深度学习中7种最优化算法的可视化与理解
关注“深度学习自然语言处理”,一起学习一起冲鸭!
设为星标,第一时间获取更多干货

来自 https://zhuanlan.zhihu.com/p/41799394
首先给出学习率lr,初始x
while True:
x = x - lr*df/dx
 梯度下降法
梯度下降法
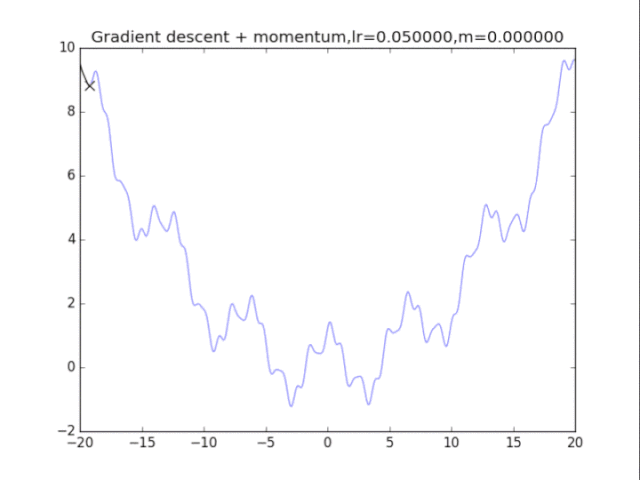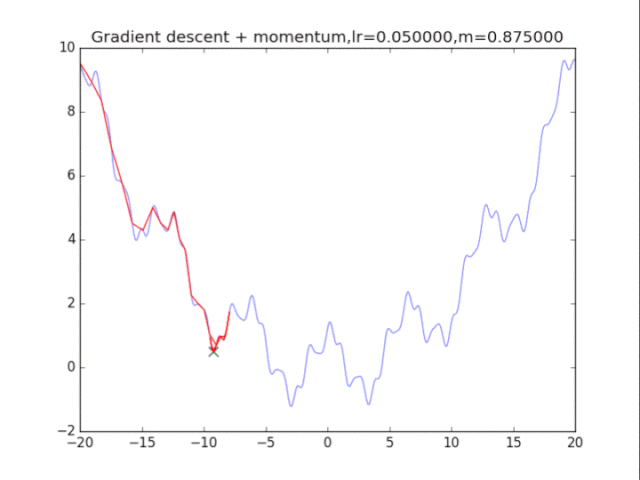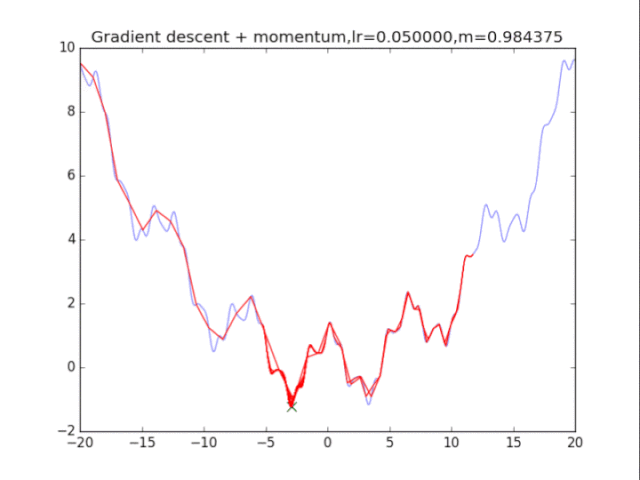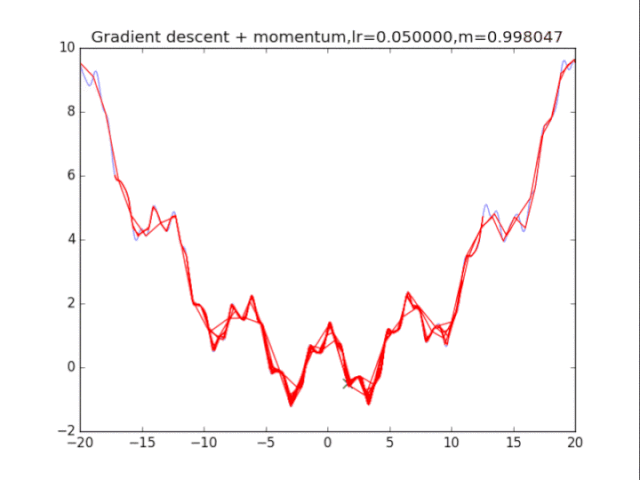
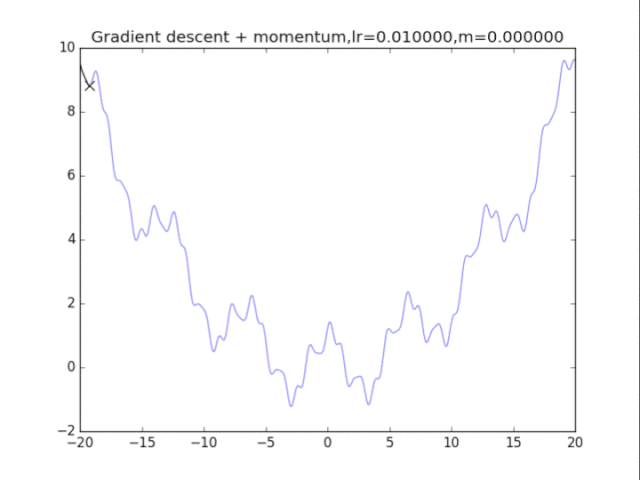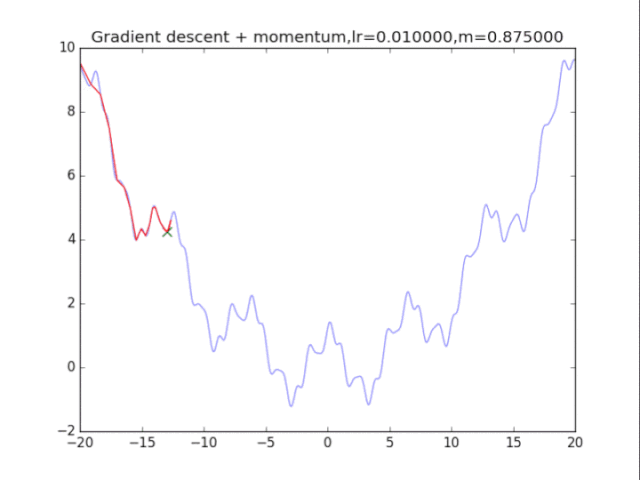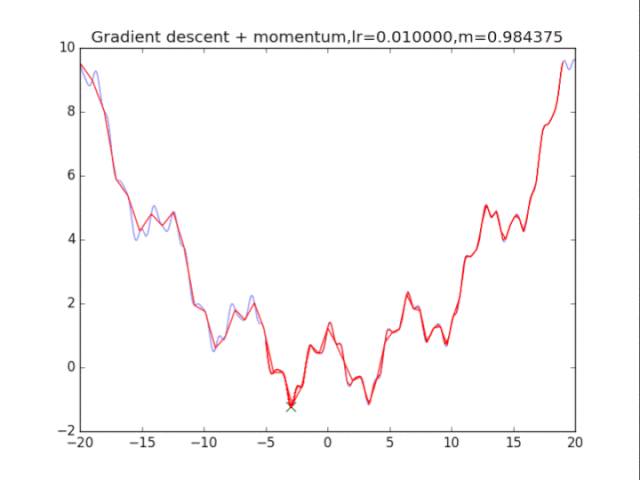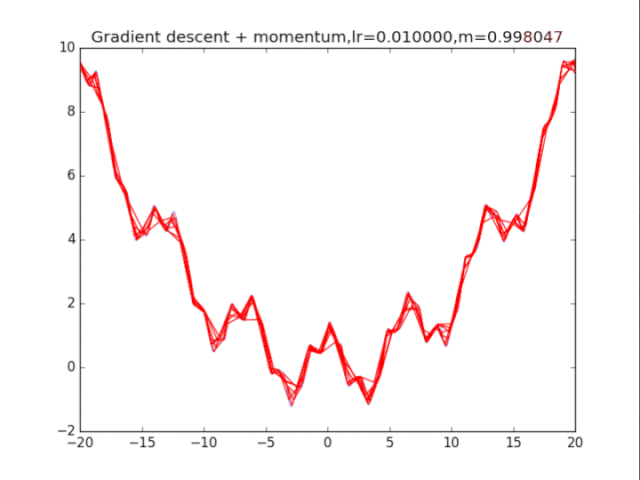
首先给出学习率lr,动量参数m
初始速度v=0,初始x
while True:
v = m * v - lr * df/dx
x += v

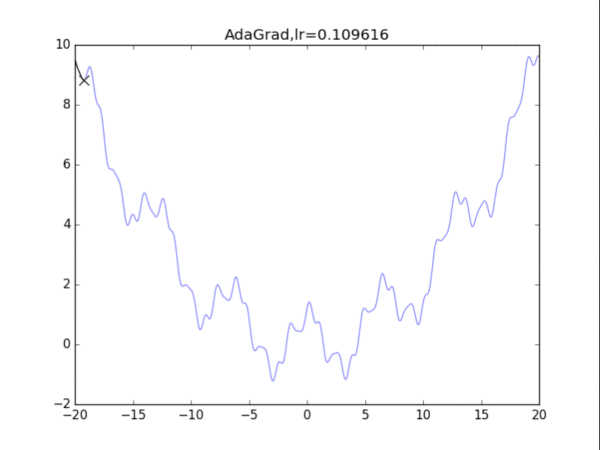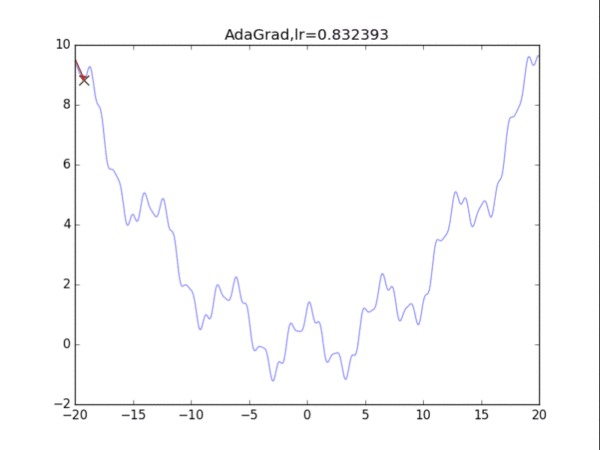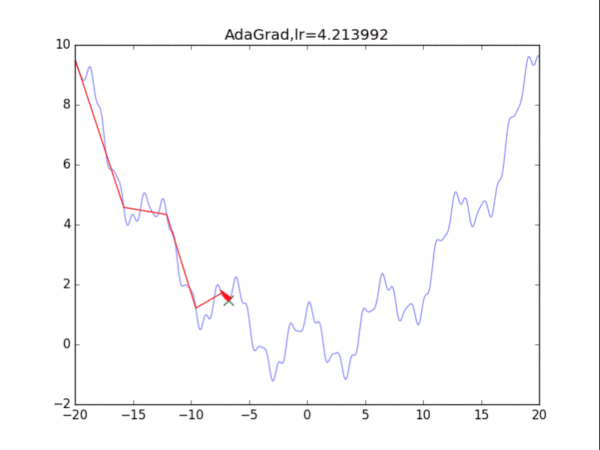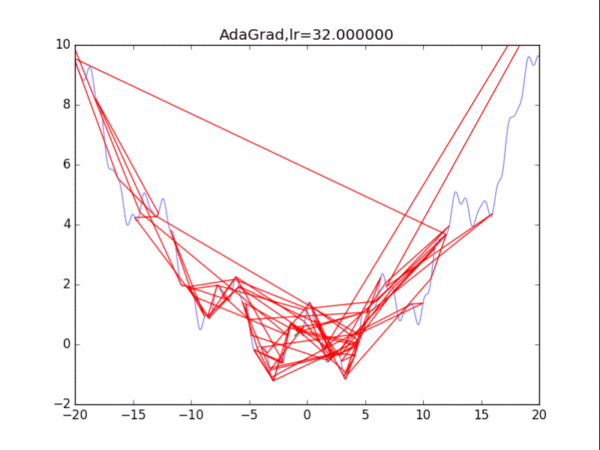
给出学习率lr,delta=1e-7
累计梯度r=0,初始x
while True:
g = df/dx
r = r + g*g
x = x - lr / (delta+ sqrt(r)) * g
