一个模型通杀8大视觉任务,一句话生成图像、视频、P图、视频处理...都能行 | MSRA&北大出品
丰色 发自 凹非寺
量子位 报道 | 公众号 QbitAI
有这样一个模型。
它可以做到一句话生成视频:

不仅零样本就能搞定,性能还直达SOTA。
它的名字,叫“NüWA”(女娲)。
“女娲女娲,神通广大”,正如其名,一句话生成视频只是这个模型的技能之一。
除此之外,一句话生成图片,草图生成图像、视频,图像补全,视频预测,图像编辑、视频编辑——
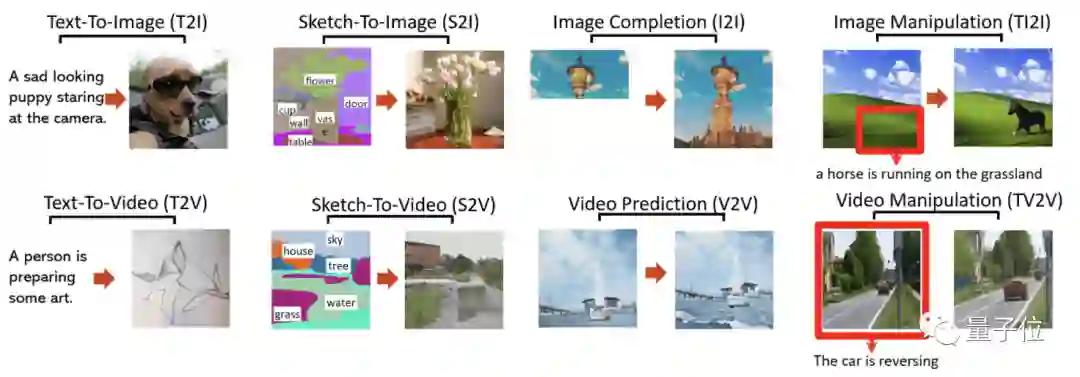
一共八种视觉任务,它其实全部都能搞定。
