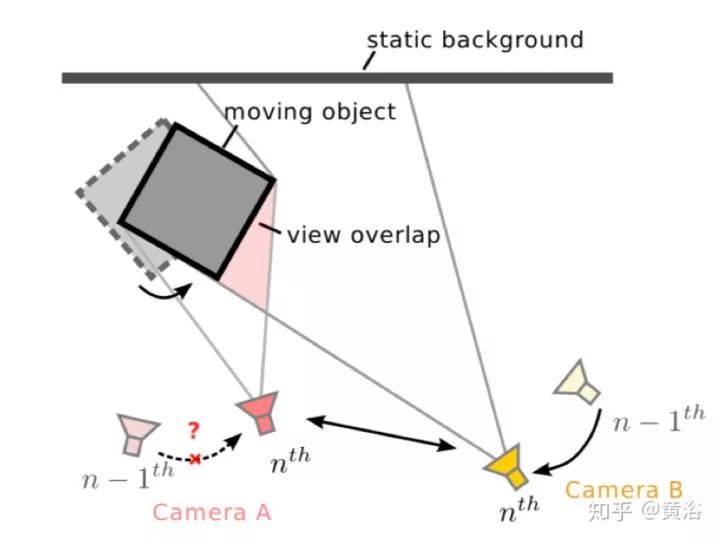
17.IMU-Assisted 2D SLAM Method for Low-Texture and Dynamic Environments
前端部分,在卡尔曼滤波extended Kalman Filter (EKF)下融合IMU传感器和2D LiDAR的2-DSLAM处理低纹理动态环境,scan matching通过LM(Levenberg–Marquardt )算法优化。在后端,做sparse pose adjustment (SPA) 。如下图:
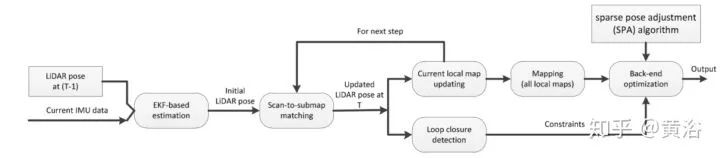
18.Dynamic pose graph SLAM: Long-term mapping in low dynamic environments
讨论如何维护室内激光雷达扫描的地图,其中Dynamic Pose Graph SLAM (DPG-SLAM)做这种动态环境下的定位。DPG定义如下:

DPG的例子:
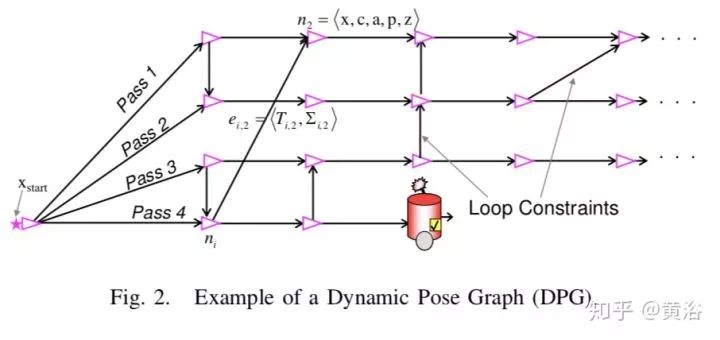
DPG的一个节点:
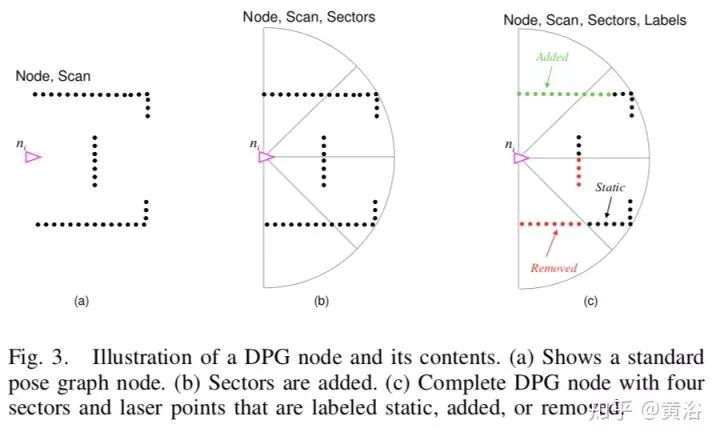
采用的SLAM方法是iSAM。所谓Low-dynamic objects就是那些容易加上/移动/去除的物体。关键是如何检测变化和更新地图。下面是三个相关算法图:



19. Semantic Monocular SLAM for Highly Dynamic Environments
扩展了ORB-SLAM,特征提取和匹配可以直接用于姿态估计,采用一个outlier概率模型处理地图的变化,系统概略如下图:
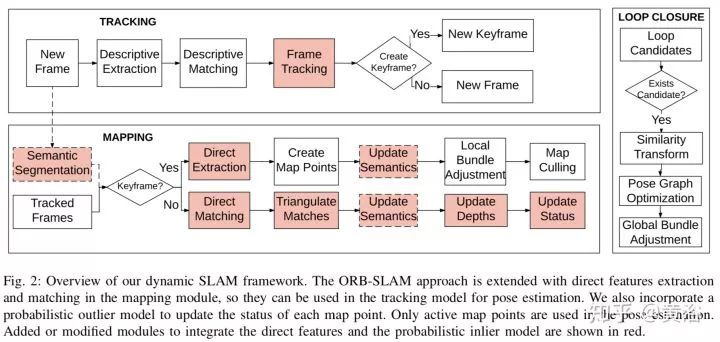
下面的结果来自一个demo视频截图:

20. Robust Monocular SLAM in Dynamic Environments
该Monocular SLAM可以处理缓慢变化的动态环境,是一种在线keyframe方法,能够检测变化并及时更新地图。另外,提出一个prior-based adaptive RANSAC (PARSAC) 算法去除outlier。系统框架如下图:
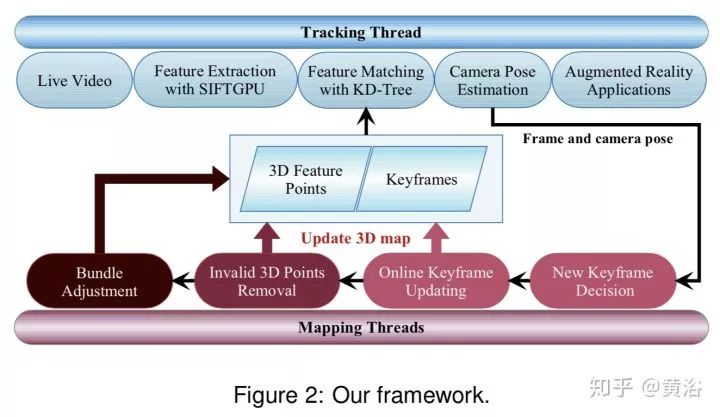
特别的,处理遮挡问题,及时检测,下图有它的算法框架,其中appearance变化测度如下:
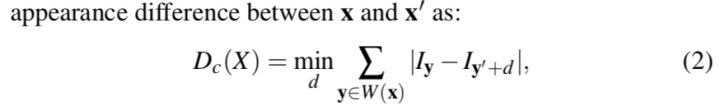