给出学习率lr,delta=1e-6,衰减速率p
累计梯度r=0,初始x
while True:
g = df/dx
r = p*r + (1-p)*g*g
x = x - lr / (delta+ sqrt(r)) * g
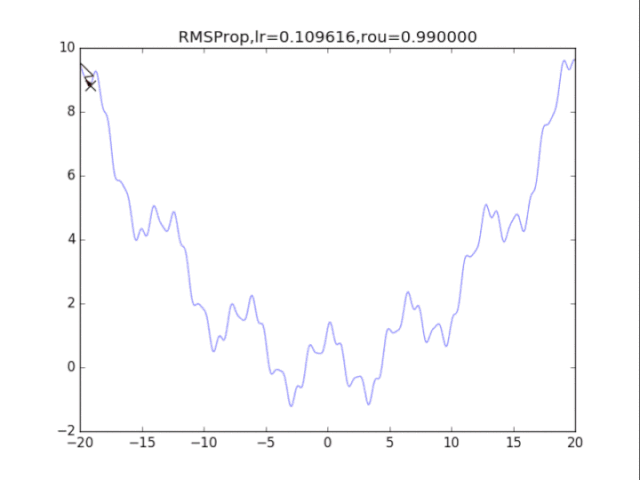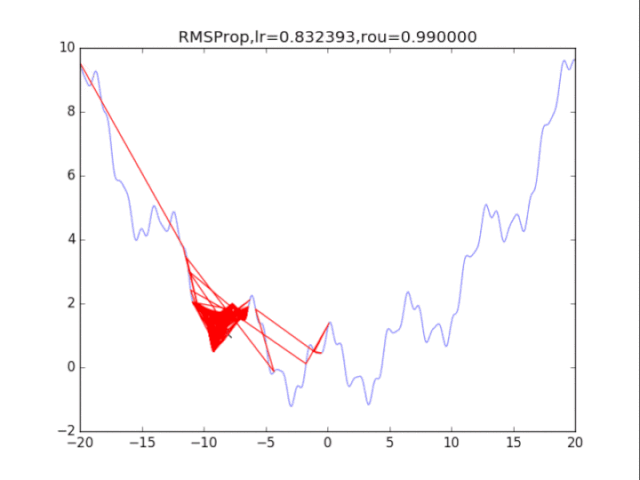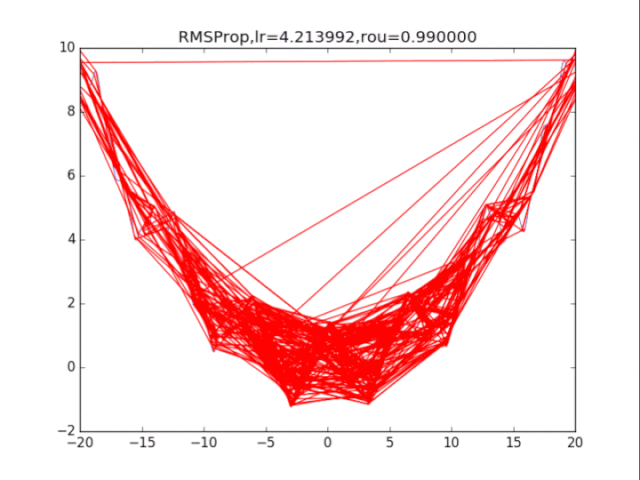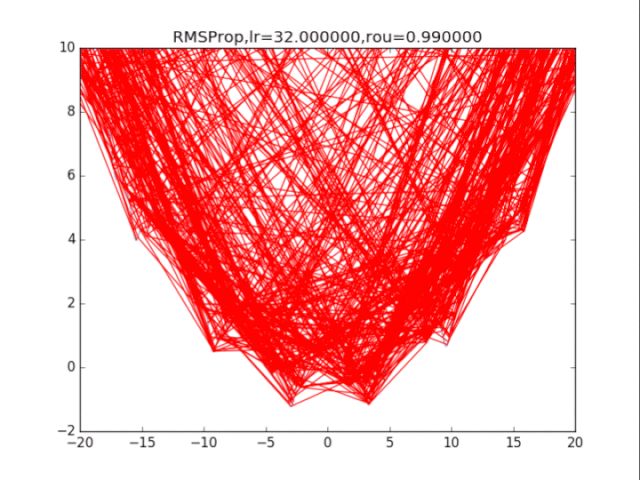
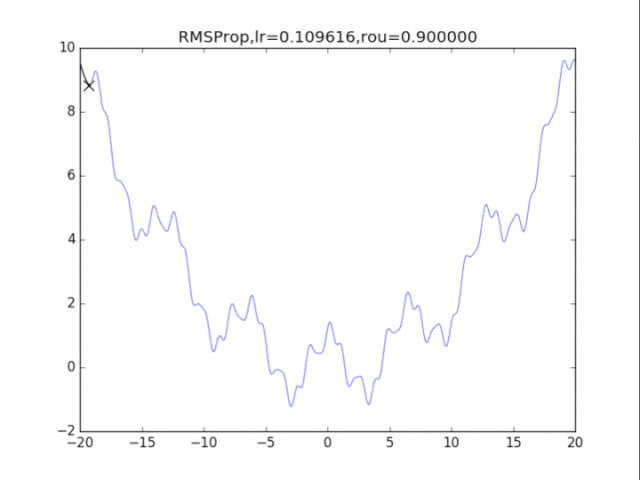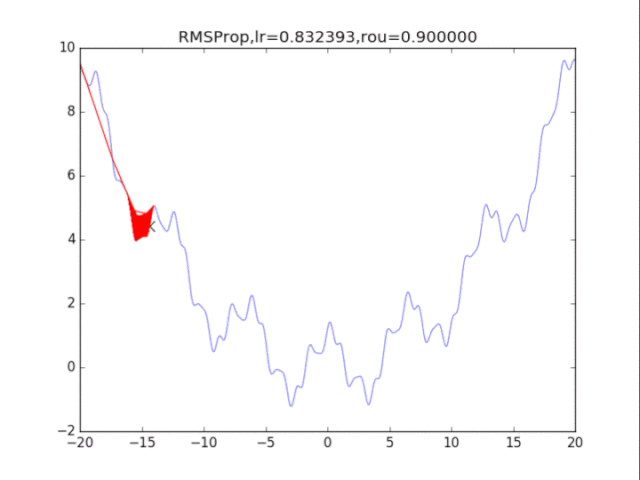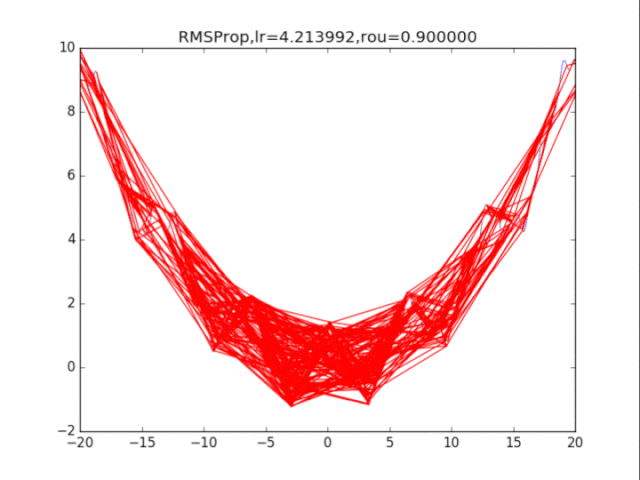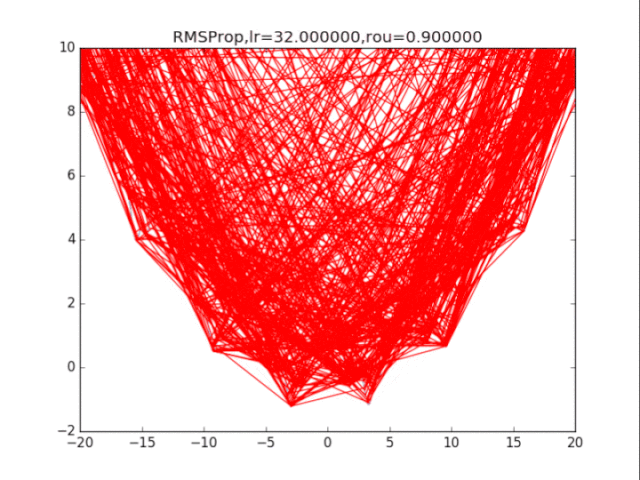
给出学习率lr,delta=1e-8,衰减速率p1=0.9,p2=0.999
累计梯度r=0,初始x ,一阶矩s=0,二阶矩r=0
时间t = 0
while True:
t += 1
g = df/dx
s = p1*s + (1-p1) *g
r = p2*r +(1-p2)*g*g
s = s / (1-p1^t)
r = r / (1-p2^t)
x = x - lr / (delta+ sqrt(r)) * s
初始x
while True:
g = df(x) # 一阶导数
gg = ddf(x) # 二阶导数
x = x - g/gg # 走到曲面的最低点
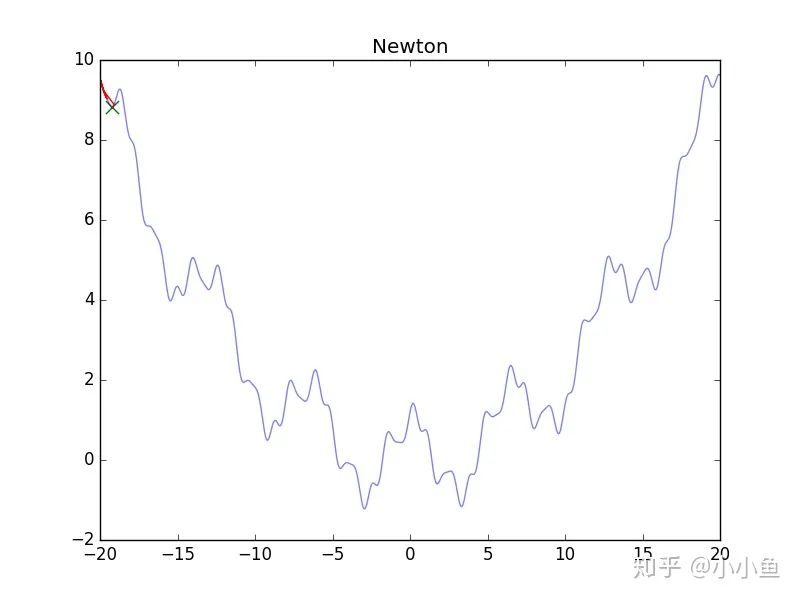 可怜的牛顿法,静态图
可怜的牛顿法,静态图
初始x ,正则化强度alpha
