【泡泡一分钟】ClothNet:基于图片生成真实感着装图(ICCV2017-79)
每天一分钟,带你读遍机器人顶级会议文章
标题:A Generative Model of People in Clothing
作者:Christoph Lassner,Gerard Pons-Moll,Peter V. Gehler
来源:ICCV 2017 ( IEEE International Conference on Computer Vision)
播音员:水蘸墨
编译:颜青松(89)
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

本文展示了第一个使用图像训练进而生成全身着衣的网络。与传统使用复杂的CG渲染的方法不同,本文的算法不需要对人体做高精度的三维扫描,只需要大量的图像即可完成。本文方法的关键难点在于如何将人体姿态、体形和外貌信息加入到网络中,从而保证生成图片的质量。也正是由于该问题较难解决,基于图像的方法一直没有得到足够关注。
本文经过研究发现,该问题可以通过两步来解决:首先利用人体信息和衣服信息进行语义分割,然后再在分割信息基础上利用条件模型生成真实感图像。本文提出的整个模型可微调,能够适应各种姿态、外形和衣服颜色。
本文模型的结果是根据图片生成不同类型、风格着装的新图片,当然也可以“凭空”生成一些具有真实感的着装的照片。经过大量的实验,本文的结果还是非常不错的,同时也证明了纯粹使用图片的方式是可行的。

图1 上图展示了本文算法基于姿态生成的一些真实感着装图片
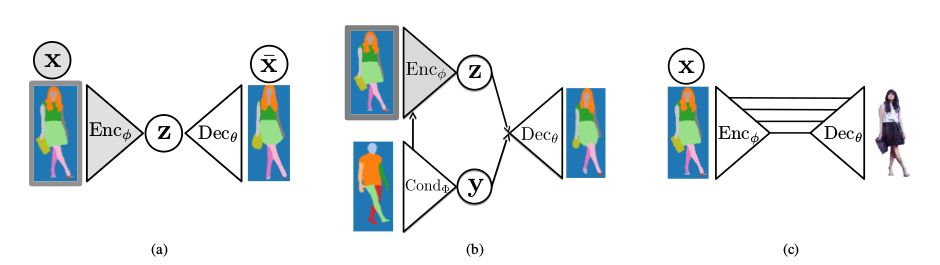
图2 上图展示了本文模型中的三个模块,(a)主要考虑的是语义分割信息;(b)考虑的是姿态信息;(c)是一个端到端的生成真实感图像的模块。

Abstract
We present the first image-based generative model of people in clothing for the full body. We sidestep the commonly used complex graphics rendering pipeline and the need for high-quality 3D scans of dressed people. Instead, we learn generative models from a large image database.
The main challenge is to cope with the high variance in human pose, shape and appearance. For this reason, pure image-based approaches have not been considered so far. We show that this challenge can be overcome by splitting the generating process in two parts. First, we learn to generate a semantic segmentation of the body and clothing. Second, we learn a conditional model on the resulting segments that creates realistic images.
The full model is differentiable and can be conditioned on pose, shape or color. The result are samples of people in different clothing items and styles. The proposed model can generate entirely new people with realistic clothing. In several experiments we present encouraging results that suggest an entirely data-driven approach to people generation is possible.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号(paopaorobot_slam)。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/forums/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com