这里把语义SLAM放在这个题目的下部分。
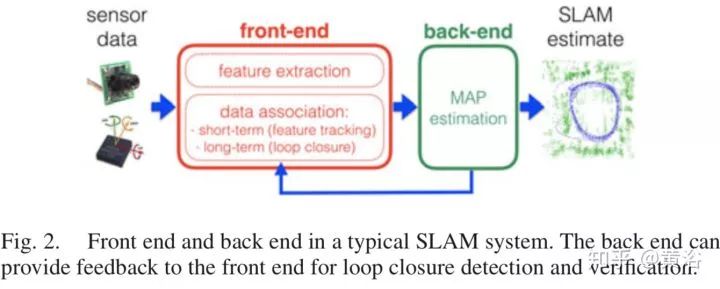
谈到语义地图,还是要读读2016年的那篇综述文章 "Past, Present, and Future of Simultaneous Localization and Mapping: Toward the Robust-Perception Age",其中第七章主要讨论语义地图的问题。
放个SLAM的标准图:前端+后端
SLAM问题是一个factor graph:
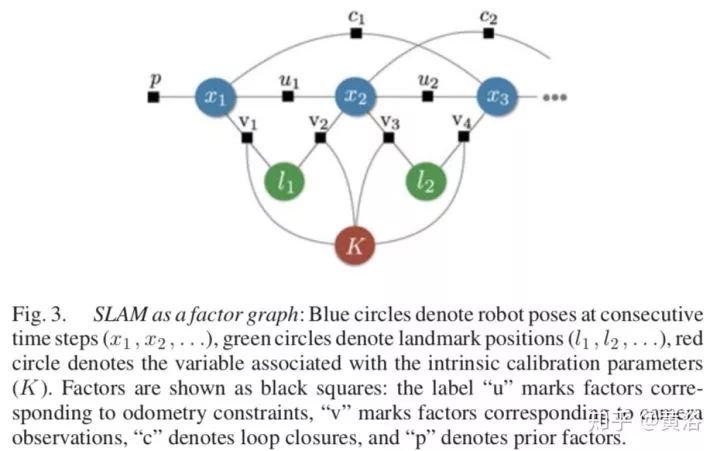
基本上,语义地图可以分为三种方法来加注语义概念:
SLAM帮助语义概念;
语义概念帮助SLAM;
语义概念和SLAM联合求解。
最后还提出了四个未解决的问题(open problems):
Consistent Semantic-Metric Fusion:和尺度地图融合;
Semantic mapping is much more than a categorization problem:语义的概念是人定义的;
Ignorance, awareness, and adaptation:缺乏自我学习知识能力;
Semantic based reasoning:不会做推理。
下面还是选了一些论文供参考(次序不按照时间)。
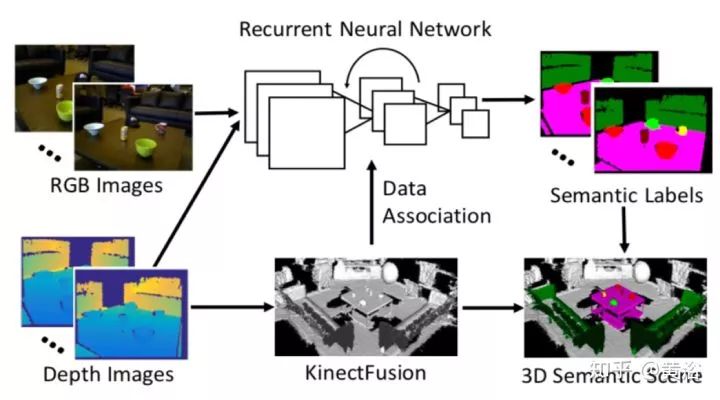
1.DA-RNN: Semantic Mapping with Data Associated Recurrent Neural Networks
Data Associated Recurrent Neural Networks (DA-RNNs)是产生语义标记的,采用RGB-D传感器,SLAM是一个如KinectFusion的平台。算法框架如下图:
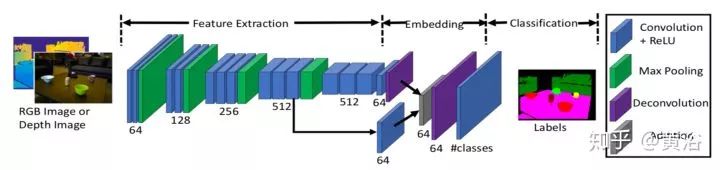
做semantic labeling的RNN模型有三个:
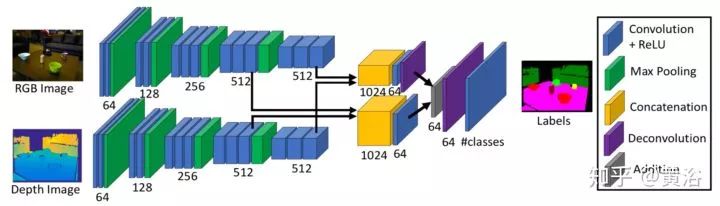
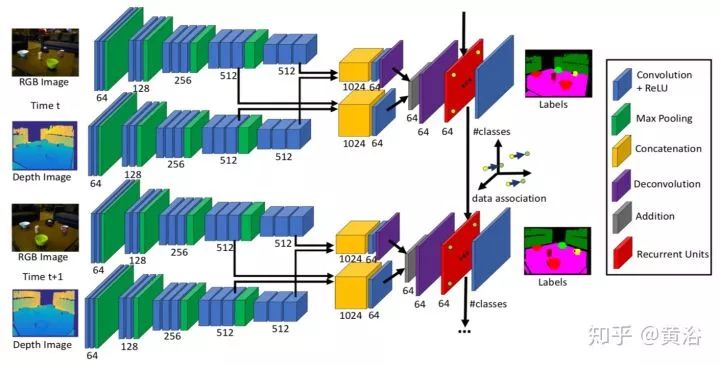
其中负责数据相关的Data Associated Recurrent Unit (DA-RU),结构如下:
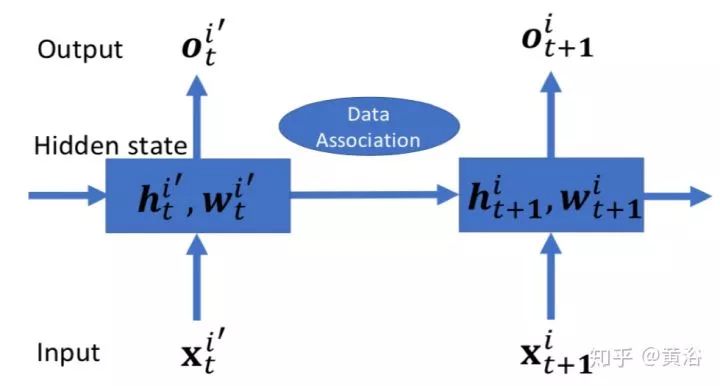
2.Probabilistic Data Association for Semantic SLAM
实现目标识别才能做到真正的语义SLAM,文章给出了定义:

语义SLAM的问题求解表示为下面的优化过程:

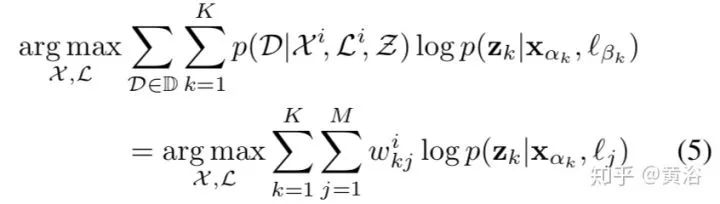
求解的算法EM如下:

更细化的EM框架如下:

3.Long-term Visual Localization using Semantically Segmented Images
讨论无人车的定位问题,主要基于最近的语义分割成果。
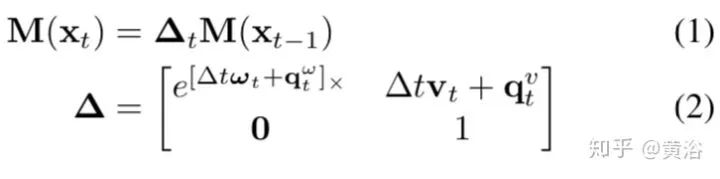
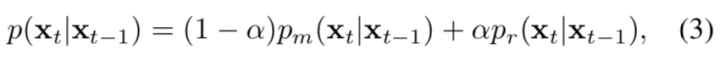
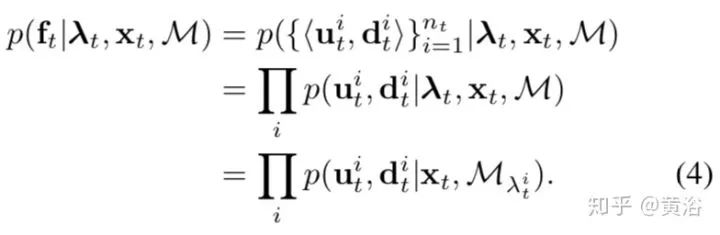
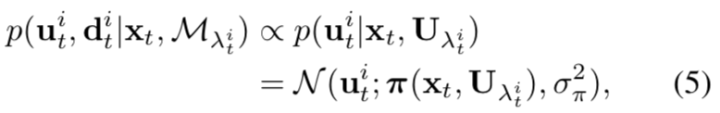
基于以上的公式,可以给出基于SIFT特征的定位算法如下:

而语义类的定位方法不同。
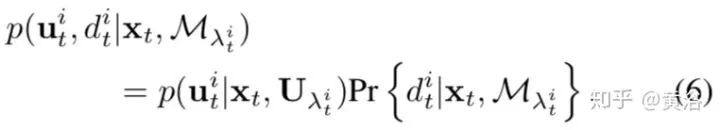
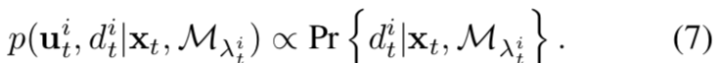
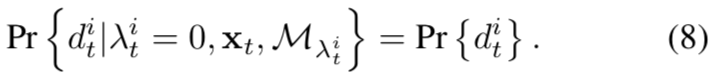
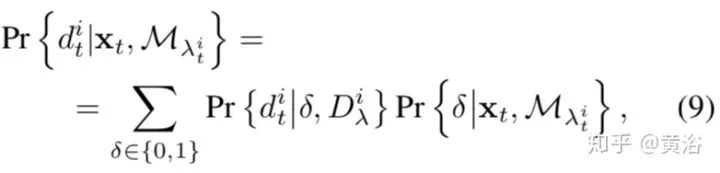
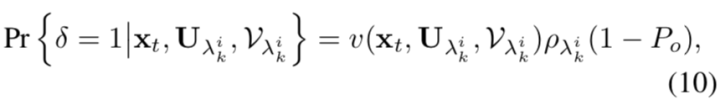
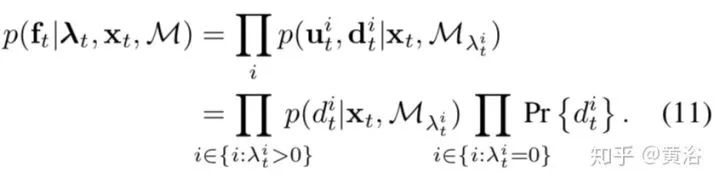
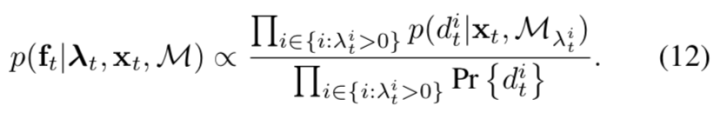
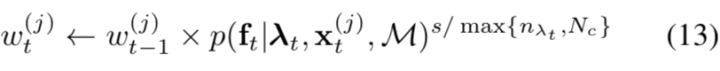
基于上述公式,推导的语义类新定位算法如下:

4.Stereo Vision-based Semantic 3D Object and Ego-motion Tracking for Autonomous Driving
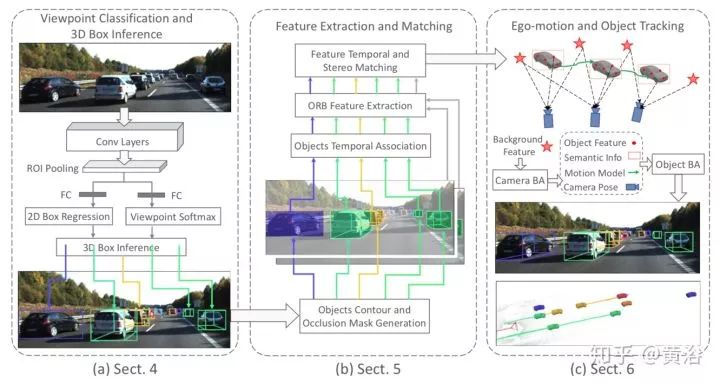
文章讨论如何从2D检测推断3-D检测的方法,本身采用双目视觉,这样做的原因是计算量小。提出在目标基础上的摄像头姿态跟踪估计,还有动态目标 bundle adjustment (BA)方法,依此融合语义观测模型和稀疏的特征匹配结合以获取3-D目标的姿态,速度和结构信息。
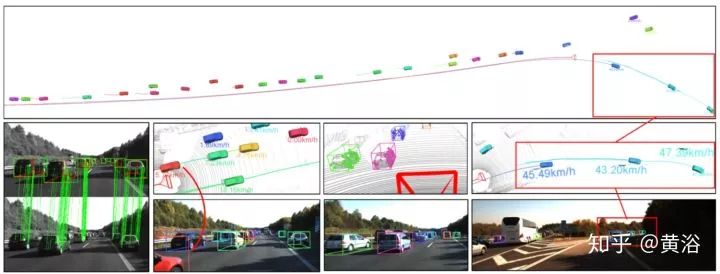
上图是一个例子,上半部分是摄像头和目标的运动轨迹,下半部分从左到右依此是双目匹配,一个被截断车的跟踪,BA恢复的稀疏特征点,和姿态估计。
整个语义意义上的跟踪框架如下图:左边是CNN模型实现的视点分类和3-D检测,中间是ORB特征提取和匹配,而右边是目标跟踪和摄像头运动估计。
5.VSO: Visual Semantic Odometry
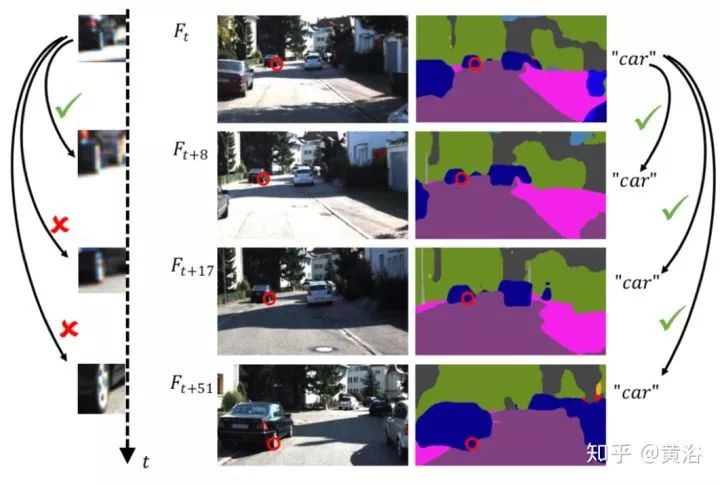
建立语义信息作为中层的VO约束,下图就是想解释为什么底层特征跟踪失败的情况下带语义信息的跟踪仍然工作很好。
VO解决的目标是:
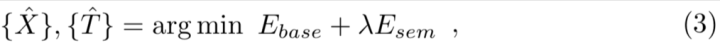
而其中特征点和语义部分分别定义为:
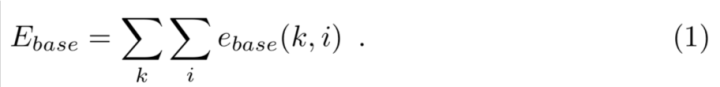
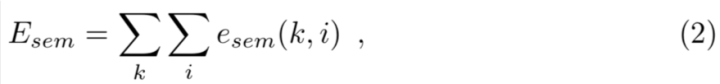
observation likelihood model 如下
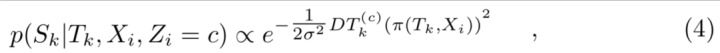
其中DT是距离变换。而semantic cost计算如下:
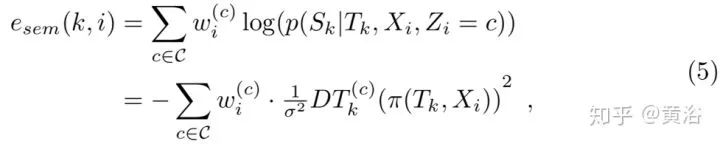
关于语义的观测似然函数,下图给出一些直观展示:

其中σ = 10 (c),σ = 40 (d),而 (b)是二值图像。
6.DS-SLAM: A Semantic Visual SLAM towards Dynamic Environments
清华大学基于ORB-SLAM2给出的语义SLAM方案,如图所示:
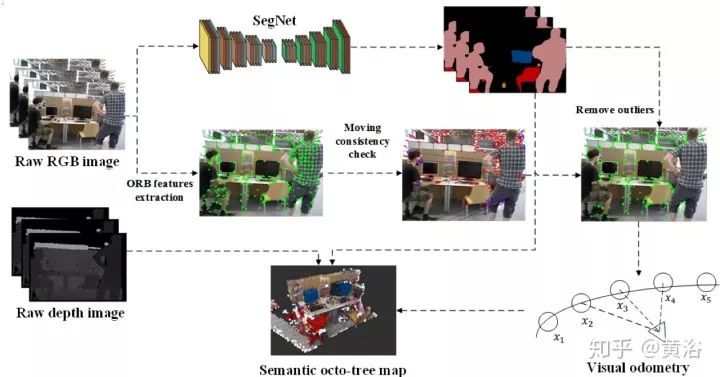
语义分割用SegNet,有深度图的数据可以生成最终Semantic octo-tree map。语义信息和ORB特征检测跟踪结合可以消除运动物体。
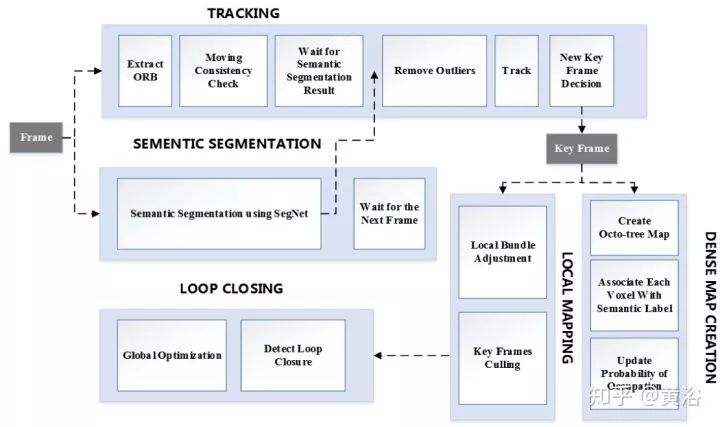
上图看出,在ORB-SLAM2基础上,加了语义分割这部分。
7.Robust Dense Mapping for Large-Scale Dynamic Environments
双目视觉输入,做深度图估计和物体分割,结合sparse scene flow,对场景进行重建。下图是系统框图:
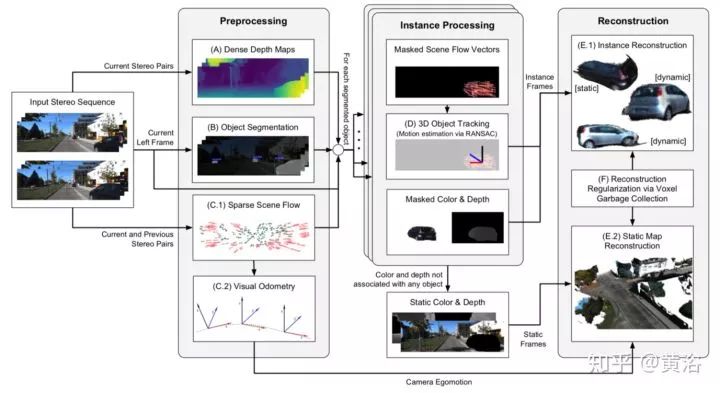
8.Meaningful Maps With Object-Oriented Semantic Mapping
结合了RGB-D SLAM,语义层次上借助深度学习的目标检测和3-D分割。
下图是一个示意图:上面从左到右,是SSD的region proposal和非监督3-D分割,而下面是带语义的地图。

如下是语义地图的框架:在ORB-SLAM2基础上改的。
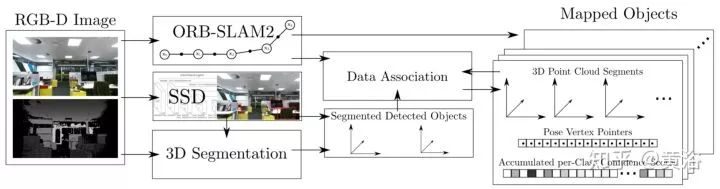
9.6-DoF Object Pose from Semantic Keypoints
主要是基于CNN提出semantic keypoints,和deformable shape model结合。下图是对算法的直观介绍:

其中CNN模型如下结构:两个沙漏模型的叠加,输出特征点的热图(heatmap)。

10.A Unifying View of Geometry, Semantics, and Data Association in SLAM
如题目所示,将几何,语义和数据相关几个部分结合起来的SLAM。
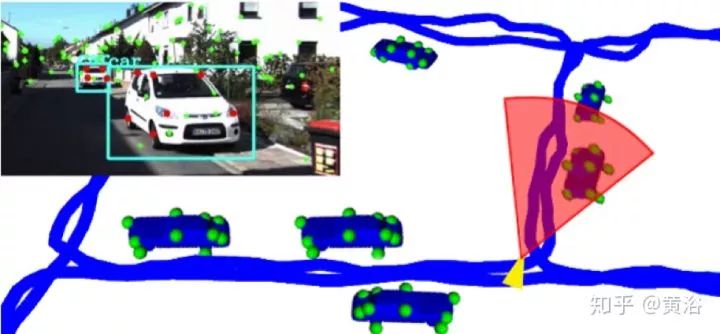
上图展示的是:测量数据包括惯导,几何和语义 (左上角),重建传感器轨迹(蓝色),检测的目标(车),还有估计的车部件 (绿色点,即门和轮子)。
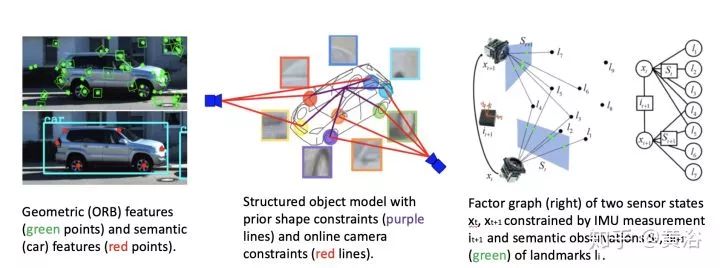
上图有特征和语义特征的比较,带有约束的结构化目标模型和被传感器观测数据(landmarks的IMU和语义)的状态向量factor graph表示。
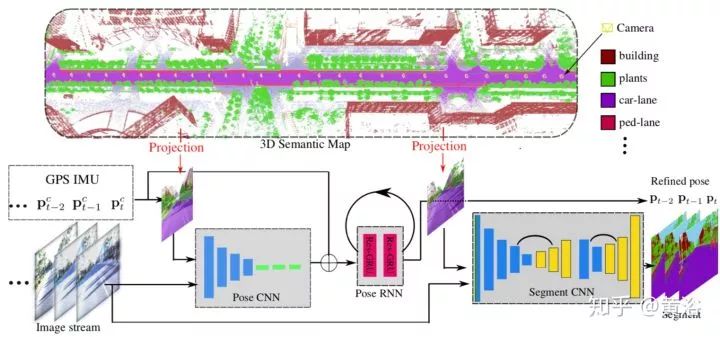
11.DeLS-3D: Deep Localization and Segmentation with a 3D Semantic Map
传感器融合的扩展,将GPS/IMU,摄像头和语义地图结合的定位。利用pose CNN做姿态估计,加上multi-layer RNN 做姿态修正。最后和segment CNN 输出的分割结合产生地图信息。
系统示意图如下:
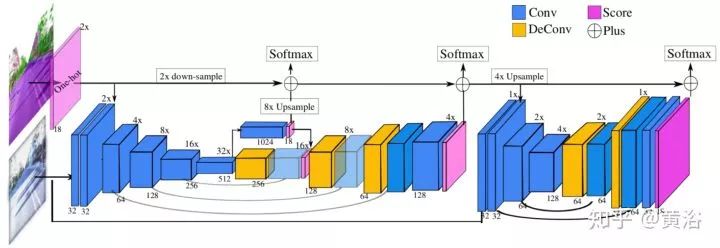
其中关键的segment CNN 结构如下:
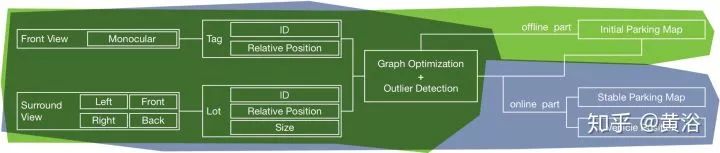
12.Vision-based Semantic Mapping and Localization for Autonomous Indoor Parking
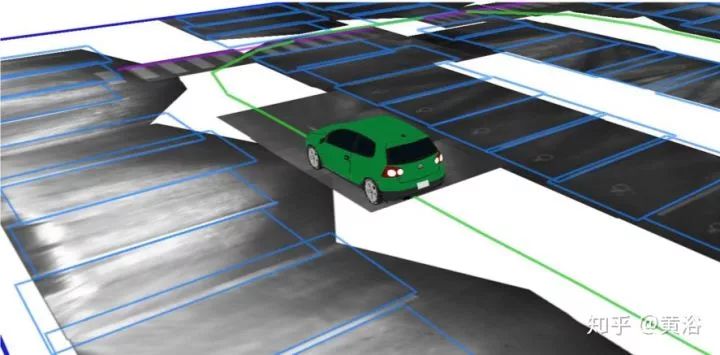
室内自动泊车采用语义地图的应用。系统流水线如下图:
系统前端做VO,后端做地图优化,优化算法是基于图论的思想,如图所示:
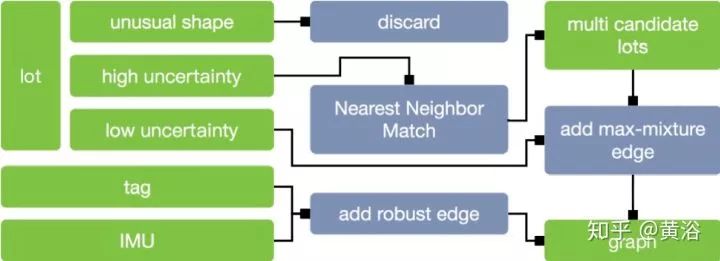
13.Integrating Metric and Semantic Maps for Vision-Only Automated Parking
另外一个自动泊车的语义地图应用,结合了Metric map和Semantic Maps。另外,不同于上一篇论文的是,只有camera传感器。系统流程图如下:
语义信息如下图:停车位线。
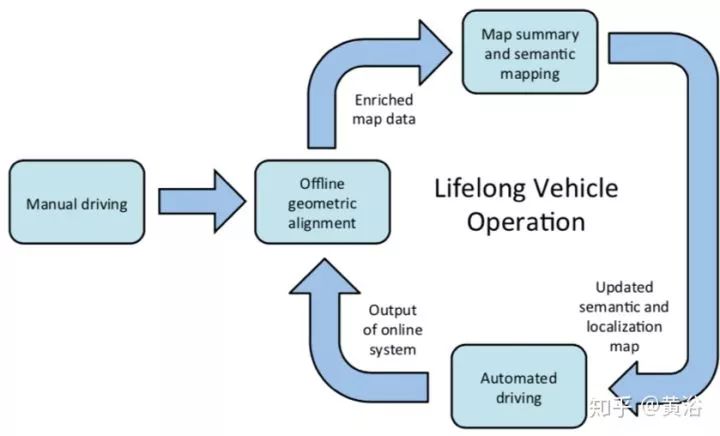
作者提出一种Base Map + Multi-Session Mapping的结构,便于地图更新。其中语义地图包括三部分:静态地图,动态地图和道路网络。
14. SemanticFusion: Dense 3D Semantic Mapping with Convolutional Neural Networks
借助CNN的工作,对RGB-D的SLAM平台ElasticFusion做扩展。流程图如图所示:
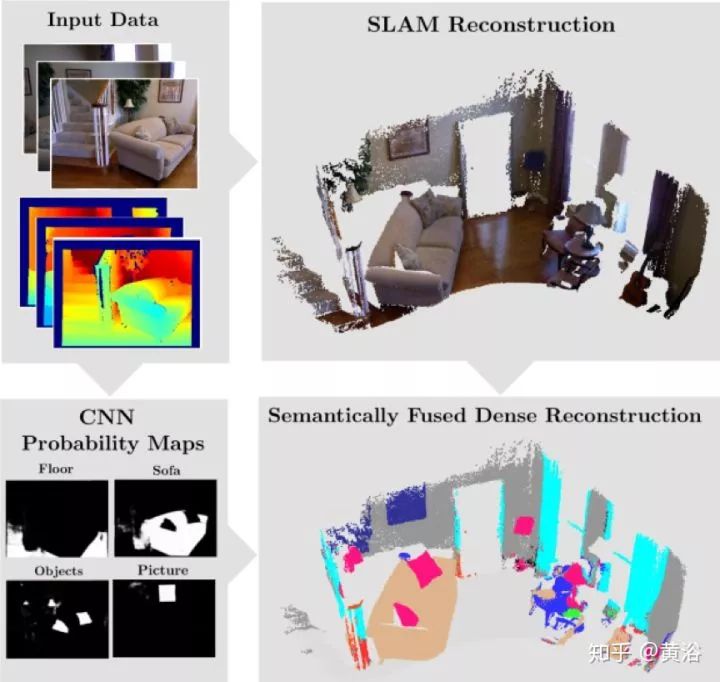
下图是一个结果例子:
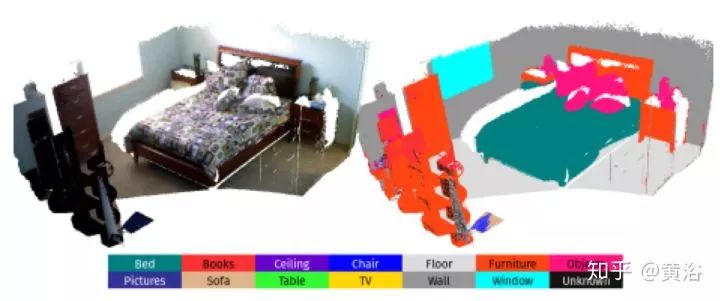
15. Semi-Dense 3D Semantic Mapping from Monocular SLAM
在单目semi-dense SLAM加入深度学习的成果,构成语义地图,系统框图如下:其中2D-3D label transfer是将2D分割投射回3-D特征点云空间。
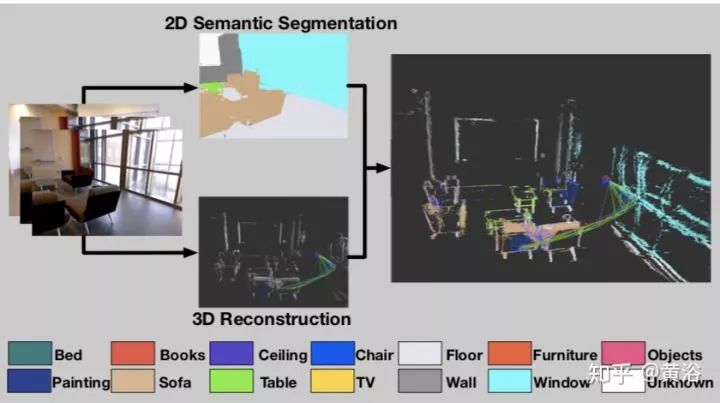
下面是一个算法流程图,包括三个进程:Keyframe selection, 2D semantic segmentation, 和3D reconstruction with semantic optimization。
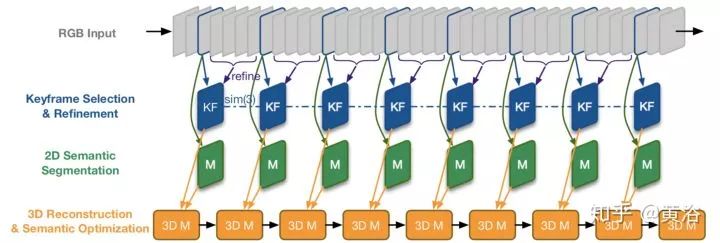
语义分割采用DeepLab-v2,SLAM是以前的LSD-SLAM,而Dense Conditional Random Fields(CRFs)负责3-D的融合。下图是一个结果例子:
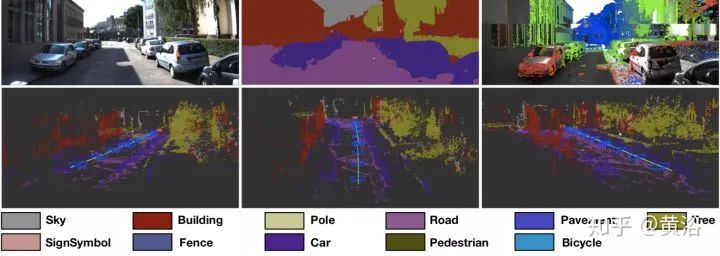
16. CubeSLAM: Monocular 3D Object Detection and SLAM without Prior Models
以前在3D目标检测中介绍过。这里重点是,作为一个multi-view object SLAM系统,3-D cuboid proposals在Multi-view bundle adjustment (BA)得到优化。
系统工作示意图如下:
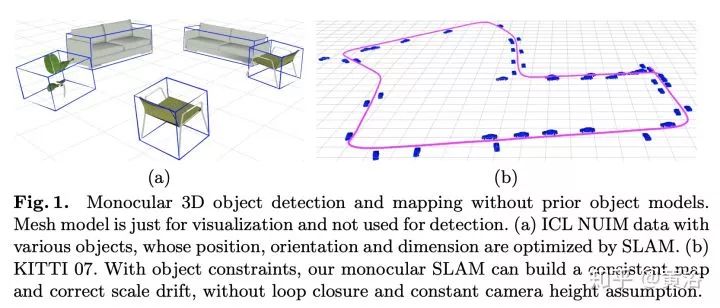
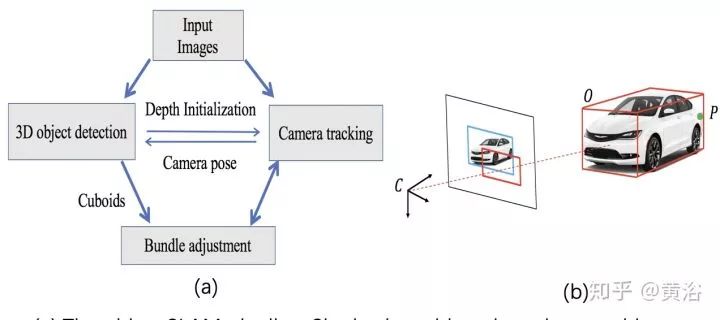
下图(a) 是目标SLAM 流水线,而(b)是BA中摄像头,目标和点之间的测量误差。
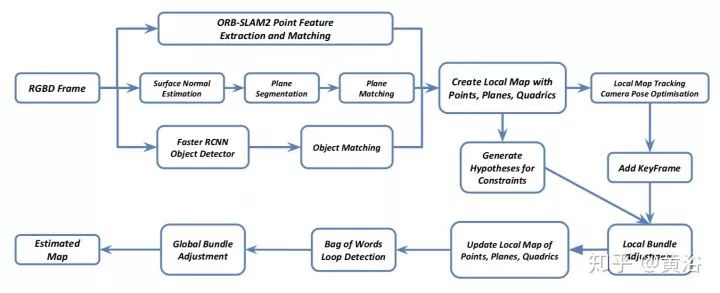
17. Structure Aware SLAM using Quadrics and Planes
还是在ORB-SLAM2加入深度学习元素,如下图:faster RCNN用于目标检测,目标跟踪结果和feature matching融合。
18. SegMap: 3D Segment Mapping using Data-Driven Descriptors
如下图包括5部分:segment extraction, description, localization, map reconstruction, 和 semantics extraction。
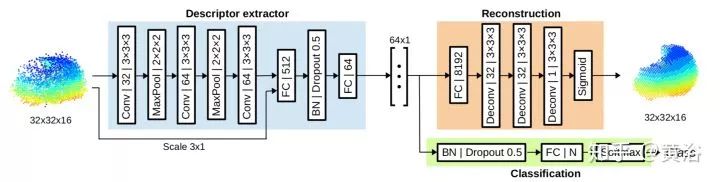
下图的FCN是附加在SegMap descriptor提取语义信息的:
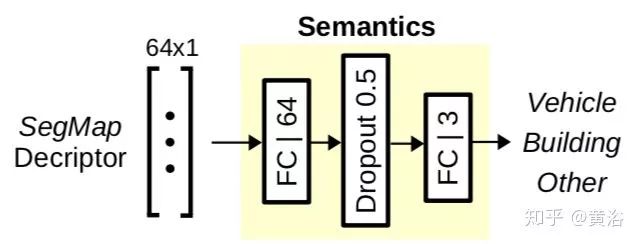
下图是从KITTI dataset提取出来的segments:vehicles, buildings, other。
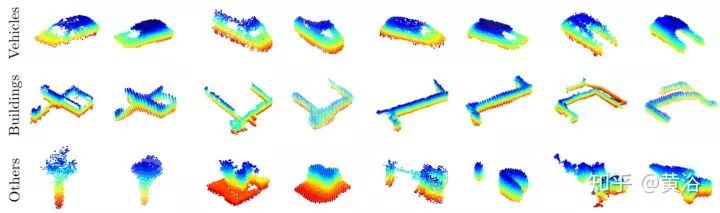
19. Place Categorization and Semantic Mapping on a Mobile Robot
还是基于CNN的工作,因为训练的是one-vs-all的分离器,系统可以在线学习新类目标,而domain knowledge加入Bayesian filter framework可实现temporal coherence。下图是产生的语义图例子:
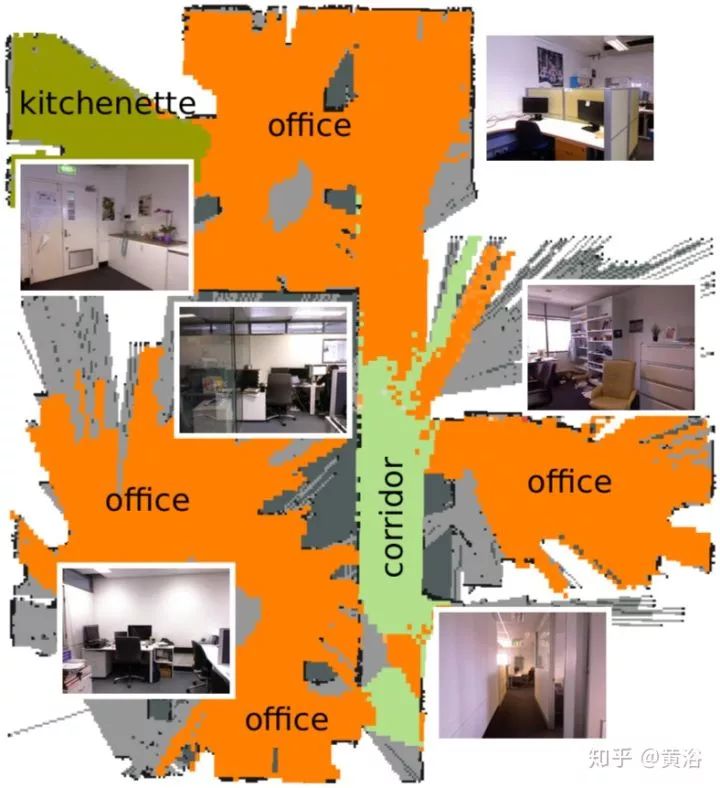
如下是语义图的结构:为绘制metric map和Semantic Map,采用occupancy grid mapping算法,每个语义层建立一个地图层。
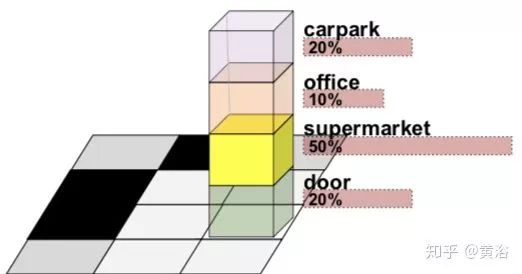
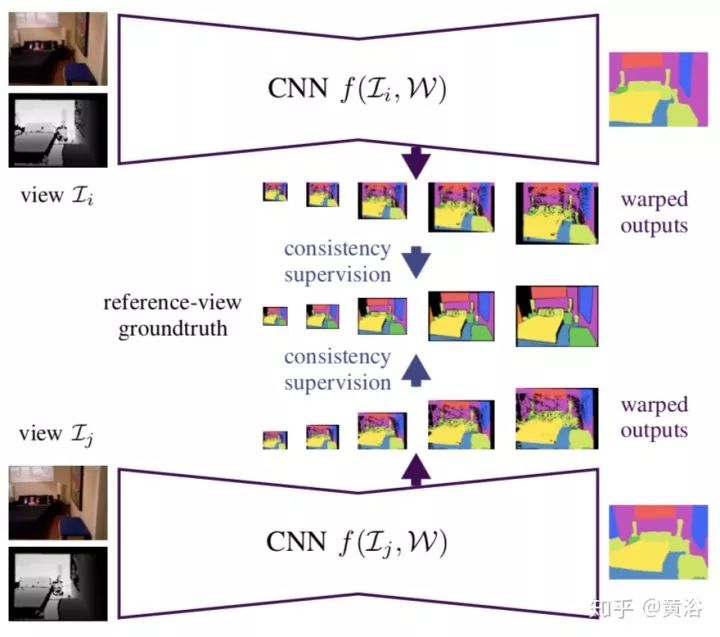
20. Multi-View Deep Learning for Consistent Semantic Mapping with RGB-D Cameras
基于CNN做图像的语义分割,特别是采用CNN学习多帧连续的语义性。之后和深度图融合。
CNN模型如图所示:
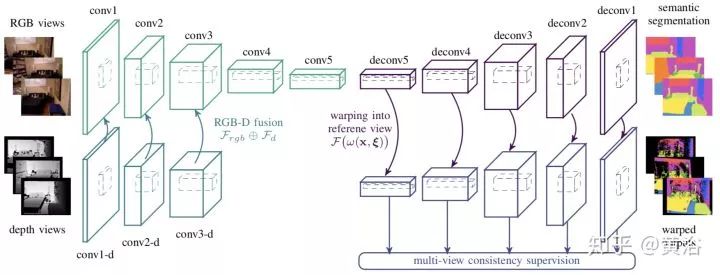
下图是经典的CNN encoder-decoder architecture:
21. Co-Fusion: Real-time Segmentation, Tracking and Fusion of Multiple Objects
一个输入RGB-D的dense SLAM系统,其中目标的模型包括两种:active 和 inactive。下图是其数据流:
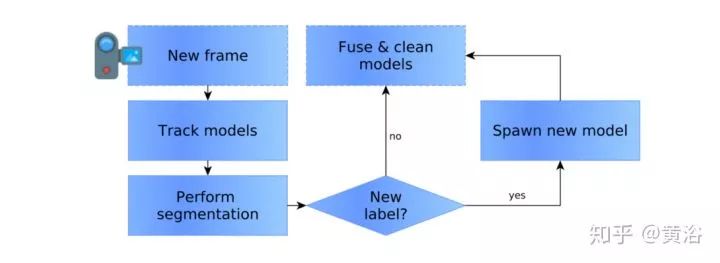
起初系统只有一个目标模型:active的背景模型。跟踪(pose tracking),分割(包括运动分割和图像分割),然后是融合得到新模型。运动分割基于CRF方法,图像分割基于深度学习模型SharpMask,而融合基于surfel模型(ElasticFusion)。
下图是一个结果例子:

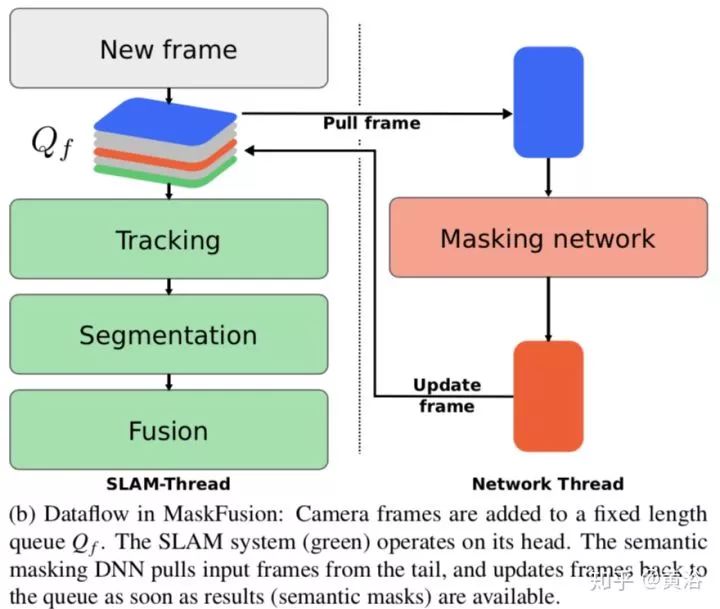
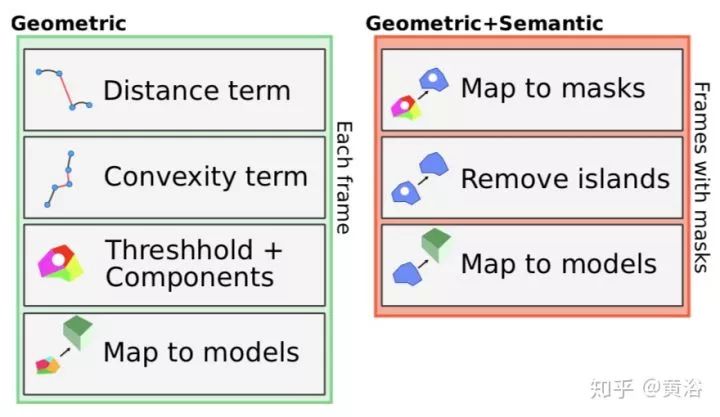
22. MaskFusion: Real-Time Recognition, Tracking and Reconstruction of Multiple Moving Objects
还是CNN的成果介入,提出一个MaskFusion,即RGB-D SLAM的平台。下图展示的MaskFusion后端的数据流:
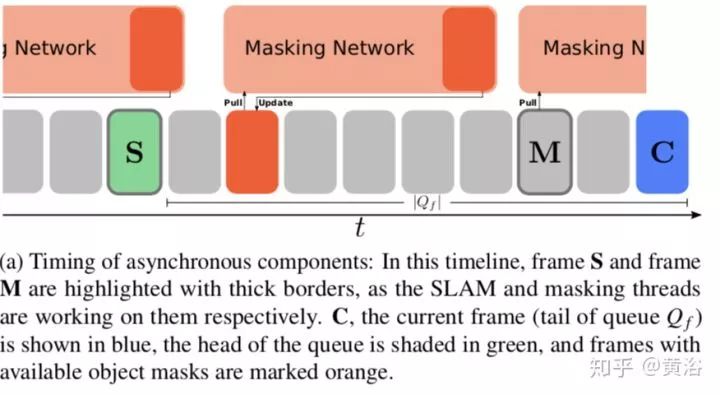
下图是分割方法的拆解:(a) RGB (b) depth, (c)-(g) 各个步骤时候的结果.