while True:
g = df(x) # 一阶导数
gg = ddf(x) # 二阶导数
x = x - g/(gg+alpha) # 走到曲面的最低点

#coding:utf-8
from __future__ import print_function
import numpy as np
import matplotlib.pyplot as plt
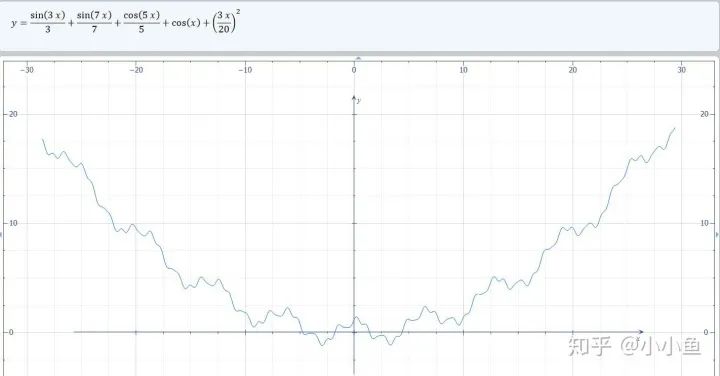
def f(x):
return (0.15*x)**2 + np.cos(x) + np.sin(3*x)/3 + np.cos(5*x)/5 + np.sin(7*x)/7
def df(x):
return (9/200)*x - np.sin(x) -np.sin(5*x) + np.cos(3*x) + np.cos(7*x)
points_x = np.linspace(-20, 20, 1000)
points_y = f(points_x)
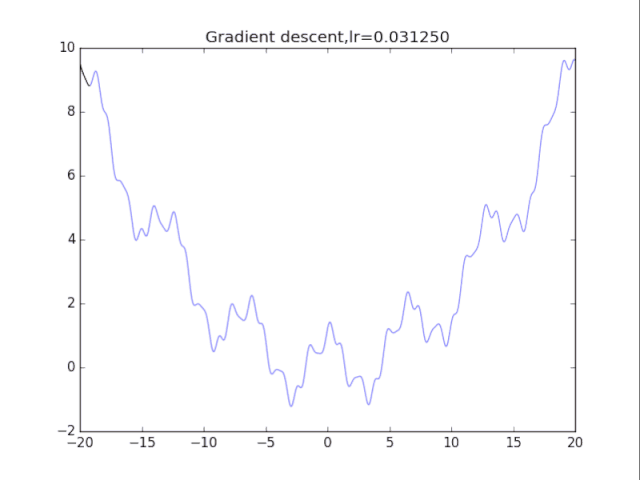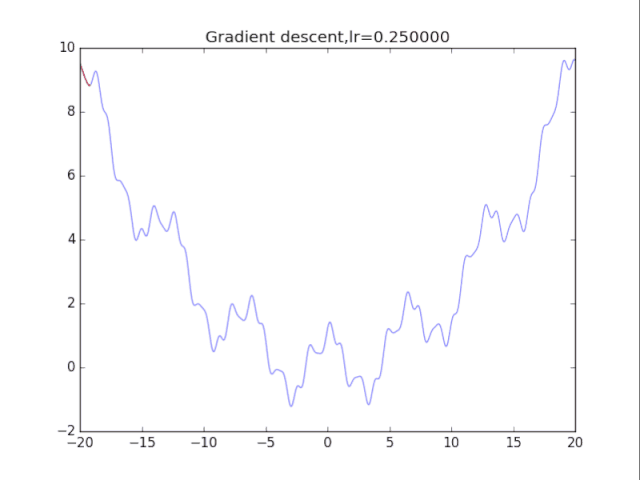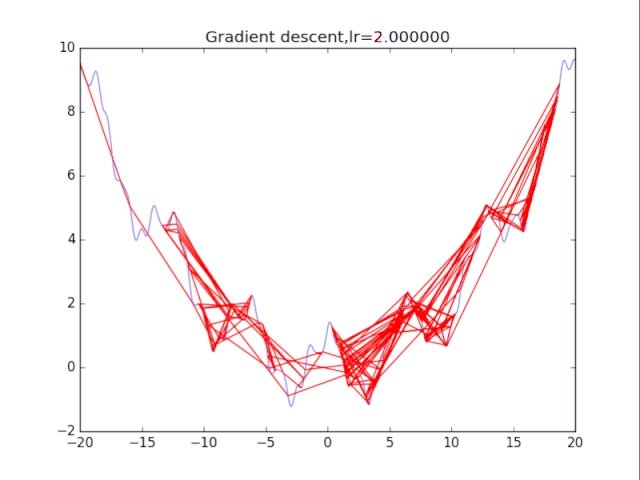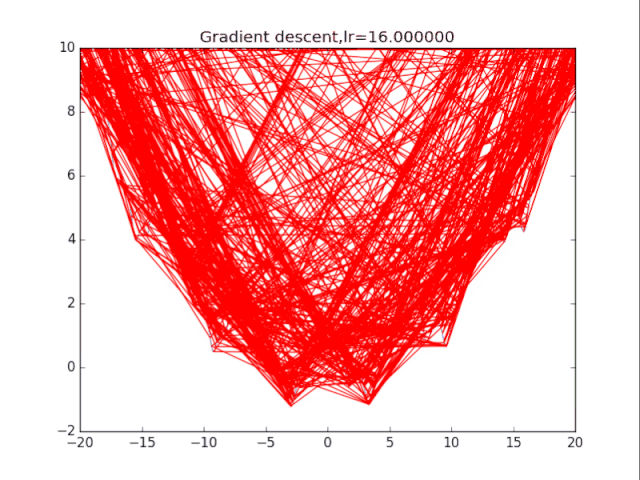
# 纯粹的梯度下降法,GD
for i in range(10):
# 绘制原来的函数
plt.plot(points_x, points_y, c="b", alpha=0.5, linestyle="-")
# 算法开始
lr = pow(2,-i)*16
x = -20.0
GD_x, GD_y = [], []
for it in range(1000):
