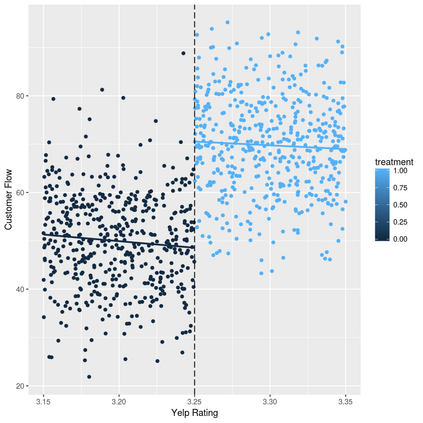
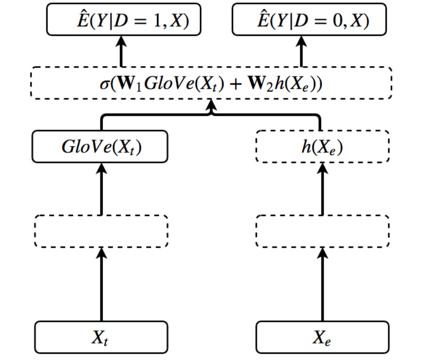
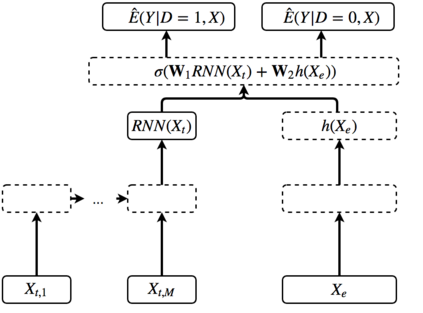
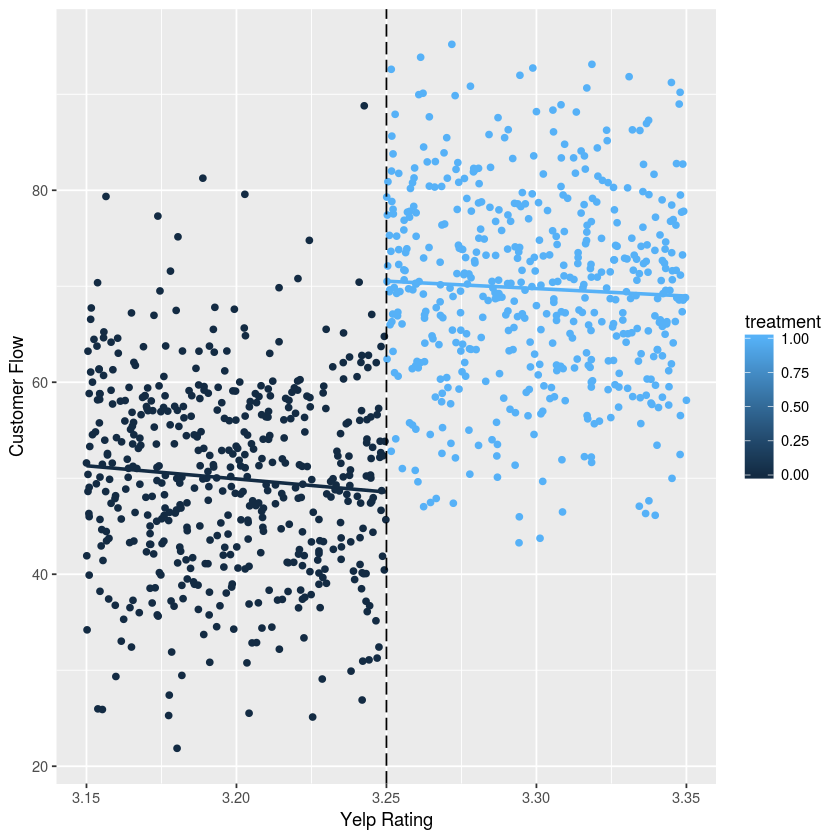
The era of big data provides researchers with convenient access to copious data. However, people often have little knowledge about it. The increasing prevalence of big data is challenging the traditional methods of learning causality because they are developed for the cases with limited amount of data and solid prior causal knowledge. This survey aims to close the gap between big data and learning causality with a comprehensive and structured review of traditional and frontier methods and a discussion about some open problems of learning causality. We begin with preliminaries of learning causality. Then we categorize and revisit methods of learning causality for the typical problems and data types. After that, we discuss the connections between learning causality and machine learning. At the end, some open problems are presented to show the great potential of learning causality with data.
翻译:海量数据时代为研究人员提供了方便的获取大量数据的机会,然而,人们往往对此知之甚少。海量数据越来越普遍,对传统的学习因果关系方法提出了挑战,因为海量数据是针对数据数量有限和先前确证的因果关系知识而开发的。这项调查的目的是通过对传统和前沿方法进行全面和结构化的审查,并讨论某些公开的学习因果关系问题,从而缩小海量数据与学习因果关系之间的差距。我们首先从学习因果关系的预备开始。然后,我们分类和重新研究典型问题和数据类型的学习因果关系方法。之后,我们讨论学习因果关系与机器学习之间的联系。最后,我们提出了一些公开的问题,以显示从数据中学习因果关系的巨大潜力。