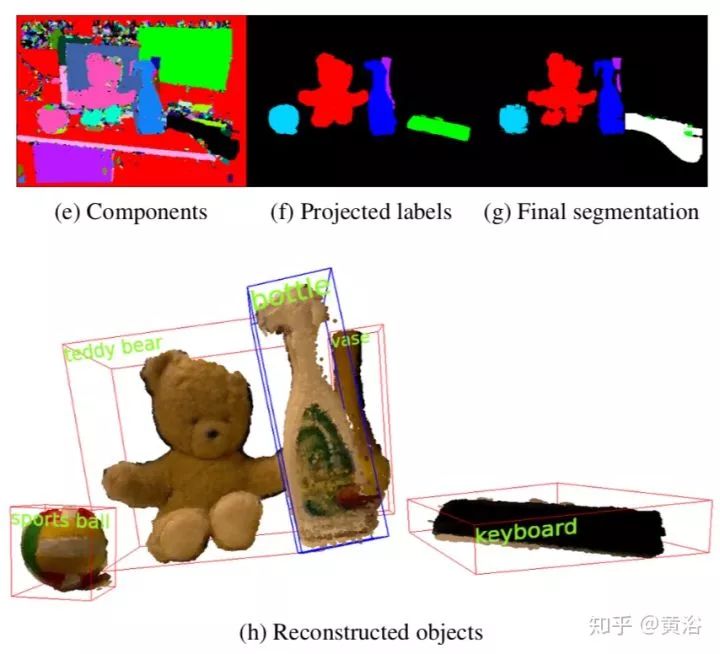
而这里是分割的流程图:
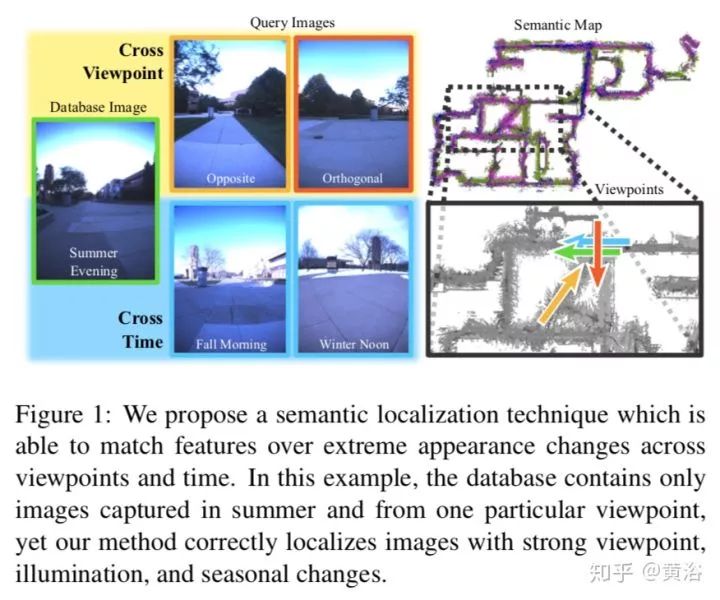
23. Semantic Visual Localization
本文是一个实现定位的generative model,基于descriptor learning,训练的时候加上semantic scene completion作为附加任务。
一个语义定位的例子如下图:夏天拍摄的图像放入数据库,在季节变化后从不同的视角拍摄的图像仍然可以成功定位。
下图是descriptor learning采用的VED模型结构:
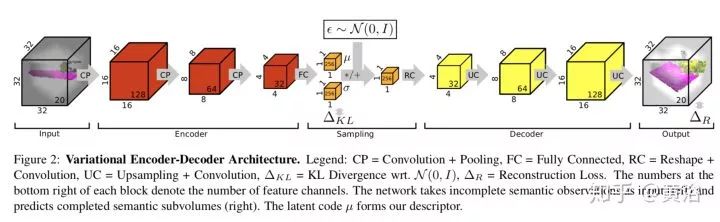
24. Joint Detection, Tracking and Mapping by Semantic Bundle Adjustment
本文给出一个Semantic Bundle Adjustment framework,在跟踪摄像头运动和环境建图同时,
静态目标被检测出来,而检测的目标可以参与全局语义优化中。模型数据库保存了检测的目标,有2-D和3-D特征点信息。BA最后优化的是摄像头的姿态和各个目标的姿态。
下图是展示SBA和传统SLAM的不同,将目标检测加入pose graph可以改进SLAM。
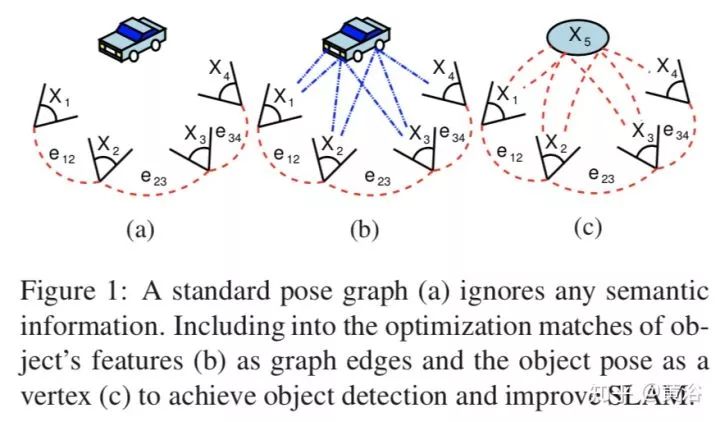
下图展示SLAM的结果:(a) 误差累计后不能做闭环; (b) 集成目标检测和语义分割可以做隐形的闭环,改进重建结果。