GD_x.append(x), GD_y.append(f(x))
dx = df(x)
x = x - lr * dx
plt.xlim(-20, 20)
plt.ylim(-2, 10)
plt.plot(GD_x, GD_y, c="r", linestyle="-")
plt.title("Gradient descent,lr=%f"%(lr))
plt.savefig("Gradient descent,lr=%f"%(lr) + ".png")
plt.clf()
# 动量 + 梯度下降法
for i in range(10):
# 绘制原来的函数
plt.plot(points_x, points_y, c="b", alpha=0.5, linestyle="-")
# 算法开始
lr = 0.002
m = 1 - pow(0.5,i)
x = -20
v = 1.0
GDM_x, GDM_y = [], []
for it in range(1000):
GDM_x.append(x), GDM_y.append(f(x))
v = m * v - lr * df(x)
x = x + v
plt.xlim(-20, 20)
plt.ylim(-2, 10)
plt.plot(GDM_x, GDM_y, c="r", linestyle="-")
plt.scatter(GDM_x[-1],GDM_y[-1],90,marker = "x",color="g")
plt.title("Gradient descent + momentum,lr=%f,m=%f"%(lr,m))
plt.savefig("Gradient descent + momentum,lr=%f,m=%f"%(lr,m) + ".png")
plt.clf()