完全是一位不折不扣的“全能型选手”。
它,就是由微软亚研院和北大联合打造的一个多模态预训练模型,在首届微软峰会上亮相。
目前,在推特上已“小有热度”。
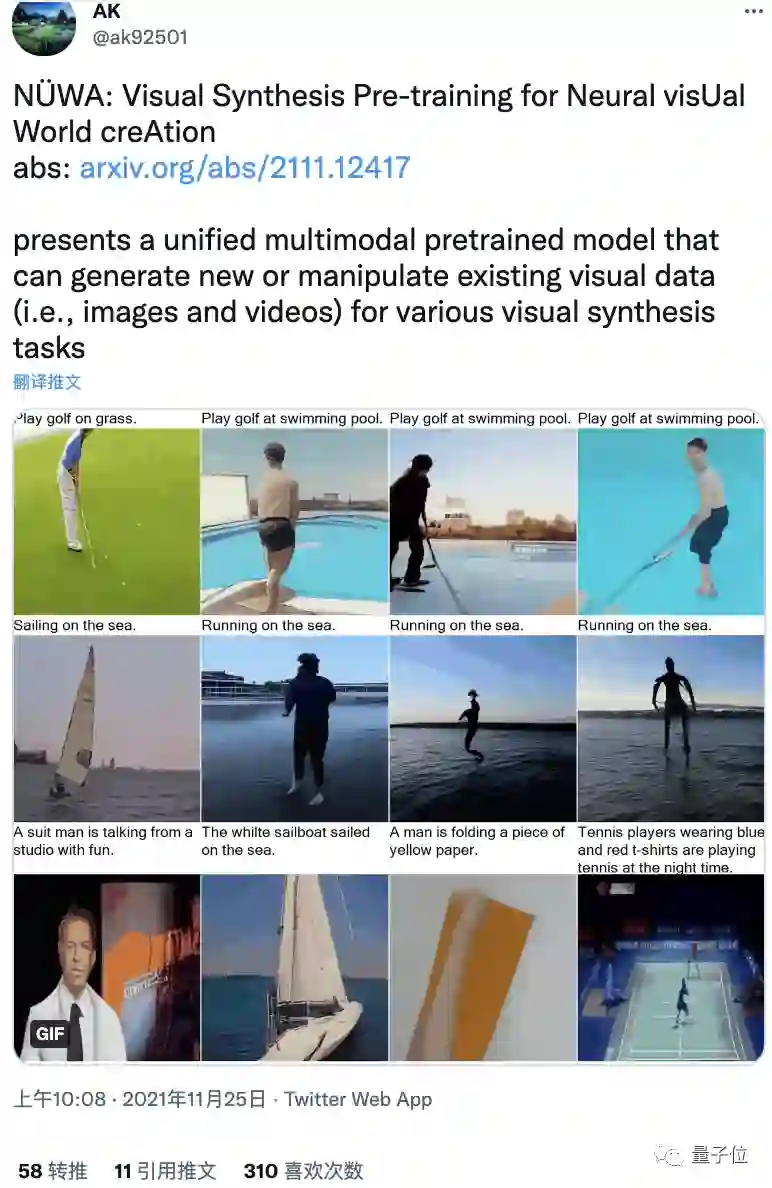
八项全能“女娲”,单拎出来也不差
所以这个全能型选手究竟表现如何?
直接与SOTA模型对比,来看看“她”在各项任务上的表现。
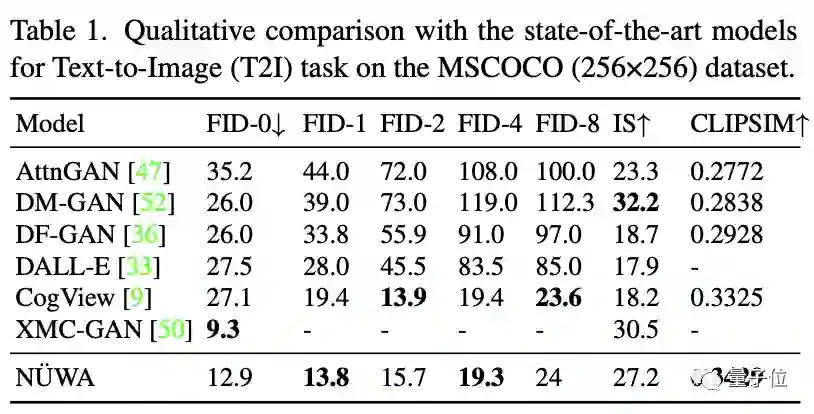
在文本生成图像中,不得不说,即使“女娲”的FID-0得分不及XMC-GAN,但在实际效果中,“女娲”生成的图肉眼可见的更好,清晰又逼真。

