

论文题目:OneKE: A Dockerized Schema-Guided LLM Agent-based Knowledge Extraction System
本文作者:罗玉洁(浙江大学),茹湘原(浙江大学),刘康为(浙江大学),袁琳(蚂蚁集团),孙梦姝(蚂蚁集团),张宁豫(浙江大学),梁磊(蚂蚁集团),张志强(蚂蚁集团),周俊(蚂蚁集团),卫岚宁(蚂蚁集团),郑达(蚂蚁集团),王昊奋(同济大学),陈华钧(浙江大学)
发表会议:WWW 2025 Demonstration
论文链接:https://arxiv.org/abs/2412.20005
代码链接:https://github.com/zjunlp/OneKE
欢迎转载,转载请注明出处****

一、引言
知识抽取(Knowledge Extraction)作为从数据中获取知识的关键环节,广泛应用于知识图谱构建、检索增强及特定领域的科学研究。近年来,尽管已有众多基于大语言模型(Large Language Models, LLMs)的知识抽取系统相继问世,但现有方法在处理复杂结构的信息抽取、错误调试与修正方面依然面临显著挑战。 为此,我们提出了OneKE,一个基于模式引导的多智能体协同知识抽取框架,其设计采用基于大语言模型的多智能体架构,涵盖了用于输出模式分析的模式解析智能体(Schema Agent)、用于知识抽取的抽取智能体(Extraction Agent)以及专责于错误处理的反思智能体(Reflection Agent)。OneKE系统具备高效处理多种格式源文本的能力,能够适应不同任务配置并生成定制化的输出方案。通过在命名实体识别(Named Entity Recognition, NER)和关系抽取(Relation Extraction, RE)两个基准数据集上的系统评估,我们充分验证了OneKE各个模块的有效性。另外,OneKE在抽取网络新闻与PDF章节中的结构化信息方面表现出了卓越的能力,展现了其应对多样数据格式及任务上下文的能力。 二、技术架构
OneKE框架
OneKE通过多智能体架构和用户可配置的外部知识库来实现多领域多任务的知识抽取。具体地,OneKE系统可划分为四个模块,分别是三个协作智能体和一个可配置的知识库:

-
模式解析智能体 (Schema Agent): 为支持多种任务和数据类型,我们基于大模型(LLMs)开发了模式解析智能体,以生成合适的输出模式(Output Schema)。其目标是预处理数据和标准化任务设定,为信息抽取做准备。我们使用Langchain的`document_loaders模块进行数据预处理,并允许用户定义新数据类型和自定义方法。模式智能体在用户定义模式时,会从知识库中选择预定义模式;若未提供,则根据指令自我推断生成。用户还可通过更新知识库的方式轻松使用自定义输出模式。
-
抽取智能体 (Extraction Agent): 在接收到模式解析智能体生成的输出模式后,我们开发了抽取智能体,利用大型语言模型(LLMs)进行知识抽取,生成初步结果。该模块支持本地开源模型(如DeepSeek, LLaMA、Qwen)和API服务(如DeepSeek、OpenAI)。智能体通过检索案例库中的相关案例作为示例,生成提示并调用LLMs获取结果。为进一步处理抽取错误,我们设计了反思智能体。
-
反思智能体 (Reflection Agent): 为了实现自我反思和纠正,使OneKE能够从错误中学习,我们设计了反思智能体来优化已知错误。智能体理利用外部案例库中的相关错误案例,改进智能体生成的初步输出,最终产生准确结果。具体而言反思智能体通过检索与当前任务相关的错误案例,并将其反思分析纳入大型语言模型(LLM)。这反思智能体能够有效学习过去的错误,增强修正能力,生成更精确的答案。
-
配置知识库 (Configure Knowledge Base): OneKE中配备的知识库为三个智能体提供了必要的信息,包括预定义模式和历史抽取案例,从而提升了框架的信息抽取和错误修正能力.