# AdaGrad
for i in range(15):
# 绘制原来的函数
plt.plot(points_x, points_y, c="b", alpha=0.5, linestyle="-")
# 算法开始
lr = pow(1.5,-i)*32
delta = 1e-7
x = -20
r = 0
AdaGrad_x, AdaGrad_y = [], []
for it in range(1000):
AdaGrad_x.append(x), AdaGrad_y.append(f(x))
g = df(x)
r = r + g*g # 积累平方梯度
x = x - lr /(delta + np.sqrt(r)) * g
plt.xlim(-20, 20)
plt.ylim(-2, 10)
plt.plot(AdaGrad_x, AdaGrad_y, c="r", linestyle="-")
plt.scatter(AdaGrad_x[-1],AdaGrad_y[-1],90,marker = "x",color="g")
plt.title("AdaGrad,lr=%f"%(lr))
plt.savefig("AdaGrad,lr=%f"%(lr) + ".png")
plt.clf()
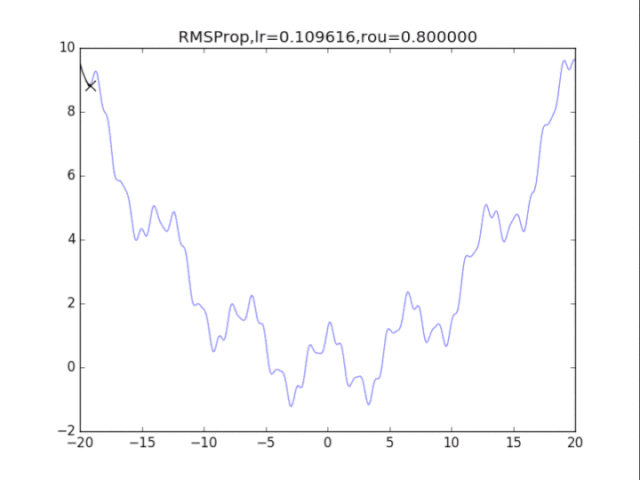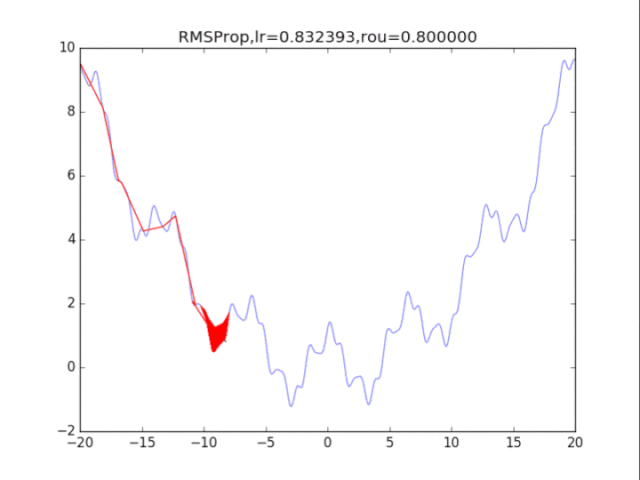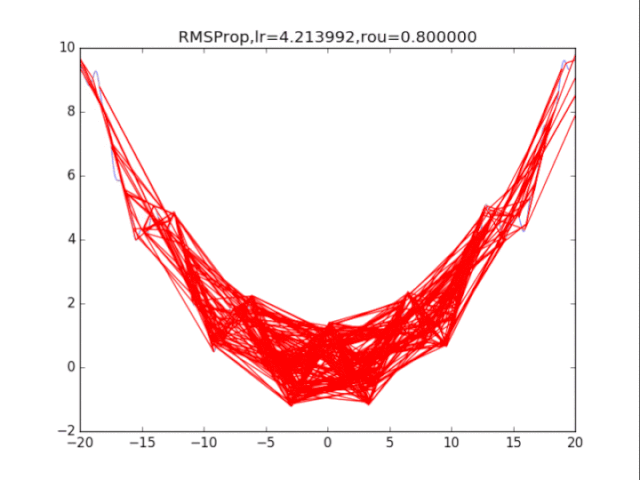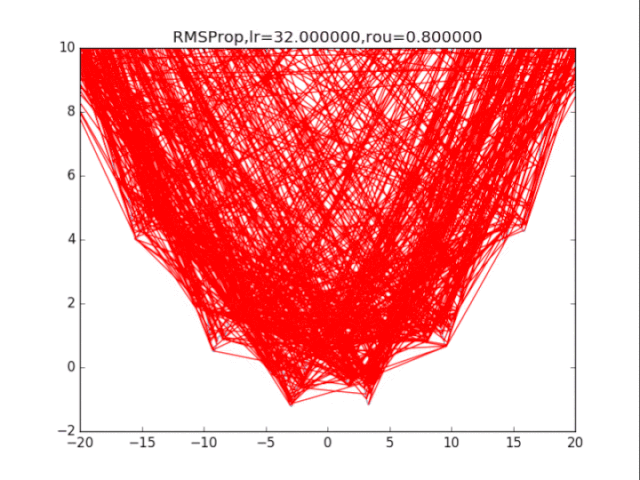
# RMSProp
for i in range(15):
# 绘制原来的函数
plt.plot(points_x, points_y, c="b", alpha=0.5, linestyle="-")