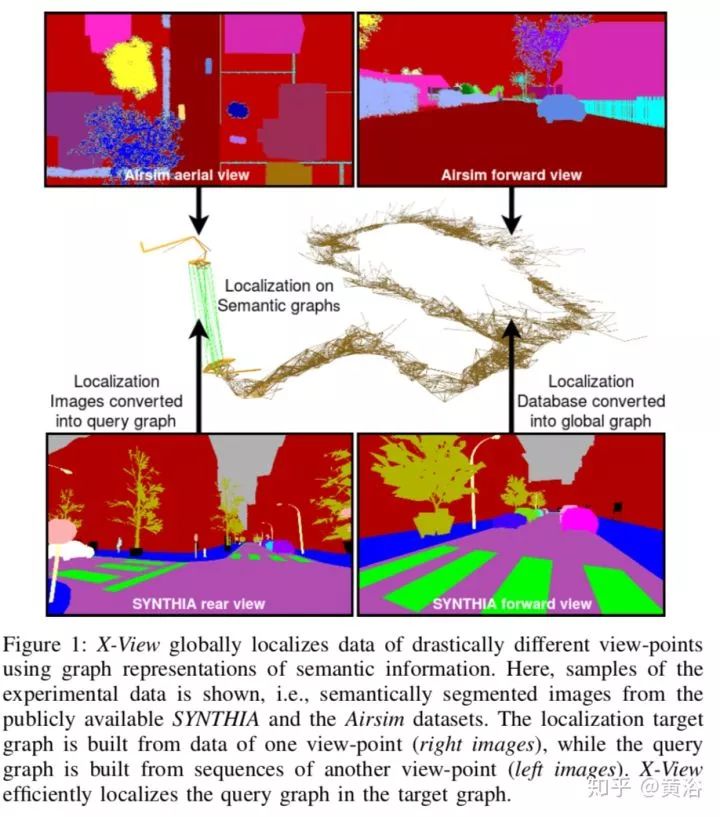
25. X-View: Graph-Based Semantic Multi-View Localization
X-View还是基于深度学习语义分割结果帮助定位。下面是一个能清楚展示系统工作原理的示意图:
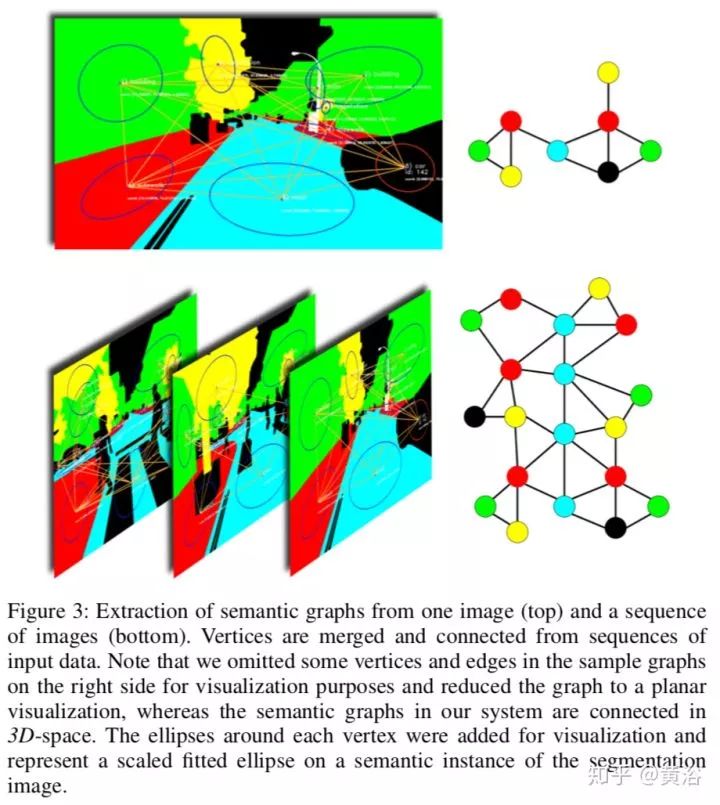
X-View是基于图的多视角定位,其中语义图描述子,vertex descriptor,是定位的关键。每个图的节点,会提取random walk描述子,在下一步匹配定位时候用。下面就是它的系统框图:
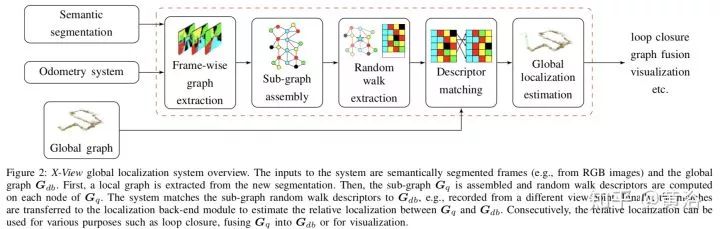
下图告诉我们如何从图像输入中提取语义图:
推荐阅读
从零开始一起学习SLAM | 不推公式,如何真正理解对极约束?
从零开始一起学习SLAM | 理解图优化,一步步带你看懂g2o代码
深度学习遇到SLAM | 如何评价基于深度学习的DeepVO,VINet,VidLoc?
新型相机DVS/Event-based camera的发展及应用

觉得有用,给个好看啦~