-
模式库 (Schema Repository):模式库为模式智能体提供预定义模式,以支持细致的抽取过程,包括用于命名实体识别(NER)、关系抽取(RE)和事件抽取(EE)任务的模式。这些模式以Pydantic对象结构化组织,后续序列化为JSON格式供抽智能体理使用。同时,用户可以在库中自定义新的输出模式,增强系统的适应性和可扩展性。
-
案例库 (Case Repository):案例库用于存储历史知识抽取案例,支持抽取智能体和反智能体理。库中的案例分为正确案例和错误案例,前者提供成功抽取的推理步骤,后者则提供避免错误的警告。知识抽取任务后,案例库会自动更新,成功的推理步骤将存储为正确案例,而与正确答案不一致的结果将分析后存储为错误案例,供智能体未来使用。
框架特色
OneKE框架中的不同的智能体通过承担各自特定的职能,协调合作以应对多样化的知识抽取场景。这种灵活的设计使系统不仅具备高效的知识获取能力,也便于适应不断变化的需求。另外,可配置知识库的引入进一步增强了系统的功能,它促使模式配置、错误案例的调试与纠正过程更加高效和准确,从而显著提升了系统的整体性能。 OneKE通过精心设计的框架,有效应对知识抽取的复杂性和挑战,具备了以下特点:
- 对现实世界数据的适应能力: OneKE支持多种数据类型,包括HTML和PDF等,并预留用户定义接口,确保系统扩展性。
- 对复杂模式的泛化能力: 为应对多样且复杂的输出模式,OneKE引入模式智能体(Schema Agent),支持预定义模式和基于大模型(LLMs)的自我推导生成模式,兼容多种大语言模型及API服务,实现灵活的知识抽取。
- 对错误的识别与修复能力: 通过引入案例库(Case Repository),OneKE增强了模型的反思和错误纠正能力,实现知识抽取任务的持续性能提升与优化。
三、实验与应用
实验分析
我们在CrossNER和NYT-11-HRL数据集上评估OneKE。具体地,CrossNER是一个跨领域的命名实体识别(NER)数据集,而NYT-11-HRL则关注新闻领域的关系抽取(RE)任务。我们在LLaMA-3-8BInstruct和GPT-4-turbo模型上进行评估。
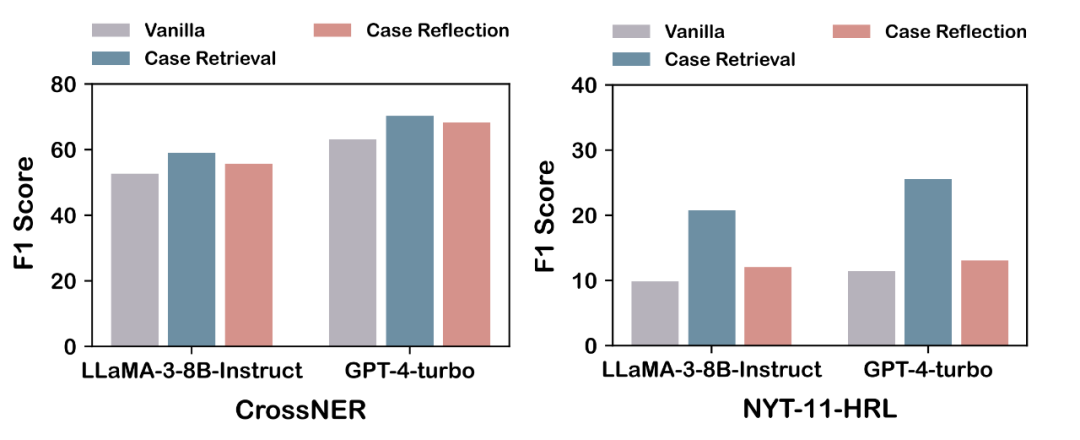