# 算法开始
lr = pow(1.5,-i)*32
delta = 1e-6
rou = 0.8
x = -20
r = 0
RMSProp_x, RMSProp_y = [], []
for it in range(1000):
RMSProp_x.append(x), RMSProp_y.append(f(x))
g = df(x)
r = rou * r + (1-rou)*g*g # 积累平方梯度
x = x - lr /(delta + np.sqrt(r)) * g
plt.xlim(-20, 20)
plt.ylim(-2, 10)
plt.plot(RMSProp_x, RMSProp_y, c="r", linestyle="-")
plt.scatter(RMSProp_x[-1],RMSProp_y[-1],90,marker = "x",color="g")
plt.title("RMSProp,lr=%f,rou=%f"%(lr,rou))
plt.savefig("RMSProp,lr=%f,rou=%f"%(lr,rou) + ".png")
plt.clf()
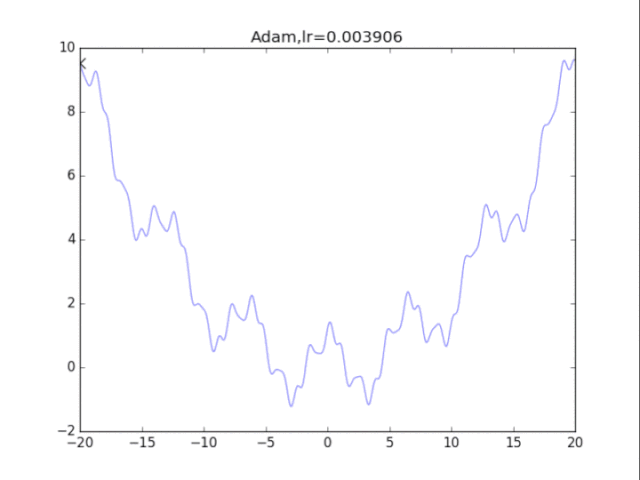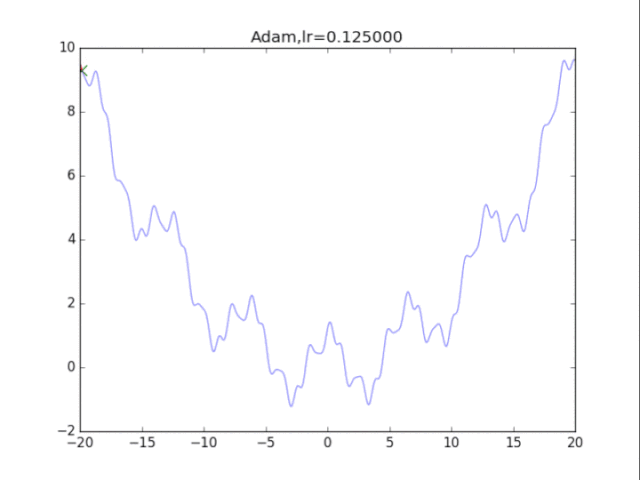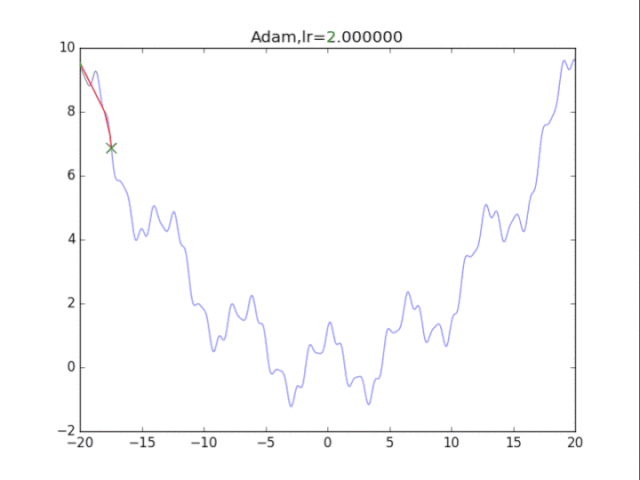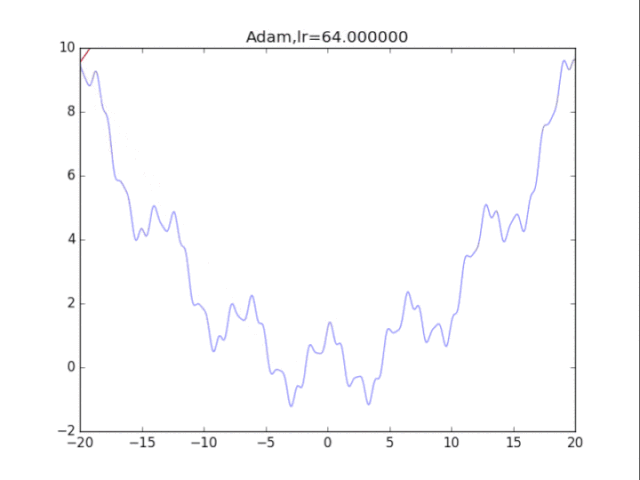
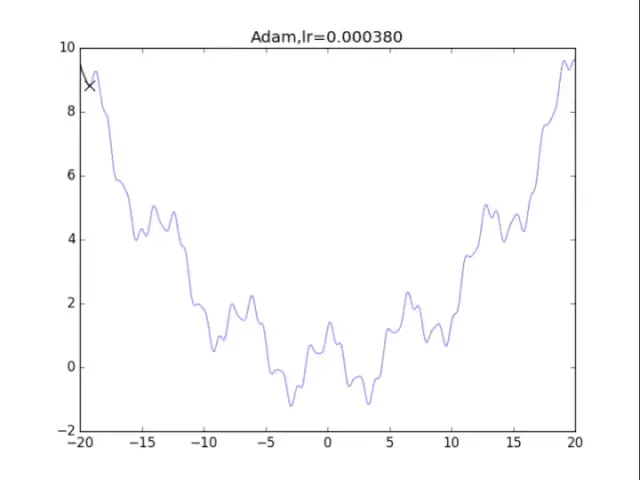
# Adam
for i in range(48):
# 绘制原来的函数
plt.plot(points_x, points_y, c="b", alpha=0.5, linestyle="-")