文本到视频中,“女娲”每一项指标都获得了第一名,从逐帧图片来看,差距很明显。
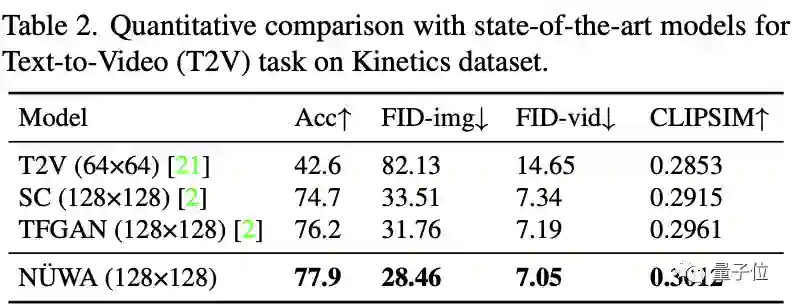

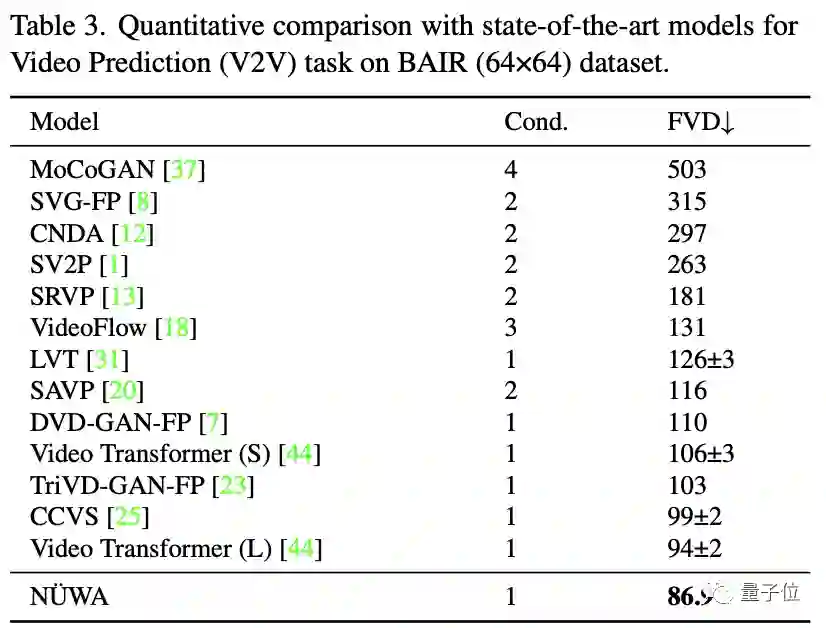
在视频预测中,所有模型使用64x64的分辨率,Cond.代表供预测的帧数。
尽管只有1帧,“女娲”也将FVD得分从94±2降到86.9。
草图转图像时,与SOTA模型相比,“女娲”生成的卡车都更逼真。

而在零样本的图像补全任务中,“女娲”拥有更丰富的“想象力”。

在零样本的图像编辑任务中,“女娲”明显比SOTA模型的“P图”能力更强。
并且,它的另一个优势是推理速度,几乎50秒就可以生成一个图像;而Paint By Word在推理过程中需要额外的训练,大约需要300秒才能收敛。

而草图生成视频以及文本引导的视频编辑任务,是本次研究首次提出,目前还没有可比对象。
直接上效果:

看,像上面这些仅用色块勾勒轮廓的视频草图,经“女娲”之手就能生成相应视频。
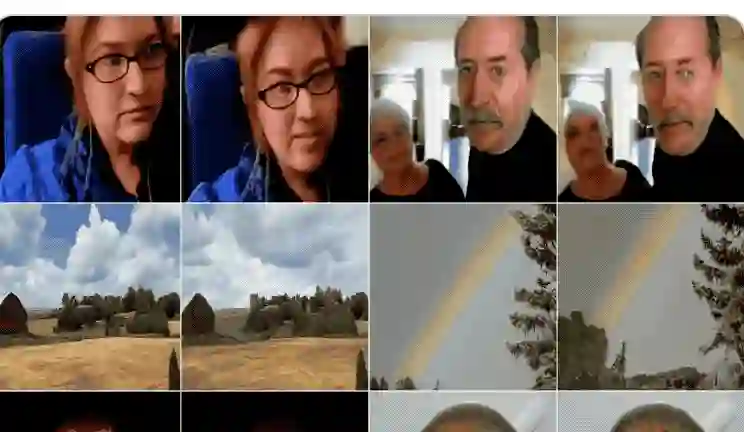
而输入一段潜水视频,“女娲”也能在文本指导下让潜水员浮出水面、继续下潜,甚至“游”到天上。