如上图所示,OneKE中采用的不同方法在NER和RE任务上都带来了性能提升。值得一提的是,抽取智能体的案例检索(Case Retrieval)方法取得了最显著的提升效果。通过轨迹分析,我们观察到该智能体有效地学习了相关案例中的推理路径,从而实现了更精准的抽取。此外,通过比较这两个不同任务,我们发现上述案例检索方法在更具挑战性的RE任务中更为有效。因为在这种相对复杂的抽取场景下,中间的推理步骤是至关重要的。另外,反思智能体的案例反思方法(Case Reflection)主要强调模型识别已知错误的能力及其对这些错误进行迁移学习的能力,从而在两个任务上均取得了类似的改进。我们将在下一部分提供特定应用场景的案例研究。
应用案例
在实际应用中,OneKE框架支持多种数据格式(HTML、PDF、Word),兼容短文本和长文本,以便无缝集成到各种下游应用中。我们将在以下两个代表性的抽取场景中提供案例分析。
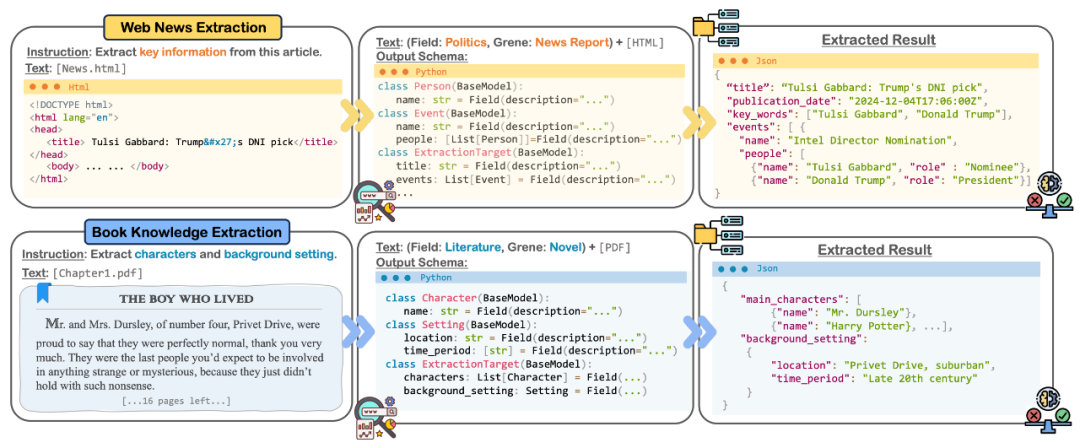
**1. 网络新闻抽取
在新闻领域,OneKE能够高效提取网页新闻内容,以支持情感监测、风险管理等多种应用。如上图,当前任务是从选取的网页HTML中提取关键信息,其目的是识别新闻特征并获取结构化内容。在解析HTML文本后,模式智能体识别出并将文档归类为政治领域的新闻报告。基于此,模式智能体生成了一种有效捕捉新闻关键信息的输出模式,并以Pydantic代码格式呈现。在输出模式序列化为JSON后,抽取智能体和反思智能体协作进行后续提取和优化。这一系列多智能体合作流程最终生成了一个JSON格式的抽取结果,准确反映了新闻报告中的关键信息和结构。2. 书籍知识抽取 OneKE还可以应用于从大型语料库中提取结构化知识,例如书籍、文档或操作手册等。以《哈利·波特》系列的第一章节为例,我们设定的抽取任务是提取章节中的主要角色和背景设定。如上图所示,模式智能体生成的输出模式成功识别了两个目标抽取对象:main_characters(主要角色)和background_setting(背景设定)。随后,在抽取智能体和反思智能体的协作下,OneKE成功完成了对应信息的精准抽取。 四、总结
本文介绍了OneKE,一个基于模式引导的多智能体协同知识抽取框架,其能够处理不同长度和格式的源文本(如HTML和PDF)和支持多种类型知识的抽取以满足特定需求。此外,集成的自我反思机制使得OneKE能够基于外部反馈进行迭代改进,从而提高其准确性和适应性。 然而,受限于大模型本身和数据解析工具的能力,OneKE目前在复杂网页、书籍抽取能力有限,且仍存在幻觉问题。在后续工作中,我们将长期维护OneKE,持续提升抽取能力,添加新功能并修复漏洞。