# 算法开始
lr = pow(1.2,-i)*2
rou1,rou2 = 0.9,0.9 # 原来的算法中rou2=0.999,但是效果很差
delta = 1e-8
x = -20
s,r = 0,0
t = 0
Adam_x, Adam_y = [], []
for it in range(1000):
Adam_x.append(x), Adam_y.append(f(x))
t += 1
g = df(x)
s = rou1 * s + (1 - rou1)*g
r = rou2 * r + (1 - rou2)*g*g # 积累平方梯度
s = s/(1-pow(rou1,t))
r = r/(1-pow(rou2,t))
x = x - lr /(delta + np.sqrt(r)) * s
plt.xlim(-20, 20)
plt.ylim(-2, 10)
plt.plot(Adam_x, Adam_y, c="r", linestyle="-")
plt.scatter(Adam_x[-1],Adam_y[-1],90,marker = "x",color="g")
plt.title("Adam,lr=%f"%(lr))
plt.savefig("Adam,lr=%f"%(lr) + ".png")
plt.clf()
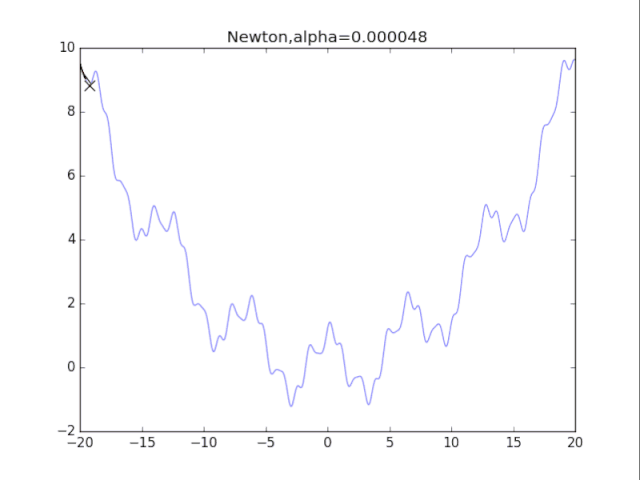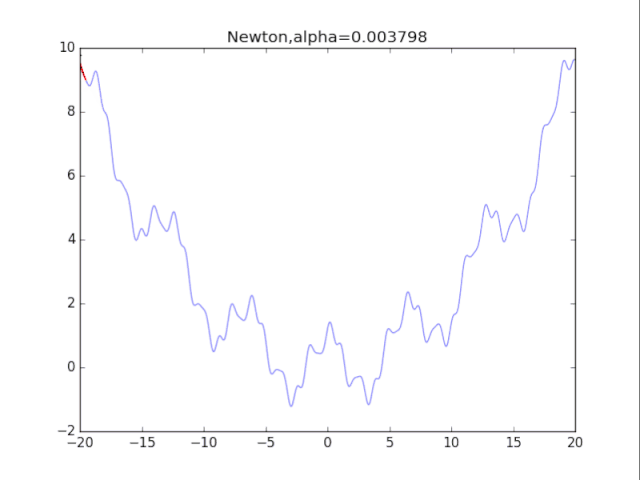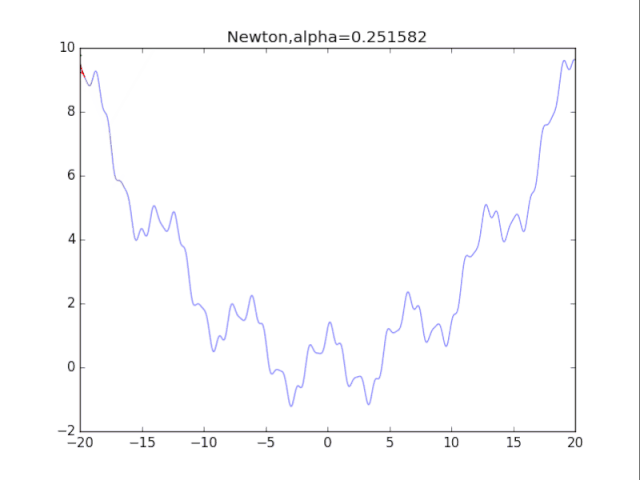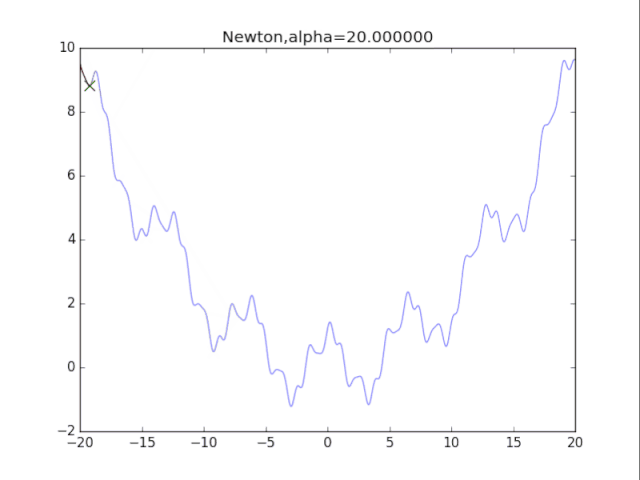
# 牛顿法
for i in range(72):