可以说,“女娲”不仅技能多,哪个单项拿出来也完全不赖。
如何实现?
这样一个无论操作对象是图像还是视频,无论是合成新的、还是在已有素材上改造都能做到做好的“女娲”,是如何被打造出来的呢?
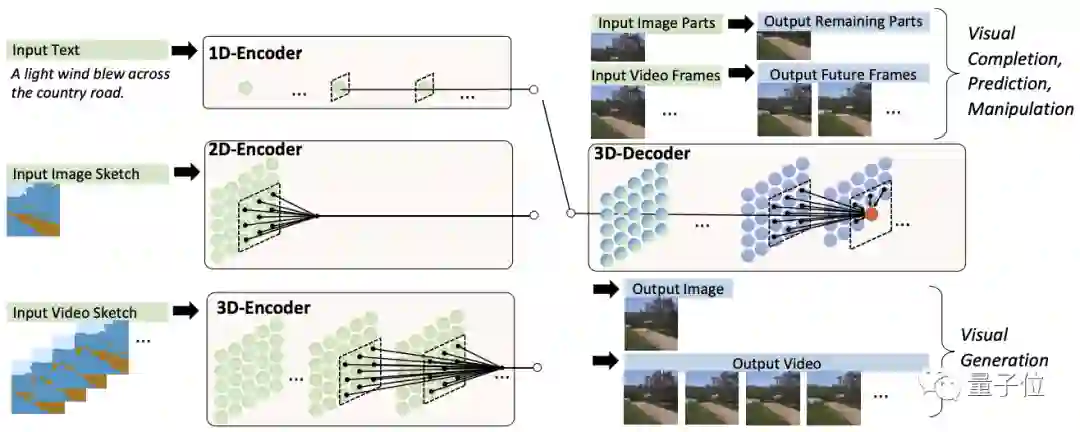
其实不难,把文字、图像、视频分别看做一维、二维、三维数据,分别对应3个以它们为输入的编码器。
另外预训练好一个处理图像与视频数据的3D解码器。
两者配合就获得了以上各种能力。
其中,对于图像补全、视频预测、图像视频编辑任务,输入的部分图像或视频直接馈送给解码器。
而编码解码器都是基于一个3D Nearby的自注意力机制(3DNA)建立的,该机制可以同时考虑空间和时间轴的上局部特性,定义如下:
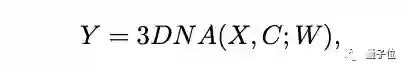
W表示可学习的权重,X和C分别代表文本、图像、视频数据的3D表示:
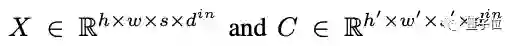
其中,h和w表示空间轴上的token数,s表时间轴上的token数(文本默认为1),d表示每个token的维数。
如果C=X,3DNA表示对目标X的自注意;如果C≠X,3DNA表示对在条件C下目标X的交叉注意。
该机制不仅可以降低模型的计算复杂度,还能提高生成结果的质量。
此外,模型还使用VQ-GAN替代VQ-VAE进行视觉tokenization,这也让生成效果好上加好。
团队介绍
一作Chenfei Wu,北京邮电大学博士毕业,现工作于微软亚研院。
共同一作Jian Liang, 来自北京大学。
其余作者包括微软亚研院的高级研究员Lei Ji,首席研究员Fan Yang,合作首席科学家Daxin Jiang,以及北大副教授方跃坚。
通讯作者为微软亚研院的高级研究员&研究经理段楠。
论文地址:
https://arxiv.org/abs/2111.12417
参考链接:
[1]https://www.microsoft.com/en-us/research/video/research-talk-nuwa-neural-visual-world-creation-with-multimodal-pretraining/
[2]https://www.youtube.com/watch?v=jhmJ5qb-JAU
[3]https://twitter.com/ak92501/status/1463691106416214019
— 完 —
本文系网易新闻•网易号特色内容激励计划签约账号【量子位】原创内容,未经账号授权,禁止随意转载。
直播免费报名!
与AI大咖一起预见智能科技新未来
量子位「MEET2022智能未来大会」将于11.30日全程直播,李开复博士、张亚勤教授、IBM大中华区CTO谢东、百度集团副总裁吴甜、京东集团副总裁何晓冬、商汤科技联创杨帆、小冰公司CEO李笛 等嘉宾邀你参会、一起预见智能科技新未来!
扫码可预约直播or加入大会交流群↓↓ 入群还可抽取惊喜礼品&现金红包哦~





<< 左右滑动查看更多 >>

量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
一键三连「分享」「点赞」和「在看」
科技前沿进展日日相见 ~