# 绘制原来的函数
plt.plot(points_x, points_y, c="b", alpha=0.5, linestyle="-")
# 算法开始
alpha= pow(1.2,-i)*20
x = -20.0
Newton_x, Newton_y = [], []
for it in range(1000):
Newton_x.append(x), Newton_y.append(f(x))
g = df(x)
gg = ddf(x)
x = x - g/(gg+alpha)
plt.xlim(-20, 20)
plt.ylim(-2, 10)
plt.plot(Newton_x, Newton_y, c="r", linestyle="-")
plt.scatter(Newton_x[-1],Newton_y[-1],90,marker = "x",color="g")
plt.title("Newton,alpha=%f"%(alpha))
plt.savefig("Newton,alpha=%f"%(alpha) + ".png")
plt.clf()
![]()
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心![]() 。
。
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。
![]()
记得备注呦
推荐两个专辑给大家:
专辑 | 李宏毅人类语言处理2020笔记
专辑 | NLP论文解读
![]()




登录查看更多
相关内容

专知会员服务
148+阅读 · 2019年12月28日
Arxiv
11+阅读 · 2020年2月18日


相关VIP内容
专知会员服务
148+阅读 · 2019年12月28日
相关资讯
相关论文
Arxiv
11+阅读 · 2020年2月18日